

Wichtige Highlights
KI-Modelle fürs Programmieren: KI-gestütztes Programmieren steigert die Produktivität von Entwicklern erheblich, indem es Routineaufgaben automatisiert, Fehler reduziert und eine gleichbleibende Codequalität über Projekte hinweg gewährleistet.
Überlegene Codegenerierungsfähigkeiten von Llama 3.3 70B: Llama 3.3 70B demonstriert eine robuste Codegenerierung mit 86 % Genauigkeit im HumanEval-Benchmark und erweiterte sprachübergreifende Fähigkeiten.
Integrationsleitfaden mit Novita AI: Die Integration über die Novita AI-Plattform bietet Entwicklern einen unkomplizierten API-Zugriff, kostenlose Testguthaben und umfassende Funktionen zum Aufruf von Funktionen.
Die Landschaft der KI-gestützten Codegenerierung hat sich erheblich weiterentwickelt, wobei Llama 3.3 70B als leistungsstarkes Werkzeug für Entwickler hervorgetreten ist. Dieser umfassende Leitfaden untersucht die Fähigkeiten dieses fortschrittlichen Sprachmodells und seine Anwendung in der modernen Softwareentwicklung.
Grundlegendes zur KI-gestützten Codegenerierung
Wie LLMs Programmiercode generieren
- Codekontext verstehen
- Umfangreiche Trainingsdaten aus Code-Repositories und technischen Foren analysieren
- Kommentare, Funktionsnamen und Variablennamen verstehen
- Verarbeitung natürlicher Spracheingabe
- Beschreibung des Entwicklers mithilfe von NLP-Techniken parsen
- Eingabe in sinnvolle Einheiten aufteilen
- Beziehungen zwischen Beschreibungsteilen identifizieren
- Natürliche Sprache auf geeignete Code-Konstrukte abbilden
- Kontextuell korrekten Code generieren
- Erlerntes Wissen über Programmiersprachen anwenden
- Syntax und Struktur der ausgewählten Sprache befolgen
- Programmierkonventionen und Best Practices einbeziehen
- Code erzeugen, der der Absicht des Entwicklers entspricht
- Ausgabe verfeinern und optimieren
- Generierten Code auf Genauigkeit und Effizienz prüfen
- Techniken zur Verbesserung der Codequalität anwenden
- Für Leistung und Lesbarkeit optimieren
- In den Entwicklungsworkflow integrieren
- Generierten Code nahtlos in bestehende Projekte einfügen
- Anpassungs- und Feinabstimmungsoptionen bereitstellen
https://www.youtube.com/watch?v=eaTIrJnkuNI
Technische Grundlage
- Token-Level-Masking
- Dies ist der häufigste Ansatz, bei dem einzelne Token im Code maskiert werden. Für Programmiersprachen können Token Variablen, Schlüsselwörter, Operatoren usw. umfassen. Das Modell wird trainiert, diese maskierten Token basierend auf dem umgebenden Kontext vorherzusagen.
- Zeichenebenen-Masking
- Bei dieser Technik werden einzelne Zeichen innerhalb von Code-Token maskiert. Dies kann dem Modell helfen, Muster auf Zeichenebene zu lernen und sein Verständnis der Codesyntax mit feinerer Granularität zu verbessern. Besonders nützlich für die Behandlung von Vokabeln, die nicht im Wortschatz enthalten sind, und für das Verständnis der Codeformatierung.
- Zeilenebenen-Masking
- Ganze Codezeilen werden bei diesem Ansatz maskiert. Dies hilft dem Modell, übergeordnete Codestrukturen und Abhängigkeiten zwischen Zeilen zu verstehen. Besonders nützlich für Aufgaben wie Codevervollständigung oder Fehlererkennung, die ein Verständnis mehrzeiliger Codeabschnitte erfordern.
Einige spezifische Implementierungen und Variationen umfassen:
- Span-Vorhersage: Anstatt einzelner Token werden zusammenhängende Token-Spannen maskiert. Dies wird in Modellen wie SpanBERT verwendet, um die Fähigkeit des Modells zu verbessern, Beziehungen zwischen entfernten Token zu erfassen.
- Ersetzte Token-Erkennung: Wird in Modellen wie ELECTRA verwendet, bei denen einige Token durch plausible Alternativen ersetzt statt maskiert werden. Das Modell wird trainiert, zwischen Original- und Ersatztoken zu unterscheiden.
- Dynamisches Masking: Implementiert in Modellen wie RoBERTa, bei dem das Maskierungsmuster während des Trainings dynamisch und nicht statisch generiert wird. Dies setzt das Modell einer größeren Vielfalt an Maskierungsmustern aus.
