

Principais Destaques
- Introdução ao Llama3: O Llama3 é um modelo de linguagem de última geração desenvolvido pela Meta, projetado para alto desempenho em tarefas de processamento de linguagem natural. O fine-tuning deste modelo pode melhorar significativamente suas capacidades para aplicações específicas.
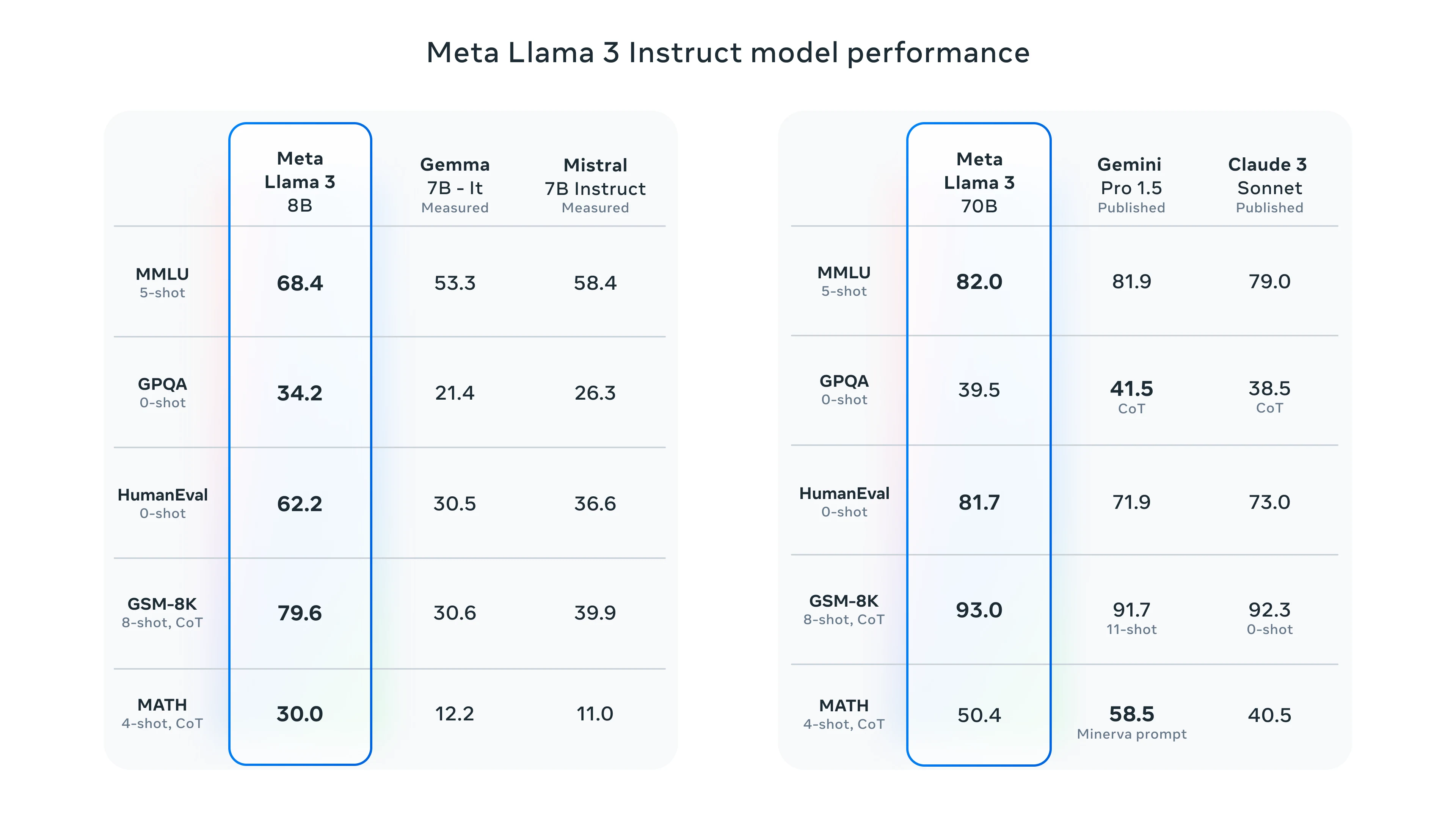
- O Llama3 alcançou pontuações competitivas em vários benchmarks, como MMLU e MATH, demonstrando sua eficácia em tarefas de raciocínio e aplicações específicas de domínio.
