

En Novita AI, nos complace anunciar que nuestro modelo DeepSeek se ha actualizado para soportar una longitud de contenido de 160k, una mejora significativa respecto al límite anterior de 128k. Esta actualización significa que ahora puedes procesar y analizar conjuntos de datos aún más grandes en una sola ejecución, ahorrando tiempo y mejorando la eficiencia. Por tiempo limitado, los nuevos usuarios pueden reclamar $10 en créditos gratuitos para explorar los modelos DeepSeek actualizados y varias otras APIs de LLM en Novita AI.
DeepSeek-R1-0528
Introducción
DeepSeek R1 0528 se lanzó el 28 de mayo de 2025 como un modelo grande de código abierto con aproximadamente 685 mil millones de parámetros. Utiliza una arquitectura Mixture-of-Experts (MoE), activando alrededor de 37 mil millones de parámetros por token durante la inferencia. El modelo soporta una longitud máxima de contexto de 128K tokens.
El modelo sobresale en chat, razonamiento, codificación, matemáticas y llamadas a funciones, con soporte adicional para salida JSON e interfaces de llamada a funciones, mejorando significativamente su capacidad para manejar tareas complejas. Fue entrenado en más de 10 billones de tokens, incluyendo contenido web, código, datos matemáticos y documentos, con un fuerte enfoque en capacidades bilingües en inglés y chino.
El entrenamiento implicó aprendizaje por refuerzo tradicional a partir de feedback humano (RLHF) y métodos de fine-tuning, combinados con recursos computacionales sustanciales y optimizaciones algorítmicas en las etapas posteriores. Este enfoque prioriza la precisión y fiabilidad sobre la eficiencia, lo que hace que el modelo sea adecuado para aplicaciones empresariales, especialmente aquellas que requieren razonamiento complejo y alta precisión.
Benchmark
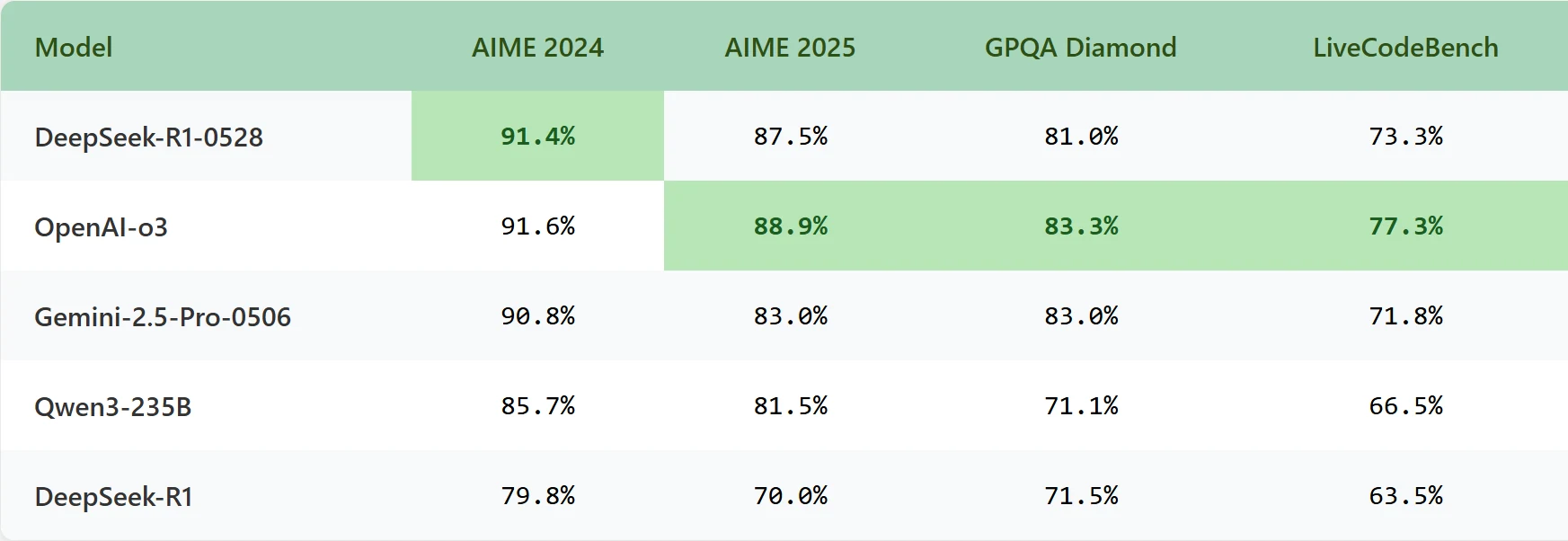
DeepSeek-V3-0324
Introducción
DeepSeek V3 0324 se lanzó el 25 de marzo de 2025 como un modelo grande de código abierto con aproximadamente 671 mil millones de parámetros, activando alrededor de 37 mil millones de parámetros por token durante la inferencia. Utiliza una arquitectura Mixture-of-Experts (MoE) y soporta una longitud máxima de contexto de 160K tokens, lo que lo hace altamente capaz de manejar entradas ultra largas y generar salidas extendidas.