Diese Techniken helfen codefokussierten Sprachmodellen, ein tieferes Verständnis von Codestruktur, Syntax und Semantik zu entwickeln, was zu einer verbesserten Leistung bei verschiedenen codebezogenen Aufgaben führt.
Wichtige Vorteile für Entwickler
- Gesteigerte Produktivität durch Aufgabenautomatisierung
- Reduzierte Entwicklungskosten
- Verbesserte Codekonsistenz und Fehlerreduzierung
- Unterstützung bei Codeübersetzung und Dokumentation
- Verbesserte Zugänglichkeit der Softwareentwicklung
Tiefer Einblick: Llama 3.3 70B
Modellbeschreibung
Llama 3.3 70B ist ein anweisungsabgestimmtes, rein textbasiertes Modell, das für mehrsprachige Dialoge und Codegenerierung entwickelt wurde. Es bietet eine verbesserte Leistung im Vergleich zu seinen Vorgängern und ist für assistentenähnliche Chat-Interaktionen optimiert.
- Architektur: Optimierte Transformer-Architektur
- Kontextfenster: Erweitertes Kontextfenster für komplexe Änderungen und lange Gespräche
- Sprachen: Unterstützt Englisch, Deutsch, Französisch, Italienisch, Portugiesisch, Hindi, Spanisch und Thailändisch mit der Fähigkeit, Text in anderen Sprachen auszugeben (Leistung kann variieren)
Benchmark-Vergleiche
HumanEval und MBPP sind zwei grundlegende Benchmarks zur Bewertung der Codegenerierungsfähigkeiten großer Sprachmodelle, wobei HumanEval sich auf komplexe Programmierherausforderungen mit 164 handgefertigten Problemen konzentriert, während MBPP grundlegende Python-Programmierfähigkeiten mit 974 Aufgaben auf Einstiegsniveau testet
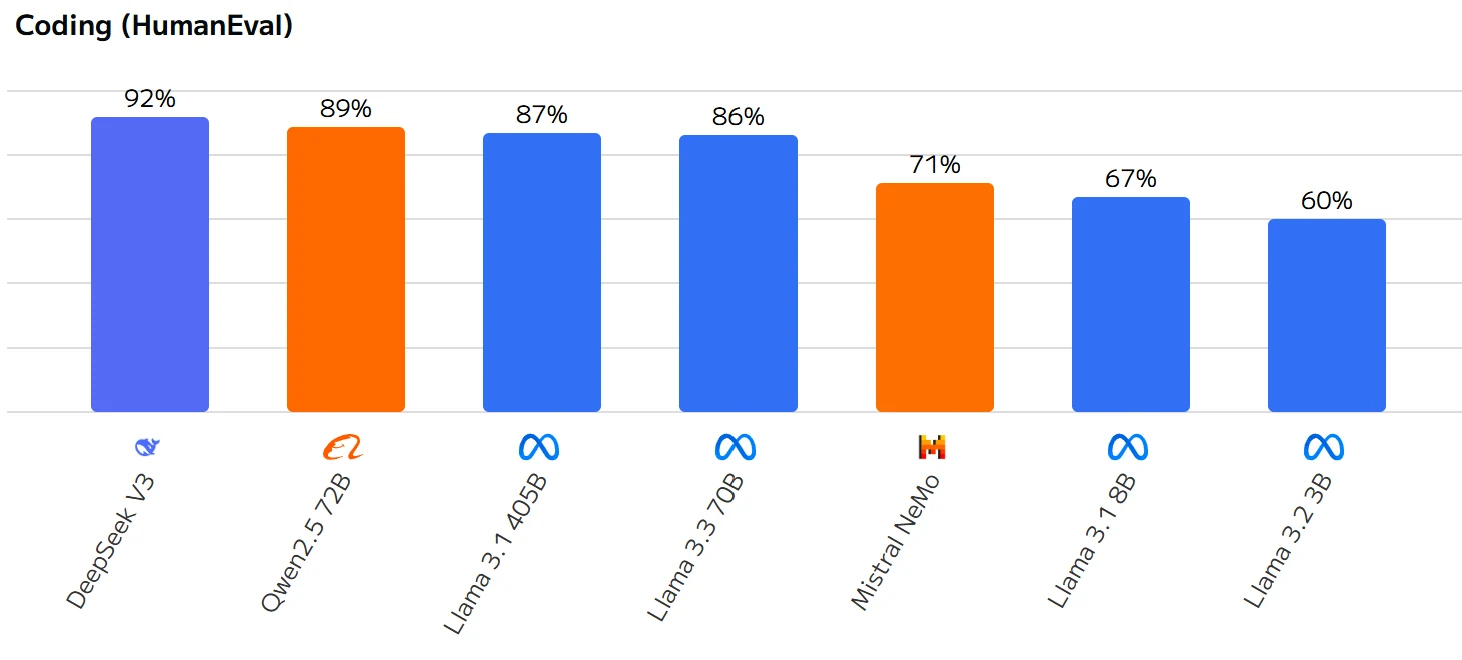
Der Wert für Llama 3.3 70B (80%) ist höher als der von Llama 3.1 8B (67%), aber niedriger als bei einigen anderen Modellen, wie z. B.:
- DeepSeek V3: 92%
- Qwen 2.5 72B: 89%
- Llama 3.1 405B: 87%
- Llama 3.3 70B: 86%
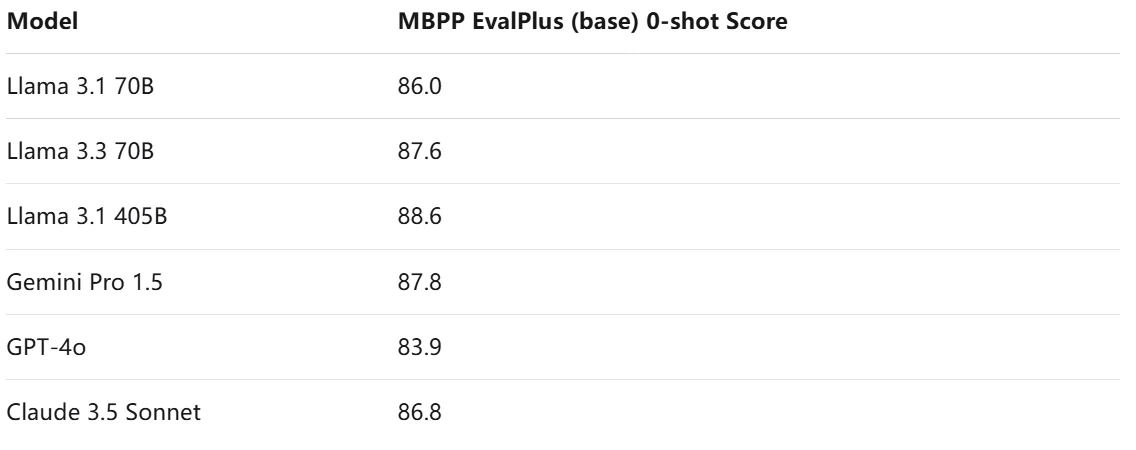
