

GLM-4.6 représente une avancée majeure par rapport à GLM-4.5 : contexte plus étendu, raisonnement plus intelligent, efficacité accrue. Mais de nombreux utilisateurs se posent encore la question : comment y accéder et l’utiliser concrètement ?
Ce guide présente les méthodes les plus simples et les plus efficaces pour débloquer toute la puissance de GLM-4.6.
GLM-4.6 vs GLM-4.5 : Quoi de neuf ?
Fenêtre de contexte plus étendue que GLM 4.5
GLM-4.6 (Reasoning) marque une étape majeure par rapport à GLM-4.5. Il étend la fenêtre de contexte de 128K à 200K tokens pour des tâches plus complexes et multi-étapes.
| Métrique | GLM-4.6 (Reasoning) | GLM-4.5 (Reasoning) |
|---|---|---|
| Fenêtre de contexte | 200 000 tokens (≈ 300 pages A4, police Arial 12 pt) | 128 000 tokens (≈ 192 pages A4, police Arial 12 pt) |
| Date de sortie | Septembre 2025 | Juillet 2025 |
| Paramètres | 357 milliards au total, 32 milliards actifs lors de l’inférence | 355 milliards au total, 32 milliards actifs lors de l’inférence |
Efficacité d’utilisation des tokens supérieure à GLM 4.5
Bien que GLM-4.6 étende considérablement sa fenêtre de contexte à 200K tokens, il améliore simultanément son efficacité : il utilise en moyenne plus de 30 % de tokens en moins que GLM-4.5, et atteint le taux de consommation le plus bas parmi les modèles comparables. Cela signifie que des entrées plus longues n’entraînent plus de coût de calcul plus élevé.
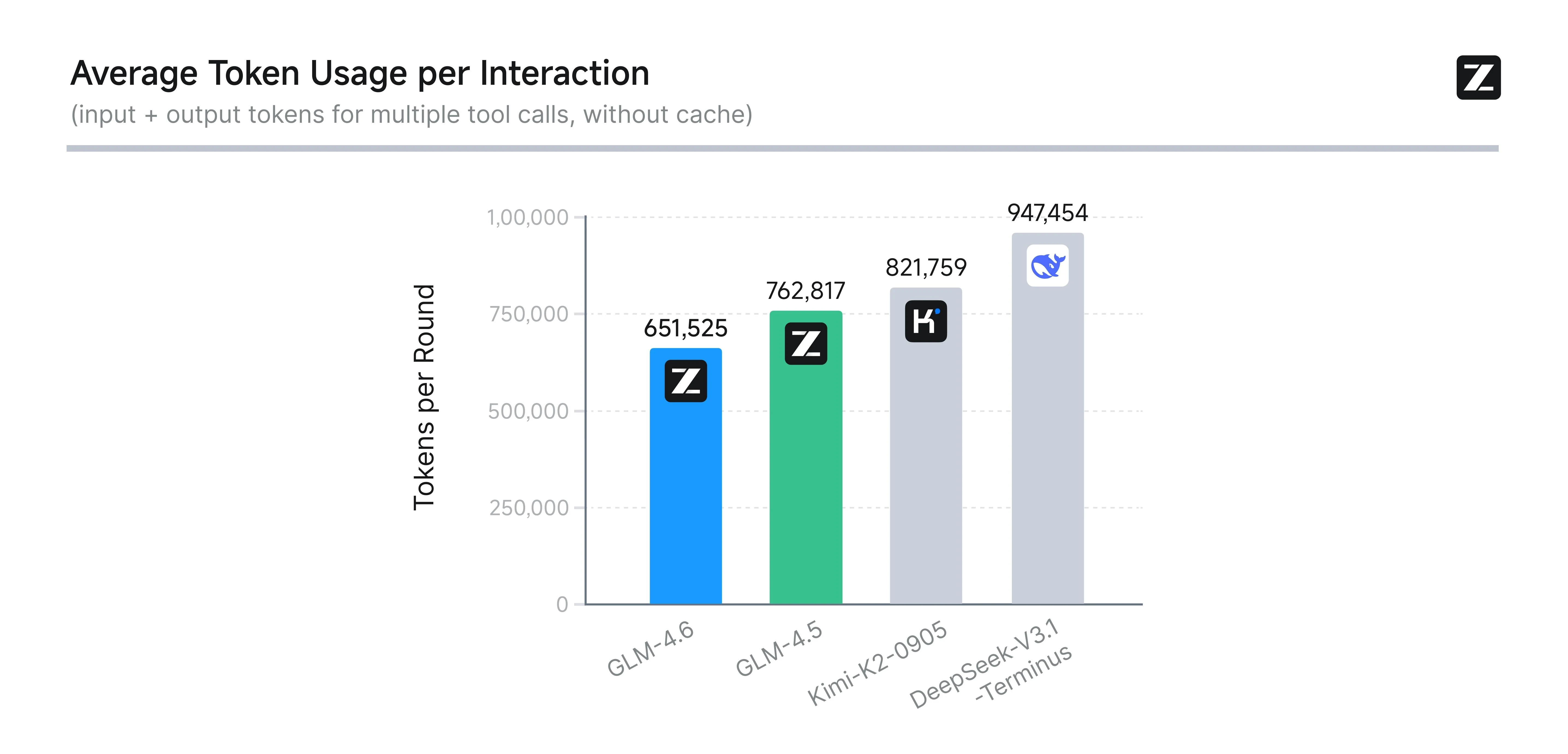
Source : Z.AI
Capacités de code, de raisonnement et d’agent supérieures à GLM 4.5
Il offre également des capacités de codage plus performantes dans des environnements réels comme Claude Code et Roo Code ; et affiche des gains clairs en matière de raisonnement grâce à l’utilisation d’outils intégrés. Le modèle alimente également des agents plus performants