

Points clés
- Introduction à Llama 3 : Llama 3 est un modèle de langage de pointe développé par Meta, conçu pour offrir des performances élevées dans les tâches de traitement du langage naturel. L’affiner peut considérablement améliorer ses capacités pour des applications spécifiques.
- Llama 3 a obtenu des scores compétitifs sur divers benchmarks comme MMLU et MATH, démontrant son efficacité dans les tâches de raisonnement et les applications spécialisées.
- Le réglage fin permet de personnaliser Llama 3 pour des tâches spécifiques, améliorant la précision et la pertinence tout en optimisant l’utilisation des ressources.
- Les outils essentiels pour le réglage fin incluent Hugging Face Transformers, PyTorch et des GPU hautes performances. Une configuration correcte est cruciale pour un réglage fin réussi.
- Le processus d’entraînement implique la définition des taux d’apprentissage, des tailles de lot et des époques, avec des stratégies pour évaluer les performances du modèle et résoudre des problèmes comme le surapprentissage.
- Novita AI propose des solutions GPU serverless qui simplifient la gestion des ressources pendant le processus de réglage fin, permettant aux développeurs de se concentrer sur l’optimisation.
Le réglage fin des modèles de langage à grande échelle comme Llama 3 est essentiel pour personnaliser les modèles pré-entraînés afin de mieux répondre à des tâches ou des ensembles de données spécifiques. Développé par Meta, Llama 3 représente une avancée significative dans le traitement du langage naturel, avec des capacités qui rivalisent avec certains des modèles les plus puissants du marché. L’architecture du modèle et ses méthodologies d’entraînement ont été conçues pour optimiser les performances sur un large éventail d’applications, ce qui en fait un outil polyvalent pour les développeurs.
Des benchmarks récents indiquent que Llama 3 surpasse tous les modèles ouverts de pointe de sa catégorie de paramètres sur des métriques d’évaluation standard telles que MedQA et MMLU. Cette performance est attribuée à un pré-entraînement intensif sur des ensembles de données diversifiés, ce qui améliore sa compréhension du contexte et des nuances du langage. Affiner efficacement Llama 3 peut débloquer ses véritables capacités, permettant aux organisations d’adapter le modèle à des cas d’usage spécifiques comme le support client, la génération de contenu ou des domaines spécialisés tels que les applications médicales et juridiques.
Ce guide propose une approche étape par étape complète pour vous aider à optimiser Llama 3 pour votre cas d’usage, de la configuration de votre environnement à la résolution des problèmes courants lors du réglage fin.
Comprendre les bases de Llama 3
Qu’est-ce que Llama 3 et comment fonctionne-t-il ?
Llama 3 est un modèle de langage de pointe développé par Meta, excellent pour comprendre et générer du texte semblable à celui d’un humain. Il repose sur une architecture Transformer, qui lui permet de traiter et de générer du langage naturel efficacement. Comme d’autres grands modèles tels que GPT-3, Llama 3 est pré-entraîné sur des ensembles de données massifs – plus de 15 trillions de tokens – ce qui lui permet de comprendre un large éventail de tâches.
L’architecture se compose de plusieurs couches de têtes d’attention qui apprennent les relations entre les mots, lui permettant de produire des résultats cohérents et contextuellement appropriés. Le processus d’entraînement est intensif en calcul, nécessitant d’énormes quantités de données et de ressources informatiques. Le réglage fin de ce modèle lui permet de se spécialiser dans des domaines plus restreints, comme le support client, la génération de contenu ou les applications médicales.
