

DeepSeek R1 represents a significant advancement in large language models, yet achieving optimal performance requires careful consideration of hardware infrastructure and deployment strategies. This guide walks you through the essential aspects of implementing DeepSeek R1, from GPU selection to deployment optimization.
We’ll explore various GPU configurations and their impact on model performance, covering everything from the NVIDIA RTX 6000 Ada to the high-end H100. Whether you’re running inference tasks or conducting training operations, you’ll find practical insights for maximizing DeepSeek R1’s capabilities while maintaining cost efficiency.
What is DeepSeek?

DeepSeek is a Chinese AI startup founded in 2023 by Liang Wenfeng, headquartered in Hangzhou, Zhejiang. Backed by the hedge fund High-Flyer, the company has quickly established itself as a significant player in the AI industry by developing open-source large language models that rival or surpass existing industry leaders in both performance and cost-efficiency.
DeepSeek’s mission centers on advancing artificial general intelligence (AGI) through open-source research and development, aiming to democratize AI technology for both commercial and academic applications. The company has gained international attention for its ability to deliver GPT-4-level capabilities at approximately 5% of the training cost.
What sets DeepSeek apart is its innovative approach to model architecture and training methodology. Despite facing export restrictions, DeepSeek achieved performance parity with U.S. competitors using only 2,000 Nvidia GPUs. This efficiency stems from their use of the Mixture of Experts (MoE) framework, reinforcement learning optimization, and hardware-agnostic design principles.
Understanding the Full Version R1 Model
Architecture and Model Scale
DeepSeek R1 employs a sophisticated Mixture of Experts (MoE) architecture that enables remarkable efficiency despite its massive scale. The model boasts an impressive 671 billion parameters, making it one of the largest language models available today. However, what makes R1 truly innovative is that it only activates 37 billion parameters per token during inference.
This selective activation is achieved through a dynamic routing system that determines which experts to utilize for each specific input. The architecture includes a combination of shared experts with general capabilities and specific experts with narrow capabilities. This design allows the model to:
- Efficiently utilize resources by activating only necessary parameters
- Adapt to various tasks through dynamic expert selection
- Balance the load across different experts to prevent over-reliance on specific components
The model employs a Multi-head Latent Attention Transformer architecture containing 256 routed experts and one shared expert, enabling it to process complex queries with remarkable efficiency.
Key Features and Capabilities
DeepSeek R1 excels in tasks requiring logical reasoning, mathematical problem-solving, and complex coding challenges:
- Mathematical Reasoning: The model achieves 97.3% accuracy on MATH-500 benchmarks, outperforming OpenAI’s o1 (96.4%)
- Coding Proficiency: R1 scores 96.3% on Codeforces benchmarks, nearly identical to OpenAI o1’s 96.6%
- Chain-of-Thought Reasoning: The model employs a step-by-step reasoning process that breaks down complex problems into manageable components
- Verification and Self-Correction: R1 can self-check its outputs for accuracy, making it particularly valuable for domains requiring high precision
These capabilities make DeepSeek R1 especially suited for applications in scientific research, financial analysis, educational technology, and software development.
Technical Advantages of the Full Version
The full version of DeepSeek R1 offers several technical advantages that set it apart from its smaller counterparts. Here are some of the key benefits:
- Superior Performance in Specialized Domains: Its advanced configuration ensures that the R1 model performs exceptionally well in domain-specific applications, where both precision and performance are critical.
- Enhanced Accuracy in Complex Tasks: The full version is designed with billions of parameters, which contributes to its superior ability to tackle intricate language challenges.
- Better Context Retention: Thanks to its scaled architecture, the model can retain context over longer stretches of text, making it highly effective for applications that require deep understanding of conversations or documents.
- Improved Reasoning Capabilities: With advanced reasoning built into its design, the R1 model can provide more analytical responses, proving beneficial for domains that require logical deduction and problem-solving.
- More Nuanced Language Generation: The enhanced language generation capabilities allow the model to produce responses that are not only contextually appropriate but also linguistically refined, showcasing subtle distinctions in tone and style.
- Superior Performance in Specialized Domains: Its advanced configuration ensures that the R1 model performs exceptionally well in domain-specific applications, where both precision and performance are critical.