et génère des textes plus fluides et plus naturels, à la fois plus intelligents sur le plan logique et plus naturels dans leur expression.
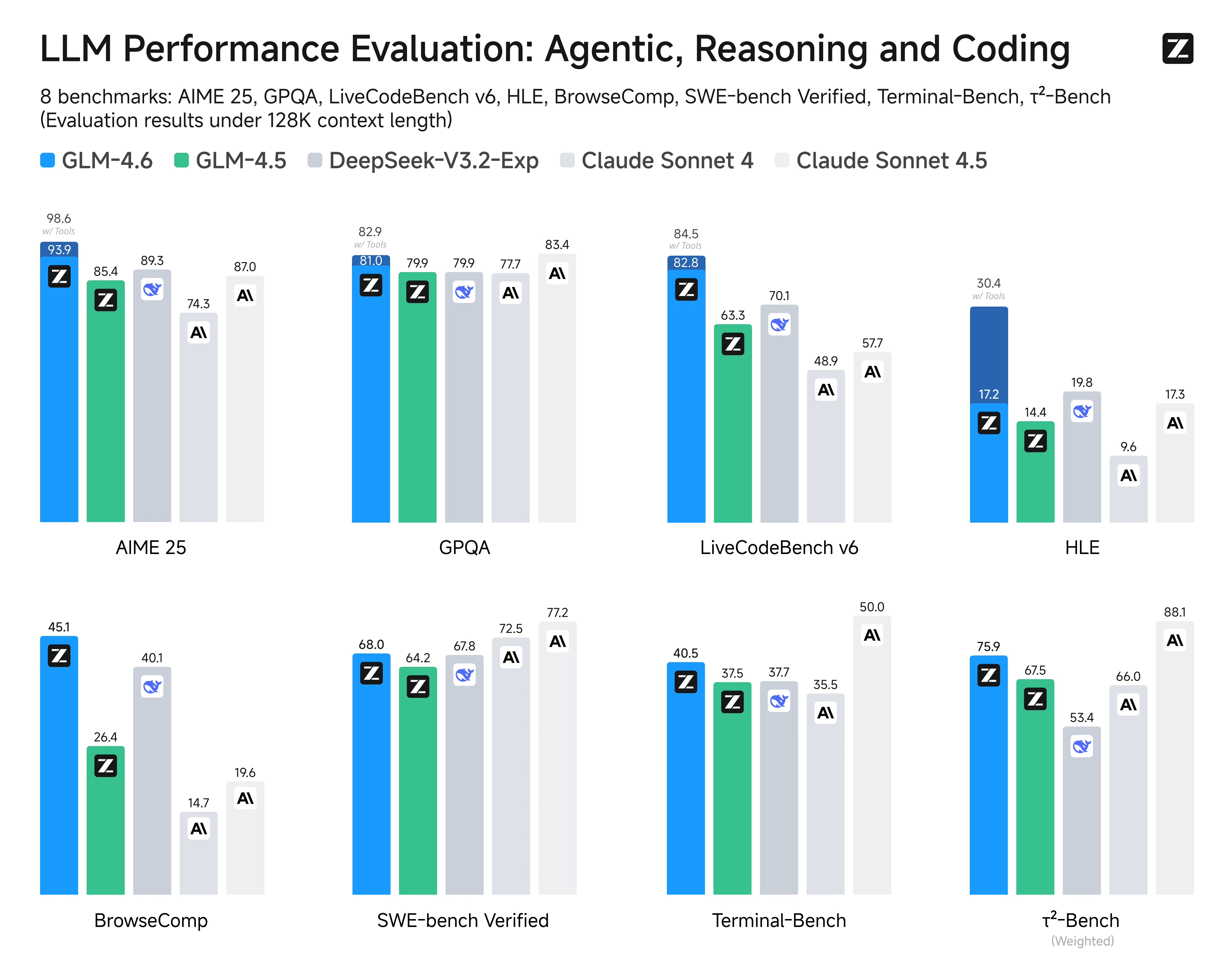
Source : Z.AI
Que pouvez-vous faire avec GLM-4.6 ?
1. Codage assisté par IA
Générez une application web de liste de tâches en une seule page en utilisant HTML, CSS et JavaScript (sans framework). Elle doit permettre d’ajouter des tâches, de les marquer comme terminées, de les supprimer et de les conserver dans le localStorage du navigateur. Ajoutez également des commentaires dans le code et un court README expliquant comment l’exécuter.
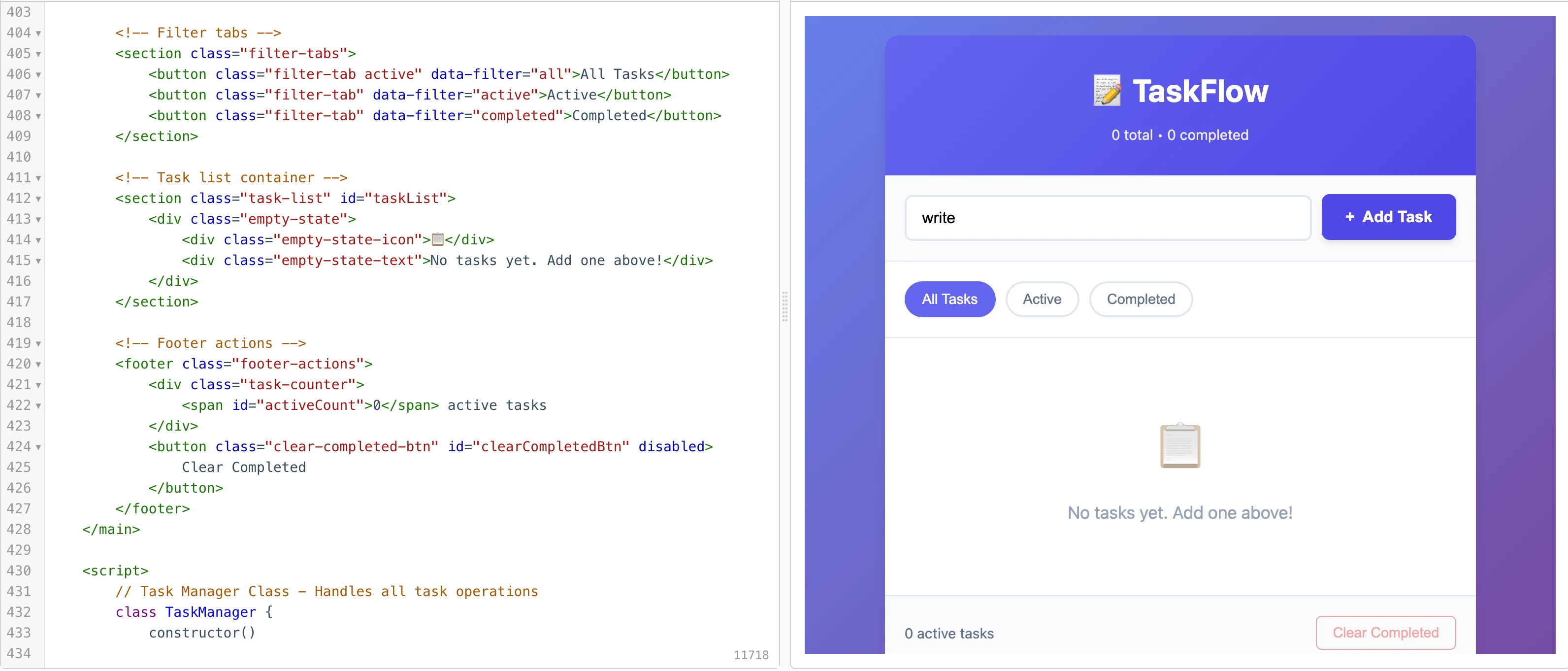
2. Agent intelligent
Vous êtes un agent capable d’effectuer des recherches web pendant l’inférence. Recherchez les derniers benchmarks IA de 2025, comparez GPT-4, GLM-4.6 et Claude, et générez un tableau récapitulatif avec des citations de sources.
