

Aspectos destacados
DeepSeek V3 introduce características de arquitectura innovadoras como MoE y MLA, mejorando significativamente la eficiencia y la longitud de contexto.
La relación coste-efectividad de DeepSeek V3 es notable, con bajos costos de entrenamiento y tarifas de uso de API más económicas que las de la competencia.
Los usuarios pueden acceder a DeepSeek V3 a través de la API de Novita AI o implementarlo localmente, ofreciendo flexibilidad para diversas necesidades y recursos.
DeepSeek, un modelo de IA innovador, saltó a la fama mundial a finales de enero de 2025. Tras el lanzamiento de su modelo V3 y su aplicación, la publicación como código abierto de su modelo de inferencia R1 el 20 de enero despertó un interés mundial. En cuestión de días, la aplicación de DeepSeek se disparó al primer puesto de la App Store de EE. UU., superando a los gigantes tecnológicos. En este artículo, analizaremos cómo acceder a él, compararemos la implementación local con el acceso mediante API y ofreceremos orientación para diferentes necesidades de los usuarios.
¿Qué es DeepSeek-V3?
DeepSeek V3 es un modelo de lenguaje grande (LLM) de código abierto y última generación basado en Mezcla de Expertos (MoE), desarrollado por Beijing DeepSeek Technology Co., Ltd. Este avanzado modelo cuenta con 671 mil millones de parámetros, de los cuales solo se activan 37 mil millones por token durante la inferencia, optimizando el rendimiento y minimizando el consumo de recursos. DeepSeek V3 está diseñado para competir con modelos líderes como GPT, destacando especialmente en tareas de codificación y técnicas.