Full Version R1 GPU Requirements
This guide outlines various GPU configurations for deploying the full version of DeepSeek-R1-671B model, featuring different NVIDIA GPU options suitable for high-performance computing environments.
Common Technical Parameters
All configurations share the following specifications:
- Model Parameters: 90.4960 trillion
- Sequence Length: 1024
- Batch Size: 1
- Vocabulary Size: 129,280
- Hidden Layer Dimension: 7,168
- Quantization: FP8
Infrastructure Requirements
Common across all setups:
- System Memory: 2048GB DDR5-4800 dual-channel
- Network: 400Gbps InfiniBand interconnect
- Storage: Distributed storage (Lustre)
- Optimization: Tensor Parallel + Pipeline Parallel
GPU Configurations
A100 SXM Setup
- GPU Count: 11 cards minimum
- VRAM: 80GB per card
H100 SXM Setup
- GPU Count: 8 cards minimum
- VRAM: 80 GB per card
This configuration ensures stable model operation and optimal performance. Note that these are baseline requirements, and actual production environments may need to consider redundancy and scalability.
Configuring the Right GPU Setup for R1 Model
Deployment Architecture Recommendations
The DeepSeek-R1-671B model deployment architecture centers around efficient GPU utilization and scaling capabilities. The foundation relies on:
Core Components:
- GPU clusters optimized for inter-node communication
- Balanced memory distribution across nodes
- Minimal latency system topology
- Flexible scaling architecture
This setup ensures optimal performance while maintaining system reliability and scalability for future expansion.
Network and Storage Requirements
High-performance infrastructure is crucial for R1 model operation. The networking backbone requires 400Gbps InfiniBand connectivity with fat-tree topology, ensuring efficient data transfer between nodes.
Essential Infrastructure:
- Network: 400Gbps InfiniBand with redundant paths
- Storage: Lustre distributed filesystem
- I/O Requirements: High IOPS, parallel access capability
- Data Management: Distributed caching system
Performance Optimization Techniques
Performance optimization integrates parallel processing strategies with efficient resource management. The implementation leverages both Tensor and Pipeline Parallelism, complemented by BF16 quantization for optimal compute efficiency.
Key Optimization Areas:
- Parallel Processing: Combined Tensor and Pipeline Parallelism
- Memory Management: Strategic gradient checkpointing
- System Optimization: Load balancing and communication efficiency
Regular monitoring and tuning ensure sustained performance, with adjustments based on workload demands and system metrics.
Maximize DeepSeek Performance with Novita AI
Novita AI offers access to high-performance GPUs such as the A100 and RTX 4090, which are ideal for training deep learning models on DeepSeek. These GPUs are optimized for high throughput and low-latency processing, ensuring that DeepSeek models can be trained and deployed faster. With its scalable and cost-effective GPU offerings, Additionally, Novita AI’s cloud services provide users with the flexibility to scale GPU resources based on workload demands, ensuring that you can easily adapt to the needs of your AI project.
If you’re interested in Novita AI, you can follow the steps below to learn more:
Step1:Register an account
Begin by creating an account on the Novita AI website to gain access to powerful cloud GPU resources. Once registered, you can easily explore how our services can help you enhance DeepSeek’s performance.

[Try using Novita AI now](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=DeepSeek R1 GPU Rental: From Selection to Performance Optimization)
Step2:Select Your GPU
Choose from our diverse GPU lineup to match your DeepSeek requirements. Each configuration comes with optimized RAM and vCPU allocations, alongside ample disk space, letting you select the perfect balance of performance and cost for your AI workloads.
