

DeepSeek V3.1 représente une évolution majeure des modèles de langage open source, en particulier pour les développeurs spécialisés dans les tâches de génération de code.
Pour les développeurs, accéder à DeepSeek V3.1 via des fournisseurs d’API élimine le besoin de matériel massif : l’auto-hébergement nécessite environ 1424 Go de VRAM sur 8 GPU H100, ce qui permet de se concentrer sur l’intégration et la mise à l’échelle.
Ce blog évalue trois fournisseurs majeurs — Novita AI, Together AI et Deepinfra — sur la base de facteurs clés : coût et tarification, performances et fiabilité, scalabilité, sécurité et conformité, facilité d’intégration et documentation, support et communauté, expérience du fournisseur, fonctionnalités et localisation.
Facteurs clés pour choisir un fournisseur d’API IA
Le choix d’un fournisseur d’API IA nécessite une évaluation multidimensionnelle pour garantir que la solution sélectionnée répond non seulement aux besoins immédiats du projet, mais soutient également la croissance à long terme et la conformité.
| Facteur | Description |
|---|---|
| Coût et tarification | Modèles transparents adaptés au budget |
| Performances et fiabilité | Faible latence, haute disponibilité |
| Scalabilité | Gérer la croissance sans accroc |
| Sécurité et conformité | Protection des données et réglementations |
| Fonctionnalités | Modèle adapté aux tâches |
| Facilité d’intégration | Documentation et outils pour la configuration |
| Support et communauté | Aide réactive et retours utilisateurs |
| Expérience du fournisseur | Historique et expertise |
| Localisation | Support linguistique et culturel optimisé |
Considérations principales
Lors du choix d’un fournisseur d’API IA, équilibrez les besoins spécifiques de votre projet — comme la génération de code ou les tâches de traitement du langage naturel — avec vos contraintes budgétaires. Des facteurs tels que les fonctionnalités et la compatibilité garantissent que l’API s’aligne sur votre stack technologique, tandis que des modèles de tarification basés sur les tokens ou des abonnements par paliers permettent de gérer les coûts efficacement.
Aspects techniques
Privilégiez la qualité du modèle, la latence (idéalement inférieure à 2 à 5 secondes pour une utilisation interactive) et la scalabilité pour gérer des charges accrues. Les fonctionnalités de sécurité, notamment le chiffrement et la conformité à des normes comme le RGPD, protègent l’intégrité des données.
Facteurs supplémentaires
Prenez en compte l’expérience du fournisseur, les options de personnalisation et le support de localisation si vous travaillez avec des langues ou des régions spécifiques. Les retours de la communauté et les tests pilotes peuvent révéler les performances en conditions réelles, vous aidant à éviter les risques de verrouillage.
Fournisseurs d’API DeepSeek V3.1
Des recherches montrent que lors du choix d’un fournisseur d’API DeepSeek V3.1, des facteurs comme le coût, les performances et la scalabilité jouent un rôle clé. Novita AI, Together AI et Deepinfra prennent en charge les modes hybrides du modèle, mais des différences de tarification et de vitesse pourraient avoir un impact sur les applications en conditions réelles.
Fournisseurs d’API DeepSeek V3.1 - Novita AI : Abordable pour des déploiements rapides
Novita AI s’est positionné comme un adoptant précoce de DeepSeek V3.1, y compris la variante Terminus, qui améliore la cohérence des sorties pour le codage et l’utilisation d’outils.
Coût et tarification :
Novita AI propose des API avec un contexte de 131 000 tokens, pour un coût de 0,27 $ par entrée et 1,0 $ par sortie, prenant en charge les sorties structurées et l’appel de fonctions, ce qui offre un soutien solide pour maximiser le potentiel d’agent de code de DeepSeek V3.1.
Essayez DeepSeek V3.1 dès maintenant !
