

Points clés
DeepSeek V3 introduit des fonctionnalités d’architecture innovantes comme MoE et MLA, améliorant considérablement l’efficacité et la longueur du contexte.
Le rapport coût-efficacité de DeepSeek V3 est remarquable, avec des coûts d’entraînement faibles et des frais d’utilisation de l’API moins chers que ceux des concurrents.
Les utilisateurs peuvent accéder à DeepSeek V3 via l’API de Novita AI ou le déployer localement, offrant une flexibilité pour divers besoins et ressources.
DeepSeek, un modèle d’IA innovant, a accédé à une renommée mondiale fin janvier 2025. Après la sortie de son modèle V3 et de son application, l’open-sourcing de son modèle d’inférence R1 le 20 janvier a suscité un intérêt mondial. En quelques jours, l’application DeepSeek a grimpé en tête de l’App Store américain, dépassant les géants de la technologie. Dans cet article, nous examinerons comment y accéder, comparerons le déploiement local avec l’accès par API, et proposerons des conseils pour différents besoins d’utilisateurs.
Qu’est-ce que DeepSeek V3
DeepSeek V3 est un modèle de langage open-source de pointe à base de Mixture-of-Experts (MoE) développé par Beijing DeepSeek Technology Co., Ltd. Ce modèle avancé compte 671 milliards de paramètres, dont seulement 37 milliards sont activés par jeton lors de l’inférence, optimisant ainsi les performances tout en minimisant la consommation de ressources. DeepSeek V3 est conçu pour concurrencer les modèles leaders comme GPT, excellant particulièrement dans les tâches de codage et techniques.