Performances sur les benchmarks
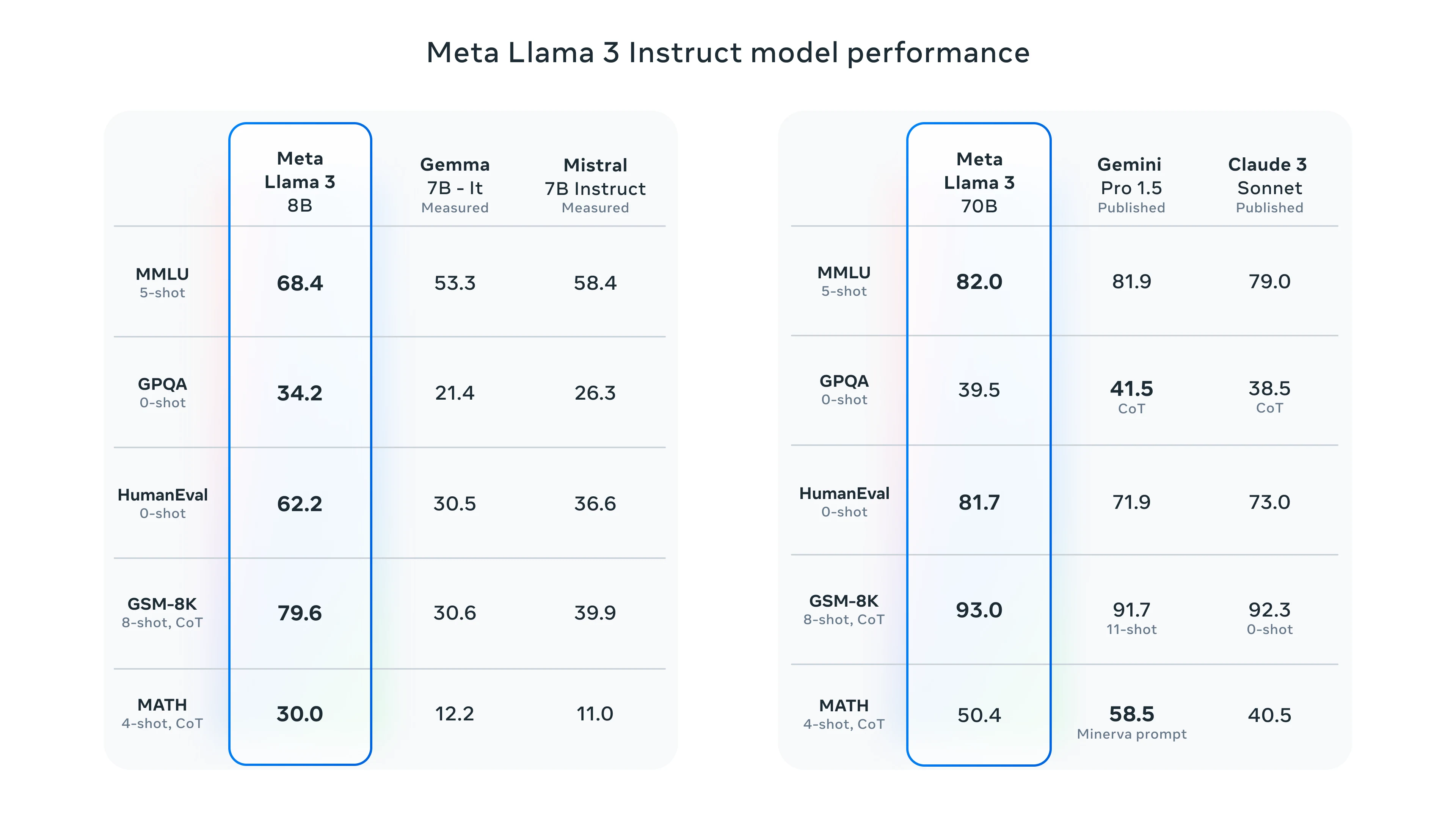
Meta a mené des évaluations approfondies de Llama 3 par rapport aux modèles leaders du secteur. Par exemple, Llama 3 a obtenu 88,6 sur le benchmark MMLU – un test complet couvrant divers sujets en mathématiques, sciences et sciences humaines – tandis que des modèles concurrents comme GPT-4 ont obtenu 88,7. De plus, sur le benchmark MATH pour les problèmes mathématiques complexes formulés en langage naturel, Llama 3 a atteint un score de 73,8, démontrant sa compétence dans les tâches de raisonnement.
