

Chez Novita AI, nous sommes ravis d’annoncer que notre modèle DeepSeek a été amélioré pour prendre en charge une longueur de contenu de 160k, une avancée significative par rapport à la limite précédente de 128k. Cette mise à niveau vous permet désormais de traiter et d’analyser des ensembles de données encore plus volumineux en une seule fois, ce qui vous fait gagner du temps et améliore l’efficacité. Pour une durée limitée, les nouveaux utilisateurs peuvent obtenir 10 $ de crédits gratuits pour explorer les modèles DeepSeek améliorés et diverses autres API LLM sur Novita AI.
DeepSeek-R1-0528
Présentation
DeepSeek R1 0528 a été lancé le 28 mai 2025 en tant que modèle open-source de grande taille avec environ 685 milliards de paramètres. Il utilise une architecture Mixture-of-Experts (MoE), activant environ 37 milliards de paramètres par token lors de l’inférence. Le modèle prend en charge une longueur de contexte maximale de 128 000 tokens.
Le modèle excelle dans les domaines de la conversation, du raisonnement, du codage, des mathématiques et de l’appel de fonctions, avec un support supplémentaire pour la sortie JSON et les interfaces d’appel de fonctions, ce qui améliore considérablement sa capacité à gérer des tâches complexes. Il a été entraîné sur plus de 10 billions de tokens, comprenant du contenu web, du code, des données mathématiques et des documents, avec un accent particulier sur les capacités bilingues en anglais et en chinois.
L’entraînement a impliqué des méthodes traditionnelles d’apprentissage par renforcement à partir de feedback humain (RLHF) et de fine-tuning, combinées à d’importantes ressources de calcul et à des optimisations algorithmiques dans les phases ultérieures. Cette approche privilégie la précision et la fiabilité par rapport à l’efficacité, ce qui rend le modèle bien adapté aux applications d’entreprise, en particulier celles nécessitant un raisonnement complexe et une haute précision.
Benchmark
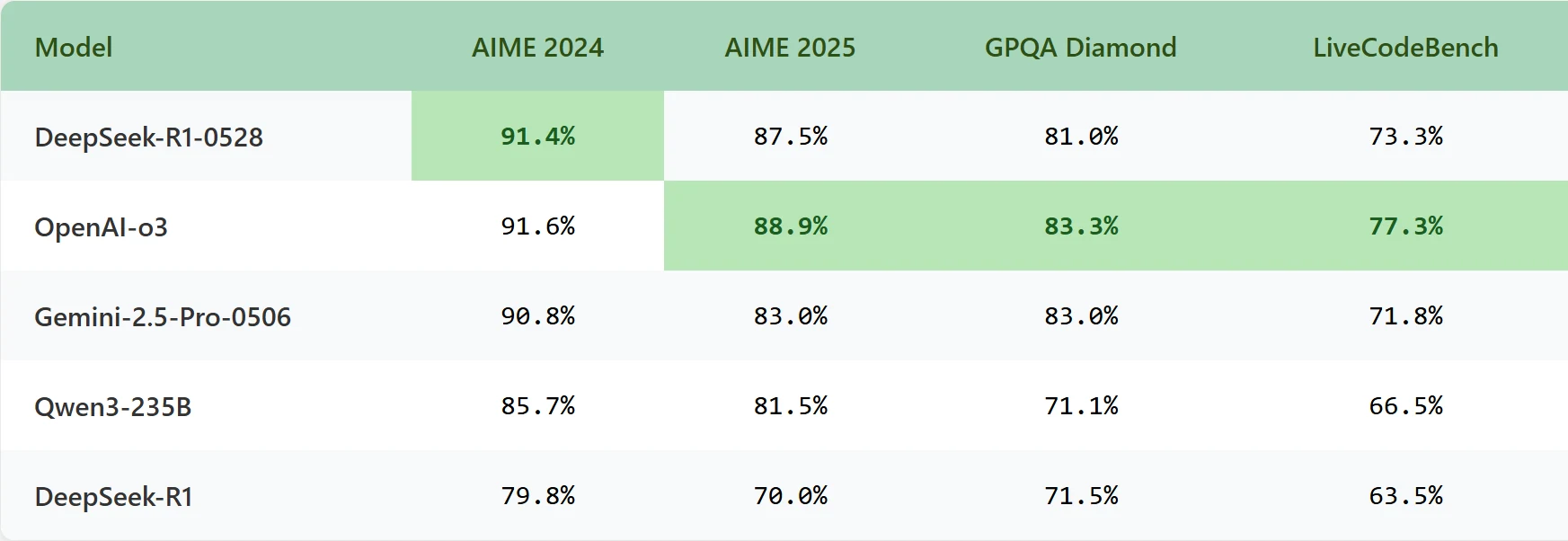
DeepSeek-V3-0324
Présentation
DeepSeek V3 0324 a été lancé le 25 mars 2025 en tant que modèle open-source de grande taille avec environ 671 milliards de paramètres, activant environ 37 milliards de paramètres par token lors de l’inférence. Il utilise une architecture Mixture-of-Experts (MoE) et prend en charge une longueur de contexte maximale de 160 000 tokens, ce qui le rend très performant pour traiter des entrées ultra-longues et générer des sorties étendues.
