

Les développeurs qui créent des flux de travail autonomes sont confrontés à un problème majeur : la plupart des modèles voient leurs performances se dégrader après plusieurs dizaines de milliers de tokens. Ce guide évalue GLM 4.7 Flash sur les plans de l’architecture, des benchmarks, de la vitesse d’inférence et des besoins matériels, et propose une voie concrète pour obtenir des agents locaux stables et adaptés à la production.
Essayez GLM 4.7 Flash dès maintenant !
Architecture de GLM 4.7 Flash
GLM 4.7 Flash associe une grande fenêtre de contexte à une structure MoE pour équilibrer les capacités de raisonnement et l’efficacité du déploiement local.
| Fonctionnalité | Description |
|---|---|
| Classe de paramètres | Modèle MoE de 30B avec 3,6B de paramètres actifs par contexte de token |
| Fenêtre de contexte | Prend en charge jusqu’à 200 000 tokens, permettant un historique étendu et une planification à long terme |
| Conception du raisonnement | Modes de réflexion entrelacés et préservés pour un raisonnement multi-tours cohérent |
Benchmarks de GLM 4.7 Flash
GLM 4.7 Flash affiche des performances de benchmark supérieures en matière de raisonnement agentique par rapport à ses pairs de sa catégorie. Ses résultats de benchmark indiquent des performances équilibrées sur les tâches de codage et de raisonnement, renforçant la confiance dans ses productions sur de longues chaînes de traitement :
| Benchmark | GLM 4.7 Flash | Qwen3-30B | GPT-OSS-20B |
|---|---|---|---|
| AIME 25 | 91.6 | 85.0 | 91.7 |
| GPQA | 75.2 | 73.4 | 71.5 |
| SWE-bench Verified | 59.2 | 22.0 | 34.0 |
| τ²-Bench | 79.5 | 49.0 | 47.7 |
| BrowseComp | 42.8 | 2.29 | 28.3 |
D’après ce tableau, GLM 4.7 Flash présente un profil de capacités très équilibré et de haut niveau :
- Raisonnement mathématique très performant
Un score de 91,6 à l’AIME 25 signifie qu’il est performant à un niveau proche des modèles de première catégorie sur des problèmes de mathématiques de niveau compétition. - Raisonnement scientifique et logique de haut niveau
Un score de 75,2 au GPQA indique des performances solides sur des questions de niveau master/doctorat qui nécessitent une compréhension approfondie. - Solides compétences en ingénierie logicielle pratique
Le score de 59,2 au SWE-bench Verified est particulièrement remarquable. Ce benchmark utilise des problèmes et des bases de code GitHub réels. Un score à ce niveau signifie que le modèle peut lire des projets inconnus, localiser des bugs, modifier le code correctement et réussir les tests dans de nombreux scénarios réels. - Planification multi-étapes performante et raisonnement de type outil
Un score de 79,5 au τ²-Bench suggère qu’il gère bien les tâches complexes et multi-étapes, comme la décomposition d’objectifs, le maintien de l’état et l’exécution de plans. - Synthèse d’informations du monde réel
Un score de 42,8 au BrowseComp montre qu’il peut rechercher, filtrer et intégrer efficacement des informations externes par rapport à de nombreux autres modèles ouverts.
Dans la pratique, GLM 4.7 Flash est positionné comme un modèle rapide et polyvalent qui combine :
- Raisonnement de haut niveau
- Compétences en codage adaptées aux cas réels
- Gestion robuste des tâches multi-étapes
- Bonnes performances sur les tâches d’information de type web
Essayez GLM 4.7 Flash dès maintenant !
Exigences matérielles pour GLM 4.7 Flash
Pour exécuter GLM 4.7 Flash efficacement, les besoins matériels dépendent du mode de précision et de la quantification ; les GPU grand public peuvent être viables avec des versions optimisées.