Essayez GLM 4.6 dès maintenant !
3. Création de contenu / jeu de rôle
Vous êtes un explorateur du XIXe siècle qui écrit un journal. Décrivez votre voyage à travers une jungle inexplorée en utilisant un langage sensoriel vivant et un ton historique.
Essayez GLM 4.6 dès maintenant !
4. Automatisation des tâches bureautiques (PPT / rapport / mise en page)
Produisez un plan d’une diapositive PowerPoint pour un pitch de startup. Pour chaque diapositive, donnez un titre, trois points clés et des suggestions d’éléments visuels ou de graphiques.

Comment accéder à GLM 4.6 ?
GLM 4.6 propose plusieurs méthodes d’accès pour répondre aux besoins des différents utilisateurs et aux exigences techniques.
Le site officiel utilise actuellement un modèle d’abonnement mensuel. Si vous souhaitez simplement l’utiliser de manière pratique plutôt que de payer pour du temps inutilisé, vous pouvez essayer Novita AI, qui propose des tarifs plus bas et des services de support très stables.
1. Interface web (la plus simple pour les débutants)
Essayez GLM 4.6 dès maintenant !
2. Accès API (pour les développeurs)
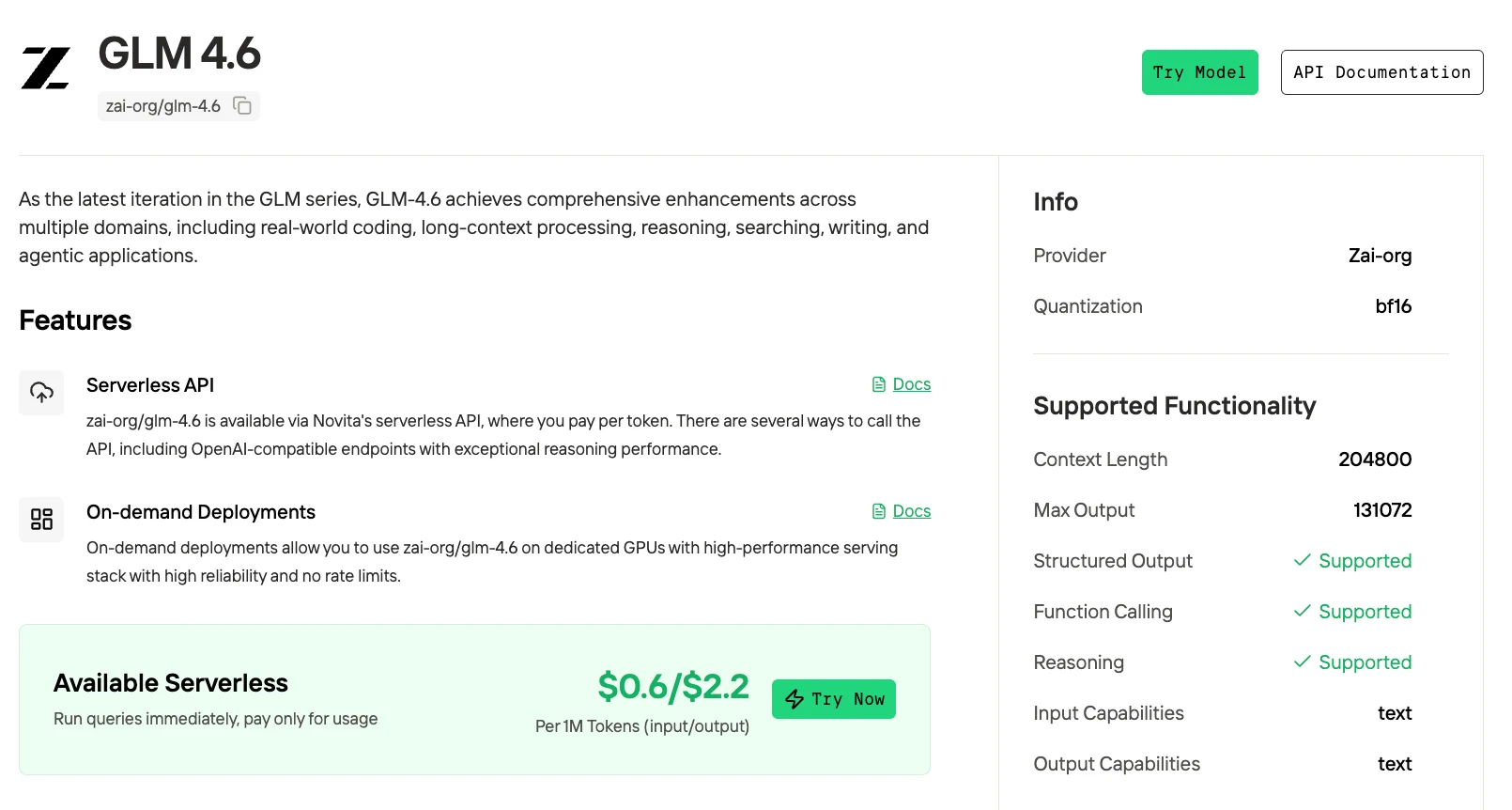
Novita AI propose des API avec un contexte de 204K, et des coûts de 0,6 $ par entrée et 2,2 $ par sortie, prenant en charge les sorties structurées et l’appel de fonctions, ce qui offre un soutien solide pour maximiser le potentiel d’agent de code de GLM 4.6.
Novita AI
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.6",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
3. Déploiement local (utilisateurs avancés)
Prérequis :