Le modèle est conçu pour exceller dans des tâches telles que les conversations multi-tours, le raisonnement approfondi, la génération de code et la résolution de problèmes mathématiques. La prise en charge multilingue améliorée, en particulier pour le chinois, et sa capacité multimodale texte-texte étendent encore sa polyvalence. Les données d’entraînement comprennent 14,8 billions de tokens provenant de sources variées, telles que le contenu web, les bases de code et les documents techniques, garantissant une base de connaissances solide pour des applications complexes.
DeepSeek V3 0324 utilise des techniques de pré-entraînement avancées et un fine-tuning post-entraînement adapté à des cas d’utilisation spécifiques. Cette approche complète, associée à d’importantes ressources de calcul, privilégie la précision, la cohérence et la fiabilité, ce qui rend le modèle idéal pour les industries nécessitant une génération de contenu longue, une résolution de problèmes complexes et des performances de niveau entreprise.
Benchmark
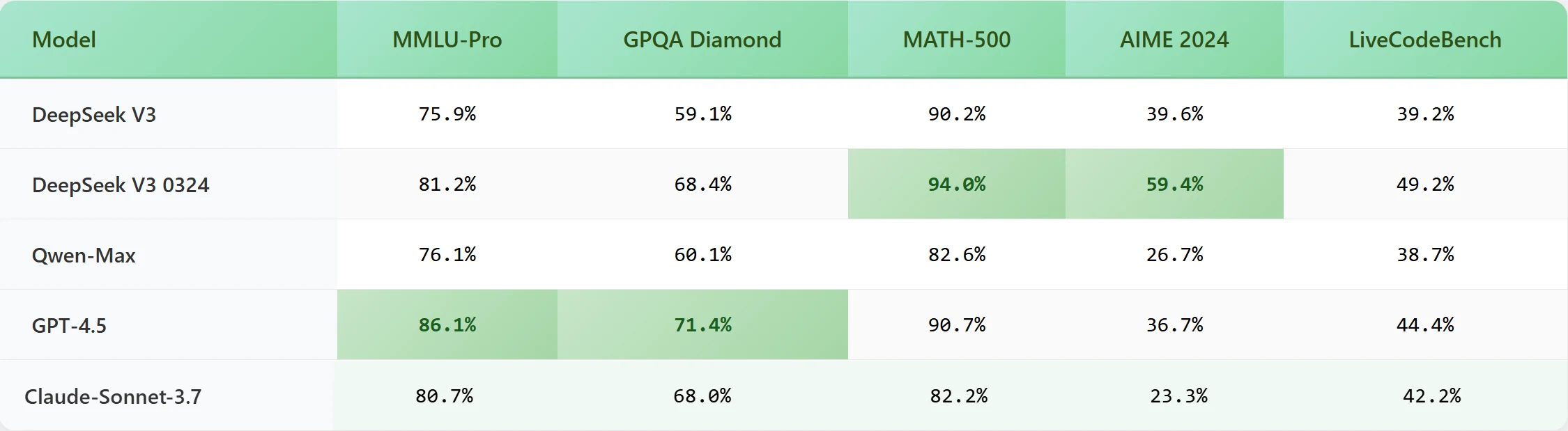
Longueur de contenu
Qu’est-ce que la longueur de contenu ?