Vous trouverez ci-dessous une répartition pratique pour les développeurs qui évaluent des déploiements locaux :
| Catégorie | Composant | Spécification |
|---|---|---|
| Configuration minimale | GPU | 24 Go de VRAM (RTX 3090, RTX 4090, A5000) |
| Mémoire système | 32 Go de RAM | |
| Stockage | 70 Go d’espace libre pour le modèle et la quantification | |
| Configuration recommandée | GPU | 48 Go de VRAM (RTX 6000 Ada, A6000) pour le contexte complet |
| Mémoire système | 64 Go de RAM pour les flux de travail multi-modèles | |
| Stockage | SSD NVMe pour un chargement rapide | |
| Puce Apple Silicon | Mac | M1, M2 ou M3 Max ou Ultra avec 48 Go ou plus de mémoire unifiée |
| Performances | Avec l’optimisation MLX, il atteint 60 à 80 tokens par seconde |
Comment utiliser GLM 4.7 Flash à un bon prix ?
Connectez GLM 4.7 Falsh de manière transparente à vos applications, flux de travail ou chatbots via l’API REST unifiée de Novita AI : pas besoin de gérer les poids du modèle ou l’infrastructure. Novita AI propose des SDK multilingues (Python, Node.js, cURL, etc.) et des contrôles de paramètres avancés pour les utilisateurs expérimentés.
Option 1 : Intégration API directe (exemple en Python)
Fonctionnalités clés :
- Point de terminaison unifié :
/v3/openaiprend en charge le format de l’API Chat Completions d’OpenAI. - Contrôles flexibles : Ajustez la température, le top-p, les pénalités et plus encore pour obtenir des résultats adaptés à vos besoins.
- Flux et traitement par lots : Choisissez le mode de réponse qui vous convient.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Essayez GLM 4.7 Flash dès maintenant !
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
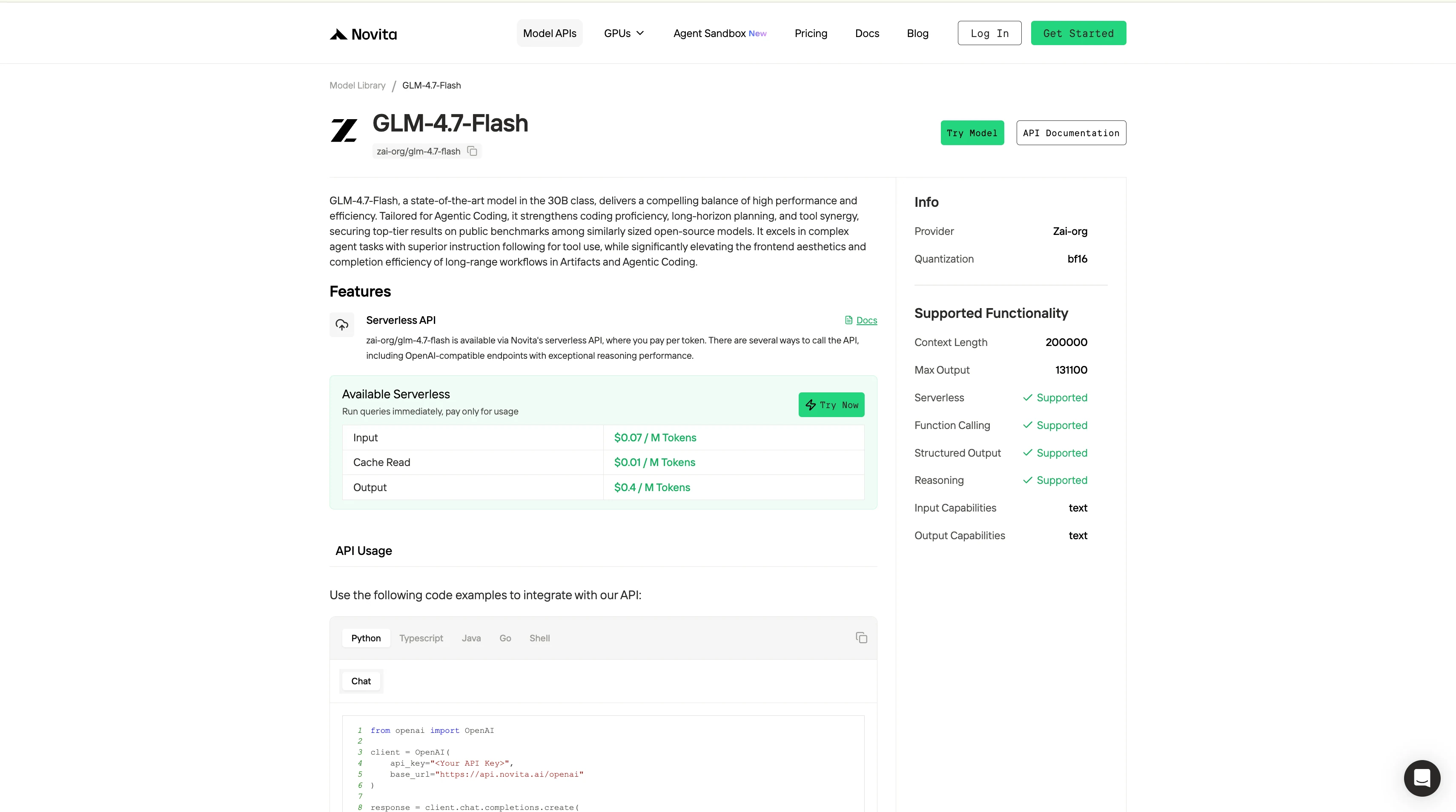
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En vous rendant sur la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
Option 2 : Flux de travail multi-agents avec le SDK OpenAI Agents
Construisez des systèmes multi-agents avancés en intégrant Novita AI au SDK OpenAI Agents :