- GLM-4.5 : Des ressources GPU importantes (peut nécessiter environ 700B de VRAM)
- GLM-4.5-Air : 16 Go de mémoire GPU (12 Go avec quantification INT4)
Étapes d’installation :
- Téléchargez les poids du modèle depuis HuggingFace ou ModelScope
- Choisissez le framework d’inférence : vLLM ou SGLang sont pris en charge
- Suivez le guide de déploiement dans le dépôt GitHub officiel
4. Intégration
Utilisation d’outils en ligne de commande comme Trae, Claude Code, Qwen Code
Si vous souhaitez utiliser les meilleurs modèles de Novita AI (comme Qwen3-Coder, Kimi K2, DeepSeek R1) pour l’assistance au codage par IA dans votre environnement local ou votre IDE, le processus est simple : récupérez votre clé API, installez l’outil, configurez les variables d’environnement et commencez à coder.
Pour des commandes d’installation détaillées et des exemples, consultez les tutoriels officiels :
- Trae : Guide étape par étape pour accéder aux modèles IA dans votre IDE
- Claude Code : Comment utiliser Kimi-K2 dans Claude Code sur Windows, Mac et Linux
- Qwen Code : Comment utiliser l’API compatible OpenAI dans Qwen Code (installation en 60s !)
Flux de travail multi-agents avec le SDK OpenAI Agents
Construisez des systèmes multi-agents avancés en intégrant Novita AI avec le SDK OpenAI Agents :
- Prêt à l’emploi : Utilisez les LLM de Novita AI dans tout flux de travail OpenAI Agents.
- Prise en charge des transferts, du routage et de l’utilisation d’outils : Concevez des agents capables de déléguer, de trier ou d’exécuter des fonctions, le tout alimenté par les modèles de Novita AI.
