

Bei Novita AI freuen wir uns, bekannt zu geben, dass unser DeepSeek-Modell aktualisiert wurde und nun eine Kontextlänge von 160.000 Tokens unterstützt – eine deutliche Verbesserung gegenüber der vorherigen Grenze von 128.000. Dieses Upgrade bedeutet, dass Sie jetzt noch größere Datensätze in einem Durchgang verarbeiten und analysieren können, was Zeit spart und die Effizienz steigert. Für eine begrenzte Zeit können neue Nutzer 10 $ Gratisguthaben beanspruchen, um die aktualisierten DeepSeek-Modelle und verschiedene andere LLM-APIs auf Novita AI zu erkunden.
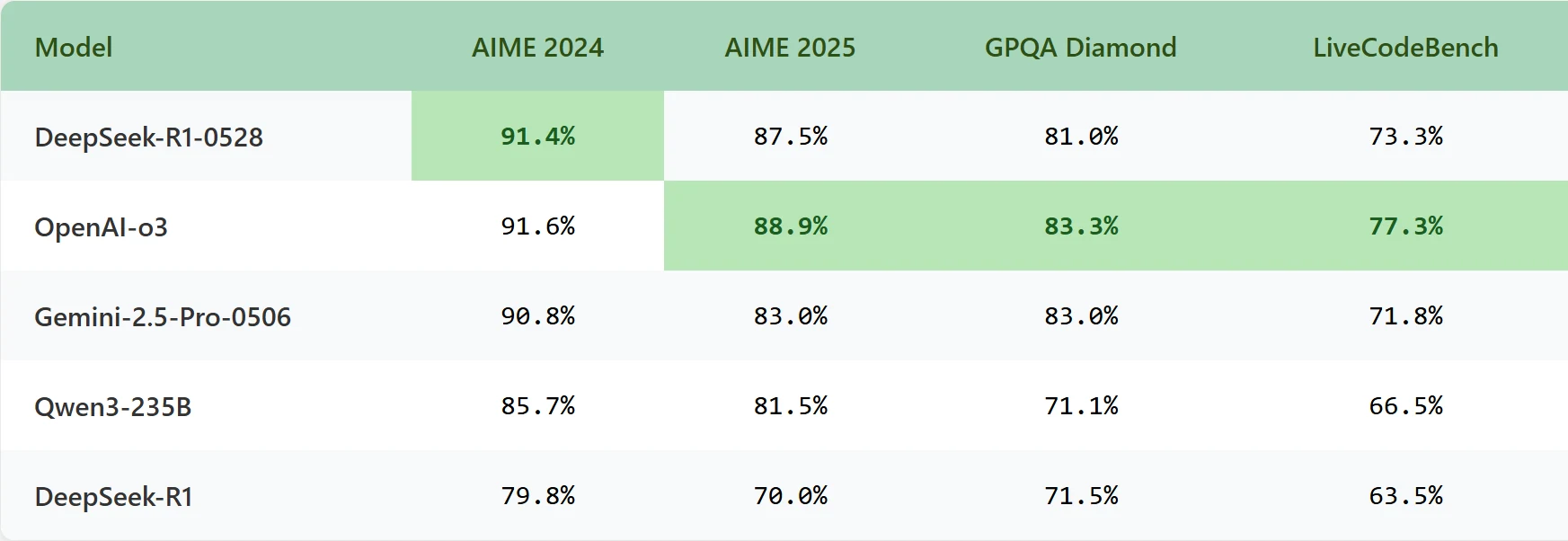
DeepSeek-R1-0528
Einführung
DeepSeek R1 0528 wurde am 28. Mai 2025 als Open-Source-Großmodell mit etwa 685 Milliarden Parametern veröffentlicht. Es verwendet eine Mixture-of-Experts (MoE)-Architektur und aktiviert während der Inferenz etwa 37 Milliarden Parameter pro Token. Das Modell unterstützt eine maximale Kontextlänge von 128K Tokens.
Das Modell zeichnet sich in den Bereichen Chat, Logik, Programmierung, Mathematik und Funktionsaufruf aus, mit zusätzlicher Unterstützung für JSON Ausgabe und Funktionsaufruf-Schnittstellen, was seine Fähigkeit zur Bewältigung komplexer Aufgaben erheblich verbessert. Es wurde mit über 10 Billionen Tokens trainiert, darunter Webinhalte, Code, Mathematikdaten und Dokumente, mit einem starken Fokus auf zweisprachige Fähigkeiten in Englisch und Chinesisch.
Das Training umfasste traditionelles Reinforcement Learning from Human Feedback (RLHF) und Feinabstimmungsmethoden, kombiniert mit erheblichen Rechenressourcen und algorithmischen Optimierungen in späteren Phasen. Dieser Ansatz priorisiert Genauigkeit und Zuverlässigkeit gegenüber Effizienz, was das Modell gut für Unternehmensanwendungen geeignet macht, insbesondere solche, die komplexe Logik und hohe Präzision erfordern.