Performances et fiabilité :
Novita prend en charge une fenêtre de contexte de 131 000 tokens, des modes de réflexion et des sorties structurées, avec un temps jusqu’au premier token (TTFT) rapide et un nombre de tokens par seconde (TPS) élevé, démontré lors de tests dans l’environnement de test.
Scalabilité :
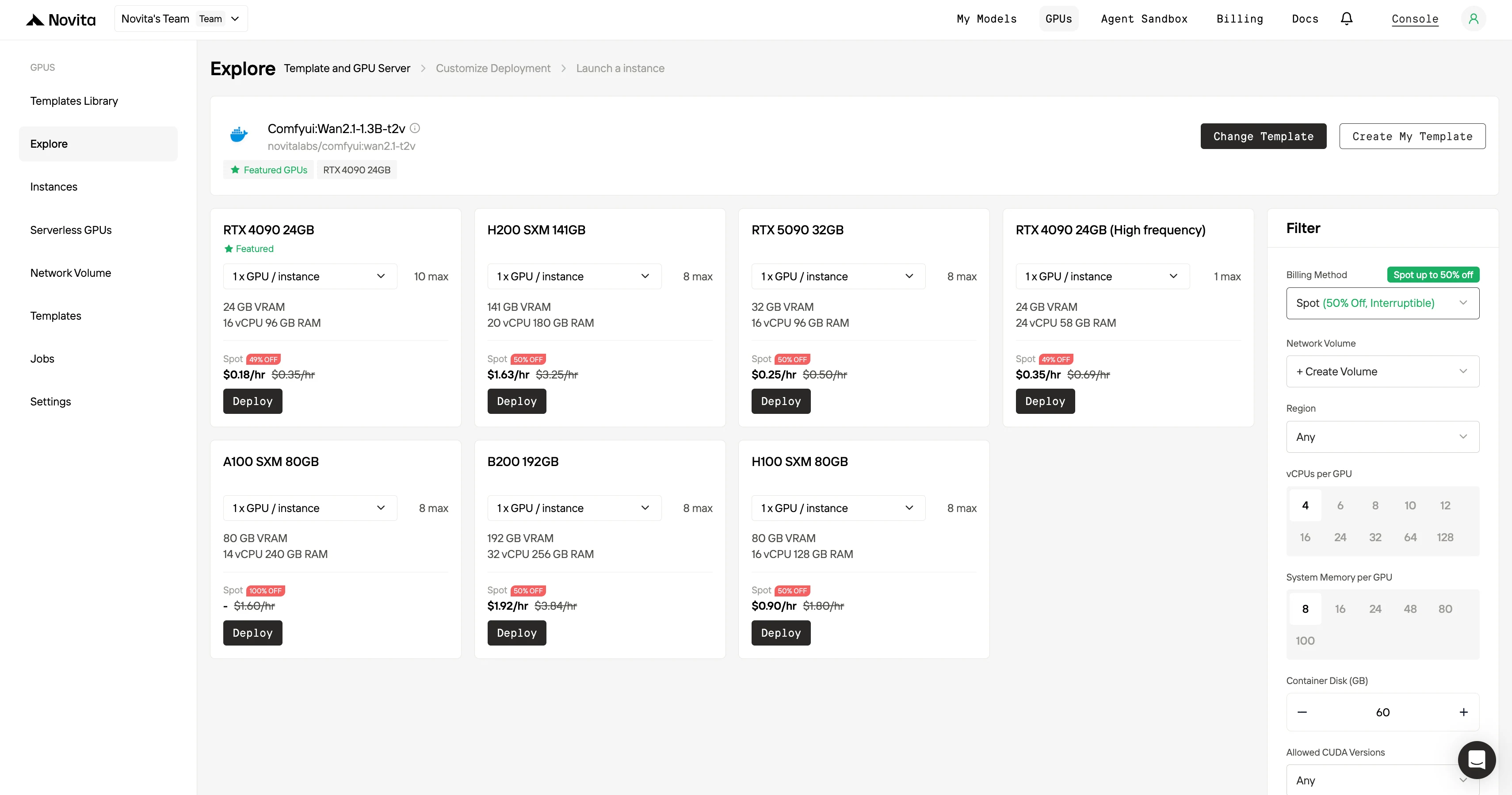
Conçu pour des déploiements de GPU serverless et à la demande, il gère la croissance via l’auto-scaling, et est adapté aux tâches agentiques dans les flux de travail de code. Novita AI propose des GPU serverless et un modèle de tarification spot qui peut réduire les coûts jusqu’à 50 %, tout en permettant de basculer de manière transparente entre différents GPU pour maintenir la scalabilité ; consultez l’article de blog référencé pour plus de détails.Instances Spot vs. à la demande : Guide de décision rapide
| Instance (GPU) | Prix à la demande | Prix Spot |
|---|---|---|
| RTX 5090 | 0,50 $ par heure | 0,25 $ par heure |
| RTX 4090 | 0,35 $ par heure | 0,18 $ par heure |
| RTX 4090 haute fréquence | 0,69 $ par heure | 0,35 $ par heure |
| H200 SXM | 3,25 $ par heure | 1,63 $ par heure |
| A100 SXM | / | 1,60 $ par heure |
| B200 | 3,84 $ par heure | 1,92 $ par heure |
| H100 SXM | 1,00 $ par heure | 0,90 $ par heure |
Lancez votre première instance Spot dès maintenant
Sécurité et conformité : En tant que fournisseur cloud, il inclut un chiffrement standard et une authentification par clé API ; aucun incident majeur n’a été signalé dans les avis.
Facilité d’intégration et documentation : La documentation couvre efficacement les points de terminaison de complétion et de chat.
