

Los desarrolladores que crean flujos de trabajo autónomos se enfrentan a un problema clave: la mayoría de los modelos se degradan después de decenas de miles de tokens. Esta guía evalúa GLM 4.7 Flash en arquitectura, benchmarks, velocidad de inferencia y necesidades de hardware, ofreciendo un camino concreto hacia agentes locales estables y de nivel de producción.
Arquitectura de GLM 4.7 Flash
GLM 4.7 Flash combina una ventana de contexto grande con una estructura MoE para equilibrar la capacidad de razonamiento y la eficiencia en el despliegue local.
| Característica | Descripción |
|---|---|
| Clase de parámetros | Modelo MoE de 30B con 3.6B parámetros activos por contexto de token |
| Ventana de contexto | Soporta hasta 200K tokens, permitiendo historial extendido y planificación |
| Diseño de razonamiento | Modos de pensamiento intercalado y preservado para razonamiento consistente en múltiples turnos |
Benchmarks de GLM 4.7 Flash
GLM 4.7 Flash muestra un rendimiento superior en benchmarks de razonamiento agéntico en comparación con pares de su clase. Sus resultados en benchmarks indican un rendimiento equilibrado en tareas de codificación y razonamiento, fortaleciendo la confianza en sus resultados a lo largo de cadenas largas:
| Benchmark | GLM 4.7 Flash | Qwen3-30B | GPT-OSS-20B |
|---|---|---|---|
| AIME 25 | 91.6 | 85.0 | 91.7 |
| GPQA | 75.2 | 73.4 | 71.5 |
| SWE-bench Verified | 59.2 | 22.0 | 34.0 |
| τ²-Bench | 79.5 | 49.0 | 47.7 |
| BrowseComp | 42.8 | 2.29 | 28.3 |
Según la tabla, GLM 4.7 Flash muestra un perfil de capacidades muy equilibrado y de alto nivel:
- Razonamiento matemático muy sólido
AIME 25 con 91.6 significa que rinde cerca de los modelos de primer nivel en problemas matemáticos de competencia. - Razonamiento científico y lógico de alto nivel
GPQA con 75.2 indica un rendimiento sólido en preguntas de nivel de posgrado que requieren comprensión profunda. - Fortaleza práctica en ingeniería de software
SWE-bench Verified con 59.2 es especialmente notable. Este benchmark utiliza issues y repositorios reales de GitHub. Una puntuación a este nivel significa que el modelo puede leer proyectos desconocidos, localizar errores, modificar código correctamente y pasar pruebas en muchos escenarios reales. - Planificación de múltiples pasos y razonamiento tipo herramienta
τ²-Bench con 79.5 sugiere que maneja bien tareas complejas de múltiples etapas, como desglosar objetivos, mantener estado y ejecutar planes. - Síntesis de información del mundo real
BrowseComp con 42.8 muestra que puede buscar, filtrar e integrar información externa de manera efectiva en comparación con muchos otros modelos abiertos.
En términos prácticos, GLM 4.7 Flash está posicionado como un modelo rápido y de propósito general que combina:
- Razonamiento de alto nivel
- Competencia real en codificación
- Manejo robusto de tareas de múltiples pasos
- Buen rendimiento en tareas de información tipo web
Requisitos de hardware de GLM 4.7 Flash
Para ejecutar GLM 4.7 Flash de manera efectiva, las necesidades de hardware dependen del modo de precisión y la cuantización; las GPUs de consumo pueden ser viables con builds optimizados.
A continuación se presenta un desglose práctico para desarrolladores que evalúan despliegues locales:
| Categoría | Componente | Especificación |
|---|---|---|
| Configuración mínima | GPU | 24 GB VRAM (RTX 3090, RTX 4090, A5000) |
| Memoria del sistema | 32 GB RAM | |
| Almacenamiento | 70 GB de espacio libre para modelo y cuantización | |
| Configuración recomendada | GPU | 48 GB VRAM (RTX 6000 Ada, A6000) para contexto completo |
| Memoria del sistema | 64 GB RAM para flujos de trabajo con múltiples modelos | |
| Almacenamiento | NVMe SSD para carga rápida | |
| Apple Silicon | Mac | M1, M2 o M3 Max o Ultra con 48 GB+ de memoria unificada |
| Rendimiento | Con optimización MLX, alcanza de 60 a 80 tokens por segundo |
¿Cómo usar GLM 4.7 Flash a buen precio?
Conecta sin problemas GLM 4.7 Flash a tus aplicaciones, flujos de trabajo o chatbots con la API REST unificada de Novita AI, sin necesidad de gestionar pesos del modelo o infraestructura. Novita AI ofrece SDKs en varios lenguajes (Python, Node.js, cURL y más) y controles de parámetros avanzados para usuarios avanzados.
Opción 1: Integración directa con API (Ejemplo en Python)
Características clave:
- Endpoint unificado:
/v3/openaicompatible con el formato de API de Chat Completions de OpenAI. - Controles flexibles: Ajusta temperatura, top-p, penalizaciones y más para resultados personalizados.
- Streaming y batching: Elige tu modo de respuesta preferido.