Benchmark
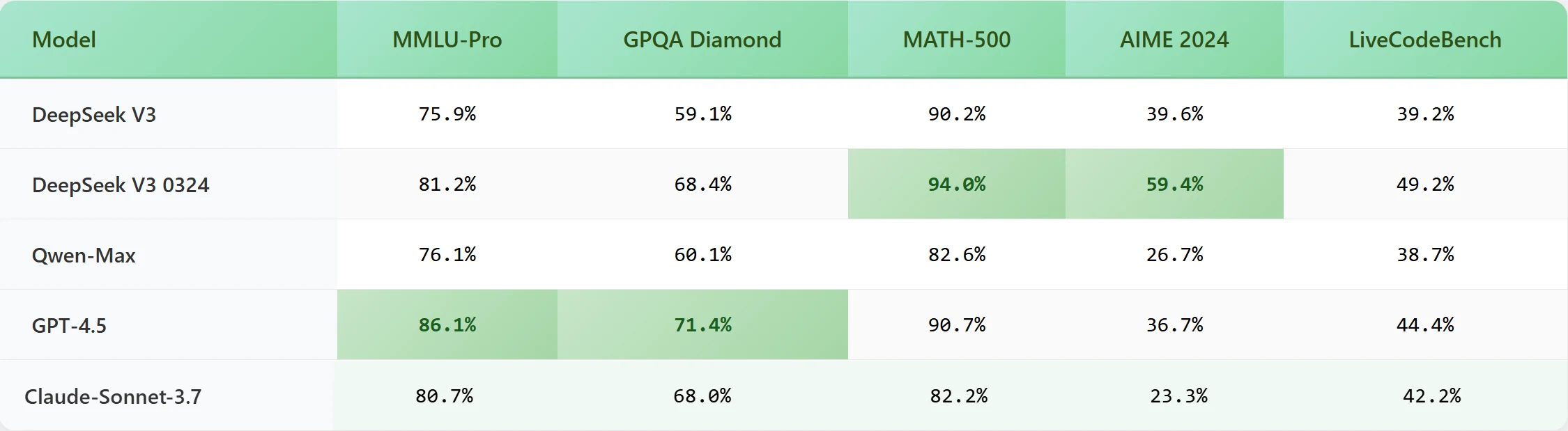
DeepSeek-V3-0324
Einführung
DeepSeek V3 0324 wurde am 25. März 2025 als Open-Source-Großmodell mit etwa 671 Milliarden Parametern veröffentlicht und aktiviert während der Inferenz etwa 37 Milliarden Parameter pro Token. Es verwendet eine Mixture-of-Experts (MoE)-Architektur und unterstützt eine maximale Kontextlänge von 160K Tokens, was es äußerst leistungsfähig bei der Verarbeitung ultra-langer Eingaben und der Erzeugung erweiterter Ausgaben macht.
Das Modell ist darauf ausgelegt, in Aufgaben wie Multi-Turn-Gesprächen, tiefgehender Logik, Codegenerierung und mathematischer Problemlösung zu glänzen. Die verbesserte mehrsprachige Unterstützung, insbesondere für Chinesisch, und seine Text-zu-Text-Multimodalität erweitern seine Vielseitigkeit weiter. Die Trainingsdaten umfassen 14,8 Billionen Tokens aus verschiedenen Quellen wie Webinhalten, Codebasen und technischen Dokumenten, was eine solide Wissensbasis für komplexe Anwendungen gewährleistet.
DeepSeek V3 0324 verwendet fortschrittliche Pre-Training-Techniken und Post-Training-Feinabstimmung, die auf spezifische Anwendungsfälle zugeschnitten sind. Dieser umfassende Ansatz zusammen mit umfangreichen Rechenressourcen priorisiert Genauigkeit, Kohärenz und Zuverlässigkeit, was das Modell ideal für Branchen macht, die Langform-Inhaltserzeugung, komplexe Problemlösung und Unternehmensleistung erfordern.
Benchmark
Kontextlänge
Was ist Kontextlänge?
Im Kontext von KI-Modellen wie DeepSeek bezieht sich Kontextlänge auf die maximale Anzahl von Tokens (Wörter, Satzzeichen oder Symbole), die das Modell in einer einzigen Interaktion verarbeiten und generieren kann. Sie definiert, wie viel Eingabe das Modell auf einmal verstehen und wie viel Ausgabe es produzieren kann. Ein größeres Kontextfenster ermöglicht es einem KI-Modell, längere Eingaben zu verarbeiten und eine größere Menge an Informationen in jede Ausgabe einzubeziehen.
Wie beeinflusst die Kontextlänge die Leistung?