Principales caractéristiques
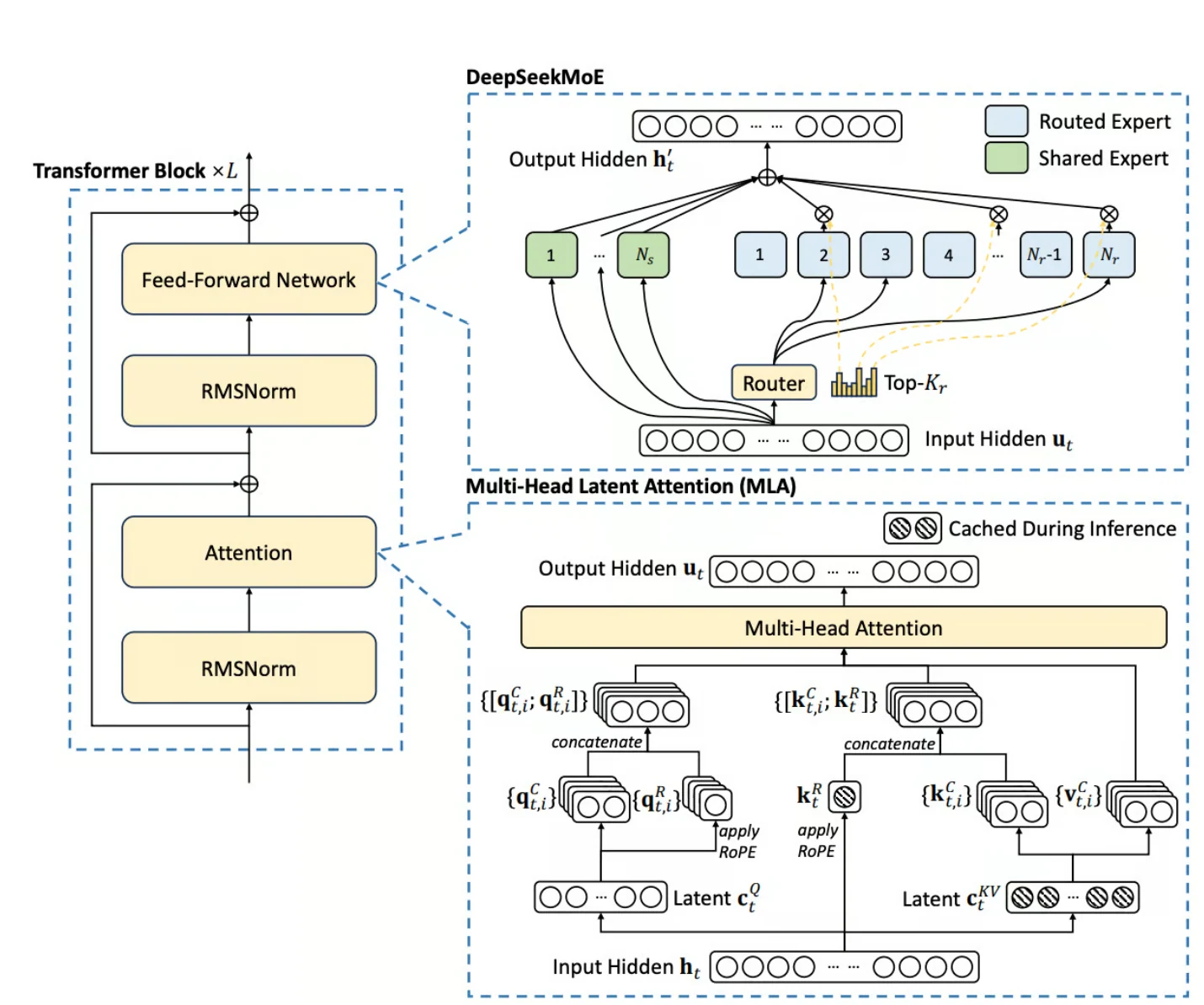
- Architecture Mixture-of-Experts (MoE) : DeepSeek V3 utilise un framework MoE avec des techniques d’équilibrage de charge dynamique et granulaire, éliminant le besoin de perte auxiliaire.
- Multi-Head Latent Attention (MLA) : Cette fonctionnalité améliore l’efficacité de l’inférence en compressant les clés et valeurs d’attention, réduisant la surcharge mémoire et permettant au modèle de gérer de longues fenêtres de contexte allant jusqu’à 128K jetons.
- Multi-Token Prediction (MTP) : MTP permet à DeepSeek V3 de prédire plusieurs jetons simultanément, améliorant à la fois l’efficacité de l’entraînement et la vitesse d’inférence.
- Entraînement en précision mixte FP8 : Le modèle utilise une précision en virgule flottante 8 bits pour l’entraînement, réduisant les coûts mémoire et de calcul.
- Support bilingue : DeepSeek V3 est optimisé pour l’anglais et le chinois, ce qui le rend adapté aux applications multilingues dans ces langues.
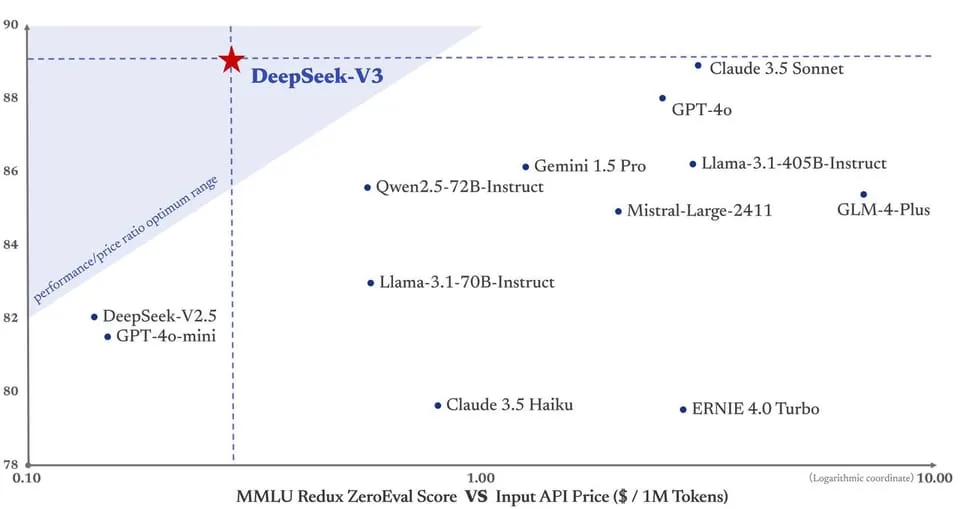
Comme l’illustre le graphique, DeepSeek V3 atteint un équilibre optimal entre hautes performances et faible coût grâce à sa conception architecturale innovante, ce qui en fait une référence en matière de rapport performance/prix. Cette conception permet à DeepSeek V3 de se démarquer parmi de nombreux modèles, en faisant un choix polyvalent pour différents budgets et exigences de tâches.
