

GLM-4.7 est le dernier LLM phare de Z.AI, conçu pour des flux de travail de niveau production : raisonnement multi-étapes, codage agentique et utilisation d’outils, sans sacrifier l’expérience de contexte long sur laquelle s’appuient les développeurs.
Cet article est une évaluation pratique de l’API GLM-4.7. Nous aborderons les points forts de GLM-4.7, ses cas d’usage les plus pertinents, et comment commencer à utiliser l’API GLM-4.7 rapidement, notamment via le endpoint serverless, facturé à la consommation de tokens et compatible OpenAI de Novita AI.
Essayez GLM 4.7 dès maintenant !
Performances de GLM-4.7
Les résultats des benchmarks suggèrent que les améliorations les plus marquées de GLM-4.7 concernent les flux de travail agentiques, l’utilisation d’outils et le codage de bout en bout — précisément les domaines où les applications pilotées par API sont les plus sensibles.
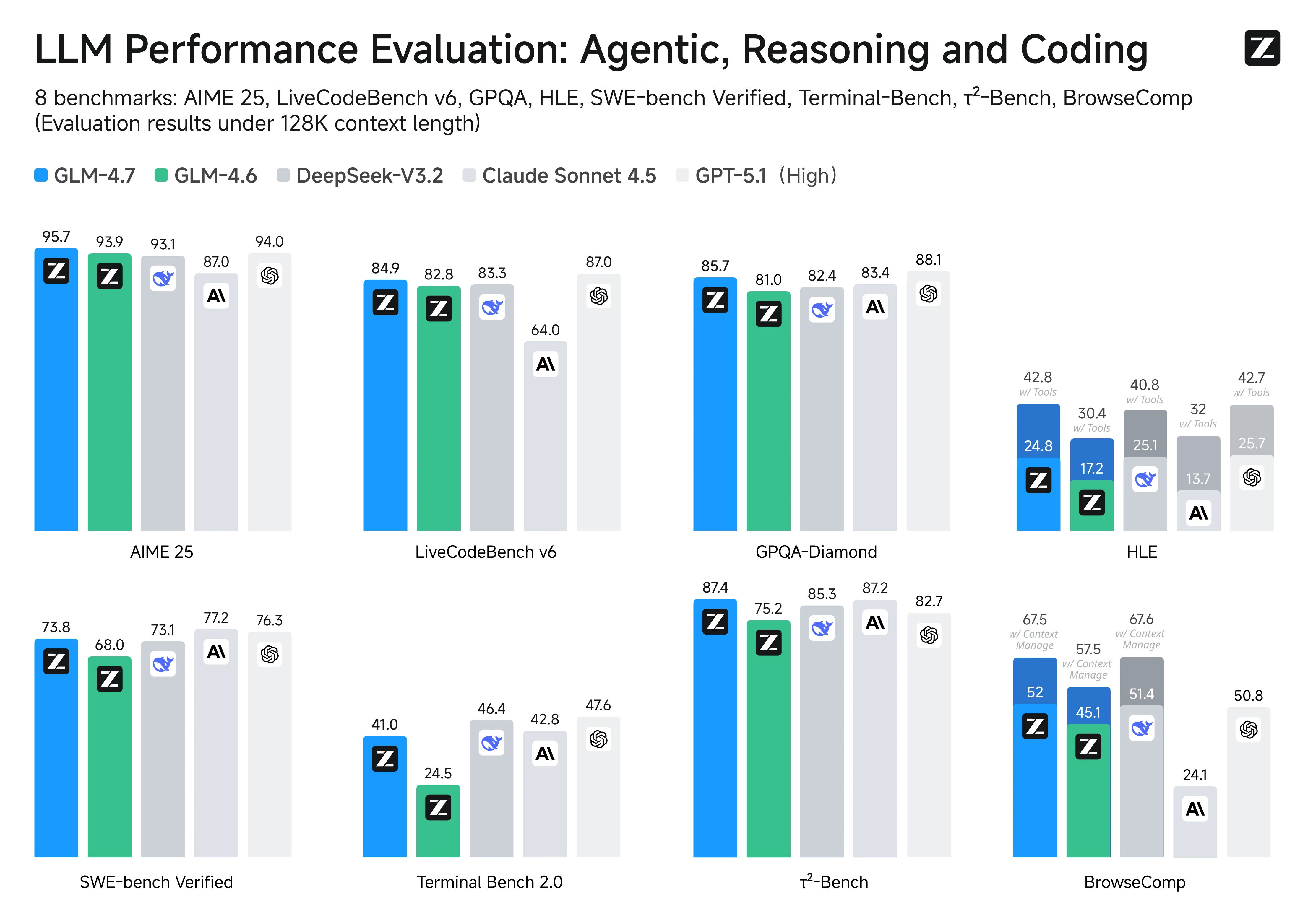
| Catégorie | Benchmark | Score GLM-4.7 |
| Flux de travail d’utilisation d’outils et agentiques | τ²-Bench | 87,4 |
| BrowseComp (avec gestion de contexte) | 67,5 | |
| Fiabilité du codage | SWE-bench Verified | 73,8 |
| Exécution d’agents de type terminal | Terminal Bench 2.0 | 41 |
| Raisonnement complexe avec outils | HLE (avec outils) | 42,8 |
💡 Ses points forts
Contexte long : Il arrive en tête sur BrowseComp, tant sur le score de base qu’avec la gestion de contexte, ce qui indique de solides performances sur les documents longs, la navigation web et la synthèse multi-sources.
Raisonnement : GLM-4.7 arrive en tête sur AIME 25 dans ce groupe, ce qui témoigne de performances supérieures en mathématiques et logique de haut niveau par rapport aux autres modèles concurrents.