Llama 3.3 70B schneidet bei Programmieraufgaben gut ab und liegt im oberen Mittelfeld der aufgeführten Modelle. Obwohl es starke Fähigkeiten zeigt, gibt es noch Raum für Verbesserungen, insbesondere im Vergleich zu den leistungsstärksten Modellen wie Claude 3.5 Sonnet und DeepSeek V3.
Darüber hinaus gibt es Hinweise darauf, dass Llama 3.3 70B in der Lage ist, JSON-Ausgaben für Funktionsaufrufe zu generieren. Dies erweitert das Potenzial von LLMs bei der Codegenerierung, -optimierung und -verwaltung erheblich, indem der Zugriff auf externe Ressourcen und die Ausführung praktischer Operationen ermöglicht werden. Dies befähigt LLMs, sich besser an die realen Anforderungen der Softwareentwicklung anzupassen und qualitativ hochwertigere und zuverlässigere Codelösungen zu liefern.
Wenn Sie weitere Informationen wünschen, lesen Sie diesen Artikel: Llama 3.3 70B Function Calling: Nahtlose Integration für bessere Leistung
So wählen Sie ein geeignetes Modell für die Programmierung aus
Wesentliche Leistungsmetriken
Bei der Auswahl eines großen Sprachmodells (LLM) für die Codegenerierung sollten mehrere wichtige Leistungsmetriken berücksichtigt werden:
- Genauigkeit: Die Fähigkeit des Modells, korrekten, funktionsfähigen Code zu generieren, der die spezifizierten Anforderungen erfüllt.
- Effizienz: Die Geschwindigkeit, mit der das Modell Code generieren kann, und sein Ressourcenverbrauch.
- Sprachunterstützung: Die Bandbreite an Programmiersprachen, mit denen das Modell effektiv arbeiten kann.
- Integrationsfähigkeiten: Wie einfach das Modell in bestehende Entwicklungsworkflows und -tools integriert werden kann.
- Kontextverständnis: Die Fähigkeit des Modells, Kontext über längere Codeabschnitte oder mehrere Dateien hinweg zu erfassen und beizubehalten.
- Anpassungsoptionen: Die Flexibilität, das Modell für bestimmte Codierungsstile oder domänenspezifische Anforderungen feinabzustimmen oder anzupassen.
