

Desenvolvedores que constroem fluxos de trabalho autônomos enfrentam um ponto de dor central: a maioria dos modelos tem degradação de desempenho após dezenas de milhares de tokens. Este guia avalia o GLM 4.7 Flash em arquitetura, benchmarks, velocidade de inferência e necessidades de hardware, oferecendo um caminho concreto para agentes locais estáveis e prontos para produção.
Experimente o GLM 4.7 Flash Agora!
Arquitetura do GLM 4.7 Flash
O GLM 4.7 Flash combina uma janela de contexto grande com uma estrutura MoE para equilibrar capacidade de raciocínio e eficiência de implantação local.
| Característica | Descrição |
|---|---|
| Classe de Parâmetros | Modelo MoE de 30B com 3,6B de parâmetros ativos por contexto de token |
| Janela de Contexto | Suporta até 200K tokens, permitindo histórico estendido e planejamento |
| Design de Raciocínio | Modos de pensamento intercalados e preservados para raciocínio multi-turno consistente |
Benchmarks do GLM 4.7 Flash
O GLM 4.7 Flash apresenta desempenho superior em benchmarks de raciocínio agentivo em comparação com pares da sua classe. Seus resultados de benchmarks indicam desempenho equilibrado em tarefas de codificação e raciocínio, fortalecendo a confiança em suas saídas em cadeias longas:
| Benchmark | GLM 4.7 Flash | Qwen3-30B | GPT-OSS-20B |
|---|---|---|---|
| AIME 25 | 91.6 | 85.0 | 91.7 |
| GPQA | 75.2 | 73.4 | 71.5 |
| SWE-bench Verified | 59.2 | 22.0 | 34.0 |
| τ²-Bench | 79.5 | 49.0 | 47.7 |
| BrowseComp | 42.8 | 2.29 | 28.3 |
Pela tabela, o GLM 4.7 Flash apresenta um perfil de capacidades muito equilibrado e de alto nível:
- Raciocínio matemático muito forte
A pontuação de 91,6 no AIME 25 significa que ele tem desempenho próximo a modelos de primeira linha em problemas de matemática de nível de competição. - Raciocínio científico e lógico de alto nível
A pontuação de 75,2 no GPQA indica desempenho sólido em questões de nível de pós-graduação que exigem compreensão profunda. - Força prática em engenharia de software
A pontuação de 59,2 no SWE-bench Verified é especialmente notável. Este benchmark usa issues e bases de código reais do GitHub. Uma pontuação nesse nível significa que o modelo pode ler projetos desconhecidos, localizar bugs, modificar o código corretamente e passar em testes em muitos cenários reais. - Planejamento multi-etapas forte e raciocínio estilo ferramenta
A pontuação de 79,5 no τ²-Bench sugere que ele lida bem com tarefas complexas e multiestágio, como dividir objetivos, manter o estado e executar planos. - Síntese de informações do mundo real
A pontuação de 42,8 no BrowseComp mostra que ele pode pesquisar, filtrar e integrar informações externas de forma eficaz em comparação com muitos outros modelos abertos.
Na prática, o GLM 4.7 Flash é posicionado como um modelo rápido e de propósito geral que combina:
- Raciocínio de alto nível
- Competência em codificação para cenários reais
- Tratamento robusto de tarefas multi-etapas
- Bom desempenho em tarefas de informação estilo web
Experimente o GLM 4.7 Flash Agora!
Requisitos de Hardware do GLM 4.7 Flash
Para executar o GLM 4.7 Flash de forma eficaz, as necessidades de hardware dependem do modo de precisão e da quantização; GPUs de consumo podem ser viáveis com compilações otimizadas.
Abaixo está uma divisão prática para desenvolvedores que avaliam implantações locais:
| Categoria | Componente | Especificação |
|---|---|---|
| Configuração Mínima | GPU | 24GB de VRAM (RTX 3090, RTX 4090, A5000) |
| Memória do Sistema | 32GB de RAM | |
| Armazenamento | 70GB de espaço livre para o modelo e quantização | |
| Configuração Recomendada | GPU | 48GB de VRAM (RTX 6000 Ada, A6000) para contexto completo |
| Memória do Sistema | 64GB de RAM para fluxos de trabalho com múltiplos modelos | |
| Armazenamento | SSD NVMe para carregamento rápido | |
| Apple Silicon | Mac | M1, M2 ou M3 Max ou Ultra com 48GB+ de memória unificada |
| Desempenho | Com otimização MLX, atinge de 60 a 80 tokens por segundo |
Como Usar o GLM 4.7 Flash por um Bom Preço?
Conecte o GLM 4.7 Flash de forma seamlessly às suas aplicações, fluxos de trabalho ou chatbots com a API REST unificada da Novita AI — não é necessário gerenciar pesos de modelo ou infraestrutura. A Novita AI oferece SDKs multilíngues (Python, Node.js, cURL e outros) e controles avançados de parâmetros para usuários avançados.
Opção 1: Integração Direta de API (Exemplo em Python)
Principais Funcionalidades:
- Endpoint unificado:
/v3/openaié compatível com o formato da API de Chat Completions da OpenAI. - Controles flexíveis: Ajuste temperatura, top-p, penalidades e mais para resultados personalizados.
- Streaming e lote: Escolha o modo de resposta de sua preferência.
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Experimente o GLM 4.7 Flash Agora!