Ces benchmarks illustrent la capacité de Llama 3 à être performant dans des scénarios réels et soulignent ses avancées par rapport aux itérations précédentes comme Llama 2. Les améliorations du modèle incluent un meilleur alignement avec l’intention de l’utilisateur et une réduction des taux de refus erronés, ce qui le rend plus fiable pour des applications pratiques.
L’importance du réglage fin dans les modèles d’IA
Le réglage fin est un processus critique pour adapter un modèle pré-entraîné à des tâches spécifiques et améliorer ses performances sur des données spécifiques à un domaine. En affinant un modèle comme Llama 3, vous optimisez essentiellement ses poids pour une meilleure précision, pertinence et compréhension contextuelle dans votre cas d’usage. Sans réglage fin, Llama 3 peut sous-performer dans des tâches spécialisées en raison de son entraînement sur des données générales.
Le réglage fin permet de résoudre les défis suivants :
- Spécialisation des tâches : Personnaliser Llama 3 pour des cas d’usage spécifiques (par exemple, textes juridiques ou médicaux) permet au modèle de mieux comprendre la terminologie et le contexte.
- Amélioration des performances : Le réglage fin contribue à améliorer les performances du modèle en réduisant les biais, en corrigeant les erreurs et en rendant les prédictions plus précises.
- Utilisation efficace des ressources : Le réglage fin économise des ressources informatiques en exploitant les connaissances préexistantes de Llama 3 plutôt que d’entraîner un modèle de zéro.
Préparation et réglage fin de Llama 3
Outils et ressources essentiels nécessaires
Avant de commencer le processus de réglage fin, assurez-vous de disposer des bons outils et ressources :
-
Outils logiciels :
- Hugging Face Transformers : Cette bibliothèque simplifie l’utilisation et le réglage fin de Llama 3 en fournissant des fonctions faciles à utiliser pour charger des modèles pré-entraînés et des tokenizers.
- PyTorch : Un framework d’apprentissage profond couramment utilisé pour entraîner et affiner des modèles comme Llama 3 en raison de sa flexibilité et de sa gestion efficace des modèles à grande échelle.
- TensorFlow : Bien que PyTorch soit populaire, TensorFlow peut également être utilisé pour le réglage fin de modèles dans certains cas, notamment lors de l’intégration avec d’autres outils dans des environnements de production.
-
Exigences matérielles :
- GPU : La taille de Llama 3 nécessite des ressources informatiques puissantes, généralement fournies par des GPU. Des GPU hautes performances comme NVIDIA A100 ou V100 peuvent considérablement accélérer le processus de réglage fin.
- Entraînement distribué : Pour des ensembles de données très volumineux ou des modèles extrêmement grands, vous pourriez avoir besoin de plusieurs GPU, voire d’une configuration d’entraînement distribué utilisant des outils comme DeepSpeed ou Horovod.
Configuration de votre environnement pour Llama 3
Configurer correctement votre environnement est crucial pour garantir un processus de réglage fin fluide. Voici un guide général étape par étape :
-
Créez un environnement virtuel : L’utilisation d’un environnement virtuel Python permet de gérer les dépendances sans conflits.
-
Installez les bibliothèques requises : Installez les packages nécessaires tels que Transformers, PyTorch et toute autre dépendance :
-
Téléchargez le modèle Llama 3 pré-entraîné : En utilisant la bibliothèque Hugging Face Transformers, vous pouvez facilement charger le modèle Llama 3 pré-entraîné :
Sélection du bon ensemble de données
La qualité de votre ensemble de données joue un rôle crucial dans le processus de réglage fin :
-
Pertinence : Assurez-vous que l’ensemble de données est hautement pertinent pour la tâche à accomplir. Si vous travaillez avec un générateur de textes juridiques, votre ensemble de données doit être composé de documents juridiques.
