

- ¿Qué resultados mejora la llamada a funciones en GLM 4.5?
- Tutorial: Uso de la llamada a funciones en GLM-4.5 para principiantes
- Novita AI ahora ofrece compatibilidad con el SDK de Anthropic
- Cómo mejorar la precisión de la llamada a funciones de GLM-4.5
- Solución de problemas de errores de llamada a funciones en GLM-4.5
GLM 4.5, al ser un modelo de lenguaje grande (LLM) avanzado con capacidades de agente, lleva la automatización y la toma de decisiones inteligentes al siguiente nivel mediante la llamada a funciones. Al aprovechar la llamada a funciones, GLM 4.5 puede interactuar con herramientas y API externas, realizar acciones, recuperar datos y automatizar flujos de trabajo complejos, por lo que va mucho más allá de ser solo un modelo conversacional.
Sin embargo, integrar y solucionar problemas de la llamada a funciones puede ser todo un reto. Este artículo ofrece guías prácticas y soluciones a los problemas comunes que puedes encontrar al usar la llamada a funciones con GLM 4.5, como errores de parser, formatos de salida incorrectos o errores comunes en el diseño de esquemas. Mediante ejemplos claros, consejos de resolución de problemas y buenas prácticas, este artículo te ayuda a identificar y resolver incidencias rápidamente, permitiéndote aprovechar al máximo el potencial agente de GLM 4.5 en tus aplicaciones del mundo real.
¿Qué resultados mejora la llamada a funciones en GLM 4.5?
La llamada a funciones es una funcionalidad potente introducida en modelos de lenguaje grandes como GLM 4.5. Permite que el modelo interactúe con herramientas externas, API o código estructurado de forma controlada y fiable. A continuación, se presentan los principales beneficios y resultados mejorados que la llamada a funciones aporta a GLM 4.5:
https://www.youtube.com/watch?v=KUEmEb71vzQ
1. Salidas más precisas y fiables
- Mayor veracidad: Al delegar tareas como cálculos, búsquedas de datos o consultas a bases de datos en funciones externas, GLM 4.5 puede evitar errores comunes en respuestas basadas únicamente en texto.
- Menos alucinaciones: El modelo se basa en resultados verificados de API o funciones, reduciendo la probabilidad de generar información incorrecta o inventada.
2. Automatización de tareas complejas
- Encadenamiento de tareas: GLM 4.5 puede desglosar una solicitud de usuario en múltiples pasos, llamando a las funciones adecuadas para cada uno y combinando los resultados.
- Automatización de flujos de trabajo: Puede automatizar procesos empresariales de varios pasos, procesamiento de datos o generación de informes mediante la orquestación de secuencias de llamadas a funciones.
3. Integración mejorada con sistemas del mundo real
- Acceso a datos en tiempo real: Con la llamada a funciones, el modelo puede obtener información en tiempo real de bases de datos, servicios web o dispositivos IoT, haciendo que sus respuestas sean más actualizadas y conscientes del contexto.
- Acciones personalizadas: Las empresas pueden definir funciones personalizadas (por ejemplo, enviar correos electrónicos, realizar pedidos), permitiendo que el modelo realice acciones específicas del dominio de forma segura.
4. Experiencia de usuario mejorada
- Aplicaciones interactivas: Los usuarios pueden interactuar con el modelo como si estuvieran usando una aplicación, con el modelo activando funciones del backend de forma transparente.
- Personalización: Las funciones pueden obtener datos o configuraciones específicas del usuario, permitiendo respuestas personalizadas.
5. Mejor manejo de errores y explicabilidad
- Razonamiento transparente: La llamada a funciones ayuda a rastrear qué recursos o herramientas externas se utilizaron, haciendo que el proceso de razonamiento del modelo sea más auditable.
- Ejecución controlada: Los desarrolladores pueden supervisar y limitar las funciones que puede llamar el modelo, mejorando la seguridad y la previsibilidad.
¿Cuáles son las limitaciones de la llamada a funciones en GLM-4.5?
1. Llamadas excesivas
GLM-4.5 a veces puede realizar llamadas excesivas o innecesarias a herramientas o API externas. Esto aumenta el uso de tokens y los costes operativos, ya que se consumen más recursos computacionales sin que siempre suponga un beneficio para el resultado final.
2. Casos límite de transmisión en streaming
En modo de transmisión en streaming, si se envían datos JSON parciales antes de que se complete la respuesta completa, las aplicaciones descendentes pueden recibir información incompleta. Sin un almacenamiento intermedio adecuado, esto puede provocar errores o fallos en el procesamiento de la salida.
3. Huella de recursos
En el caso de la llamada a funciones, esto significa que los recursos de hardware limitados pueden afectar la capacidad del modelo para gestionar eficientemente un gran número de solicitudes, procesar datos complejos o ejecutar cadenas intrincadas de llamadas a herramientas. En entornos con recursos limitados, el rendimiento y la precisión de la llamada a funciones pueden reducirse de forma notable.
