

Les moteurs de recherche traditionnels reposent fortement sur la correspondance de mots-clés, manquant souvent l’intention réelle ou le contexte derrière les requêtes des utilisateurs. Les modèles d’embedding révolutionnent ce processus en transformant les requêtes et les documents en vecteurs denses qui capturent une signification sémantique profonde. Cela permet une recherche très pertinente et sensible au contexte, même lorsque les mots-clés exacts ne correspondent pas.
Désormais disponible sur Novita AI, le puissant modèle Qwen3 Embedding 8B prend en charge les entrées longues, la compréhension multilingue et la personnalisation sensible aux instructions, établissant ainsi une nouvelle norme pour les applications de recherche, de recommandation et de gestion des connaissances.
Construisez avec Novita AI dès aujourd’hui !
Qu’est-ce qu’un modèle d’embedding ?
Un modèle d’embedding est une technique d’apprentissage automatique qui transforme des données complexes et de haute dimension (mots, images, audio) en vecteurs numériques de dimension inférieure. Ces vecteurs capturent les relations sémantiques entre les points de données, permettant aux modèles de traiter et d’analyser les données plus efficacement.
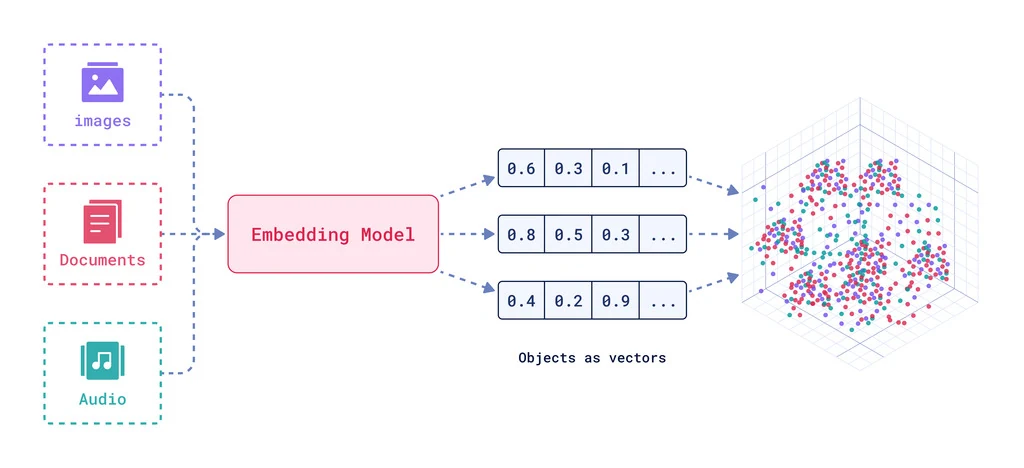
De Qdrant
Quels problèmes les modèles d’embedding résolvent-ils ?
Les embeddings permettent une recherche sémantique efficace en représentant les requêtes et les documents sous forme de vecteurs, résolvant ainsi le problème de la récupération des données les plus pertinentes pour une génération améliorée dans les systèmes RAG.
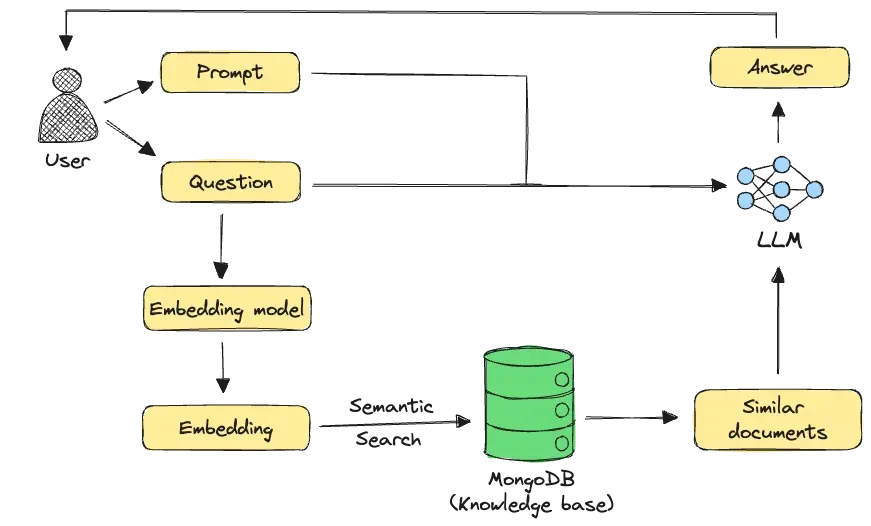
De Blog
1. Recherche et recommandations dans le commerce électronique
Des plateformes comme Instacart et Taobao utilisent des systèmes de recherche par embedding pour améliorer la recherche de produits et les recommandations. En comprenant les relations sémantiques entre les produits et les requêtes des utilisateurs, ces systèmes peuvent suggérer des articles qui correspondent aux préférences de l’utilisateur, même lorsque des mots-clés spécifiques ne sont pas utilisés.