- O fine-tuning permite que o Llama3 seja personalizado para tarefas específicas, melhorando a precisão e relevância enquanto otimiza o uso de recursos.
- Ferramentas essenciais para fine-tuning incluem Hugging Face Transformers, PyTorch e GPUs de alto desempenho. A configuração adequada é crucial para um fine-tuning bem-sucedido.
- O processo de treinamento envolve definir taxas de aprendizado, tamanhos de lote e épocas, com estratégias para avaliar o desempenho do modelo e solucionar problemas como overfitting.
- A Novita AI oferece soluções de GPU serverless que simplificam o gerenciamento de recursos durante o processo de fine-tuning, facilitando que os desenvolvedores foquem na otimização.
O fine-tuning de modelos de linguagem em larga escala como o Llama3 é essencial para personalizar modelos pré-treinados para melhor se adequarem a tarefas ou conjuntos de dados específicos. Desenvolvido pela Meta, o Llama3 representa um avanço significativo no processamento de linguagem natural, com capacidades que rivalizam com alguns dos modelos mais poderosos do mercado. A arquitetura e metodologias de treinamento do modelo foram projetadas para otimizar o desempenho em uma ampla gama de aplicações, tornando-o uma ferramenta versátil para desenvolvedores.
Benchmarks recentes indicam que o Llama3 supera todos os modelos abertos de última geração dentro de sua classe de parâmetros em métricas de avaliação padrão, como MedQA e MMLU. Esse desempenho é atribuído ao extenso pré-treinamento em conjuntos de dados diversos, que melhora sua compreensão do contexto e nuances da linguagem. O fine-tuning eficaz do Llama3 pode desbloquear suas verdadeiras capacidades, permitindo que organizações adaptem o modelo para casos de uso específicos, como suporte ao cliente, geração de conteúdo ou domínios especializados, como aplicações médicas e jurídicas.
Este guia fornece uma abordagem abrangente passo a passo para ajudá-lo a otimizar o Llama3 para seu caso de uso, desde a configuração do ambiente até a solução de problemas comuns durante o fine-tuning.
Entendendo o Básico do Llama3
O que é o Llama3 e Como Funciona?
O Llama3 é um modelo de linguagem de última geração desenvolvido pela Meta que se destaca na compreensão e geração de texto semelhante ao humano. Ele é construído sobre uma arquitetura Transformer, que permite processar e gerar linguagem natural de forma eficiente. Assim como outros grandes modelos, como o GPT-3, o Llama3 é pré-treinado em vastos conjuntos de dados — mais de 15 trilhões de tokens — o que permite entender uma ampla gama de tarefas.
A arquitetura consiste em múltiplas camadas de cabeças de atenção que aprendem relações entre palavras, permitindo produzir saídas coerentes e contextualmente apropriadas. O processo de treinamento é computacionalmente intensivo, exigindo grandes quantidades de dados e recursos computacionais. O fine-tuning deste modelo permite que ele se especialize em domínios mais restritos, como suporte ao cliente, geração de conteúdo ou aplicações médicas.
Desempenho em Benchmarks
A Meta realizou extensas avaliações do Llama3 em comparação com modelos líderes na área. Por exemplo, o Llama3 obteve 88,6 no benchmark MMLU — um teste abrangente que cobre vários assuntos de matemática, ciências e humanidades — enquanto modelos concorrentes como o GPT-4 obtiveram 88,7. Além disso, no benchmark MATH para problemas matemáticos complexos, o Llama3 alcançou 73,8, demonstrando sua proficiência em tarefas de raciocínio.
Esses benchmarks ilustram a capacidade do Llama3 de competir em cenários do mundo real e destacam seus avanços em relação a iterações anteriores, como o Llama2. As melhorias do modelo incluem um alinhamento aprimorado com a intenção do usuário e taxas reduzidas de falsas recusas, tornando-o mais confiável para aplicações práticas.
A Importância do Fine-Tuning em Modelos de IA
O fine-tuning é um processo crítico para adaptar um modelo pré-treinado a tarefas específicas e melhorar seu desempenho em dados específicos de domínio. Ao realizar o fine-tuning de um modelo como o Llama3, você está essencialmente otimizando seus pesos para obter melhor precisão, relevância e compreensão contextual no seu caso de uso. Sem o fine-tuning, o Llama3 pode ter um desempenho inferior em tarefas especializadas devido ao seu treinamento em dados gerais.