- Tâches d’inférence à grande échelle (par exemple, génération de contenu par lots).
- Entreprises et équipes de taille petite à moyenne avec un fort accent sur la rentabilité.
- Tâches impliquant les mathématiques, la génération de code et le raisonnement logique complexe.
DeepSeek V3 est désormais disponible sur Novita AI ! Profitez de prix incroyablement bas par million de jetons pour l’entrée et la sortie—ne manquez pas cette opportunité d’accéder à une IA de pointe à un coût imbattable !
Comparaison avec d’autres modèles
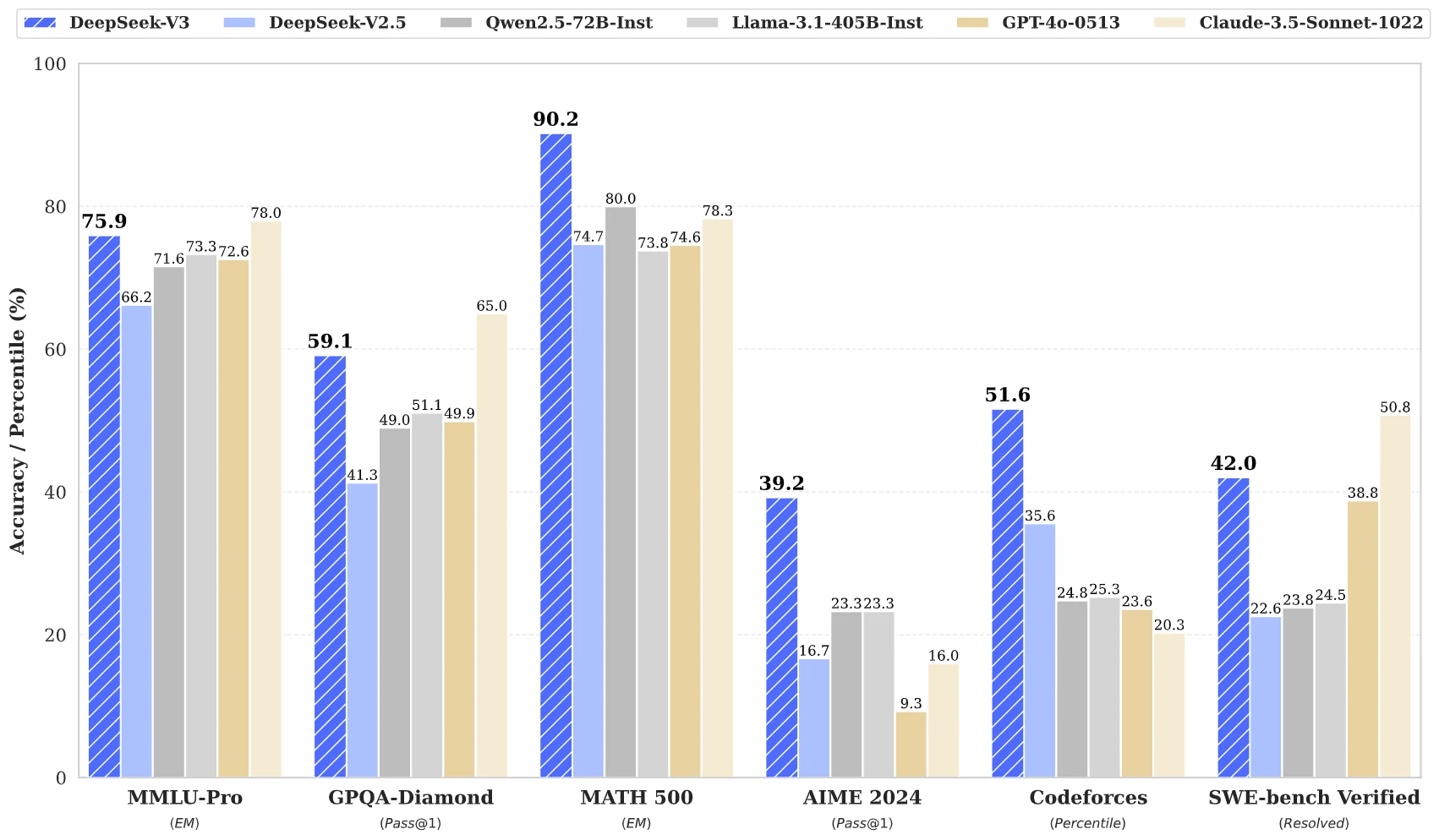
DeepSeek V3 est un modèle puissant excellent dans plusieurs domaines, notamment dans le traitement des connaissances professionnelles, les mathématiques de base et les tâches de programmation. Cependant, il a des marges d’amélioration dans le raisonnement avancé et les applications spécifiques à un domaine. Cela indique des axes d’amélioration futurs, tels que le renforcement de la résolution de problèmes ouverts, du raisonnement mathématique complexe et des performances dans des scénarios d’ingénierie logicielle pratique.
Si vous souhaitez une comparaison de paramètres plus détaillée, consultez les articles : Deepseek v3 vs Llama 3.3 70b : Tâches linguistiques vs Code et Mathématiques ; Llama 3.2 3B vs DeepSeek V3 : Comparaison de l’efficacité et des performances.
Comment accéder à DeepSeek V3 localement
Configuration matérielle requise et recommandations
-
Système d’exploitation
- Windows 10 ou plus récent
- macOS 10.15 ou ultérieur
- Linux (Ubuntu 18.04+)
-
Processeur
- Processeur multicœur (minimum 4 cœurs)
-
GPU
- GPU NVIDIA recommandés pour une inférence plus rapide
- Minimum 8 Go de VRAM pour les petits R1 distillés
- Plus de VRAM nécessaire pour le modèle complet de 671B
