

主なポイント
DeepSeek V3 は、MoE や MLA などの革新的なアーキテクチャ機能を導入し、効率性とコンテキスト長を大幅に向上させています。
DeepSeek V3 のコストパフォーマンスは際立っており、トレーニングコストが低く、API 使用料も競合他社より安価です。
ユーザーは、Novita AI の API を介して DeepSeek V3 にアクセスするか、ローカルにデプロイすることができ、さまざまなニーズやリソースに柔軟に対応できます。
DeepSeek は革新的な AI モデルであり、2025 年 1 月下旬に世界的な注目を集めました。V3 モデルとアプリのリリースに続き、1 月 20 日の R1 推論モデルのオープンソース化は世界中で関心を呼びました。数日以内に、DeepSeek のアプリは米国の App Store でトップに急上昇し、テクノロジー大手を追い抜きました。そこでこの記事では、アクセス方法を検討し、ローカルデプロイと API アクセスを比較し、さまざまなユーザーニーズに合わせたガイダンスを提供します。
DeepSeek-V3 とは
DeepSeek V3 は、北京 DeepSeek Technology Co., Ltd. が開発した、最先端のオープンソース Mixture-of-Experts (MoE) 大規模言語モデルです。この高度なモデルは 6,710 億のパラメータを持ち、推論時にトークンごとにアクティブになるのは 370 億のみであり、リソース消費を最小限に抑えながらパフォーマンスを最適化します。DeepSeek V3 は、特にコーディングや技術タスクにおいて、GPT などの主要モデルと競合するように設計されています。
主な機能
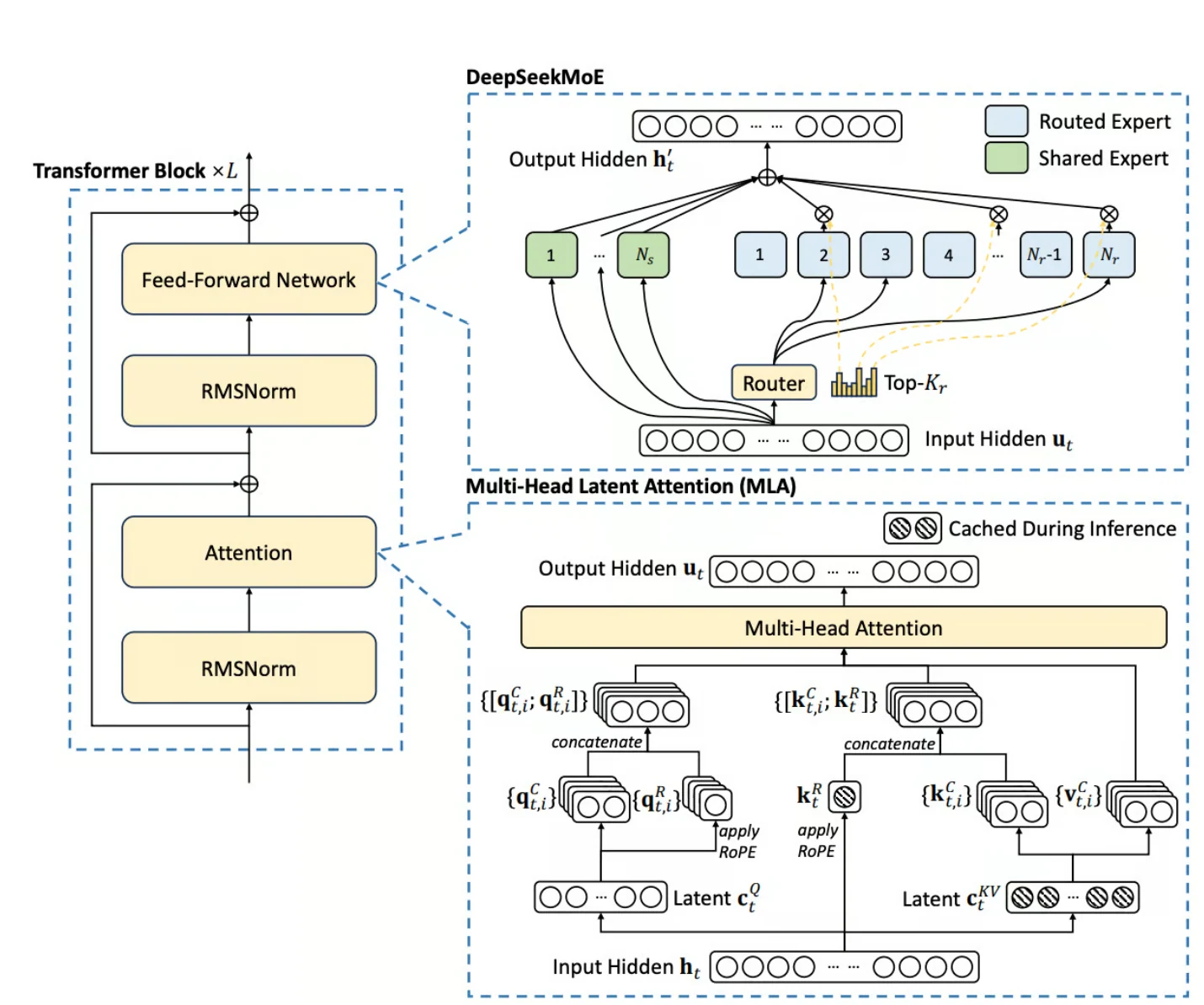
- Mixture-of-Experts (MoE) アーキテクチャ : DeepSeek V3 は、補助損失を必要としない、きめ細かい動的負荷分散技術を備えた MoE フレームワークを採用しています。
- Multi-Head Latent Attention (MLA) : この機能は、アテンションのキーとバリューを圧縮することで推論効率を向上させ、メモリオーバーヘッドを削減し、最大 128K トークンの長いコンテキストウィンドウを処理できるようにします。