O fine-tuning ajuda a enfrentar os seguintes desafios:
- Especialização em Tarefas: Personalizar o Llama3 para casos de uso específicos (por exemplo, textos jurídicos ou médicos) permite que o modelo compreenda melhor a terminologia e o contexto.
- Melhoria de Desempenho: O fine-tuning ajuda a melhorar o desempenho do modelo, reduzindo vieses, corrigindo erros e tornando as previsões mais precisas.
- Uso Eficiente de Recursos: O fine-tuning economiza recursos computacionais ao aproveitar o conhecimento pré-existente no Llama3, em vez de treinar um modelo do zero.
Preparação e Fine-Tuning do Llama3
Ferramentas e Recursos Essenciais Necessários
Antes de iniciar o processo de fine-tuning, certifique-se de ter as ferramentas e recursos corretos:
-
Ferramentas de Software:
- Hugging Face Transformers: Esta biblioteca simplifica o uso e o fine-tuning do Llama3, fornecendo funções fáceis de usar para carregar modelos pré-treinados e tokenizadores.
- PyTorch: Um framework de aprendizado profundo comumente usado para treinar e ajustar modelos como o Llama3 devido à sua flexibilidade e manipulação eficiente de modelos em larga escala.
- TensorFlow: Embora o PyTorch seja popular, o TensorFlow também pode ser usado para fine-tuning de modelos em alguns casos, especialmente quando integrado a outras ferramentas em ambientes de produção.
-
Requisitos de Hardware:
- GPUs: O tamanho do Llama3 exige recursos computacionais poderosos, geralmente fornecidos por GPUs. GPUs de alto desempenho, como NVIDIA A100 ou V100, podem acelerar significativamente o processo de fine-tuning.
- Treinamento Distribuído: Para conjuntos de dados muito grandes ou modelos extremamente grandes, você pode precisar de várias GPUs ou até mesmo de uma configuração de treinamento distribuído usando ferramentas como DeepSpeed ou Horovod.
Configurando seu Ambiente para o Llama3
Configurar seu ambiente corretamente é crucial para garantir um processo de fine-tuning suave. Aqui está um guia geral passo a passo:
-
Crie um Ambiente Virtual: Usar o ambiente virtual do Python ajuda a gerenciar dependências sem conflitos.
-
Instale as Bibliotecas Necessárias: Instale pacotes necessários como Transformers, PyTorch e quaisquer outras dependências:
-
Baixe o Modelo Llama3 Pré-treinado: Usando a biblioteca Transformers do Hugging Face, você pode carregar facilmente o modelo Llama3 pré-treinado:
Selecionando o Conjunto de Dados Adequado
A qualidade do seu conjunto de dados desempenha um papel crucial no processo de fine-tuning:
-
Relevância: Certifique-se de que o conjunto de dados seja altamente relevante para a tarefa em questão. Se você estiver trabalhando com um gerador de texto jurídico, seu conjunto de dados deve consistir em documentos jurídicos.
-
Tamanho: O fine-tuning com um conjunto de dados maior geralmente melhora o desempenho; no entanto, certifique-se de que seja gerenciável com seus recursos computacionais.
-
Evitando Overfitting: Use técnicas como aumento de dados (por exemplo, paráfrase) e regularização para evitar overfitting. É importante que o modelo não memorize os dados de treinamento, mas generalize bem para novas entradas.
Carregando o Modelo e Tokenizador Llama3
O fine-tuning requer tanto o modelo quanto o tokenizador para converter dados de texto em um formato que o modelo possa entender:
from transformers import LlamaForCausalLM, LlamaTokenizer
model = LlamaForCausalLM.from_pretrained("meta/llama-3")
tokenizer = LlamaTokenizer.from_pretrained("meta/llama-3")
Certifique-se de que o tokenizador corresponda à versão do Llama3 que você está usando; tokenização incorreta pode levar a resultados ruins de fine-tuning.
Personalizando o Modelo para Suas Necessidades
O fine-tuning eficiente de modelos grandes como o Llama3 pode ser alcançado usando técnicas como LoRA (Adaptação de Baixo Ranque) e QLoRA (LoRA Quantizado). Esses métodos reduzem o custo computacional do treinamento sem comprometer o desempenho do modelo, tornando-os ideais para ambientes com recursos limitados.
LoRA (Low-Rank Adaptation)
O LoRA reduz o número de parâmetros a serem treinados introduzindo matrizes de baixo ranque em vez de atualizar todos os pesos do modelo. Isso permite uma adaptação eficiente do modelo com recursos computacionais significativamente menores.