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
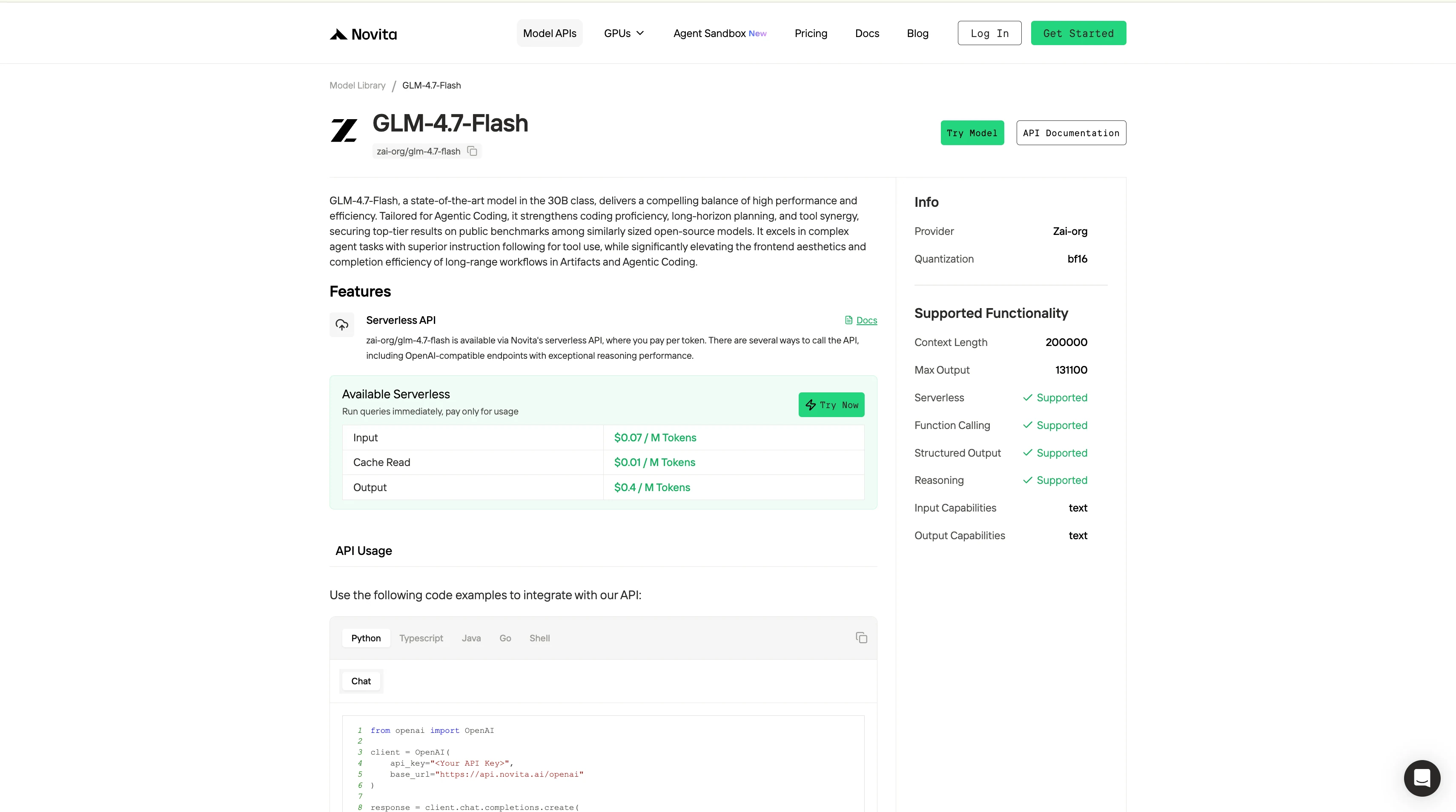
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página “Settings” y copia la clave API como se indica en la imagen.

from openai import OpenAI
client = OpenAI(
api_key="<Tu Clave API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
Opción 2: Flujos de trabajo multi-agente con el SDK de OpenAI Agents
Construye sistemas multi-agente avanzados integrando Novita AI con el SDK de OpenAI Agents:
- Plug-and-play: Usa los LLMs de Novita AI en cualquier flujo de trabajo de OpenAI Agents.
- Soporta traspasos, enrutamiento y uso de herramientas: Diseña agentes que puedan delegar, clasificar o ejecutar funciones, todo potenciado por los modelos de Novita AI.
- Integración en Python: Simplemente apunta el SDK al endpoint de Novita (
https://api.novita.ai/v3/openai) y usa tu clave API.
Opción 3:Conecta la API de GLM 4.7 Flash en plataformas de terceros
- Hugging Face: Usa GLM 4.7 Flash en Spaces, pipelines o con la biblioteca Transformers a través de los endpoints de Novita AI.
- Frameworks de agente y orquestación: Conecta fácilmente Novita AI con plataformas asociadas como Continue, AnythingLLM, LangChain, Dify y Langflow a través de conectores oficiales y guías de integración paso a paso.
- API compatible con OpenAI: Disfruta de una migración e integración sin complicaciones con herramientas como Cline y Cursor, diseñadas para el estándar de API de OpenAI.
Con una gran ventana de contexto, entrenamiento orientado a agentes, benchmarks sólidos y requisitos prácticos de GPU, GLM 4.7 Flash es uno de los pocos modelos que puede ejecutarse de manera confiable durante cientos de miles de tokens sin fallos estructurales.
¿Por qué GLM 4.7 Flash es adecuado para agentes locales de larga duración?
GLM 4.7 Flash está entrenado para tareas agénticas con pensamiento preservado y contexto grande, evitando la deriva en sesiones largas.
¿Qué tamaño de contexto puede manejar GLM 4.7 Flash en la práctica?
GLM 4.7 Flash admite ventanas muy grandes y se mantiene estable a lo largo de decenas o cientos de miles de tokens.
¿Puede GLM 4.7 Flash ejecutarse en GPUs de consumo?
Sí, GLM 4.7 Flash puede ejecutarse en GPUs de 24 GB usando cuantización de 4 bits o FP8.
Novita AI es una plataforma cloud de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA mediante nuestra API simple, al mismo tiempo que proporciona GPU cloud asequible y confiable para construir y escalar.