- Multi-Token Prediction (MTP) : MTP により、DeepSeek V3 は複数のトークンを同時に予測でき、トレーニング効率と推論速度の両方を向上させます。
- FP8 Mixed Precision Training : このモデルは、トレーニングに 8 ビット浮動小数点精度を利用し、メモリと計算コストを削減します。
- バイリンガルサポート : DeepSeek V3 は英語と中国語の両方に最適化されており、これらの言語での多言語アプリケーションに適しています。
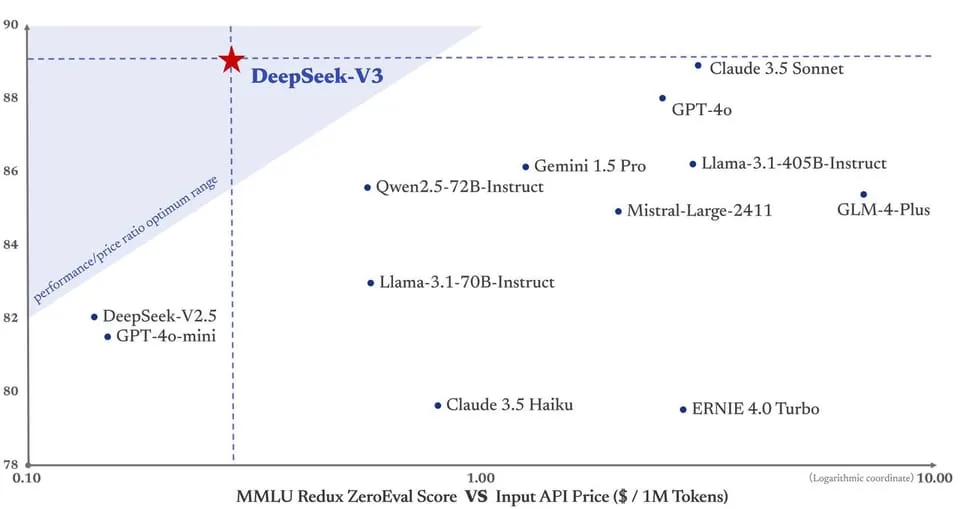
グラフに示されているように、DeepSeek-V3 は革新的なアーキテクチャ設計により、高性能と低コストの最適なバランスを実現し、性能対価格比のベンチマークとなっています。この設計により、DeepSeek-V3 は数多くのモデルの中で際立ち、さまざまな予算やタスク要件に適した汎用的な選択肢となっています。
- 大規模な推論タスク (例: バッチコンテンツ生成)
- コスト効率を重視する企業や中小規模チーム
- 数学、コード生成、複雑な論理的推論を伴うタスク
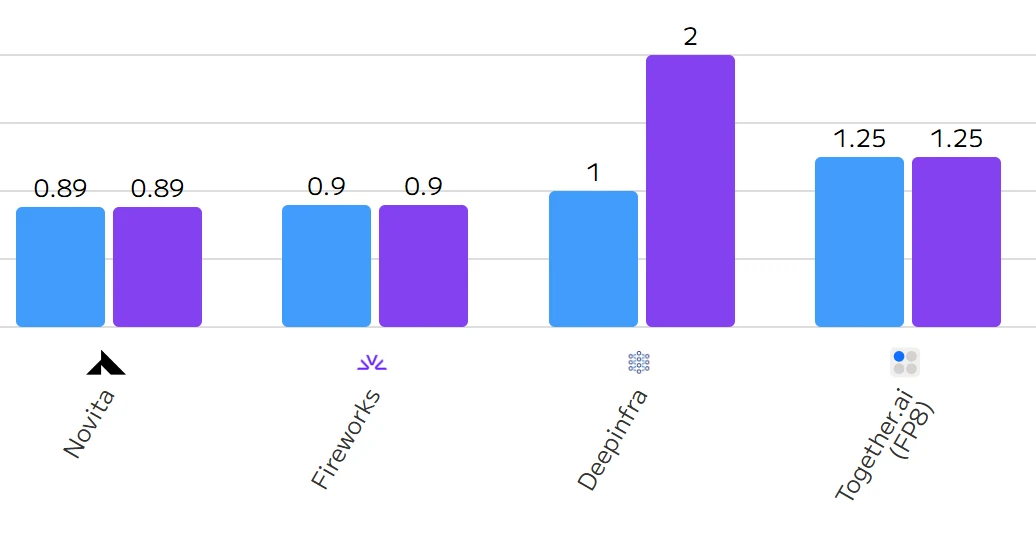
DeepSeek-V3 が Novita AI で利用可能になりました!入力と出力の両方で、100 万トークンあたりの信じられないほど低い価格をお楽しみください。この機会に、比類のないコストで最先端の AI にアクセスしてください。
他のモデルとの比較
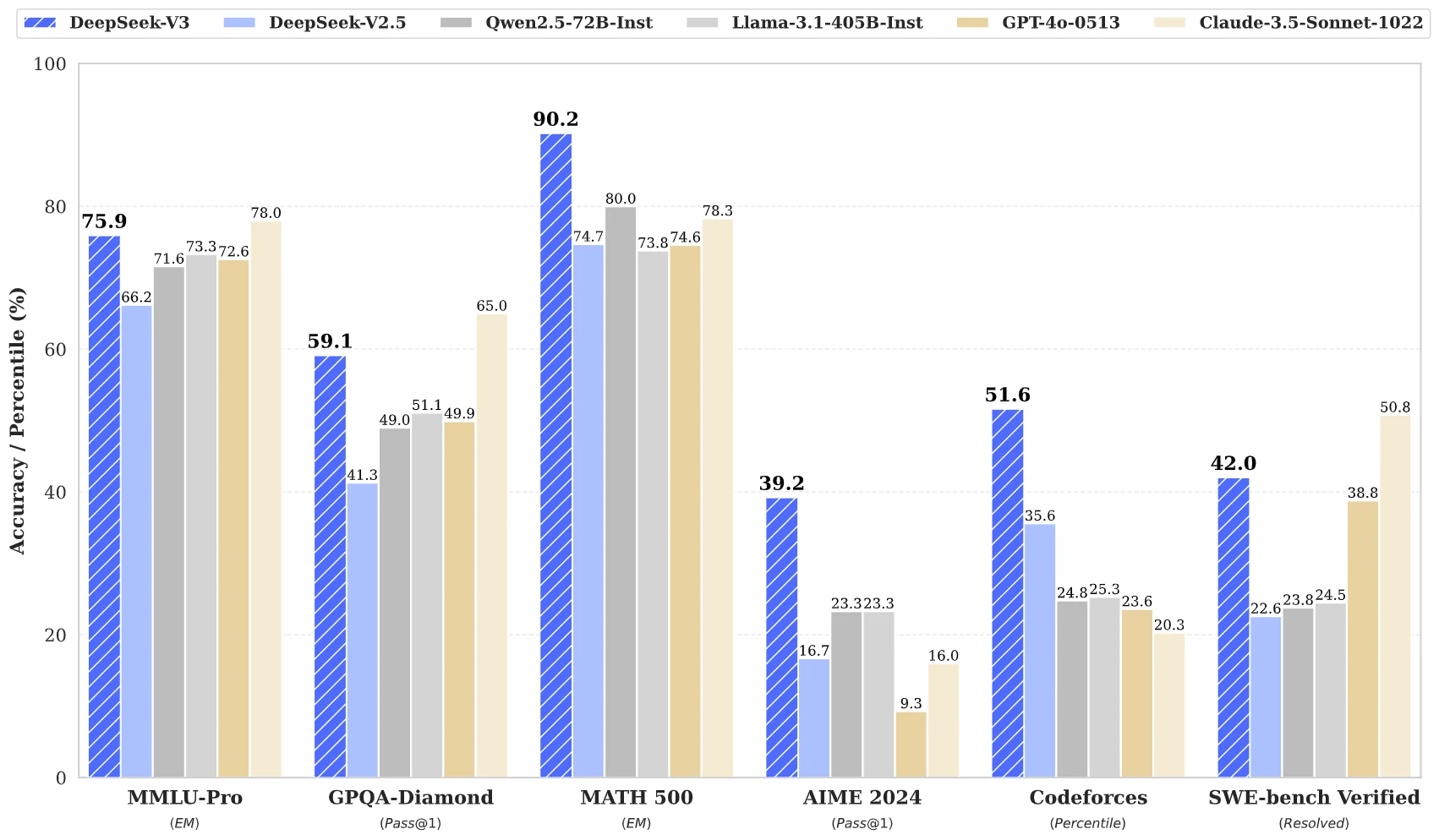
DeepSeek-V3 は、特に専門知識、基礎数学、プログラミングタスクの処理において、複数の領域で優れたパワフルなモデルです。ただし、高度な推論や特定のドメインアプリケーションには改善の余地があります。これは、オープンエンドの問題解決、複雑な数学的推論、および実践的なソフトウェアエンジニアリングシナリオでのパフォーマンスを強化するなど、将来の機能強化の領域を示しています。
より詳細なパラメータ比較をご覧になりたい方は、以下の記事をご確認ください: Deepseek v3 vs Llama 3.3 70b: Language Tasks vs Code & Math ; Llama 3.2 3B vs DeepSeek V3: Comparing Efficiency and Performance .