Aqui está um exemplo de como você pode aplicar LoRA ao modelo Llama3 usando a biblioteca peft do Hugging Face (que fornece uma interface fácil para técnicas de fine-tuning eficientes em parâmetros, como LoRA):
- Instale a biblioteca
peft: Primeiro, certifique-se de instalar as bibliotecas necessárias:
pip install peft
- Carregue o modelo Llama3 e aplique LoRA: Abaixo está o código para ajustar o Llama3 usando LoRA:
from transformers import LlamaForCausalLM, LlamaTokenizer
from peft import LoraConfig, get_peft_model
from peft import Trainer
import torch
# Carregar modelo e tokenizador Llama3
model = LlamaForCausalLM.from_pretrained("meta/llama-3")
tokenizer = LlamaTokenizer.from_pretrained("meta/llama-3")
# Definir configuração LoRA
lora_config = LoraConfig(
r=8, # Ranque da adaptação de baixo ranque
lora_alpha=32, # Fator de escala
lora_dropout=0.1, # Taxa de dropout
bias="none" # Se deve adaptar termos de viés
)
# Aplicar LoRA ao modelo
model = get_peft_model(model, lora_config)
# Mover o modelo para GPU se disponível
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Preparar seu conjunto de dados para fine-tuning (ex.: usando Datasets do Hugging Face)
# dataset = ...
# Configurar argumentos de treinamento (isso pode ser ajustado com base nos recursos)
training_args = {
"output_dir": "./output",
"num_train_epochs": 3,
"per_device_train_batch_size": 8,
"gradient_accumulation_steps": 2,
"learning_rate": 2e-5,
"logging_dir": "./logs",
"logging_steps": 100,
}
# Inicializar o Trainer com parâmetros LoRA
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
)
# Ajustar o modelo
trainer.train()
QLoRA (Quantized LoRA)
O QLoRA otimiza o LoRA adicionando quantização às matrizes de baixo ranque, o que reduz tanto o tamanho do modelo quanto o custo computacional, permitindo um fine-tuning mais eficiente, especialmente em hardware limitado.
Aqui está como você pode aplicar QLoRA ao Llama3 usando a biblioteca bitsandbytes para quantização de modelo:
- Instale as bibliotecas necessárias:
pip install bitsandbytes peft
- Quantize o modelo e aplique LoRA:
from transformers import LlamaForCausalLM, LlamaTokenizer
from peft import LoraConfig, get_peft_model
from peft import Trainer
from bitsandbytes import load_quantized_model
import torch
# Carregar o modelo Llama3 pré-treinado com quantização
model = load_quantized_model("meta/llama-3", load_in_4bit=True) # Carregar modelo com quantização de 4 bits
# Definir configuração LoRA (igual ao anterior)
lora_config = LoraConfig(
r=8, # Ranque da adaptação de baixo ranque
lora_alpha=32,
lora_dropout=0.1,
bias="none"
)
# Aplicar LoRA ao modelo
model = get_peft_model(model, lora_config)
# Mover o modelo para GPU se disponível
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Preparar seu conjunto de dados para fine-tuning (ex.: usando Datasets do Hugging Face)
# dataset = ...
# Configurar argumentos de treinamento
training_args = {
"output_dir": "./output",
"num_train_epochs": 3,
"per_device_train_batch_size": 8,
"gradient_accumulation_steps": 2,
"learning_rate": 2e-5,
"logging_dir": "./logs",
"logging_steps": 100,
}
# Inicializar o Trainer com LoRA e parâmetros de quantização
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
)
# Ajustar o modelo
trainer.train()
Ao usar QLoRA, você pode se beneficiar de um tamanho de modelo menor e menor uso de memória, mantendo o desempenho do modelo por meio de técnicas de quantização.
Treinando o Modelo
Depois de configurar o modelo com LoRA ou QLoRA, você pode iniciar o processo de fine-tuning. Abaixo estão os principais parâmetros a considerar ao treinar o modelo:
- Taxa de Aprendizado:
- Uma taxa de aprendizado pequena é importante para evitar ultrapassar a solução ótima. Um valor de
2e-5é comumente usado para fine-tuning de modelos grandes, mas você deve monitorar o processo de treinamento e ajustar se necessário.
- Uma taxa de aprendizado pequena é importante para evitar ultrapassar a solução ótima. Um valor de
- Tamanho do Lote:
- O tamanho do lote depende da memória disponível da sua GPU. Tamanhos de lote maiores aceleram o treinamento, mas exigem mais memória GPU. Se você estiver trabalhando com memória GPU limitada, pode reduzir o tamanho do lote ou usar acumulação de gradientes para simular um tamanho de lote maior.