Passo 3: Inicie Seu Teste Gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
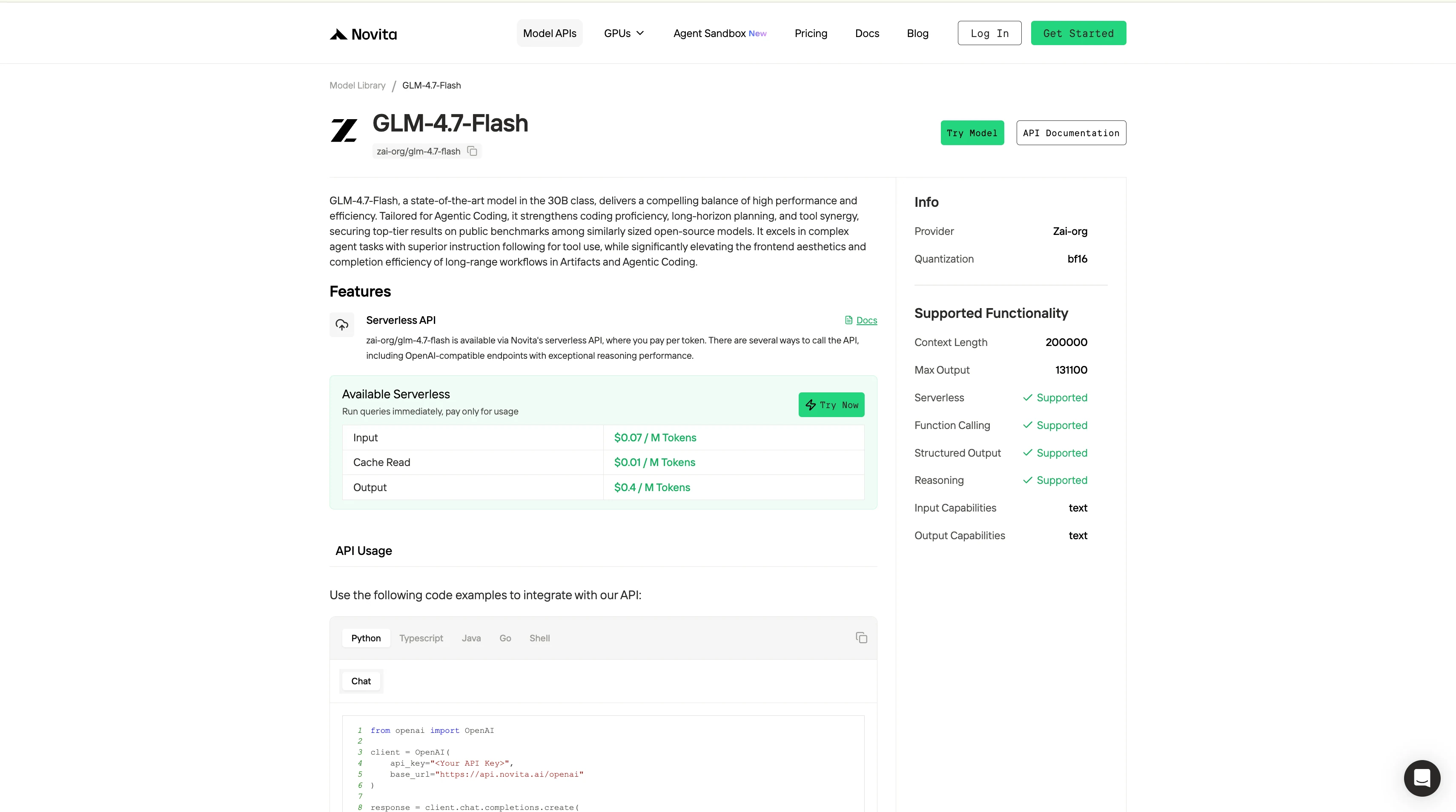
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API para você. Acessando a página de “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
Opção 2: Fluxos de Trabalho Multiagente com o SDK OpenAI Agents
Construa sistemas multiagente avançados integrando a Novita AI com o OpenAI Agents SDK:
- Plug-and-play: Use os LLMs da Novita AI em qualquer fluxo de trabalho do OpenAI Agents.
- Suporta transferências, roteamento e uso de ferramentas: Projete agentes que podem delegar, triar ou executar funções, todos alimentados pelos modelos da Novita AI.
- Integração com Python: Aponte o SDK simplesmente para o endpoint da Novita (
https://api.novita.ai/v3/openai) e use sua chave de API.
Opção 3:Conecte a API do GLM 4.7 Flash em Plataformas de Terceiros
- Hugging Face: Use o GLM 4.7 Flash em Spaces, pipelines ou com a biblioteca Transformers por meio dos endpoints da Novita AI.
- Frameworks de Agentes e Orquestração: Conecte a Novita AI facilmente com plataformas parceiras como Continue, AnythingLLM,LangChain, Dify e Langflow por meio de conectores oficiais e guias de integração passo a passo.
- API Compatível com OpenAI: Aproveite migração e integração sem complicações com ferramentas como Cline e Cursor, projetadas para o padrão da API da OpenAI.
Experimente o GLM 4.7 Flash Agora!
Com uma janela de contexto grande, treinamento voltado para agentes, benchmarks fortes e requisitos de GPU práticos, o GLM 4.7 Flash é um dos poucos modelos que pode ser executado de forma confiável por centenas de milhares de tokens sem falha estrutural.
Por que o GLM 4.7 Flash é adequado para agentes locais de execução prolongada?
O GLM 4.7 Flash é treinado para tarefas agentivas com pensamento preservado e contexto grande, evitando desvio em sessões longas.
Qual tamanho de contexto o GLM 4.7 Flash pode manipular na prática?
O GLM 4.7 Flash suporta janelas muito grandes e permanece estável em dezenas ou centenas de milhares de tokens.
O GLM 4.7 Flash pode ser executado em GPUs de consumo?
Sim, o GLM 4.7 Flash pode ser executado em GPUs de 24 GB usando quantização de 4 bits ou FP8.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer nuvem de GPU acessível e confiável para construção e escalonamento.