El modelo está diseñado para sobresalir en tareas como conversaciones de múltiples turnos, razonamiento profundo, generación de código y resolución de problemas matemáticos. El soporte multilingüe mejorado, particularmente para chino, y su capacidad multimodal texto a texto amplían aún más su versatilidad. Los datos de entrenamiento incluyen 14.8 billones de tokens de diversas fuentes, como contenido web, bases de código y documentos técnicos, asegurando una base de conocimiento robusta para aplicaciones complejas.
DeepSeek V3 0324 emplea técnicas avanzadas de pre-entrenamiento y fine-tuning post-entrenamiento adaptadas a casos de uso específicos. Este enfoque integral, junto con amplios recursos computacionales, prioriza la precisión, coherencia y fiabilidad, haciendo que el modelo sea ideal para industrias que requieren generación de contenido de formato largo, resolución de problemas complejos y rendimiento de nivel empresarial.
Benchmark
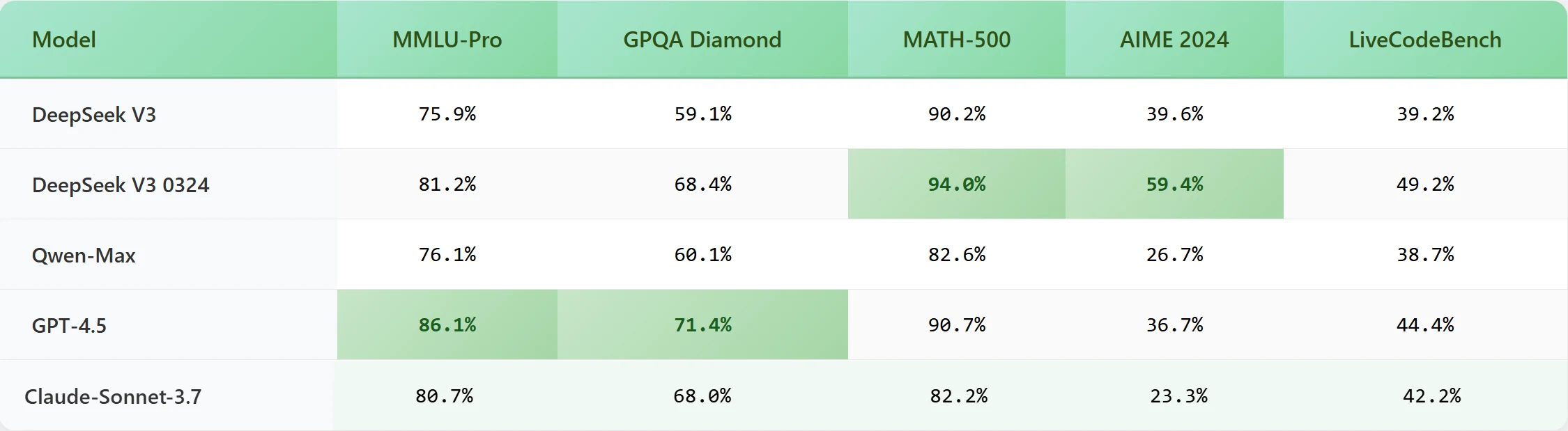
Longitud de contenido
¿Qué es la longitud de contenido?