-
Taille : Un réglage fin avec un ensemble de données plus volumineux améliore généralement les performances ; cependant, assurez-vous qu’il soit géable compte tenu de vos ressources informatiques.
-
Éviter le surapprentissage : Utilisez des techniques comme l’augmentation des données (par exemple, la paraphrase) et la régularisation pour éviter le surapprentissage. Il est important que le modèle ne mémorise pas les données d’entraînement mais se généralise bien à de nouvelles entrées.
Chargement du modèle Llama 3 et du tokenizer
Le réglage fin nécessite à la fois le modèle et le tokenizer pour convertir les données textuelles dans un format que le modèle peut comprendre :
from transformers import LlamaForCausalLM, LlamaTokenizer
model = LlamaForCausalLM.from_pretrained("meta/llama-3")
tokenizer = LlamaTokenizer.from_pretrained("meta/llama-3")
Assurez-vous que le tokenizer correspond à la version de Llama 3 que vous utilisez ; une tokenisation incorrecte peut entraîner de mauvais résultats de réglage fin.
Personnalisation du modèle selon vos besoins
Un réglage fin efficace des grands modèles comme Llama 3 peut être réalisé grâce à des techniques telles que LoRA (Low-Rank Adaptation) et QLoRA (Quantized LoRA). Ces méthodes réduisent le coût computationnel de l’entraînement sans compromettre les performances du modèle, ce qui les rend idéales pour des environnements aux ressources limitées.
LoRA (Low-Rank Adaptation)
LoRA réduit le nombre de paramètres à entraîner en introduisant des matrices de bas rang au lieu de mettre à jour tous les poids du modèle. Cela permet une adaptation efficace du modèle avec beaucoup moins de ressources informatiques.
Voici un exemple de la façon d’appliquer LoRA au modèle Llama 3 en utilisant la bibliothèque peft de Hugging Face (qui fournit une interface facile pour les techniques de réglage fin économes en paramètres comme LoRA) :
- Installez la bibliothèque
peft: Assurez-vous d’abord d’installer les bibliothèques nécessaires :
pip install peft
- Chargez le modèle Llama 3 et appliquez LoRA : Voici le code pour affiner Llama 3 en utilisant LoRA :
from transformers import LlamaForCausalLM, LlamaTokenizer
from peft import LoraConfig, get_peft_model
from peft import Trainer
import torch
# Charger le modèle Llama 3 et le tokenizer
model = LlamaForCausalLM.from_pretrained("meta/llama-3")
tokenizer = LlamaTokenizer.from_pretrained("meta/llama-3")
# Définir la configuration LoRA
lora_config = LoraConfig(
r=8, # Rang de l'adaptation de bas rang
lora_alpha=32, # Facteur d'échelle
lora_dropout=0.1, # Taux de dropout
bias="none" # Si les termes de biais doivent être adaptés
)
# Appliquer LoRA au modèle
model = get_peft_model(model, lora_config)
# Déplacer le modèle sur GPU si disponible
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Préparer votre ensemble de données pour le réglage fin (par exemple, avec Hugging Face Datasets)
# dataset = ...
# Configurer les arguments d'entraînement (à ajuster selon les ressources)
training_args = {
"output_dir": "./output",
"num_train_epochs": 3,
"per_device_train_batch_size": 8,
"gradient_accumulation_steps": 2,
"learning_rate": 2e-5,
"logging_dir": "./logs",
"logging_steps": 100,
}
# Initialiser le Trainer avec les paramètres LoRA
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
)
# Affiner le modèle
trainer.train()
QLoRA (Quantized LoRA)
QLoRA optimise LoRA en ajoutant une quantification aux matrices de bas rang, ce qui réduit à la fois la taille du modèle et le coût computationnel, permettant un réglage fin plus efficace, notamment sur du matériel aux ressources limitées.