Características principales
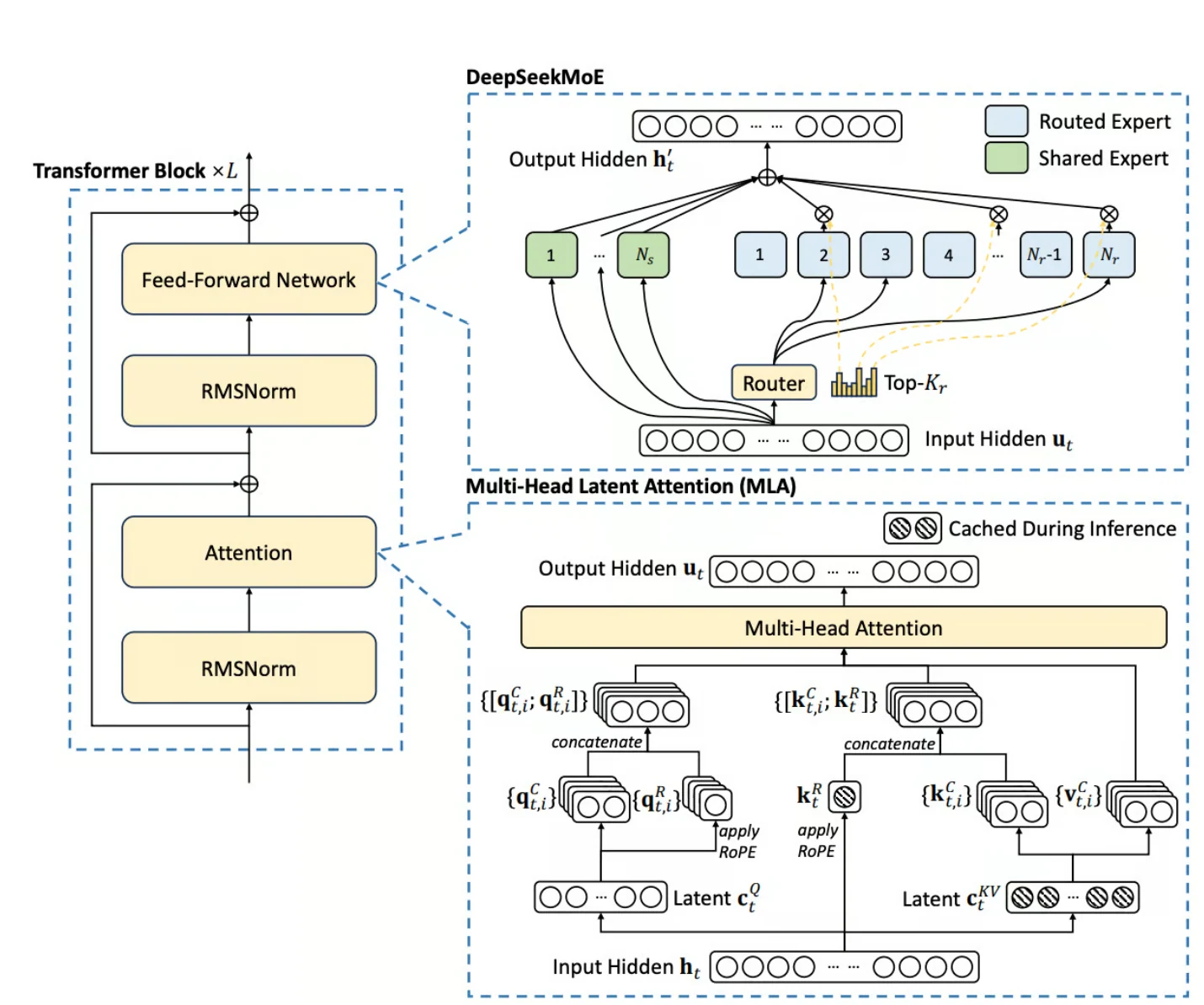
- Arquitectura de Mezcla de Expertos (MoE): DeepSeek V3 emplea un marco MoE con técnicas de equilibrio de carga dinámico de grano fino, eliminando la necesidad de pérdida auxiliar.
- Atención Latente Multi-Cabeza (MLA): Esta característica mejora la eficiencia de la inferencia al comprimir las claves y valores de atención, reduciendo la sobrecarga de memoria y permitiendo al modelo manejar ventanas de contexto largas de hasta 128 mil tokens.
- Predicción Multi-Token (MTP): MTP permite a DeepSeek V3 predecir múltiples tokens simultáneamente, mejorando tanto la eficiencia del entrenamiento como la velocidad de inferencia.
- Entrenamiento de Precisión Mixta FP8: El modelo utiliza precisión de punto flotante de 8 bits para el entrenamiento, reduciendo los costos de memoria y computación.
- Soporte Bilingüe: DeepSeek V3 está optimizado tanto para inglés como para chino, lo que lo hace adecuado para aplicaciones multilingües en estos idiomas.
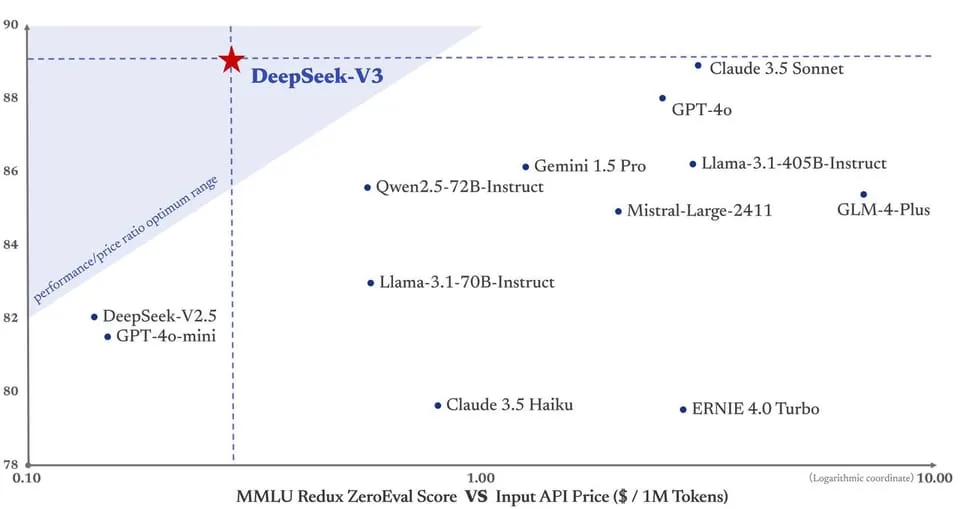
Como se ilustra en el gráfico, DeepSeek-V3 logra un equilibrio óptimo entre alto rendimiento y bajo costo gracias a su diseño arquitectónico innovador, convirtiéndolo en un referente de relación rendimiento-precio. Este diseño permite que DeepSeek-V3 se destaque entre numerosos modelos, siendo una opción versátil para diversos presupuestos y requisitos de tareas.