Die Kontextlänge beeinflusst maßgeblich die Fähigkeit des Modells:
- Kontext zu verstehen: Längere Kontextfenster erlauben es dem Modell, mehr Informationen aus der Eingabe zu referenzieren, wodurch die Wahrscheinlichkeit verringert wird, kritische Details zu verlieren.
- Kohärente Ausgaben zu erzeugen: Mit Zugriff auf den vollständigen Kontext kann das Modell Antworten produzieren, die über längere Ausgaben hinweg logische Konsistenz bewahren.
- Komplexe Logik zu ermöglichen: Aufgaben, die mehrstufige Logik oder die Nachverfolgung historischer Zustände erfordern, wie Programmierung, technische Analyse oder tiefgehende Recherche, profitieren stark von erweitertem Kontext.
Vorteile der Erweiterung auf 160.000 Tokens
Mit dem aktuellen Upgrade unterstützen DeepSeek-V3-0324 und DeepSeek-R1-0528 nun ein Limit von 160.000 Tokens, ein bedeutender Sprung gegenüber dem vorherigen Kontextfenster von 128.000. Diese Erweiterung bringt mehrere wichtige Vorteile:
- Unterstützt Ultra-lange Gespräche: Das erweiterte Kontextfenster ermöglicht nahtlose Multi-Turn-Dialoge, ohne den Überblick über vorherige Interaktionen zu verlieren – ideal für Aufgaben, die langfristige Konsistenz und Gedächtnis erfordern.
- Ermöglicht tiefgehende Agentenanalyse: Agenten können jetzt größere Datensätze analysieren oder über längere Zeiträume hinweg tiefere Logik anwenden, was neue Möglichkeiten für Anwendungen wie Business Intelligence oder wissenschaftliche Forschung eröffnet.
- Ermöglicht Anwendungen mit langen Ausgaben: Aufgaben wie Codegenerierung, Dokumentenzusammenfassung oder detaillierte Berichterstellung können jetzt größere und komplexere Eingaben verarbeiten und liefern umfassende Ergebnisse in einer einzigen Ausgabe.
Durch die Erweiterung der Kontextlänge ist DeepSeek nun besser gerüstet, um die Anforderungen moderner Arbeitsabläufe zu erfüllen, was es zu einem leistungsstarken Werkzeug für Benutzer in verschiedenen Branchen macht.
Zugriff auf DeepSeek über Novita AI
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie auf die Seite „Einstellungen“ und kopieren Sie den API-Schlüssel wie im Bild gezeigt.
Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit der Interaktion mit Novita AI LLM zu beginnen. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer, um auf DeepSeek R1 0528 zuzugreifen.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_r5eB9eC3oBfDyuGn69eevTLAudts6AFa3JeHeml91oVyVe6uZnGUmAh7aO9rZxUSRocPWUBszQaiC39g4VGiAg==",
)
model = "deepseek/deepseek-r1-0528"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Novita AI bietet sowohl DeepSeek R1 0528 als auch DeepSeek V3 0324 mit erweiterter Kontextlänge an, sodass Sie längere Gespräche und komplexere Projekte bewältigen können. Mit einem Preis von nur 0,70 $/2,50 $ pro 1 Million Eingabe-/Ausgabetokens für DeepSeek R1 0528 und sogar noch günstigeren 0,28 $/1,14 $ pro 1 Million Tokens für DeepSeek V3 0324 erhalten Sie hochmoderne KI-Leistung, ohne Ihr Budget zu sprengen. Für eine begrenzte Zeit können neue Nutzer 10 $ Gratisguthaben beanspruchen, um die aktualisierten DeepSeek-Modelle und verschiedene andere LLM-APIs auf Novita AI zu erkunden.
Häufig gestellte Fragen
Was ist Deepseek V3 0324?
Deepseek V3 0324 ist ein hochmodernes großes Sprachmodell von DeepSeek, das für allgemeine Konversation, Verständnis und fortgeschrittene Logik entwickelt wurde.
Wie kommt die erweiterte Kontextlänge Programmierprojekten zugute?
Mit dem erweiterten Kontext können Sie gesamte Codebasen teilen, den Kontext über mehrere Dateien hinweg beibehalten und an komplexen Refactoring-Aufgaben arbeiten, ohne den Überblick über Abhängigkeiten und Beziehungen zwischen verschiedenen Teilen Ihres Codes zu verlieren. Dies verbessert die Fähigkeit der KI, genaue, kontextrelevante Vorschläge zu liefern, erheblich.
Was ist eine gute Kontextlänge für ein LLM?
Für die meisten Anwendungen bieten 32K–128K Tokens eine hervorragende Leistung, während die aktualisierte 160K-Kontextlänge von Novita AI sicherstellt, dass Sie selbst die komplexesten Dokumente und erweiterten Gespräche ohne Einschränkungen bewältigen können.
Über Novita AI
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für den Aufbau von Anwendungen bereitstellt.



