

Points clés
Modèles d’IA pour le codage : Le codage assisté par IA augmente considérablement la productivité des développeurs en automatisant les tâches répétitives, en réduisant les erreurs et en assurant une qualité de code cohérente sur l’ensemble des projets.
Capacités de génération de code supérieures de Llama 3.3 70B : Llama 3.3 70B démontre une génération de code robuste avec une précision de 86 % sur le benchmark HumanEval et des capacités avancées multi-langages.
Guide d’intégration avec Novita AI : L’intégration via la plateforme Novita AI offre aux développeurs un accès API simple, des crédits d’essai gratuits et des fonctions d’appel complètes.
Le paysage de la génération de code assistée par IA a considérablement évolué, et Llama 3.3 70B s’impose comme un outil puissant pour les développeurs. Ce guide complet explore les capacités de ce modèle de langage avancé et son application dans le développement logiciel moderne.
Comprendre la génération de code assistée par IA
Comment les LLM génèrent du code de programmation
- Comprendre le contexte du code
- Analyser les données d’entraînement volumineuses issues de dépôts de code et de forums techniques
- Comprendre les commentaires, les noms de fonctions et les noms de variables
- Traiter les entrées en langage naturel
- Analyser la description du développeur à l’aide de techniques de NLP
- Décomposer l’entrée en unités significatives
- Identifier les relations entre les parties de la description
- Mapper le langage naturel vers les constructions de code appropriées
- Générer un code contextuellement précis
- Appliquer les connaissances acquises sur les langages de programmation
- Respecter la syntaxe et la structure du langage sélectionné
- Intégrer les conventions de codage et les meilleures pratiques
- Produire un code qui correspond à l’intention du développeur
- Affiner et optimiser la sortie
- Vérifier l’exactitude et l’efficacité du code généré
- Appliquer des techniques d’amélioration de la qualité du code
- Optimiser pour les performances et la lisibilité
- Intégrer dans le flux de travail de développement
- Incorporer de manière transparente le code généré dans les projets existants
- Proposer des options de personnalisation et de réglage fin
https://www.youtube.com/watch?v=eaTIrJnkuNI
Fondements techniques
- Masquage au niveau des tokens
- C’est l’approche la plus courante, où des tokens individuels dans le code sont masqués. Pour les langages de programmation, les tokens peuvent inclure des variables, des mots-clés, des opérateurs, etc. Le modèle est entraîné à prédire ces tokens masqués en fonction du contexte environnant.
- Masquage au niveau des caractères
- Dans cette technique, des caractères individuels au sein des tokens de code sont masqués. Cela peut aider le modèle à apprendre des motifs au niveau des caractères et à améliorer sa compréhension de la syntaxe du code à une granularité plus fine. C’est particulièrement utile pour gérer les tokens hors vocabulaire et comprendre le formatage du code.
- Masquage au niveau des lignes
- Des lignes entières de code sont masquées dans cette approche. Cela aide le modèle à comprendre des structures de code de plus haut niveau et les dépendances entre les lignes. C’est particulièrement utile pour des tâches comme la complétion de code ou la détection de bugs qui nécessitent la compréhension de segments de code multi-lignes.
Quelques implémentations et variations spécifiques incluent :
- Prédiction de spans : Au lieu de masquer des tokens individuels, des spans contigus de tokens sont masqués. Utilisé dans des modèles comme SpanBERT pour améliorer la capacité du modèle à capturer les relations entre des tokens éloignés.
- Détection de tokens remplacés : Utilisé dans des modèles comme ELECTRA, où certains tokens sont remplacés par des alternatives plausibles plutôt que masqués. Le modèle est entraîné à distinguer les tokens originaux des tokens remplacés.
- Masquage dynamique : Implémenté dans des modèles comme RoBERTa, où le motif de masquage est généré dynamiquement pendant l’entraînement plutôt que d’être statique. Cela expose le modèle à des motifs de masquage plus diversifiés.
Ces techniques aident les modèles de langage spécialisés dans le code à développer une compréhension plus approfondie de la structure, de la syntaxe et de la sémantique du code, conduisant à de meilleures performances sur diverses tâches liées au code.
Principaux avantages pour les développeurs
- Augmentation de la productivité grâce à l’automatisation des tâches
- Réduction des coûts de développement
- Amélioration de la cohérence du code et réduction des erreurs
- Aide à la traduction et à la documentation du code
- Accessibilité améliorée du développement logiciel
Plongée en profondeur : Llama 3.3 70B
Description du modèle
Llama 3.3 70B est un modèle textuel uniquement, optimisé par instructions, conçu pour le dialogue multilingue et la génération de code. Il offre des performances améliorées par rapport à ses prédécesseurs et est optimisé pour les interactions de type assistant.