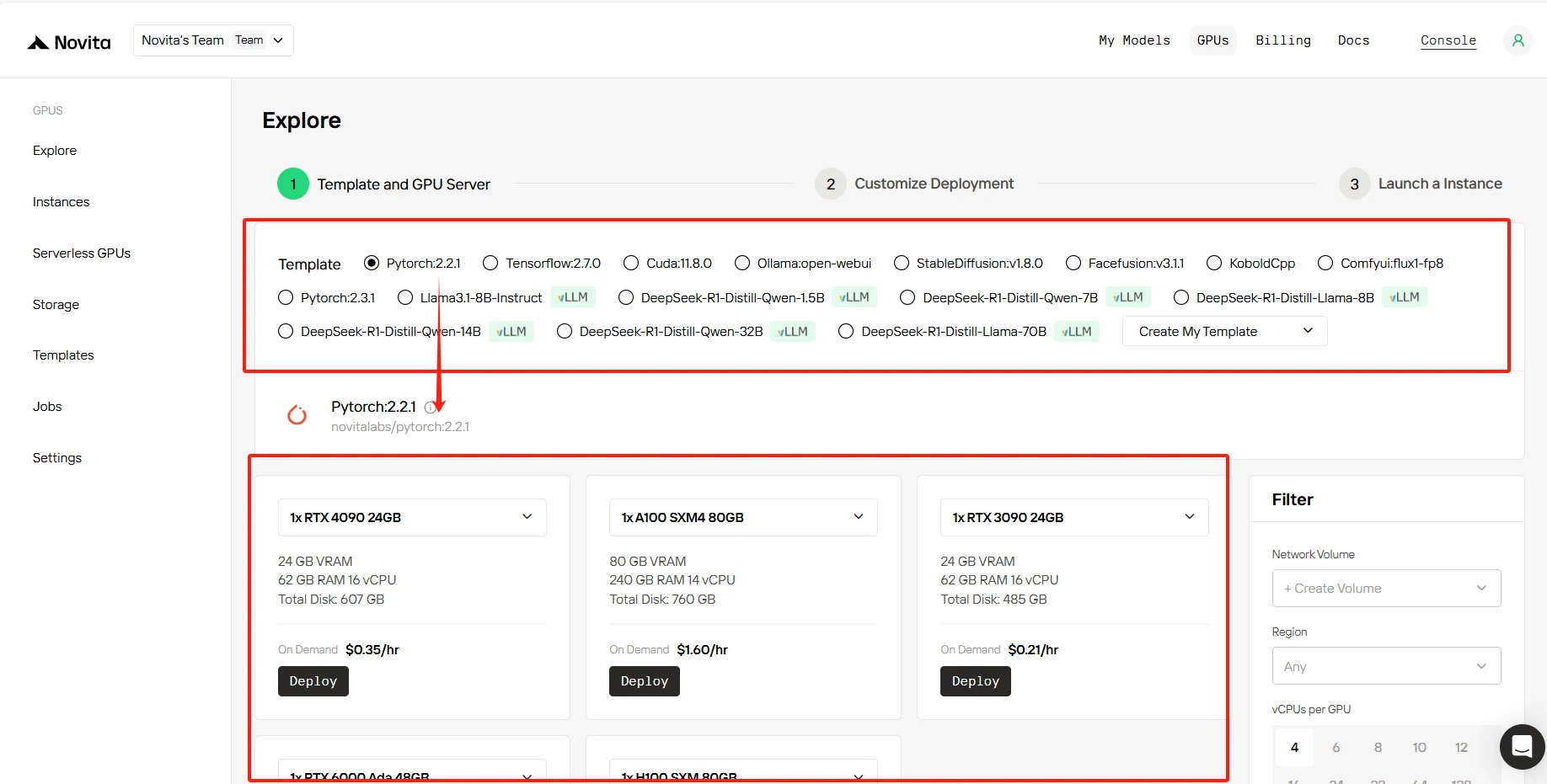
[Try Novita AI’s High-Performance GPUs](https://novita.ai/gpus-console/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=DeepSeek R1 GPU Rental: From Selection to Performance Optimization)
Step3:Customize Your Setup
Customize your cloud GPU deployment to match your specific DeepSeek project needs. With 60GB of free storage on the Container Disk , you can tailor the resources to fit your task’s complexity. Additional storage options are available at a reasonable cost.