Voici comment appliquer QLoRA à Llama 3 en utilisant la bibliothèque bitsandbytes pour la quantification du modèle :
- Installez les bibliothèques nécessaires :
pip install bitsandbytes peft
- Quantifiez le modèle et appliquez LoRA :
from transformers import LlamaForCausalLM, LlamaTokenizer
from peft import LoraConfig, get_peft_model
from peft import Trainer
from bitsandbytes import load_quantized_model
import torch
# Charger le modèle Llama 3 pré-entraîné avec quantification
model = load_quantized_model("meta/llama-3", load_in_4bit=True) # Chargement du modèle avec quantification 4 bits
# Définir la configuration LoRA (identique à précédemment)
lora_config = LoraConfig(
r=8, # Rang de l'adaptation de bas rang
lora_alpha=32,
lora_dropout=0.1,
bias="none"
)
# Appliquer LoRA au modèle
model = get_peft_model(model, lora_config)
# Déplacer le modèle sur GPU si disponible
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Préparer votre ensemble de données pour le réglage fin (par exemple, avec Hugging Face Datasets)
# dataset = ...
# Configurer les arguments d'entraînement
training_args = {
"output_dir": "./output",
"num_train_epochs": 3,
"per_device_train_batch_size": 8,
"gradient_accumulation_steps": 2,
"learning_rate": 2e-5,
"logging_dir": "./logs",
"logging_steps": 100,
}
# Initialiser le Trainer avec LoRA et les paramètres de quantification
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
)
# Affiner le modèle
trainer.train()
En utilisant QLoRA, vous bénéficiez d’une taille de modèle réduite et d’une utilisation mémoire moindre, tout en maintenant les performances grâce aux techniques de quantification.
Entraînement du modèle
Une fois que vous avez configuré le modèle avec LoRA ou QLoRA, vous pouvez commencer le processus de réglage fin. Voici les paramètres clés à prendre en compte lors de l’entraînement du modèle :
- Taux d’apprentissage :
- Un taux d’apprentissage faible est important pour éviter de dépasser la solution optimale. Une valeur de
2e-5est couramment utilisée pour le réglage fin des grands modèles, mais vous devez surveiller le processus d’entraînement et l’ajuster si nécessaire.
- Un taux d’apprentissage faible est important pour éviter de dépasser la solution optimale. Une valeur de
- Taille de lot :
- La taille de lot dépend de la mémoire disponible de votre GPU. Des tailles de lot plus grandes accélèrent l’entraînement mais nécessitent plus de mémoire GPU. Si vous travaillez avec une mémoire GPU limitée, vous pouvez réduire la taille de lot ou utiliser l’accumulation de gradient pour simuler une taille de lot plus grande.
- Époques :
- Le réglage fin nécessite généralement 3 à 5 époques. Un plus grand nombre d’époques peut entraîner un surapprentissage, surtout sur de petits ensembles de données. Il est essentiel de surveiller les performances du modèle sur un ensemble de validation pour décider quand arrêter.
Voici comment définir ces paramètres dans l’API Trainer :
training_args = {
"output_dir": "./output",
"num_train_epochs": 3,
"per_device_train_batch_size": 8, # Ajustez en fonction de la mémoire de votre GPU
"gradient_accumulation_steps": 2, # Accumuler les gradients sur plusieurs étapes pour simuler une taille de lot plus grande
"learning_rate": 2e-5, # Taux d'apprentissage faible pour le réglage fin
"logging_dir": "./logs",
"logging_steps": 100,
}
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
)
trainer.train()
Cette configuration garantit que le modèle est entraîné avec les bons paramètres pour obtenir les meilleures performances possibles.