- Architecture : Architecture transformer optimisée
- Fenêtre de contexte : Fenêtre de contexte étendue pour les modifications complexes et les longues conversations
- Langues : Prend en charge l’anglais, l’allemand, le français, l’italien, le portugais, l’hindi, l’espagnol et le thaï, avec la possibilité de produire du texte dans d’autres langues (les performances peuvent varier)
Comparaisons de benchmarks
HumanEval et MBPP sont deux benchmarks fondamentaux utilisés pour évaluer les capacités de génération de code des grands modèles de langage. HumanEval se concentre sur des défis de programmation complexes à travers 164 problèmes conçus à la main, tandis que MBPP teste les compétences de base en programmation Python à travers 974 tâches de niveau débutant.
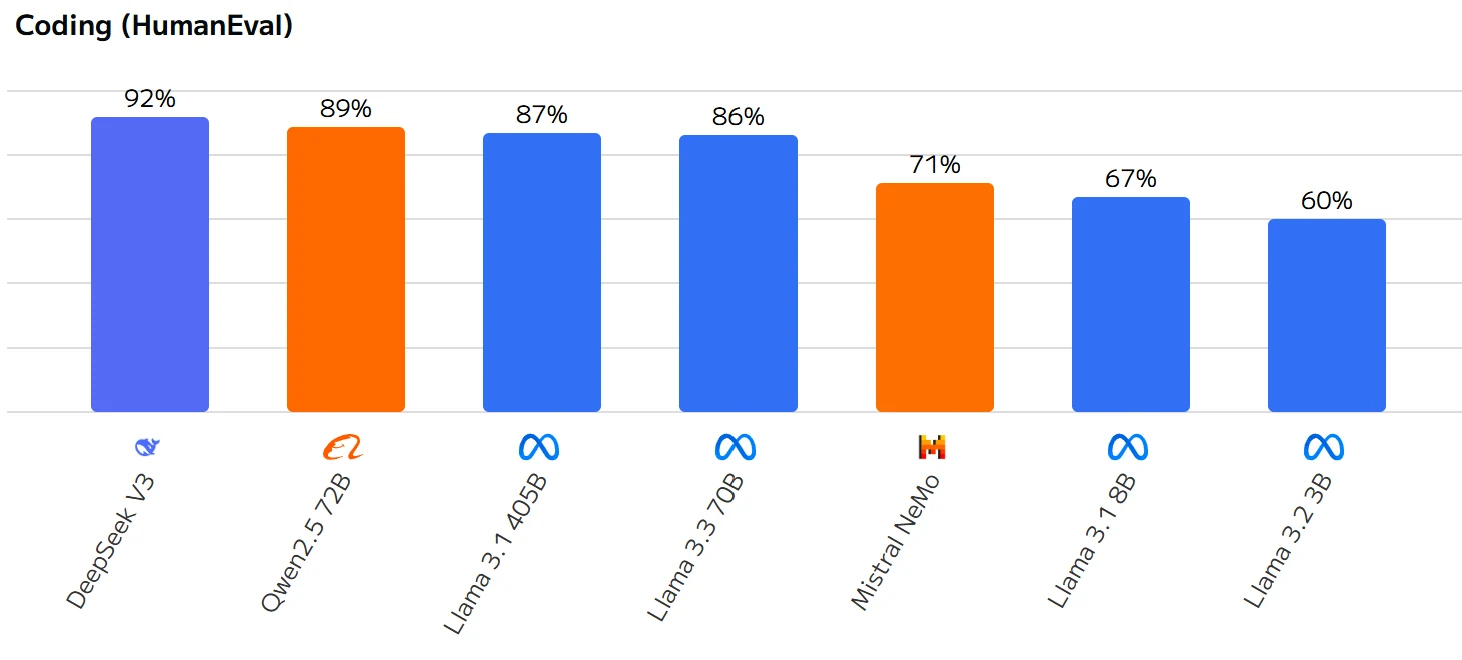
Le score de Llama 3.3 70B (80 %) est supérieur à celui de Llama 3.1 8B (67 %), mais inférieur à celui de certains autres modèles, tels que :
- DeepSeek V3: 92 %
- Qwen 2.5 72B : 89 %
- Llama 3.1 405B : 87 %
- Llama 3.3 70B : 86 %
Llama 3.3 70B obtient de bons résultats dans les tâches de codage, se situant dans la fourchette moyenne-haute parmi les modèles listés. Bien qu’il montre des capacités solides, il reste une marge d’amélioration, notamment par rapport aux modèles les plus performants comme Claude 3.5 Sonnet et DeepSeek V3.
De plus, des messages indiquent que Llama 3.3 70B a la capacité de générer des sorties JSON pour l’appel de fonctions. Cela améliore considérablement le potentiel du LLM en matière de génération, d’optimisation et de gestion de code en permettant l’accès à des ressources externes et l’exécution d’opérations pratiques. Cela permet au LLM de mieux s’adapter aux besoins réels du développement logiciel, en fournissant des solutions de code de meilleure qualité et plus fiables.