En utilisant le service de Novita AI, vous pouvez contourner les restrictions régionales de Claude Code. Novita propose également des garanties de niveau de service (SLA) avec une stabilité de service de 99 %, ce qui le rend particulièrement adapté aux scénarios à haute fréquence comme la génération de code et les tests automatisés.
En plus de DeepSeek V3.1, les utilisateurs peuvent également accéder à des modèles de codage puissants comme Kimi-k2 et Qwen3 Coder, dont les performances sont proches de celles du Sonnet 4 closed-source de Claude, pour moins d’un cinquième du coût. Novita AI propose également des guides d’accès pour Trae et Qwen Code, que vous pouvez trouver dans les articles suivants.
Par ailleurs, vous pouvez facilement connecter Novita AI à des plateformes partenaires comme Continue, AnythingLLM, LangChain, Dify et Langflow via des connecteurs officiels et des guides d’intégration étape par étape.

Support et communauté : Support 24/7 via Discord et email, avec une présence active sur X pour les mises à jour ; les retours de la communauté sur Reddit louent l’abordabilité mais notent des baisses de qualité occasionnelles par rapport aux API officielles.
Expérience du fournisseur et fonctionnalités : Expérimenté dans les API LLM et le cloud GPU, Novita excelle dans des fonctionnalités spécifiques au code comme l’appel de fonctions.
Localisation : Principalement axé sur l’anglais, avec une prise en charge multilingue partielle des modèles.
Dans l’ensemble, Novita AI convient aux développeurs soucieux de leur budget qui ont besoin d’un accès rapide et riche en fonctionnalités pour leurs expériences de génération de code.
Essayez DeepSeek V3.1 dès maintenant !
Fournisseurs d’API DeepSeek V3.1 - Together AI : Optimisé pour la production haute performance
Together AI met l’accent sur une infrastructure pour des modèles massifs comme DeepSeek V3.1, en s’appuyant sur son AI Native Cloud pour un fonctionnement transparent en mode hybride.