- Tareas de inferencia a gran escala (por ejemplo, generación de contenido por lotes).
- Empresas y equipos pequeños y medianos con un fuerte enfoque en la eficiencia de costos.
- Tareas que involucran matemáticas, generación de código y razonamiento lógico complejo.
¡DeepSeek-V3 ya está disponible en Novita AI! Disfruta de precios increíblemente bajos por millón de tokens tanto para entrada como para salida; no pierdas esta oportunidad de acceder a IA de vanguardia a un costo imbatible.
Comparación con otros modelos
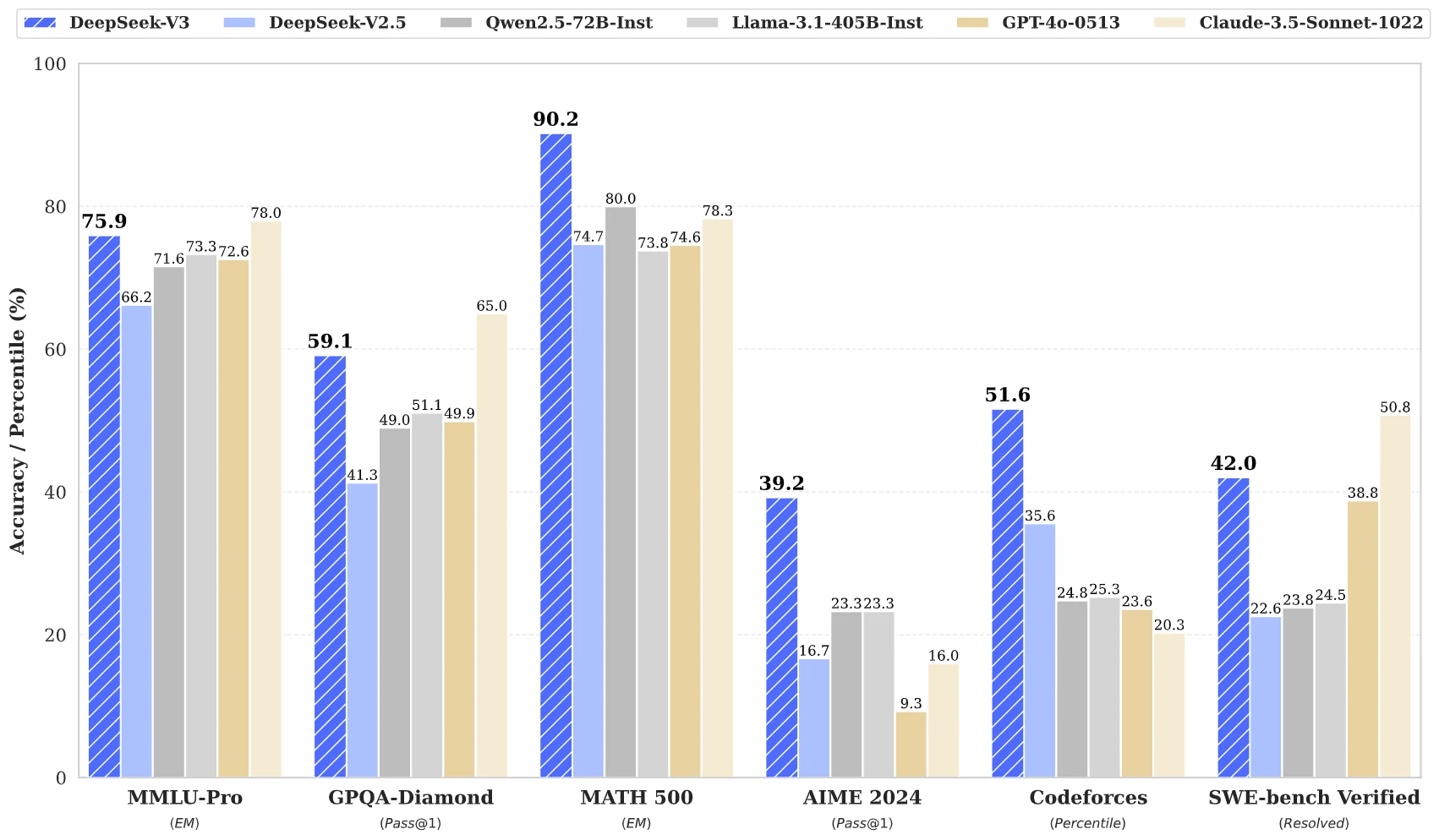
DeepSeek-V3 es un modelo potente que sobresale en múltiples dominios, particularmente en el manejo de conocimiento profesional, matemáticas básicas y tareas de programación. Sin embargo, tiene margen de mejora en razonamiento avanzado y aplicaciones en dominios específicos. Esto indica áreas para futuras mejoras, como potenciar la resolución de problemas abiertos, el razonamiento matemático complejo y el rendimiento en escenarios prácticos de ingeniería de software.
Si deseas ver una comparación de parámetros más detallada, puedes consultar los artículos: Deepseek v3 vs Llama 3.3 70b: Tareas de lenguaje vs código y matemáticas; Llama 3.2 3B vs DeepSeek V3: Comparando eficiencia y rendimiento.
Cómo acceder a DeepSeek-V3 de forma local
Requisitos de hardware y recomendaciones de configuración
-
Sistema operativo
- Windows 10 o posterior
- macOS 10.15 o posterior
- Linux (Ubuntu 18.04+)
-
CPU
- Procesador multinúcleo (mínimo 4 núcleos)
-
GPU
- Se recomiendan GPUs NVIDIA para una inferencia más rápida
- Mínimo 8 GB de VRAM para destilados R1 más pequeños
- Se requiere más VRAM para el modelo completo de 671B
- Es posible ejecutar solo con CPU, pero es significativamente más lento
-
Memoria (RAM)