- Prêt à l’emploi : Utilisez les LLMs de Novita AI dans tout flux de travail OpenAI Agents.
- Prend en charge les transferts, le routage et l’utilisation d’outils : Concevez des agents qui peuvent déléguer, trier ou exécuter des fonctions, le tout alimenté par les modèles de Novita AI.
- Intégration Python : Il suffit de pointer le SDK vers le point de terminaison de Novita (
https://api.novita.ai/v3/openai) et d’utiliser votre clé API.
Option 3:Connectez l’API GLM 4.7 Flash sur des plateformes tierces
- Hugging Face : Utilisez GLM 4.7 Falsh dans les Spaces, les pipelines ou avec la bibliothèque Transformers via les points de terminaison Novita AI.
- Frameworks d’agents et d’orchestration : Connectez facilement Novita AI à des plateformes partenaires comme Continue, AnythingLLM,LangChain, Dify et Langflow via des connecteurs officiels et des guides d’intégration étape par étape.
- API compatible OpenAI : Profitez d’une migration et d’une intégration sans problème avec des outils comme Cline et Cursor, conçus pour la norme d’API OpenAI.
Essayez GLM 4.7 Flash dès maintenant !
Avec sa grande fenêtre de contexte, son entraînement orienté agent, ses benchmarks solides et ses besoins GPU pratiques, GLM 4.7 Flash est l’un des rares modèles à pouvoir s’exécuter de manière fiable sur des centaines de milliers de tokens sans défaillance structurelle.
Pourquoi GLM 4.7 Flash est-il adapté aux agents locaux en exécution prolongée ?
GLM 4.7 Flash est entraîné pour des tâches agentiques avec une réflexion préservée et un grand contexte, ce qui évite la dérive lors de longues sessions.
Quelle taille de contexte GLM 4.7 Flash peut-il gérer en pratique ?
GLM 4.7 Flash prend en charge des fenêtres de contexte très grandes et reste stable sur des dizaines ou des centaines de milliers de tokens.
GLM 4.7 Flash peut-il fonctionner sur des GPU grand public ?
Oui, GLM 4.7 Flash peut fonctionner sur des GPU de 24 Go en utilisant une quantification 4 bits ou FP8.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle de projets.