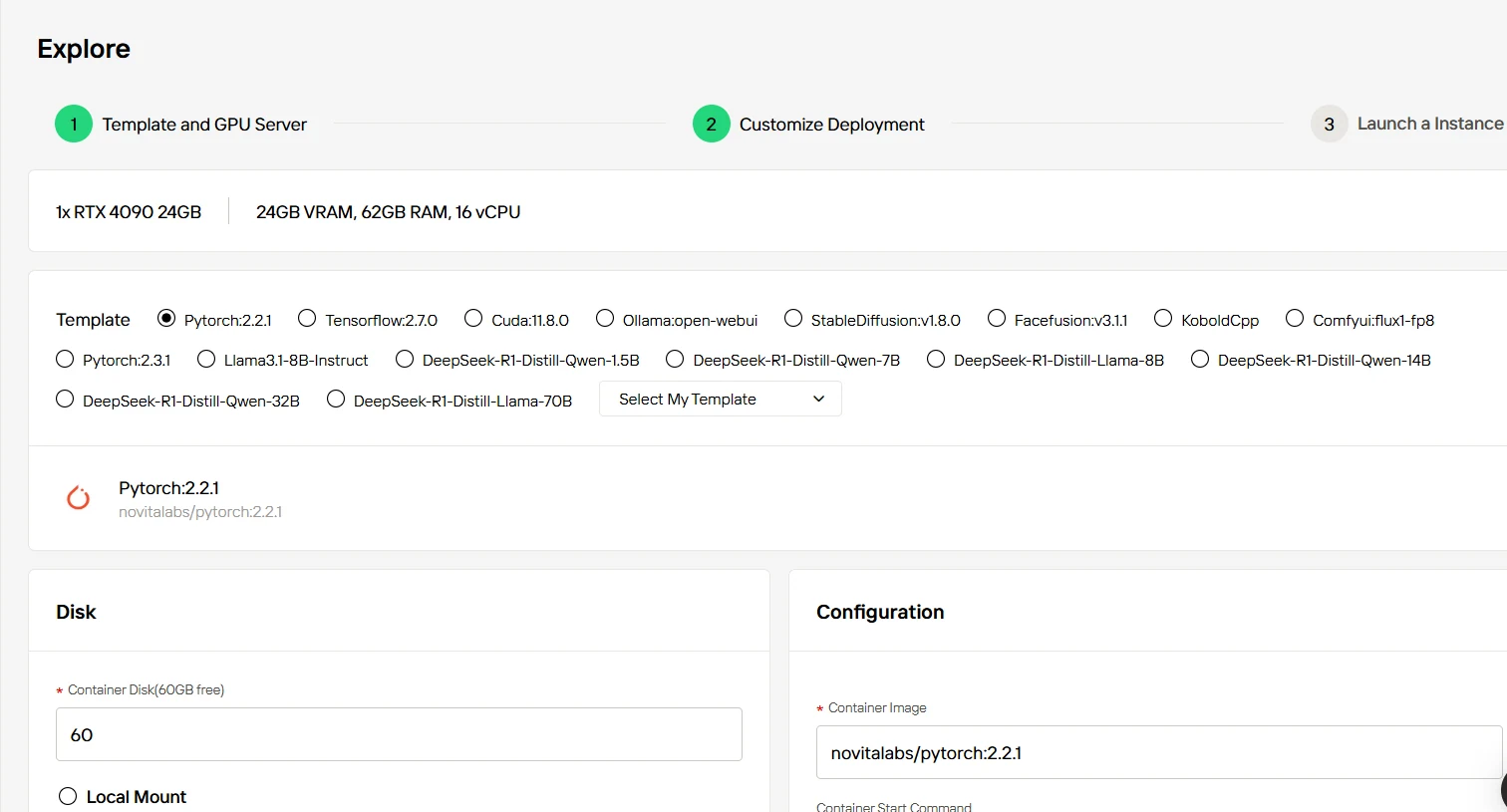
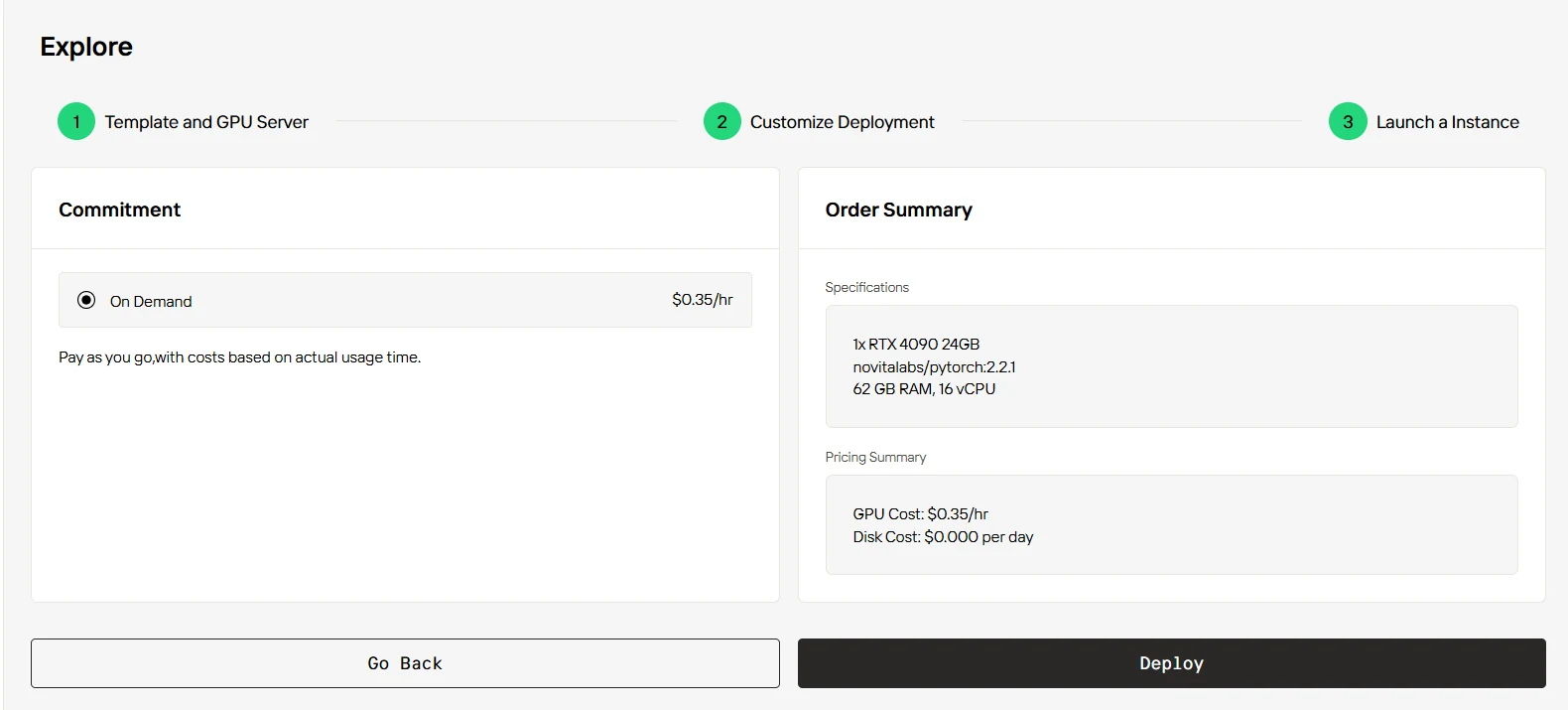
Step4:Launch Your DeepSeek Instance
Deploy your selected GPU instance to start working with DeepSeek. Novita AI’s cloud-based GPU instances provide exceptional computational power, ensuring smooth, efficient AI model training and deployment.
Conclusions
Renting GPUs for DeepSeek R1 is an excellent way to scale your AI projects without the capital investment in expensive hardware. By choosing the right GPUs like the NVIDIA RTX 6000 Ada, A100, and H100, and optimizing your setup for BF16 precision, you can ensure that your DeepSeek R1 model performs at its best. Whether you’re working on cutting-edge research or enterprise AI applications, renting cloud GPUs through services like Novita AI allows you to quickly access the computational power you need, saving costs and time while achieving top-tier results.
Frequently Asked Questions
How do I choose between A100 and H100 for DeepSeek R1 deployment?
Choose A100 for cost-effective production deployment, or H100 for maximum performance needs where budget isn’t the primary constraint.
Can I run DeepSeek R1 on multiple GPUs for better performance?
Yes, DeepSeek R1 fully supports multi-GPU configurations for enhanced training and inference performance.
Can I save progress and resume DeepSeek training sessions later?
Yes, you can save model checkpoints to persistent storage and resume training sessions from where you left off.
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=DeepSeek R1 GPU Rental: From Selection to Performance Optimization) is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Recommended Reading
Rent Best GPUs in GPU Cloud for Stable Diffusion: Top Picks 2024