Die Bewertung dieser Metriken stellt sicher, dass das gewählte Modell Ihren Entwicklungsanforderungen entspricht und die Produktivität Ihres Teams effektiv steigern kann.
Top-Open-Source-Optionen
Es stehen mehrere Open-Source-Alternativen zur Codegenerierung zur Verfügung, jede mit ihren eigenen Stärken:
- Llama 3.3 70B: Ein leistungsstarkes Modell, bekannt für seine mehrsprachigen Fähigkeiten und starke Leistung bei Codegenerierungsaufgaben.
- DeepSeek Coder V3: Ein fortschrittliches Modell mit robusten Codegenerierungsfähigkeiten und Unterstützung für mehrere Programmierparadigmen.
- Codestral (Mistral): Fokussiert auf effiziente Codegenerierung, besonders geeignet für schnelles Prototyping und Codevervollständigungsaufgaben.
- Stable Code 3B: Ein leichtgewichtiges Modell, optimiert für codebezogene Aufgaben, das eine gute Balance zwischen Leistung und Ressourcenanforderungen bietet.
Diese Alternativen bieten Entwicklern eine Reihe von Optionen, um unterschiedlichen Projektanforderungen gerecht zu werden, von großen Unternehmensanwendungen bis hin zu kleineren, ressourcenbeschränkten Umgebungen. Berücksichtigen Sie bei der Auswahl eines Modells Faktoren wie die spezifischen Programmieraufgaben, die Sie erledigen müssen, die Sprachen, mit denen Sie arbeiten, und Ihre verfügbaren Rechenressourcen.
Tutorial zur Codegenerierung: Implementierung von Llama 3.3 70B
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.

Schritt 4: Holen Sie sich Ihren API-Schlüssel
Um sich bei der API zu authentifizieren, stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie auf die Seite „Einstellungen“ und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Bei der Registrierung stellt Novita AI ein Guthaben von 0,50 $ zur Verfügung, um Ihnen den Einstieg zu erleichtern!
Wenn das kostenlose Guthaben aufgebraucht ist, können Sie bezahlen, um es weiter zu nutzen.
Erweiterte Fehlerbehebungsanleitung

Häufige Probleme und Lösungen
- Logische Fehler: Eingabeaufforderungen verfeinern und mehr Kontext bereitstellen
- Unvollständige Abschnitte: Komplexe Aufgaben in kleinere, überschaubare Aufforderungen aufteilen
- Missverstandener Kontext: Anforderungen klären und domänenspezifische Terminologie verwenden
Techniken zur Verbesserung der Codequalität
- Gründliches Testen des generierten Codes
- Verwendung von Codeanalysetools wie DeepCode oder Codiga
- Implementierung statischer Analysen für Sicherheit und Effizienz
Zusammenfassend lässt sich sagen, dass Entwickler mit der weiteren Entwicklung der KI-Codegenerierung eine verbesserte Genauigkeit und eine bessere Integration in Entwicklungsumgebungen erwarten können. Um die Vorteile zu maximieren, beginnen Sie mit klaren Anforderungen, testen Sie generierten Code gründlich und wahren Sie ein Gleichgewicht zwischen KI-Unterstützung und menschlichem Fachwissen. Beginnen Sie mit der Implementierung von Llama 3.3 70B für spezifische Programmieraufgaben, während Sie Codequalität und Team-Schulung in KI-Tools priorisieren. Dieser Ansatz gewährleistet eine effektive Einführung von KI-Programmierfähigkeiten unter Berücksichtigung bewährter Verfahren und zukünftiger Entwicklungen auf diesem Gebiet.
Häufig gestellte Fragen
Was sind die Einschränkungen bei der Verwendung von LLMs zur Codegenerierung?
LLMs können ungenauen Code produzieren, wenn ihre Trainingsdaten veraltet sind oder sie die Eingabe falsch interpretieren.
Wie bleibe ich über die neuesten Entwicklungen bei LLMs zur Codegenerierung auf dem Laufenden?
Bleiben Sie auf dem Laufenden, indem Sie an technischen Foren, Communities teilnehmen und Forschungspapiere lesen, wie z. B. Novita AI.
Welche Arten von KI-Tools gibt es, die beim Programmieren helfen?
KI-Programmiertools reichen von der Codevervollständigung bis zur vollständigen Projekterstellung und bieten Funktionen wie Echtzeitvorschläge und Debugging-Hilfe.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, serverlos, GPU-Instanz – die kosteneffizienten Tools, die Sie benötigen. Infrastruktur überflüssig machen, kostenlos starten und Ihre KI-Vision verwirklichen.