- Exécution uniquement CPU possible mais significativement plus lente
-
Mémoire (RAM)
- 8 Go : Suffisant pour les plus petites versions (1,5B ou 7B)
- 16 Go ou plus : Recommandé pour les modèles de taille moyenne (14B ou 32B)
-
Stockage
- 4 à 50 Go d’espace libre requis, selon la taille de R1 téléchargée
-
Logiciels requis
- Python 3.10 pour les scripts R1 officiels
Guide d’installation étape par étape
1.Cloner le dépôt :
git clone https://github.com/deepseek-ai/DeepSeek-V3.git
2.Naviguer vers le dossier d’inférence et installer les dépendances :
cd DeepSeek-V3/inference
pip install -r requirements.txt
3.Télécharger les poids du modèle :
Téléchargez les poids du modèle depuis Hugging Face et placez-les dans le répertoire désigné (par exemple /path/to/DeepSeek-V3).
4.Convertir les poids du modèle :
Utilisez le script convert.py fourni pour convertir les poids dans un format spécifique. Exemple :
python convert.py --hf-ckpt-path /path/to/DeepSeek-V3 --save-path /path/to/DeepSeek-V3-Demo --n-experts 256 --model-parallel 16
5.Lancer DeepSeek V3 :
Utilisez la commande torchrun pour démarrer le modèle. Modifiez les paramètres selon votre configuration. Exemple :
torchrun --nnodes 2 --nproc-per-node 8 --node-rank $RANK --master-addr $ADDR generate.py --ckpt-path /path/to/DeepSeek-V3-Demo --config configs/config_671B.json --interactive --temperature 0.7 --max-new-tokens 200
6.Inférence par lots (optionnel) :
Pour une inférence par lots sur un fichier donné :
torchrun --nnodes 2 --nproc-per-node 8 --node-rank $RANK --master-addr $ADDR generate.py --ckpt-path /path/to/DeepSeek-V3-Demo --config configs/config_671B.json --input-file $FILE
Comment accéder à DeepSeek V3 via Novita AI
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant également un GPU cloud abordable et fiable pour construire et passer à l’échelle.