Coût et tarification :
Estimé à 0,60 $ par entrée / 1,70 $ par sortie par million de tokens, il est tarifé comme une offre premium mais justifié par des optimisations comme ATLAS, qui s’adapte aux charges de travail pour plus d’efficacité. La scalabilité transparente permet de gérer le coût total de possession (TCO).
Performances et fiabilité :
ATLAS offre une inférence jusqu’à 4 fois plus rapide et 500 TPS sur V3.1, avec des SLA de disponibilité de 99,9 % garantissant la stabilité en production.
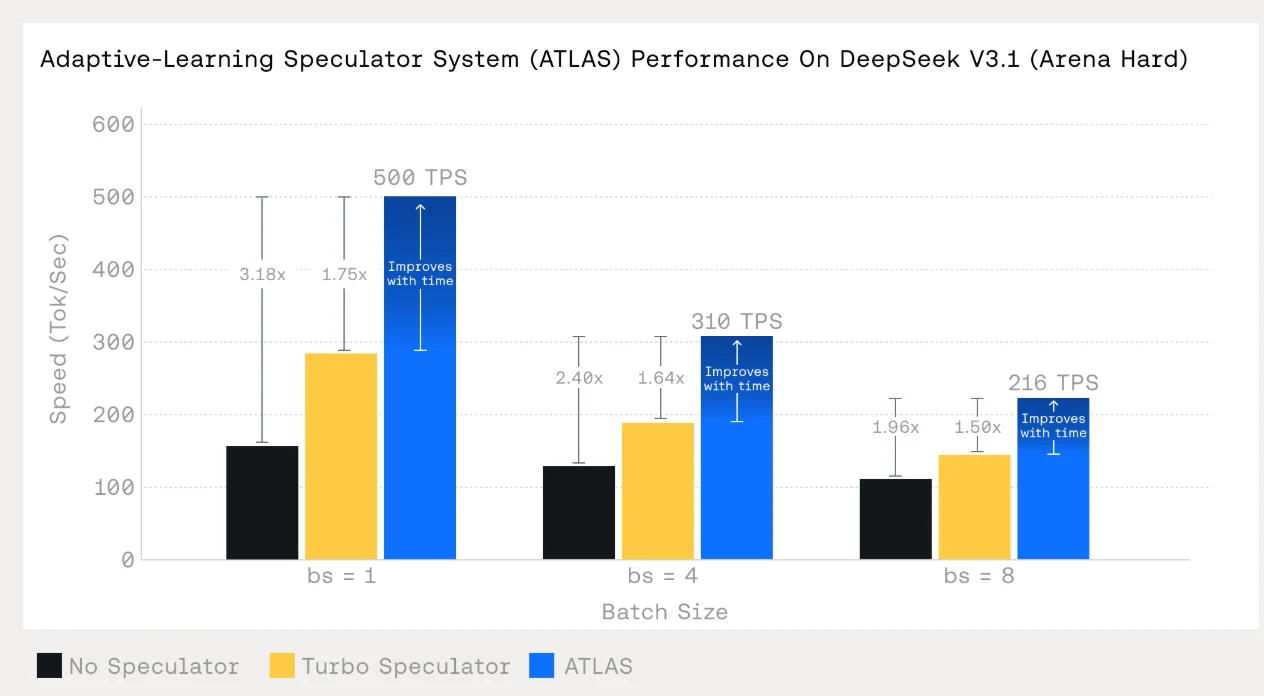
Scalabilité : L’auto-scaling et l’équilibrage de charge prennent en charge des augmentations de volume de 10 à 100 fois, parfait pour des applications agentiques en évolution.
Together AI propose deux modèles de facturation. Les Instances Instantanées fournissent des GPU entièrement à la demande et en libre-service avec des tarifs horaires plus élevés et aucune garantie de capacité, adaptés aux tâches courtes et à la mise à l’échelle rapide. Les Instances Réservées offrent une capacité GPU dédiée et garantie à des prix plus bas, adaptées aux charges de travail soutenues et à l’entraînement à grande échelle.