Beneficios de usar la llamada a funciones con GLM-4.5
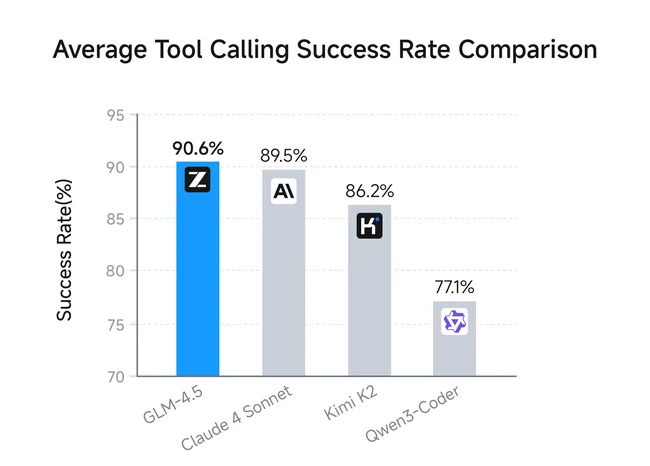
Se realizó una evaluación independiente de las capacidades de codificación agente de GLM-4.5 usando Claude Code, que cubría 52 tareas de codificación diversas como desarrollo frontend, creación de herramientas, análisis de datos, pruebas e implementación de algoritmos. GLM-4.5 obtuvo una tasa de éxito de llamada a herramientas líder del 90,6%, superando a Claude-4-Sonnet (89,5%), Kimi K2 (86,2%) y Qwen3-Coder (77,1%).
Tutorial: Uso de la llamada a funciones en GLM-4.5 para principiantes
Esta guía muestra cómo usar la llamada a funciones para obtener información meteorológica actual de la ubicación especificada por un usuario. Recorreremos un ejemplo de código Python completo.
Para conocer el formato específico de la API de llamada a funciones, consulta la documentación!
- Inicializa el cliente
from openai import OpenAI
import json
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key from: https://novita.ai/settings/key-management.
api_key="<YOUR Novita AI API Key>",
)
model = "zai-org/glm-4.5"
- Define la función que se va a llamar
# Example function to simulate fetching weather data.
def get_weather(location):
"""Retrieves the current weather for a given location."""
print("Calling get_weather function with location: ", location)
# In a real application, you would call an external weather API here.
# This is a simplified example returning hardcoded data.
return json.dumps({"location": location, "temperature": "60 degrees Fahrenheit"})
- Construye la solicitud de API con herramientas y el mensaje del usuario
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather of an location, the user shoud supply a location first",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
}
},
"required": ["location"]
},
}
},
]
messages = [
{
"role": "user",
"content": "What is the weather in San Francisco?"
}
]
# Let's send the request and print the response.
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools,
)
# Please check if the response contains tool calls if in production.
tool_call = response.choices[0].message.tool_calls[0]
print(tool_call.model_dump())
- Salida
{'id': '0', 'function': {'arguments': '{"location": "San Francisco, CA"}', 'name': 'get_weather'}, 'type': 'function'}
- Responde con el resultado de la llamada a la función y obtén la respuesta final
# Ensure tool_call is defined from the previous step
if tool_call:
# Extend conversation history with the assistant's tool call message
messages.append(response.choices[0].message)
function_name = tool_call.function.name
if function_name == "get_weather":
function_args = json.loads(tool_call.function.arguments)
# Execute the function and get the response
function_response = get_weather(
location=function_args.get("location"))
# Append the function response to the messages
messages.append(
{
"tool_call_id": tool_call.id,
"role": "tool",
"content": function_response,
}
)
# Get the final response from the model, now with the function result
answer_response = client.chat.completions.create(
model=model,
messages=messages,
# Note: Do not include tools parameter here.
)
print(answer_response.choices[0].message)
- Salida
{'id': '0', 'function': {'arguments': '{"location": "San Francisco, CA"}', 'name': 'get_weather'}, 'type': 'function'}
Novita AI ahora ofrece compatibilidad con el SDK de Anthropic
La combinación de GLM-4.5 y Claude Code ha ganado rápidamente atención en la comunidad de IA, ofreciendo capacidades agente avanzadas para aplicaciones del mundo real. Para agilizar aún más esta integración, Novita AI ahora ofrece compatibilidad con el SDK de Anthropic, permitiéndote aprovechar fácilmente el poder de GLM-4.5 a través de la interfaz familiar de Claude Code.
Puedes consultar esta documentación para obtener más detalles!
1. Instala el SDK de Anthropic
pip install anthropic
2. Inicializa el cliente
Los SDK de Anthropic están diseñados para obtener la clave de API y la URL base de las variables de entorno: ANTHROPIC_API_KEY y ANTHROPIC_BASE_URL. También puedes suministrar los parámetros al cliente de Anthropic al inicializarlo.
Puedes ver y gestionar tus claves de API en la página de configuración.