Étape 1 : Se connecter et accéder à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez DeepSeek V3 Demo maintenant !
Étape 2 : Choisir votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Démarrer votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.

Étape 4 : Obtenir votre clé API
Pour vous authentifier avec l’API, nous vous fournirons une nouvelle clé API. Entrez dans la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installer l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE_CLÉ_API_Novita_AI>",
)
model = "deepseek/deepseek_v3"
stream = True # ou False
max_tokens = 2048
system_content = """Soyez un assistant utile"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Lors de l’inscription, Novita AI offre un crédit de 0,50 $ pour vous aider à démarrer !
Si les crédits gratuits sont épuisés, vous pouvez payer pour continuer à utiliser le service.
Quelles méthodes vous conviennent ?
Comparaison entre accès local et API
| Fonctionnalité | Déploiement local | Accès API |
|---|---|---|
| Contrôle | Élevé | Limité |
| Personnalisation | Flexible | Restreinte |
| Configuration matérielle requise | Élevée | Faible |
| Coût initial | Élevé | Faible |
| Évolutivité | Limitée | Élevée |
| Difficulté de maintenance | Élevée | Faible |
| Protection de la vie privée | Forte | Dépend du fournisseur |
Recommandations pour différents groupes d’utilisateurs
-
Pour les chercheurs et développeurs
- Recommandation : Déploiement local de DeepSeek V3.
- Pourquoi : Offre un contrôle total sur le modèle, permettant une personnalisation et une optimisation poussées.
- Considérations : Nécessite des ressources matérielles importantes et une expertise technique avancée.
-
Pour les startups et PME
- Recommandation : Utiliser l’API DeepSeek V3 fournie par Novita AI.
- Avantages : Rentable, facile à intégrer et évolutif pour répondre aux besoins changeants de l’entreprise.
- Meilleurs cas d’utilisation : Prototyper rapidement des idées et créer des applications pilotées par l’IA sans investissements initiaux lourds.
En conclusion, DeepSeek V3 est un modèle open-source puissant qui offre des performances exceptionnelles en codage, mathématiques et raisonnement. Il offre une flexibilité pour divers cas d’utilisation, qu’il soit déployé localement ou accessible via des API. Alors que le déploiement local offre un contrôle total, il nécessite des ressources matérielles importantes. Alternativement, des plateformes comme Novita AI offrent un moyen plus accessible et pratique d’utiliser les capacités du modèle. Le choix optimal dépend des exigences de votre projet, de votre expertise technique et de votre budget.
Questions fréquemment posées
Comment DeepSeek V3 parvient-il à son efficacité ?
DeepSeek V3 utilise une architecture Mixture-of-Experts (MoE), n’activant que 37 milliards de paramètres par jeton. Il emploie Multi-Head Latent Attention (MLA) et un objectif Multi-Token Prediction (MTP) pour réduire la consommation de ressources et accélérer à la fois l’entraînement et l’inférence.
Quels sont les principaux avantages de DeepSeek V3 ?
DeepSeek V3 excelle dans les tâches de codage, mathématiques, raisonnement et connaissances générales, et possède un fort support multilingue pour l’anglais et le chinois. Il démontre des performances exceptionnelles sur divers benchmarks, surpassant souvent d’autres modèles open-source et même certains modèles fermés.
Quels sont les besoins en VRAM pour DeepSeek V3 ?
Les besoins en VRAM pour DeepSeek V3 varient selon la précision. Pour FP16, le modèle 671B nécessite environ 1 543 Go de VRAM, tandis qu’avec une quantification 4 bits, il nécessite environ 386 Go de VRAM. Les paramètres actifs sont de 37B.
Novita AI est la plateforme cloud tout-en-un qui propulse vos ambitions IA. API intégrées, sans serveur, Instance GPU—les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement, et réalisez votre vision IA.