DeepSeek-V3 にローカルでアクセスする方法
ハードウェア要件と設定推奨事項
-
オペレーティングシステム
- Windows 10 以降
- macOS 10.15 以降
- Linux (Ubuntu 18.04+)
-
CPU
- マルチコアプロセッサ (最低 4 コア)
-
GPU
- より高速な推論には NVIDIA GPU を推奨
- 小規模な R1 蒸留モデルには最低 8GB VRAM
- フル 671B モデルにはより多くの VRAM が必要
- CPU のみの実行も可能ですが、大幅に低速
-
メモリ (RAM)
- 8GB : 最小バージョン (1.5B または 7B) に十分
- 16GB 以上 : 中規模モデル (14B または 32B) に推奨
-
ストレージ
- ダウンロードする R1 のサイズに応じて、4~50GB の空き容量 が必要
-
ソフトウェア要件
- 公式 R1 スクリプトには Python 3.10
ステップバイステップインストールガイド
1. リポジトリのクローン:
git clone https://github.com/deepseek-ai/DeepSeek-V3.git
2. 推論フォルダに移動し、依存関係をインストール:
cd DeepSeek-V3/inference
pip install -r requirements.txt
3. モデル重みのダウンロード :
Hugging Face からモデル重みをダウンロードし、指定されたディレクトリ (例: /path/to/DeepSeek-V3) に配置します。
4. モデル重みの変換 :
提供されている convert.py スクリプトを使用して、重みを特定の形式に変換します。例:
python convert.py --hf-ckpt-path /path/to/DeepSeek-V3 --save-path /path/to/DeepSeek-V3-Demo --n-experts 256 --model-parallel 16
5. DeepSeek-V3 の実行:
torchrun コマンドを使用してモデルを起動します。セットアップに応じてパラメータを変更してください。例:
torchrun --nnodes 2 --nproc-per-node 8 --node-rank $RANK --master-addr $ADDR generate.py --ckpt-path /path/to/DeepSeek-V3-Demo --config configs/config_671B.json --interactive --temperature 0.7 --max-new-tokens 200
6. バッチ推論 (オプション) :
指定されたファイルに対してバッチ推論を行う場合:
torchrun --nnodes 2 --nproc-per-node 8 --node-rank $RANK --master-addr $ADDR generate.py --ckpt-path /path/to/DeepSeek-V3-Demo --config configs/config_671B.json --input-file $FILE
Novita AI を介して DeepSeek-V3 にアクセスする方法
Novita AI は AI クラウドプラットフォームであり、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできるようにすると同時に、構築とスケーリングのための手頃で信頼性の高い GPU クラウドを提供します。
ステップ 1: ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ 2: モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。

ステップ 3: 無料トライアルを開始
無料トライアルを開始して、選択したモデルの機能を試します。

ステップ 4: API キーを取得
API で認証するために、新しい API キーを提供します。「設定」ページに移動し、画像のように API キーをコピーできます。

ステップ 5: API をインストール
プログラミング言語固有のパッケージマネージャーを使用して API をインストールします。

インストール後、開発環境に必要なライブラリをインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。これは、Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_v3"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
登録時に、Novita AI はスターターとして $0.5 のクレジットを提供します!