Sécurité et conformité : Fonctionnalités robustes comme le chiffrement et la conformité aux normes, sans préoccupation de confidentialité des données dans les avis.
Facilité d’intégration et documentation : Des SDK complets, des API RESTful et une documentation détaillée réduisent le temps de configuration ; prend en charge le fine-tuning et le multimodal si nécessaire.

Support et communauté : Canaux prioritaires et forums actifs ; X et Reddit louent les améliorations de vitesse, même si certains notent des coûts plus élevés.
Expérience du fournisseur et fonctionnalités : Solide historique dans l’infrastructure IA, avec les modes de raisonnement de V3.1 entièrement optimisés ; excelle dans l’appel d’outils structuré.
Localisation : Adapté aux utilisateurs mondiaux, avec un potentiel d’optimisations spécifiques aux langues.
Together AI est la meilleure option pour les équipes nécessitant une inférence fiable et haute vitesse dans des environnements de code en production.
Fournisseurs d’API DeepSeek V3.1 - DeepInfra : Outils axés sur l’inférence
Coût et tarification : Le moins cher à 0,27 $ par entrée / 1,00 $ par sortie, avec une mise en cache à 0,216 $, ce qui le rend idéal pour les développeurs sensibles aux coûts
Performances et fiabilité : Environ 79 TPS pour des modèles similaires, avec une mise en cache des prompts pour une faible latence ; fiable pour l’utilisation d’outils, même si les SLA de disponibilité sont moins mis en avant. Les avis utilisateurs notent une haute qualité (97 % de celle des API officielles).
Scalabilité : Prend en charge la scalabilité horizontale via API. Le système de Deepinfra dimensionne automatiquement le modèle sur plus de matériel en fonction de vos besoins. Il limite chaque compte à 200 requêtes simultanées.
Sécurité et conformité : Chiffrement et authentification standard.
Facilité d’intégration et documentation : Documentation claire pour des démarrages rapides.
Support et communauté : Les retours sur Reddit soulignent l’abordabilité et la vitesse, avec des avis mitigés sur les modèles mais une forte confiance dans le fournisseur.
Expérience du fournisseur et fonctionnalités : Expérimenté dans l’inférence ML, avec les améliorations de V3.1 en matière de cohérence pour les agents de codage.
Localisation : Axé sur l’accès mondial.
DeepInfra attire les développeurs indépendants qui priorisent les faibles coûts et l’intégration facile d’outils pour les tâches de code.
Les importantes exigences de calcul de DeepSeek V3.1 rendent les fournisseurs d’API essentiels. Novita AI offre un accès à faible coût et des fonctionnalités orientées code solides ; Together AI fournit une infrastructure de production haute performance ; DeepInfra se concentre sur l’abordabilité et une exécution d’inférence légère. La valeur fondamentale réside dans l’association des modes hybrides de DeepSeek V3.1 au fournisseur qui équilibre le mieux le budget, la vitesse et les besoins de scalabilité.
Questions fréquemment posées
Quel fournisseur prend en charge le plus large éventail de fonctionnalités pour DeepSeek V3.1 ?
Novita AI prend en charge DeepSeek V3.1 avec un contexte de 131 000 tokens, des sorties structurées, des modes de réflexion et un appel de fonctions optimisé pour les flux de travail de codage.
Quel fournisseur dimensionne les charges de travail DeepSeek V3.1 de la manière la plus fiable ?
Together AI dimensionne automatiquement DeepSeek V3.1 sur les Instances Instantanées et les Instances Réservées, prenant en charge une croissance de charge de 10 à 100 fois.
Quelle plateforme offre les meilleures performances pour DeepSeek V3.1 ?
Together AI offre l’inférence DeepSeek V3.1 la plus rapide grâce à ATLAS, permettant une accélération jusqu’à 4 fois et environ 500 TPS.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.
Lectures recommandées