- Épocas:
- O fine-tuning normalmente requer de 3 a 5 épocas. Mais épocas podem levar a overfitting, especialmente em conjuntos de dados pequenos. É essencial monitorar o desempenho do modelo em um conjunto de validação para decidir quando parar.
Aqui está como definir esses parâmetros na API Trainer:
training_args = {
"output_dir": "./output",
"num_train_epochs": 3,
"per_device_train_batch_size": 8, # Ajuste com base na sua memória GPU
"gradient_accumulation_steps": 2, # Acumular gradientes em múltiplos passos para simular lote maior
"learning_rate": 2e-5, # Taxa de aprendizado pequena para fine-tuning
"logging_dir": "./logs",
"logging_steps": 100,
}
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
)
trainer.train()
Esta configuração garante que o modelo seja treinado com os parâmetros corretos para obter o melhor desempenho possível.
Avaliando o Desempenho do Modelo
Após o treinamento, é crucial avaliar o desempenho do seu modelo usando um conjunto de dados de validação:
-
Validação Cruzada: Divida seu conjunto de dados em subconjuntos de treinamento e validação para obter melhores insights sobre o desempenho do modelo.
-
Ajuste de Hiperparâmetros: Ajuste as taxas de aprendizado, tamanhos de lote ou arquiteturas com base nos resultados da validação para melhorar o desempenho.
Solucionando Problemas Comuns Durante o Fine-Tuning
Superando o Overfitting dos Dados
O overfitting ocorre quando o modelo se torna muito especializado nos dados de treinamento:
- Use técnicas de aumento de dados (por exemplo, paráfrase) para aumentar a variedade.
- Aplique dropout e decaimento de peso como técnicas de regularização.
Lidando com o Baixo Desempenho do Modelo
Se o seu modelo apresentar baixo desempenho:
- Aumente o tamanho do conjunto de dados: Conjuntos de dados mais diversos geralmente melhoram a generalização.
- Ajuste Hiperparâmetros: Altere as taxas de aprendizado, tamanhos de lote e épocas conforme necessário.
Aproveitando as GPUs da Novita AI para Executar Modelos Ajustados
Ao ajustar modelos em larga escala como o Llama3, o gerenciamento eficiente de recursos é fundamental. A Novita AI aborda esses desafios com soluções de GPU serverless que permitem que os desenvolvedores se concentrem na otimização dos modelos, em vez de gerenciar hardware.