En el contexto de modelos de IA como DeepSeek, la longitud de contenido se refiere al número máximo de tokens (palabras, puntuación o símbolos) que el modelo puede procesar y generar en una sola interacción. Define cuánta entrada puede entender el modelo a la vez y cuánta salida puede producir. Una ventana de contexto más grande permite que un modelo de IA procese entradas más largas e incorpore una mayor cantidad de información en cada salida.
¿Cómo afecta la longitud de contenido al rendimiento?
La longitud de contenido influye significativamente en la capacidad del modelo para:
- Entender el contexto: Las ventanas de contexto más largas permiten que el modelo haga referencia a más información de la entrada, reduciendo las posibilidades de perder detalles críticos.
- Generar salidas coherentes: Con acceso al contexto completo, el modelo puede producir respuestas que mantienen consistencia lógica a lo largo de salidas más largas.
- Habilitar razonamiento complejo: Las tareas que requieren razonamiento de múltiples pasos o seguimiento de estados históricos, como la codificación, el análisis técnico o la investigación profunda, se benefician enormemente de un contexto extendido.
Beneficios de la expansión a 160k tokens
Con la reciente actualización, DeepSeek-V3-0324 y DeepSeek-R1-0528 ahora soportan un límite de 160k tokens, un salto significativo respecto a la ventana de contexto anterior de 128k. Esta expansión trae varias ventajas clave:
- Soporta conversaciones ultra largas: La ventana de contexto extendida permite diálogos fluidos de múltiples turnos sin perder el rastro de interacciones previas, ideal para tareas que requieren consistencia y memoria a largo plazo.
- Facilita el análisis profundo de agentes: Los agentes ahora pueden analizar conjuntos de datos más grandes o realizar razonamientos más profundos durante períodos extendidos, desbloqueando nuevas posibilidades para aplicaciones como inteligencia empresarial o investigación científica.
- Habilita aplicaciones de salida larga: Tareas como generación de código, resumen de documentos o generación de informes detallados ahora pueden manejar entradas más grandes y complejas, proporcionando resultados completos en una sola salida.
Al expandir la longitud de contenido, DeepSeek está mejor equipado para manejar las demandas de los flujos de trabajo modernos, convirtiéndolo en una herramienta poderosa para usuarios de diversas industrias.