無料クレジットが使い切られた場合は、支払いを行って引き続き使用できます。
どの方法があなたに適していますか?
ローカル vs API アクセスの比較
| 特徴 | ローカルデプロイ | API アクセス |
|---|---|---|
| 制御 | 高い | 限定的 |
| カスタマイズ | 柔軟 | 制限あり |
| ハードウェア要件 | 高い | 低い |
| 初期費用 | 高い | 低い |
| スケーラビリティ | 限定的 | 高い |
| メンテナンスの難しさ | 高い | 低い |
| プライバシー保護 | 強固 | プロバイダーによる |
さまざまなユーザーグループへの推奨事項
-
研究者や開発者向け
- 推奨 : DeepSeek V3 のローカルデプロイ
- 理由 : モデルを完全に制御でき、広範なカスタマイズと最適化が可能
- 考慮事項 : かなりのハードウェアリソースと高度な技術的専門知識が必要
-
スタートアップや中小企業向け
- 推奨 : Novita AI が提供する DeepSeek V3 API の使用
- 利点 : コスト効率が良く、統合が容易で、進化するビジネスニーズに合わせてスケーラブル
- 最適なユースケース : 多額の先行投資なしで、アイデアを迅速にプロトタイプ化し、AI 駆動アプリケーションを構築
結論として、DeepSeek V3 は、コーディング、数学、推論タスクで優れたパフォーマンスを発揮する強力なオープンソースモデルです。ローカルにデプロイする場合も、API を介してアクセスする場合も、多様なユースケースに柔軟性を提供します。ローカルデプロイは完全な制御を提供しますが、かなりのハードウェアリソースが必要です。または、Novita AI のようなプラットフォームは、モデルの機能を利用するためのよりアクセスしやすく便利な方法を提供します。最適な選択は、プロジェクトの要件、技術的専門知識、予算によって異なります。
よくある質問
DeepSeek V3 はどのように効率を達成していますか?
DeepSeek V3 は Mixture-of-Experts (MoE) アーキテクチャを使用し、トークンごとに **370 億のパラメータ ** のみをアクティブにします。また、Multi-Head Latent Attention (MLA) と Multi-Token Prediction (MTP) オブジェクティブを採用して、リソース消費を削減し、トレーニングと推論の両方を高速化します。
DeepSeek V3 の主な利点は何ですか?
DeepSeek V3 は、コーディング、数学、推論、一般知識タスクに優れ、英語と中国語の強力な多言語サポートを備えています。さまざまなベンチマークで卓越したパフォーマンスを示し、他のオープンソースモデルやクローズドソースモデルを凌ぐことがよくあります。
DeepSeek V3 に必要な VRAM はどのくらいですか?
DeepSeek V3 に必要な VRAM は精度によって異なります。FP16 の場合、671B モデルには約 1,543 GB の VRAM が必要であり、4 ビット量子化の場合、約 386 GB の VRAM が必要です。アクティブパラメータは 37B です。
Novita AI は、AI の野心を強化するオールインワンクラウドプラットフォームです。統合 API、サーバーレス、GPU インスタンス — 必要なコスト効率の高いツール。インフラストラクチャを排除し、無料で開始して、AI のビジョンを実現しましょう。