Por que as GPUs da Novita AI São Ideais para Executar Modelos Ajustados
- GPU Serverless: A solução serverless da Novita AI escala automaticamente os recursos de GPU de acordo com a demanda da carga de trabalho, eliminando o gerenciamento manual de infraestrutura.
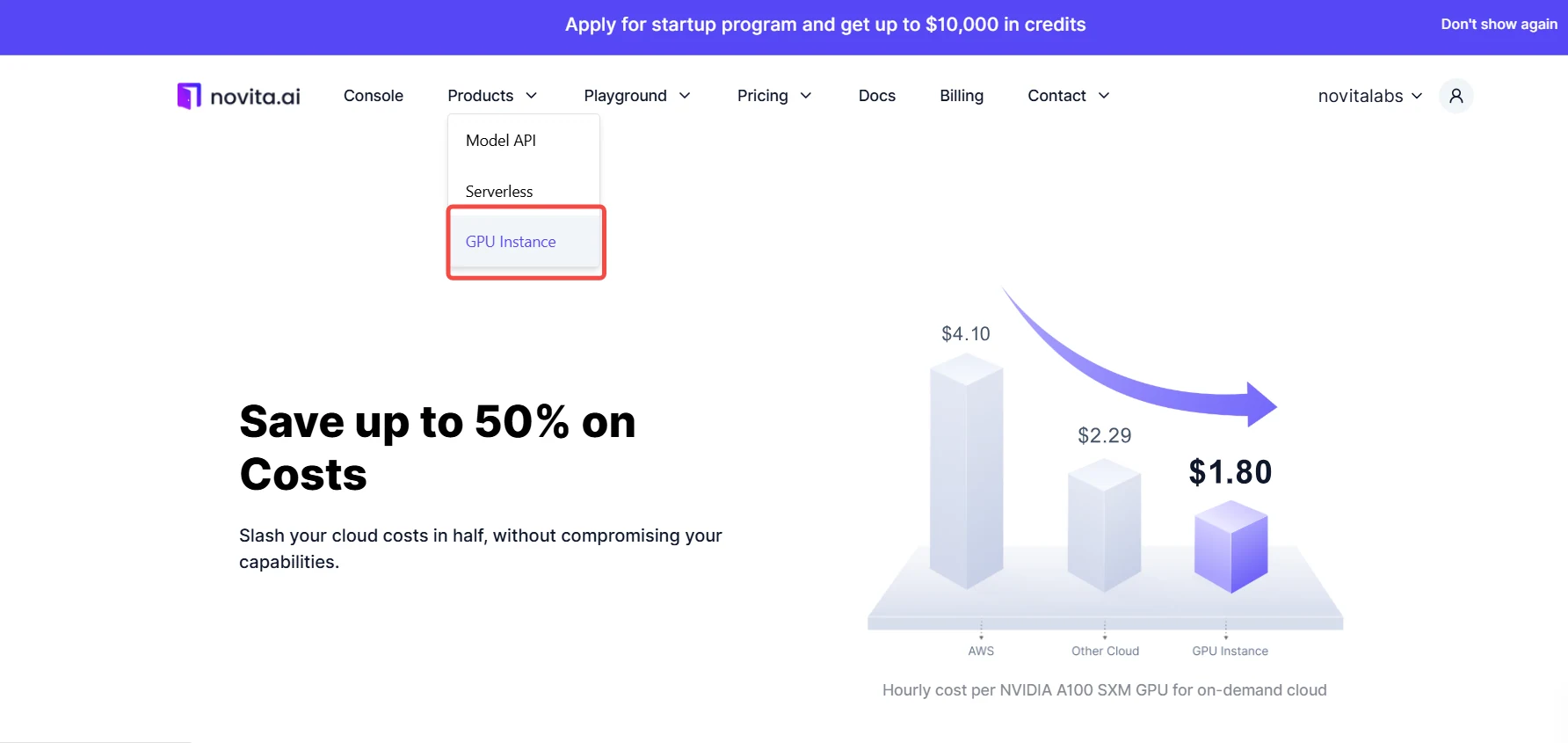
- Instâncias de GPU Custo-Efetivas: Instâncias de GPU de alto desempenho estão disponíveis por uma fração do custo dos serviços tradicionais de nuvem, com um modelo de pagamento conforme o uso que pode reduzir despesas em até 50%.
- Processo de Implantação Simplificado: A Novita AI fornece fluxos de trabalho de implantação simplificados para projetos de fine-tuning, permitindo que empresas dimensionem suas iniciativas de IA sem necessidade de profundo conhecimento em infraestrutura.
Conclusão
O fine-tuning do Llama3 para desempenho ideal requer uma abordagem cuidadosa — desde a configuração do ambiente até a seleção de conjuntos de dados adequados e personalização de modelos. Seguindo as melhores práticas, como usar técnicas como LoRA e QLoRA, enquanto aproveita soluções de infraestrutura escaláveis como a Novita AI, você pode adaptar efetivamente o Llama3 para aplicações específicas.
1.O Llama 3 pode ser ajustado (fine-tuned)?
Sim, o Llama 3 pode ser ajustado.
Como ajustar um modelo Llama?
O ajuste envolve treinar o modelo Llama pré-treinado em um conjunto de dados específico usando frameworks como Hugging Face.
O fine-tuning melhora a precisão?
O fine-tuning pode melhorar a precisão para tarefas ou domínios específicos.
Quantas épocas para ajustar um Llama?
Normalmente, de 3 a 5 épocas são suficientes, dependendo do conjunto de dados.
Qual é a diferença entre fine-tuning e RAG?
O fine-tuning ajusta um modelo para uma tarefa, enquanto o RAG usa recuperação de documentos externos para contexto durante a geração.
Leitura Recomendada
- Guia Rápido e Fácil para Fine-Tuning do Llama
- Como Usar o Llama 3 8B Instruct e Ajustar a Temperatura para Resultados Ótimos?
- Desbloqueie o Llama 3–8b Zero-Shot Chat: Dicas e Técnicas de Especialistas
Novita AI é a plataforma completa em nuvem que impulsiona suas ambições de IA. APIs integradas, serverless, instância GPU — as ferramentas custo-efetivas que você precisa. Elimine infraestrutura, comece gratuitamente e torne sua visão de IA realidade.