Dans le contexte des modèles d’IA comme DeepSeek, la longueur de contenu désigne le nombre maximum de tokens (mots, ponctuation ou symboles) que le modèle peut traiter et générer en une seule interaction. Elle définit la quantité d’entrée que le modèle peut comprendre à la fois et la quantité de sortie qu’il peut produire. Une fenêtre de contexte plus grande permet à un modèle d’IA de traiter des entrées plus longues et d’intégrer une plus grande quantité d’informations dans chaque sortie.
Comment la longueur de contenu impacte-t-elle les performances ?
La longueur de contenu influence considérablement la capacité du modèle à :
- Comprendre le contexte : Des fenêtres de contexte plus longues permettent au modèle de se référer à davantage d’informations issues de l’entrée, réduisant ainsi les risques de perte de détails critiques.
- Générer des sorties cohérentes : Avec un accès au contexte complet, le modèle peut produire des réponses qui conservent une cohérence logique sur des sorties plus longues.
- Permettre un raisonnement complexe : Les tâches nécessitant un raisonnement en plusieurs étapes ou un suivi des états historiques, comme le codage, l’analyse technique ou la recherche approfondie, bénéficient grandement d’un contexte étendu.
Avantages de l’extension à 160k tokens
Avec la récente mise à niveau, DeepSeek-V3-0324 et DeepSeek-R1-0528 prennent désormais en charge une limite de 160 000 tokens, un bond significatif par rapport à la précédente fenêtre de contexte de 128k. Cette extension apporte plusieurs avantages clés :
- Prise en charge des conversations ultra-longues : La fenêtre de contexte étendue permet des dialogues multi-tours sans perdre le fil des interactions précédentes, idéale pour les tâches nécessitant une cohérence et une mémoire à long terme.
- Facilite l’analyse approfondie des agents : Les agents peuvent désormais analyser des ensembles de données plus volumineux ou effectuer un raisonnement plus approfondi sur de longues périodes, ouvrant de nouvelles possibilités pour des applications telles que la veille économique ou la recherche scientifique.
- Permet les applications à sortie longue : Des tâches comme la génération de code, le résumé de documents ou la génération de rapports détaillés peuvent désormais traiter des entrées plus volumineuses et complexes, fournissant des résultats complets en une seule sortie.
En élargissant la longueur de contenu, DeepSeek est désormais mieux équipé pour répondre aux exigences des flux de travail modernes, ce qui en fait un outil puissant pour les utilisateurs de divers secteurs.
Accéder à DeepSeek via Novita AI