2. Découverte de contenu
Les plateformes médiatiques utilisent les embeddings pour recommander des articles, des vidéos ou de la musique en fonction du comportement et des préférences des utilisateurs. Par exemple, si un utilisateur lit un article sur l’exploration spatiale, le système pourrait suggérer du contenu connexe sur l’astronomie ou la technologie des fusées.
3. Gestion des connaissances en entreprise
Les organisations utilisent des modèles d’embedding pour faciliter la recherche sémantique au sein de documents internes et de bases de connaissances. Cela permet aux employés de trouver efficacement des informations pertinentes, même lorsque leurs termes de recherche ne correspondent pas exactement au contenu du document.
4. Chatbots de support client
Les modèles d’embedding améliorent les chatbots en leur permettant de comprendre et de répondre plus efficacement aux requêtes des utilisateurs. En mappant les questions des utilisateurs à des réponses sémantiquement similaires dans une base de connaissances, les chatbots peuvent fournir des réponses précises et contextuellement appropriées.
Évaluation des modèles d’embedding
Ces métriques et catégories de tâches sont essentielles pour évaluer et comparer les performances des modèles d’embedding dans diverses applications. En analysant les performances d’un modèle dans ces domaines, les chercheurs et les praticiens peuvent sélectionner les modèles les plus adaptés à leurs besoins spécifiques.
- Moyenne (Tâche) : Performance moyenne du modèle sur toutes les tâches évaluées, montrant la polyvalence globale.
- Moyenne (Type) : Performance moyenne sur différents types de tâches ou formats de données (par exemple, phrase-à-phrase, paragraphe-à-paragraphe).
- Bitext Mining : Trouver des paires de phrases dans différentes langues qui sont des traductions, important pour les corpus multilingues.
- Class. (Classification) : Attribution d’étiquettes prédéfinies à des textes, comme la classification de sentiments ou de sujets.
- Clust. (Clustering) : Regroupement de textes similaires sans étiquettes pour découvrir des sujets ou des structures.
- Inst. Retri. (Récupération d’instances) : Récupération de documents spécifiques pertinents pour une requête, utilisé dans la recherche ou les recommandations.
- Multi. Class. (Classification multiclasse) : Classification des entrées en 3 catégories ou plus, par ex. sujets d’actualité.
- Pair. Class. (Classification par paires) : Détermination des relations entre paires de textes, comme les doublons ou les paraphrases.
- Rerank : Réorganisation des listes candidates (par exemple, résultats de recherche) pour améliorer la pertinence.
- Retri. (Récupération) : Récupération de documents/passages pertinents à partir de grands corpus en fonction des requêtes.
Qu’est-ce que le modèle Qwen3 Embedding ?
| Modèle | Taille | Couches | Longueur de séquence | Dimension d’embedding | Support MRL | Sensible aux instructions |
|---|---|---|---|---|---|---|
| Qwen3 Embedding 0.6B | 0.6B | 28 | 32K | 1024 | Oui | Oui |
| Qwen3 Embedding 4B | 4B | 36 | 32K | 2560 | Oui | Oui |
| Qwen3 Embedding 8B | 8B | 36 | 32K | 4096 | Oui | Oui |
- Les modèles Qwen3 Embedding sont disponibles en trois tailles : petit (0.6B), moyen (4B) et grand (8B).
- Tous les modèles prennent en charge des séquences d’entrée longues jusqu’à 32 000 tokens, adaptées au traitement de longs documents ou de code.
- Les modèles plus grands ont plus de couches (36 contre 28), des dimensions d’embedding plus grandes (jusqu’à 4096), ce qui leur permet potentiellement de capturer une information sémantique plus riche.
- Ils prennent tous en charge l’apprentissage de représentation multilingue (MRL), permettant un embedding efficace dans de nombreuses langues.
- Tous les modèles sont sensibles aux instructions, ce qui signifie qu’ils peuvent répondre à des instructions ou des invites de tâches spécifiques, améliorant la personnalisation et les performances en aval.
De plus, Qwen3 propose un modèle de reclassement qui aide à réordonner les résultats de requête pour fournir les réponses les plus pertinentes.