Codage : GLM-4.7 obtient 73,8 sur SWE-bench Verified, devançant les modèles ouverts présentés dans le graphique.
Agents et outils : GLM-4.7 réalise une progression majeure sur TerminalBench 2.0 et atteint le score maximum sur HLE avec outils, ce qui est exactement ce que l’on attend d’agents devant manipuler des outils et accomplir des tâches multi-étapes.
Pourquoi l’API GLM-4.7 est importante : modèles ouverts vs modèles fermés
Lorsque l’on parle de « modèles open source », on fait généralement référence à des modèles à poids ouverts : les poids du modèle sont disponibles, ce qui permet un contrôle et une portabilité accrus. Les « modèles fermés » désignent quant à eux des modèles accessibles uniquement via l’API d’un seul fournisseur.
Pourquoi les développeurs choisissent les modèles ouverts
Les modèles ouverts sont attractifs car ils peuvent offrir :
- Contrôle et reproductibilité : épinglage de version et comportement cohérent dans le temps
- Portabilité et flexibilité : souplesse pour des stratégies multi-fournisseurs ou un hébergement autonome futur
- Flexibilité de gouvernance : selon votre organisation, les modèles ouverts peuvent simplifier les revues internes et les contraintes de déploiement
Pourquoi les modèles fermés restent populaires
Les modèles fermés peuvent offrir :
- Expérience clé en main : un packaging et des outils solides
- Itération centralisée : les améliorations peuvent être déployées rapidement
Point clé à retenir : Si un modèle ouvert comme GLM-4.7 arrive en tête d’un classement de préférence humaine, c’est un signal fort que les modèles ouverts peuvent concurrencer les modèles fermés sur la qualité des sorties prêtes à être déployées, et pas seulement sur le coût.
❓La question pratique se pose maintenant : Comment bénéficier des avantages des modèles ouverts tout en gardant une intégration simple ? ➡ C’est là qu’intervient Novita.
Pourquoi utiliser l’API Novita
Novita aide les équipes à déployer des modèles ouverts plus rapidement en proposant :
- API compatible OpenAI (intégration facile avec les SDK et outils existants)
- Inférence serverless (pas d’hébergement, de mise à l’échelle ou d’opérations GPU nécessaires)
- Une méthode unifiée pour appeler les modèles ouverts populaires, y compris GLM-4.7
Si votre équipe souhaite adopter des modèles ouverts mais ne veut pas gérer d’infrastructure, Novita permet de passer facilement de l’évaluation au prototype puis à la production.
Capacités du modèle (GLM-4.7 sur Novita)
- Longueur de contexte : 204 800 tokens
- Sortie maximale : 131 072 tokens
- Prend en charge l’appel de fonctions, les sorties structurées et le raisonnement
🙌Prêt à l’essayer ? GLM-4.7 sur Novita est tarifé à 0,60 $ par million de tokens d’entrée et 2,20 $ par million de tokens de sortie. Pour consulter les tarifs actuels (et les éventuelles promotions), rendez-vous sur la page de tarification de Novita.
Accéder à GLM-4.7 via Novita
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles Connectez-vous (ou inscrivez-vous) sur votre compte Novita AI et accédez à la bibliothèque de modèles.
Étape 2 : Sélectionnez GLM-4.7 Parcourez les modèles disponibles et sélectionnez GLM-4.7 en fonction des exigences de votre charge de travail.
Étape 3 : Démarrez votre essai gratuit Activez votre essai gratuit pour explorer les capacités de raisonnement, de contexte long et de rapport qualité-prix de GLM-4.7.
Étape 4 : Récupérez votre clé API Ouvrez la page des paramètres pour générer et copier votre clé API pour l’authentification.
Étape 5 : Installez et appelez l’API (exemple en Python) Voici un exemple simple utilisant l’API de complétions de chat avec Python :
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Cette configuration vous permet de contrôler la profondeur de raisonnement, l’utilisation de tokens et le comportement de génération — particulièrement utile lorsque vous exploitez la réflexion au niveau des tours de parole pour gérer les coûts et la latence.
Conclusion
La plus grande valeur de Design Arena est de transformer la qualité subjective en signaux mesurables grâce au vote de préférence humaine. Dans le classement des modèles open source, la note leader de GLM-4.7 indique que c’est une option solide pour les équipes qui attachent de l’importance à la qualité des sorties génératives prêtes à être déployées, tout en conservant la flexibilité des modèles ouverts.
Si vous souhaitez déployer GLM-4.7 en production rapidement, l’API compatible OpenAI de Novita vous permet de l’intégrer en peu de temps avec des modifications de code minimales, tout en vous offrant un contexte long, des sorties volumineuses et des fonctionnalités structurées adaptées aux flux de travail des applications modernes.
Foire aux questions
Qu’est-ce que GLM 4.7 ? GLM-4.7 est le LLM phare de Z.ai, conçu pour améliorer la programmation et offrir un raisonnement/exécution multi-étapes plus stable. Il est publié avec un modèle officiel à poids ouverts (disponible sur Hugging Face).
À quoi sert l’API GLM-4.7 ? L’API GLM-4.7 est couramment utilisée pour les flux de travail agentiques, l’appel d’outils et les tâches de codage nécessitant un contexte long et des sorties structurées stables.
Comment accéder rapidement à l’API GLM-4.7 ? Vous pouvez accéder à GLM-4.7 via un endpoint compatible OpenAI (par exemple Novita) en utilisant votre clé API et l’API de complétions de chat.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en proposant un cloud GPU abordable et fiable pour construire et mettre à l’échelle vos projets.