Si vous souhaitez en savoir plus, vous pouvez consulter cet article : Llama 3.3 70B Function Calling : Intégration transparente pour de meilleures performances
Comment choisir un modèle adapté au codage
Métriques de performance essentielles
Lors du choix d’un grand modèle de langage (LLM) pour la génération de code, il est crucial de prendre en compte plusieurs métriques de performance clés :
- Précision : La capacité du modèle à générer un code correct et fonctionnel qui répond aux exigences spécifiées.
- Efficacité : La vitesse à laquelle le modèle peut générer du code et sa consommation de ressources.
- Support linguistique : L’étendue des langages de programmation avec lesquels le modèle peut travailler efficacement.
- Capacités d’intégration : La facilité avec laquelle le modèle peut être intégré dans les flux de travail et outils de développement existants.
- Compréhension du contexte : La capacité du modèle à saisir et à maintenir le contexte sur des segments de code plus longs ou plusieurs fichiers.
- Options de personnalisation : La flexibilité pour affiner ou adapter le modèle à des styles de codage spécifiques ou à des exigences de domaine particulières.
L’évaluation de ces métriques garantit que le modèle choisi correspond à vos besoins de développement et peut améliorer efficacement la productivité de votre équipe.
Meilleures options open-source
Plusieurs alternatives open-source sont disponibles pour la génération de code, chacune avec ses forces uniques :
- Llama 3.3 70B : Un modèle puissant connu pour ses capacités multilingues et ses performances solides dans les tâches de génération de code.
- DeepSeek Coder V3 : Un modèle avancé avec des capacités robustes de génération de code et le support de multiples paradigmes de programmation.
- Codestral (Mistral) : Axé sur la génération efficace de code, particulièrement adapté au prototypage rapide et aux tâches de complétion de code.
- Stable Code 3B : Un modèle léger optimisé pour les tâches liées au code, offrant un bon équilibre entre performances et exigences en ressources.
Ces alternatives offrent aux développeurs une gamme d’options pour répondre à différents besoins de projet, des applications d’entreprise à grande échelle aux environnements plus petits aux ressources limitées. Lors du choix d’un modèle, tenez compte de facteurs tels que les tâches de codage spécifiques à accomplir, les langages avec lesquels vous travaillez et vos ressources de calcul disponibles.
Tutoriel de génération de code : Implémentation de Llama 3.3 70B
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.

Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En entrant dans la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Obtenez la clé API Novita AI en vous référant à : https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<VOTRE Clé API Novita AI>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # ou False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Agissez comme un assistant utile.",
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Lors de l’inscription, Novita AI offre un crédit de 0,50 $ pour vous lancer !
Si les crédits gratuits sont épuisés, vous pouvez payer pour continuer à utiliser le service.
Guide avancé de dépannage

Problèmes courants et solutions
- Erreurs logiques : Affinez les invites et fournissez plus de contexte
- Sections incomplètes : Décomposez les tâches complexes en invites plus petites et gérables
- Contexte mal compris : Clarifiez les exigences et utilisez une terminologie spécifique au domaine
Techniques d’amélioration de la qualité du code
- Tests approfondis du code généré
- Utilisation d’outils d’analyse de code comme DeepCode ou Codiga
- Mise en œuvre d’une analyse statique pour la sécurité et l’efficacité
En conclusion, à mesure que la génération de code par IA continue d’évoluer, les développeurs peuvent s’attendre à une meilleure précision et à une intégration plus poussée avec les environnements de développement. Pour maximiser ses avantages, commencez par des exigences claires, testez minutieusement le code généré et maintenez un équilibre entre l’assistance de l’IA et l’expertise humaine. Commencez à implémenter Llama 3.3 70B pour des tâches de codage spécifiques tout en priorisant la qualité du code et la formation de l’équipe aux outils d’IA. Cette approche garantit une adoption efficace des capacités de codage par IA tout en restant attentif aux meilleures pratiques et aux développements futurs dans le domaine.
Questions fréquentes
Quelles sont les limites de l’utilisation des LLM pour la génération de code ?
Les LLM peuvent produire un code inexact si leurs données d’entraînement sont obsolètes ou s’ils interprètent mal l’entrée.
Comment rester informé des dernières avancées des LLM pour la génération de code ?
Restez informé en participant à des forums techniques, des communautés et en consultant des articles de recherche, comme Novita AI.
Quels types d’outils d’IA sont disponibles pour aider au codage ?
Les outils de codage IA vont de la complétion de code à la génération complète de projet, offrant des fonctionnalités comme les suggestions en temps réel et l’aide au débogage.
Novita AI est la plateforme cloud tout-en-un qui alimente vos ambitions en IA. APIs intégrées, serverless, GPU Instance — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.