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library .
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Commencez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier avec l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Settings », vous pouvez copier la clé API comme indiqué sur l’image.
Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de packages spécifique à votre langage de programmation.
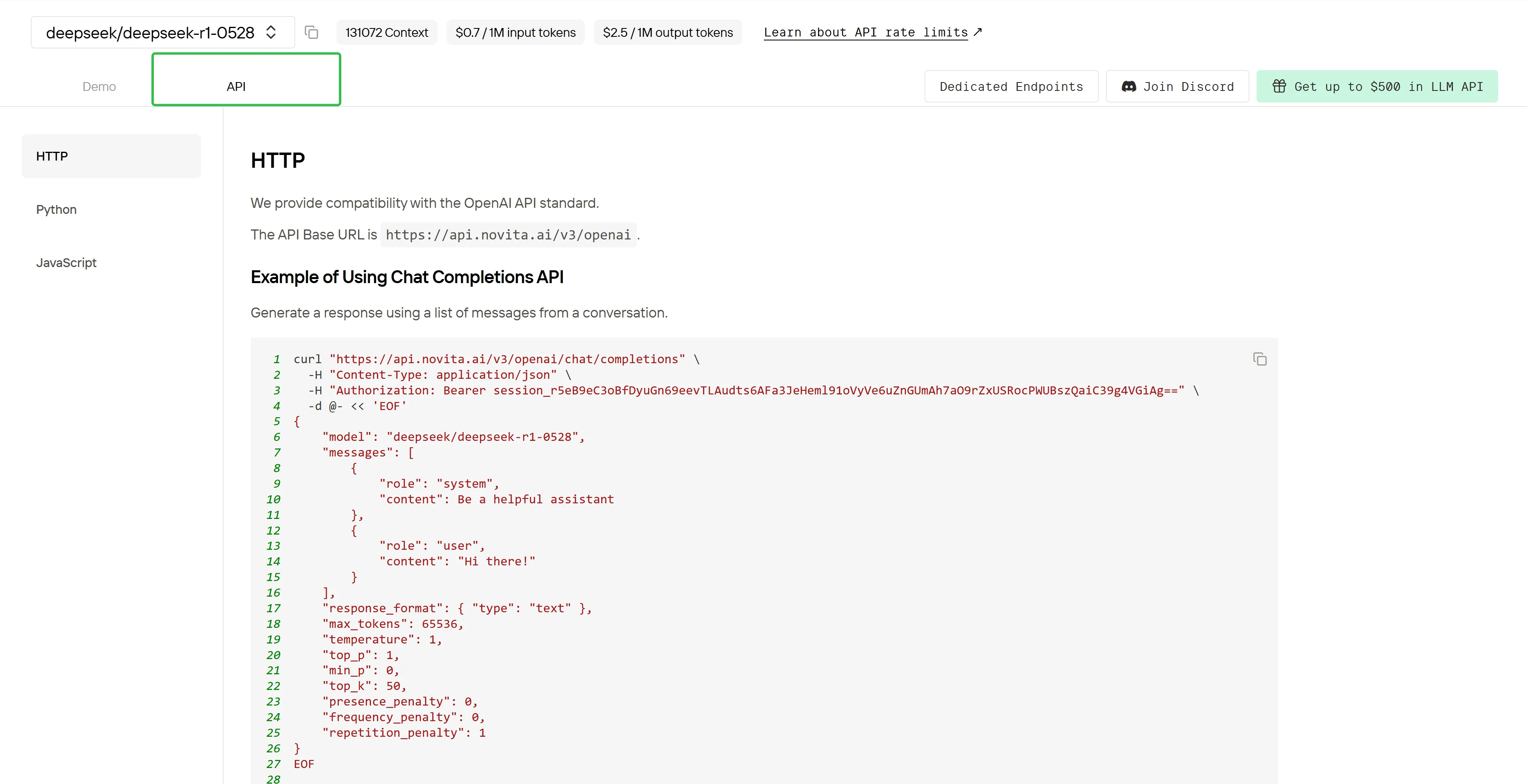
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python afin d’accéder à DeepSeek R1 0528.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_r5eB9eC3oBfDyuGn69eevTLAudts6AFa3JeHeml91oVyVe6uZnGUmAh7aO9rZxUSRocPWUBszQaiC39g4VGiAg==",
)
model = "deepseek/deepseek-r1-0528"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Novita AI propose à la fois DeepSeek R1 0528 et DeepSeek V3 0324 avec une longueur de contexte étendue, vous permettant de gérer des conversations plus longues et des projets plus complexes. Avec DeepSeek R1 0528 au prix de seulement 0,7 $ / 2,5 $ par million de tokens d’entrée/sortie et DeepSeek V3 0324 à un prix encore plus abordable de 0,28 $ / 1,14 $ par million de tokens, vous pouvez accéder à des performances d’IA de pointe sans dépasser votre budget. Pour une durée limitée, les nouveaux utilisateurs peuvent obtenir 10 $ de crédits gratuits pour explorer les modèles DeepSeek améliorés et diverses autres API LLM sur Novita AI.
Foire aux questions
Qu’est-ce que Deepseek V3 0324 ?
Deepseek V3 0324 est un modèle de langage de grande taille de pointe développé par DeepSeek, conçu pour la conversation générale, la compréhension et le raisonnement avancé.
Comment la longueur de contexte étendue profite-t-elle aux projets de codage ?
Avec un contexte étendu, vous pouvez partager des bases de code entières, maintenir le contexte entre plusieurs fichiers et travailler sur des tâches de refactorisation complexes sans perdre la trace des dépendances et des relations entre les différentes parties de votre code. Cela améliore considérablement la capacité de l’IA à fournir des suggestions précises et contextuellement pertinentes.
Quelle est une bonne longueur de contexte pour un LLM ?
Pour la plupart des applications, 32k à 128k tokens offrent d’excellentes performances, tandis que la longueur de contexte améliorée de 160k proposée par Novita AI vous garantit de pouvoir traiter même les documents les plus complexes et les conversations les plus longues sans aucune limitation.
À propos de Novita AI
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour créer et faire évoluer leurs applications.