- 8 GB: Suficiente para las versiones más pequeñas (1.5B o 7B)
- 16 GB o más: Recomendado para modelos de gama media (14B o 32B)
-
Almacenamiento
- Espacio libre de 4 a 50 GB requerido, dependiendo del tamaño de R1 descargado
-
Requisitos de software
- Python 3.10 para los scripts oficiales de R1
Guía de instalación paso a paso
1. Clonar el repositorio:
git clone https://github.com/deepseek-ai/DeepSeek-V3.git
2. Navegar a la carpeta de inferencia e instalar dependencias:
cd DeepSeek-V3/inference
pip install -r requirements.txt
3. Descargar los pesos del modelo:
Descarga los pesos del modelo desde Hugging Face y colócalos en el directorio designado (por ejemplo, /ruta/a/DeepSeek-V3).
4. Convertir los pesos del modelo:
Usa el script convert.py proporcionado para convertir los pesos a un formato específico. Por ejemplo:
python convert.py --hf-ckpt-path /ruta/a/DeepSeek-V3 --save-path /ruta/a/DeepSeek-V3-Demo --n-experts 256 --model-parallel 16
5. Ejecutar DeepSeek-V3:
Usa el comando torchrun para iniciar el modelo. Modifica los parámetros según sea necesario para tu configuración. Ejemplo:
torchrun --nnodes 2 --nproc-per-node 8 --node-rank $RANK --master-addr $ADDR generate.py --ckpt-path /ruta/a/DeepSeek-V3-Demo --config configs/config_671B.json --interactive --temperature 0.7 --max-new-tokens 200
6. Inferencia por lotes (opcional):
Para inferencia por lotes en un archivo dado:
torchrun --nnodes 2 --nproc-per-node 8 --node-rank $RANK --master-addr $ADDR generate.py --ckpt-path /ruta/a/DeepSeek-V3-Demo --config configs/config_671B.json --input-file $ARCHIVO
Cómo acceder a DeepSeek-V3 a través de Novita AI
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, al mismo tiempo que proporciona la GPU en la nube asequible y confiable para construir y escalar.