Caractéristiques clés de Qwen3 Embedding 8B

Capacité de Qwen3 Embedding 8B
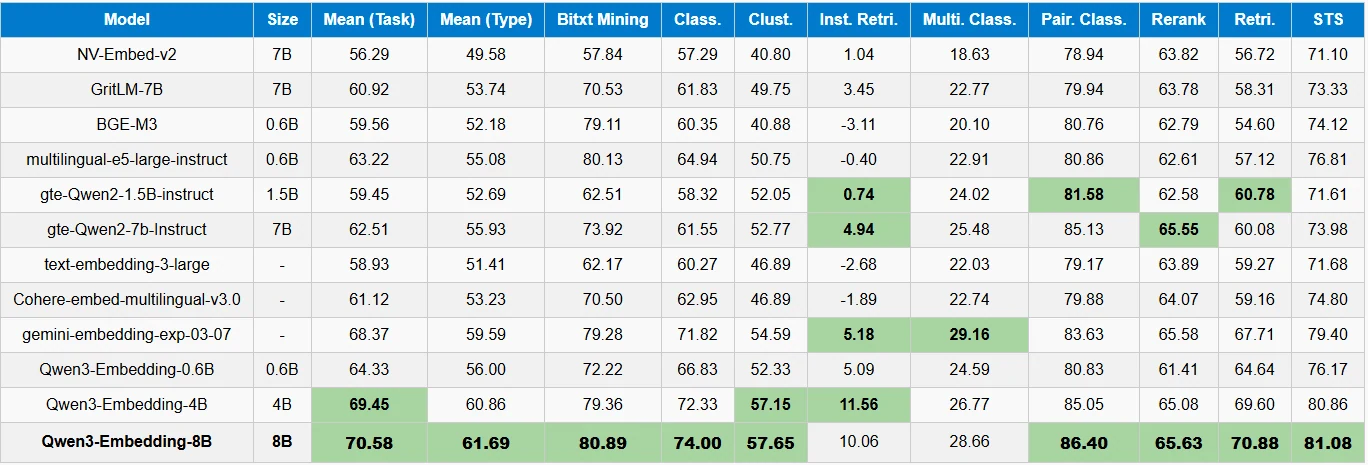
Vous pouvez consulter l’évaluation des modèles d’embedding sur ce leaderboard !
Comment accéder à Qwen3 Embedding 8B ?
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant le GPU cloud fiable et abordable pour construire et passer à l’échelle.
En plus de Qwen3 Embedding 8B, Novita AI propose également le bge-m3 gratuit pour soutenir le développement de la communauté open source !
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library .

Essayez Qwen3 Embedding 8B maintenant !
Étape 2 : Choisissez votre modèle et démarrez un essai gratuit
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Rendez-vous sur la page « Paramètres » et copiez la clé API comme indiqué sur l’image.

Étape 4 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec les modèles Novita AI. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
import json
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<Your API Key>",
)
model = "qwen/qwen3-embedding-8b"
def get_embeddings(text, model="qwen/qwen3-embedding-8b", encoding_format="float"):
response = client.embeddings.create(
model=model,
input=text,
encoding_format=encoding_format
)
return response
# Example usage
text = "The quick brown fox jumped over the lazy dog"
result = get_embeddings(text)
print(json.dumps(result.model_dump(), indent=2))
La série Qwen3 Embedding propose des modèles évolutifs, sensibles aux instructions et multilingues (0.6B, 4B et 8B paramètres) qui prennent en charge les séquences longues et offrent des performances de premier plan. Grâce à une personnalisation flexible et à un modèle de reclassement dédié, la série Qwen3 Embedding est bien adaptée à divers scénarios réels nécessitant une compréhension sémantique efficace et précise.
Foire aux questions
Qu’est-ce qu’un embedding ?
Un embedding est une technique utilisée pour convertir des données d’entrée en un vecteur de valeurs numériques dans un espace de dimension inférieure.
Quels problèmes les modèles d’embedding résolvent-ils ?
Ils permettent la recherche et la récupération sémantiques, améliorant la pertinence dans les moteurs de recherche, les recommandations, le support client, etc., en comprenant la signification derrière les requêtes et les documents.
Qu’est-ce que le modèle Qwen3 Embedding ?
Qwen3-Embedding est une famille de trois modèles (0.6B, 4B et 8B paramètres) prenant en charge les entrées longues (jusqu’à 32K tokens), l’apprentissage de représentation multilingue et la sensibilité aux instructions pour des tâches personnalisées. Le modèle 8B est en tête du classement MTEB avec un score de 70,58 ! Vous pouvez l’utiliser sur Novita AI !
Novita AI est la plateforme cloud tout-en-un qui dynamise vos ambitions IA. API intégrées, sans serveur, instance GPU — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et réalisez votre vision IA.