Évaluation des performances du modèle
Après l’entraînement, il est crucial d’évaluer les performances de votre modèle à l’aide d’un ensemble de validation :
- Validation croisée : Divisez votre ensemble de données en sous-ensembles d’entraînement et de validation pour obtenir de meilleures informations sur les performances du modèle.
- Réglage des hyperparamètres : Ajustez les taux d’apprentissage, les tailles de lot ou les architectures en fonction des résultats de validation pour améliorer les performances.
Résolution des problèmes courants lors du réglage fin
Surmonter le surapprentissage des données
Le surapprentissage se produit lorsque le modèle devient trop spécialisé dans les données d’entraînement :
- Utilisez des techniques d’augmentation des données (par exemple, la paraphrase) pour augmenter la variété.
- Appliquez le dropout et la décroissance du poids comme techniques de régularisation.
Gérer la sous-performance du modèle
Si votre modèle sous-performe :
- Augmentez la taille de l’ensemble de données : des ensembles de données plus diversifiés améliorent souvent la généralisation.
- Ajustez les hyperparamètres : Modifiez les taux d’apprentissage, les tailles de lot et les époques selon les besoins.
Tirer parti des GPU Novita AI pour exécuter des modèles affinés
Lors du réglage fin de modèles à grande échelle comme Llama 3, une gestion efficace des ressources est essentielle. Novita AI répond à ces défis avec des solutions GPU serverless qui permettent aux développeurs de se concentrer sur l’optimisation des modèles plutôt que sur la gestion du matériel.
Pourquoi les GPU Novita AI sont idéaux pour exécuter des modèles affinés
- GPU serverless : La solution serverless de Novita AI met automatiquement à l’échelle les ressources GPU en fonction de la charge de travail, éliminant ainsi la gestion manuelle de l’infrastructure.
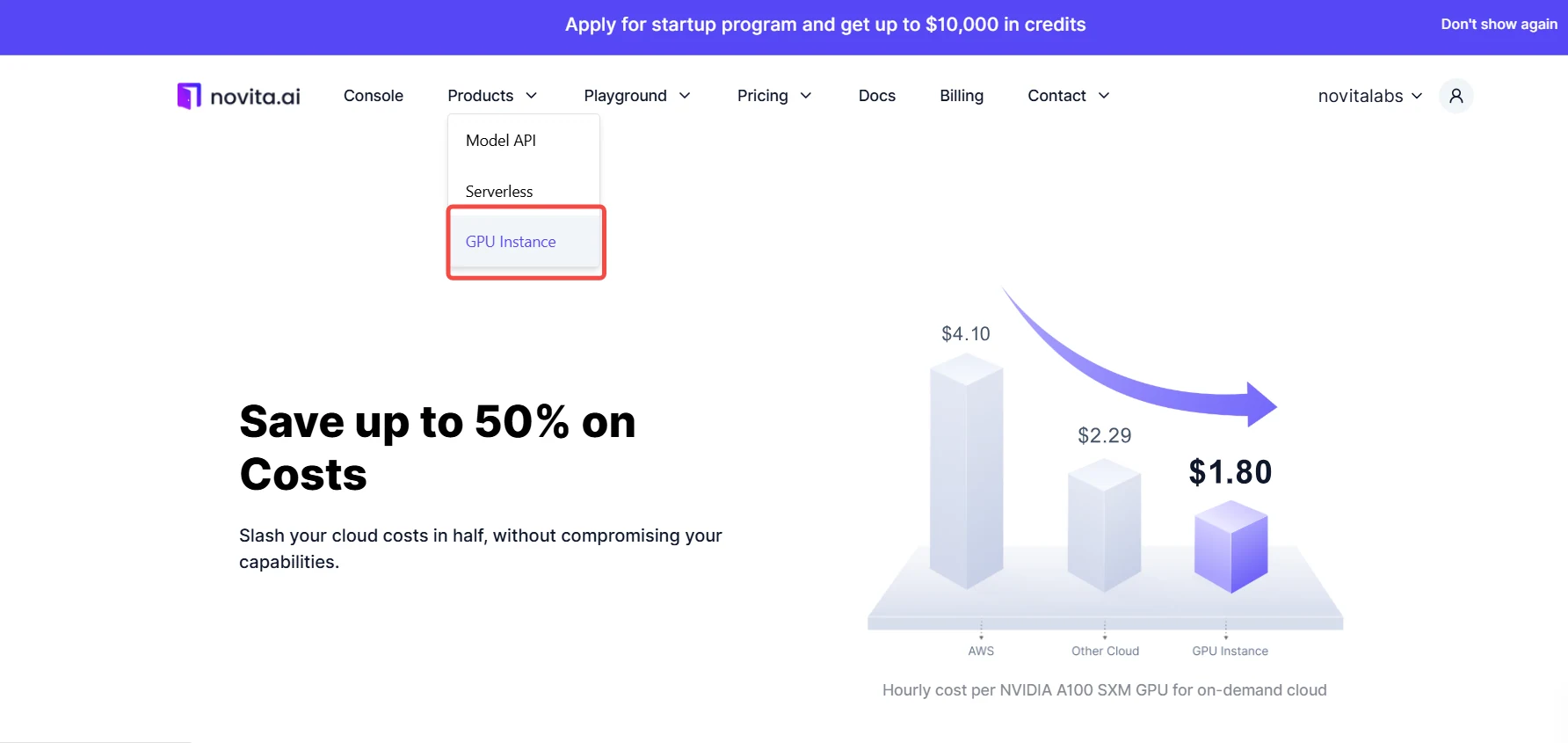
- Instances GPU économiques : Des instances GPU hautes performances sont disponibles à une fraction du coût des services cloud traditionnels, avec un modèle de paiement à l’utilisation qui peut réduire les dépenses jusqu’à 50 %.