- Usando variables de entorno
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_API_KEY="<YOUR_NOVITA_API_KEY>"
- Establece los parámetros al inicializar el cliente de Anthropic
import anthropic
client = anthropic.Anthropic(
base_url="https://api.novita.ai/anthropic",
api_key="<YOUR_NOVITA_API_KEY>"
)
3. Llama a la API
import anthropic
# Initialize the client, if you already set `ANTHROPIC_BASE_URL` and `ANTHROPIC_API_KEY`
# in the environment variables, you can omit the `api_key` and `base_url` parameters.
client = anthropic.Anthropic(
base_url="https://api.novita.ai/anthropic",
api_key="<YOUR_NOVITA_API_KEY>"
)
message = client.messages.create(
model="zai-org/glm-4.5",
max_tokens=1000,
temperature=1,
system="You are a world-class poet. Respond only with short poems.",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Why is the ocean salty?"
}
]
}
]
)
print(message.content)
Cómo mejorar la precisión de la llamada a funciones de GLM-4.5
1. Claridad del esquema
- Qué significa: Usa nombres de parámetros cortos y únicos, y evita el
anyOfanidado hasta que el parser sea más robusto. - Qué soluciona:
- Evita confusiones de parámetros y conflictos de nomenclatura, facilitando que el modelo complete los argumentos correctamente.
- Reduce los errores de parser y las llamadas a funciones fallidas causadas por esquemas demasiado complejos.
2. Prompt del sistema
- Qué significa: Indica al modelo que “primero decida si se necesita una herramienta; de lo contrario, responda directamente”.
- Qué soluciona:
- Reduce las llamadas innecesarias o excesivas a herramientas o funciones (llamadas excesivas).
- Ayuda a ahorrar recursos computacionales y costes operativos.
3. Temperatura ≤ 0,2
- Qué significa: Establece el parámetro de temperatura en 0,2 o inferior.
- Qué soluciona:
- Reduce la aleatoriedad de la salida, garantizando un comportamiento más predecible y coherente.
- Evita la desviación del esquema, por lo que el modelo se mantiene en la estructura de parámetros prevista y reduce los errores.
4. Usa tool_choice="required"
- Qué significa: Establece esta opción cuando el usuario solicite explícitamente una llamada a una función.
- Qué soluciona:
- Garantiza que el modelo siempre realice la llamada a función requerida, mejorando la fiabilidad y la satisfacción del usuario.
5. Usa llamadas paralelas con moderación
- Qué significa: Solo paraleliza funciones que sean realmente independientes; de lo contrario, genera las llamadas de forma secuencial.
- Qué soluciona:
- Evita la mezcla de argumentos o la incoherencia lógica entre llamadas.
- Garantiza que cada llamada reciba el contexto y las entradas correctos, lo que lleva a resultados más precisos.
Solución de problemas de errores de llamada a funciones en GLM-4.5
| Síntoma | Causa probable | Solución / Corrección |
|---|---|---|
| IndexError: list index out of range en el parser | Se usa el parser por defecto; el formato de ID de GLM es diferente. | Inicia el servidor con --tool-call-parser glm4_moe. |
| Texto aleatorio mezclado con JSON | Temperatura demasiado alta o falta el parámetro tool_choice. |
Reduce la temperatura; establece tool_choice como "auto" o "required". |
| Recursión infinita de herramientas | El modelo alucina llamadas repetidas. | Registra las llamadas ejecutadas y aborta las duplicadas en la lógica del host. |
| OOM / Sin recursos | La compilación FP8 sigue superando la memoria compartida en los kernels de Triton. | Reduce num_stages o cambia a la cuantización mixta Int4-Int8. |
| No se emite ninguna llamada | El esquema de la herramienta es demasiado vago. | Añade una lista required estricta y valores de enum explícitos. |
La llamada a funciones transforma GLM 4.5 de un modelo conversacional a un agente inteligente capaz de ejecutar tareas y automatizar procesos en tiempo real. Al comprender los problemas típicos y sus soluciones, como errores de parser, formato JSON o diseño de esquemas, puedes garantizar una integración fluida y aprovechar todo el potencial de las capacidades agente de GLM 4.5. Esperamos que este artículo haya aclarado las dudas comunes y te haya capacitado para implementar la llamada a funciones de GLM 4.5 con confianza.
Preguntas frecuentes
¿Por qué es importante la llamada a funciones para GLM 4.5 como LLM agente? La llamada a funciones permite que GLM 4.5 interactúe mediante programación con servicios externos, bases de datos y herramientas. Esto permite la automatización, el razonamiento de varios pasos, la recuperación de información y acciones del mundo real más allá de la generación de texto.
¿Cómo evito la recursión infinita o las llamadas repetidas a herramientas? Implementa lógica en el lado del host para registrar y abortar llamadas a funciones duplicadas, evitando bucles infinitos.
¿Cuáles son las buenas prácticas para el diseño de esquemas que garanticen que se emitan las llamadas a funciones? Usa nombres de parámetros concisos y únicos, proporciona enums explícitos y define los parámetros requeridos para que el esquema sea claro para el modelo.
Novita AI es la plataforma cloud todo en uno que impulsa tus ambiciones en IA. APIs integradas, sin servidor, instancias de GPU: las herramientas económicas que necesitas. Elimina la infraestructura, empieza gratis y haz realidad tu visión de IA.