Acceder a DeepSeek a través de Novita AI
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.
Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página de “Settings“ y copia la clave API como se indica en la imagen.
Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico para tu lenguaje de programación.
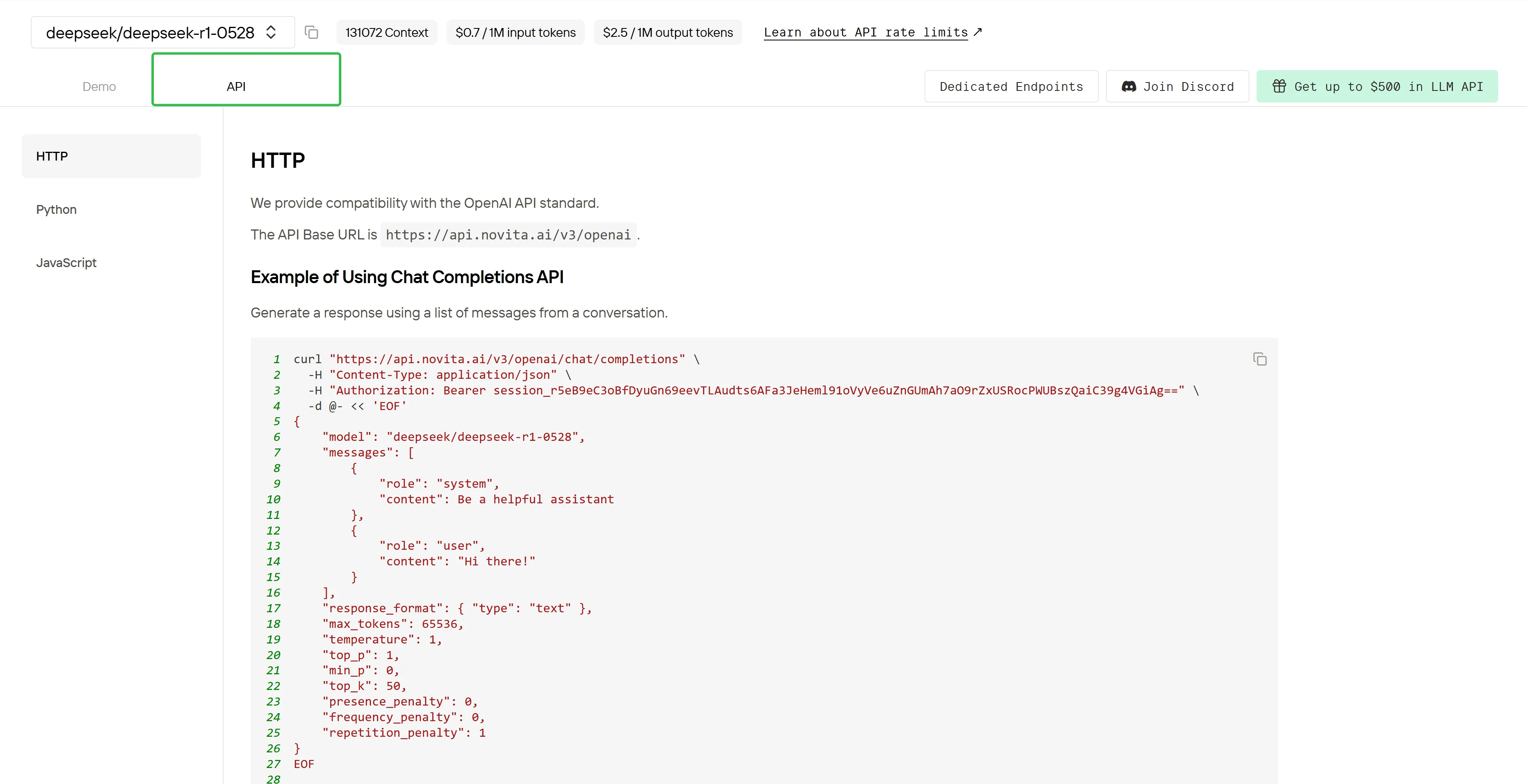
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python para acceder a DeepSeek R1 0528.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_r5eB9eC3oBfDyuGn69eevTLAudts6AFa3JeHeml91oVyVe6uZnGUmAh7aO9rZxUSRocPWUBszQaiC39g4VGiAg==",
)
model = "deepseek/deepseek-r1-0528"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Novita AI ofrece tanto DeepSeek R1 0528 como DeepSeek V3 0324 con longitud de contexto extendida, permitiéndote manejar conversaciones más largas y proyectos más complejos. Con DeepSeek R1 0528 con un precio de solo $0.7/$2.5 por 1M de tokens de entrada/salida y DeepSeek V3 0324 a un precio aún más asequible de $0.28/$1.14 por 1M de tokens, puedes acceder a un rendimiento de IA de vanguardia sin exceder tu presupuesto. Por tiempo limitado, los nuevos usuarios pueden reclamar $10 en créditos gratuitos para explorar los modelos DeepSeek actualizados y varias otras APIs de LLM en Novita AI.
Preguntas Frecuentes
¿Qué es Deepseek V3 0324?
Deepseek V3 0324 es un modelo de lenguaje grande de última generación de DeepSeek, diseñado para conversación general, comprensión y razonamiento avanzado.
¿Cómo beneficia la longitud de contexto extendida a los proyectos de codificación?
Con un contexto extendido, puedes compartir bases de código completas, mantener el contexto a través de múltiples archivos y trabajar en tareas complejas de refactorización sin perder el rastro de las dependencias y relaciones entre diferentes partes de tu código. Esto mejora drásticamente la capacidad de la IA para proporcionar sugerencias precisas y contextualmente relevantes.
¿Cuál es una buena longitud de contexto para un LLM?
Para la mayoría de las aplicaciones, de 32K a 128K tokens proporciona un rendimiento excelente, mientras que la longitud de contexto actualizada de 160K de Novita AI asegura que puedas manejar incluso los documentos más complejos y las conversaciones más extensas sin limitaciones.
Acerca de Novita AI
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona la GPU en la nube asequible y confiable para construir y escalar aplicaciones de IA.