- Intégration Python : Définissez simplement le point de terminaison du SDK sur
https://api.novita.ai/v3/openaiet utilisez votre clé API.
Connecter l’API sur des plateformes tierces
API compatible OpenAI : Profitez d’une migration et d’une intégration sans souci avec des outils comme Cline et Cursor, conçus pour la norme d’API OpenAI.
Hugging Face : Utilisez les modèles dans Spaces, les pipelines ou avec la bibliothèque Transformers via les points de terminaison Novita AI.
Frameworks d’agents et d’orchestration : Connectez facilement Novita AI à des plateformes partenaires comme Continue, AnythingLLM,LangChain, Dify et Langflow via des connecteurs officiels et des guides d’intégration étape par étape.
Conseils pour accéder à GLM 4.6
1. Configuration de base
- Utilisez
"model": "glm-4.6"pour spécifier la version correcte. - Le tableau
messagesdéfinit le flux de dialogue : chaque entrée a unrole("user"ou"assistant") et uncontent(texte). Alternez les rôles pour des conversations multi-tours. - Contrôlez la sortie avec
max_tokens(recommandation :4096) ettemperature(par exemple0.6pour la stabilité, une valeur plus élevée pour la créativité). - Activez
"stream": truepour des réponses en flux segmenté. - Activez le mode de raisonnement via
"thinking": {"type": "enabled"}pour inclure les processus de réflexion étape par étape.
2. Performance et fiabilité
- Utilisez
top_ppour l’échantillonnage par noyau etpresence_penaltypour réduire les répétitions. - Validez les charges utiles pour éviter des erreurs comme HTTP
400. - Appliquez un backoff exponentiel sur des erreurs comme
429(limite de débit dépassée) pour éviter la surcharge du serveur. - Gérez les cas limites (délais d’attente, sorties vides ou réponses corrompues) avec une logique de repli.
3. Optimisation et contrôle du contexte
- Rédigez des prompts clairs et concis pour améliorer la précision du modèle.
- Utilisez des messages système pour établir le contexte de la tâche et guider le comportement.
- Enregistrez les conversations pour l’audit, le débogage et l’analyse des performances.
- Ajustez les paramètres de manière itérative pour obtenir le ton, la longueur et la profondeur de raisonnement souhaités.
4. Sécurité et gestion des accès
- Gardez les clés API privées dans les environnements de production.
- Évitez de les intégrer dans du code front-end ou côté client.
- Surveillez l’utilisation pour rester dans les limites de débit, généralement définies par tokens par minute ou plafonds de requêtes quotidiennes.
- Consultez régulièrement la documentation de Zhipu AI pour connaître les limites mises à jour et les nouveaux paramètres.
GLM-4.6 propulse l’écosystème Zhipu AI vers un nouveau niveau de performance : il gère des contextes plus longs, raisonne plus profondément et fonctionne plus efficacement que son prédécesseur. Combiné à des chemins d’accès polyvalents et des API adaptées aux développeurs, il s’agit de l’un des modèles pilotés par le raisonnement les plus performants disponibles.
En maîtrisant les méthodes d’accès et les conseils de configuration présentés ici, les utilisateurs peuvent débloquer tout le potentiel de GLM-4.6 dans les domaines du codage, de la création de contenu, des agents intelligents et de l’automatisation des entreprises.
Questions fréquemment posées
Qu’est-ce qui rend GLM-4.6 meilleur que GLM-4.5 ?
GLM-4.6 dispose d’une fenêtre de contexte de 200K tokens, d’une efficacité d’utilisation des tokens supérieure de 30 %, de compétences de raisonnement et de codage plus solides et d’une intégration d’agents plus fluide.
Comment puis-je commencer à utiliser GLM-4.6 ?
Vous pouvez y accéder via l’interface web officielle, l’API Novita AI ou un déploiement local en utilisant Hugging Face ou ModelScope. Novita AI propose des tarifs abordables et des performances stables.
L’API est-elle adaptée aux débutants ?
Oui. Avec des étapes d’installation claires, des points de terminaison compatibles OpenAI et du code d’exemple, les développeurs peuvent commencer à envoyer des requêtes en quelques minutes.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA grâce à notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.