- Processus de déploiement simplifié : Novita AI propose des workflows de déploiement simplifiés pour les projets de réglage fin, permettant aux entreprises de faire évoluer leurs initiatives IA sans expertise approfondie en infrastructure.
Conclusion
Le réglage fin de Llama 3 pour des performances optimales nécessite une approche réfléchie – de la configuration de votre environnement à la sélection d’ensembles de données adaptés et à la personnalisation des modèles. En suivant les bonnes pratiques telles que l’utilisation de techniques comme LoRA et QLoRA, tout en tirant parti de solutions d’infrastructure évolutives comme Novita AI, vous pouvez adapter efficacement Llama 3 à des applications spécifiques.
1. Peut-on affiner Llama 3 ?
Oui, Llama 3 peut être affiné.
2. Comment affiner un modèle Llama ?
Le réglage fin consiste à entraîner le modèle Llama pré-entraîné sur un ensemble de données spécifique en utilisant des frameworks comme Hugging Face.
3. Le réglage fin améliore-t-il la précision ?
Oui, le réglage fin peut améliorer la précision pour des tâches ou des domaines spécifiques.
4. Combien d’époques pour affiner un Llama ?
Généralement, 3 à 5 époques suffisent, selon l’ensemble de données.
5. Quelle est la différence entre le réglage fin et RAG ?
Le réglage fin ajuste un modèle pour une tâche, tandis que RAG utilise la récupération externe de documents pour apporter du contexte lors de la génération.
Lectures recommandées
- Guide rapide et facile pour le réglage fin de Llama
- Comment utiliser Llama 3 8B Instruct et ajuster la température pour des résultats optimaux ?
- Débloquer le chat zero-shot de Llama 3–8b : astuces et techniques d’experts
Novita AI est la plateforme cloud tout-en-un qui donne vie à vos ambitions IA. APIs intégrées, serverless, instances GPU — les outils économiques dont vous avez besoin. Supprimez l’infrastructure, commencez gratuitement, et faites de votre vision IA une réalité.