Paso 1: Iniciar sesión y acceder a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de Modelos.

¡Prueba DeepSeek V3 Demo ahora!
Paso 2: Elegir tu modelo
Navega entre las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Iniciar tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.

Paso 4: Obtener tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página de “Configuración” y copia la clave API como se indica en la imagen.

Paso 5: Instalar la API
Instala la API utilizando el administrador de paquetes específico para tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completaciones de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<TU CLAVE API DE Novita AI>",
)
model = "deepseek/deepseek_v3"
stream = True # o False
max_tokens = 2048
system_content = """Sé un asistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "¡Hola!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Al registrarte, Novita AI te otorga un crédito de $0.5 para que empieces.
Si los créditos gratuitos se agotan, puedes pagar para continuar usándolo.
¿Qué métodos son adecuados para ti?
Comparación entre acceso local y mediante API
| Característica | Implementación local | Acceso mediante API |
|---|---|---|
| Control | Alto | Limitado |
| Personalización | Flexible | Restringido |
| Requisitos de hardware | Altos | Bajos |
| Costo inicial | Alto | Bajo |
| Escalabilidad | Limitada | Alta |
| Dificultad de mantenimiento | Alta | Baja |
| Protección de privacidad | Fuerte | Depende del proveedor |
Recomendaciones para diferentes grupos de usuarios
-
Para investigadores y desarrolladores
- Recomendación: Implementación local de DeepSeek V3.
- Por qué: Ofrece control total sobre el modelo, permitiendo una amplia personalización y optimización.
- Consideraciones: Requiere recursos de hardware sustanciales y experiencia técnica avanzada.
-
Para startups y pequeñas y medianas empresas
- Recomendación: Usar la API de DeepSeek V3 proporcionada por Novita AI.
- Ventajas: Rentable, fácil de integrar y escalable para satisfacer las necesidades cambiantes del negocio.
- Mejores casos de uso: Prototipado rápido de ideas y creación de aplicaciones impulsadas por IA sin grandes inversiones iniciales.
En conclusión, DeepSeek V3 es un potente modelo de código abierto que ofrece un rendimiento excepcional en tareas de codificación, matemáticas y razonamiento. Ofrece flexibilidad para diversos casos de uso, ya sea implementado localmente o accedido mediante APIs. Si bien la implementación local proporciona control total, exige recursos de hardware considerables. Alternativamente, plataformas como Novita AI ofrecen una forma más accesible y conveniente de utilizar las capacidades del modelo. La elección óptima depende de los requisitos de tu proyecto, tu experiencia técnica y tu presupuesto.
Preguntas frecuentes
¿Cómo logra DeepSeek V3 su eficiencia?
DeepSeek V3 utiliza una arquitectura de Mezcla de Expertos (MoE) que activa solo 37 mil millones de parámetros por token. Emplea Atención Latente Multi-Cabeza (MLA) y un objetivo de Predicción Multi-Token (MTP) para reducir el consumo de recursos y acelerar tanto el entrenamiento como la inferencia.
¿Cuáles son las principales ventajas de DeepSeek V3?
DeepSeek V3 sobresale en tareas de codificación, matemáticas, razonamiento y conocimiento general, y cuenta con un sólido soporte multilingüe para inglés y chino. Demuestra un rendimiento excepcional en varios puntos de referencia, superando a menudo a otros modelos de código abierto e incluso a algunos de código cerrado.
¿Cuáles son los requisitos de VRAM para DeepSeek V3?
Los requisitos de VRAM para DeepSeek V3 varían según la precisión. Para FP16, el modelo de 671B requiere aproximadamente 1.543 GB de VRAM, mientras que con cuantización de 4 bits requiere aproximadamente 386 GB de VRAM. Los parámetros activos son 37B.
Novita AI es la plataforma integral en la nube que impulsa tus ambiciones de IA. APIs integradas, sin servidor, instancias de GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



