

Wichtige Highlights
Revolutionäre KI-Architektur
Enthält Innovationen wie Mixture-of-Experts (MoE), Multi-Head Latent Attention (MLA) und Multi-Token Prediction (MTP).
Hardware-Anforderungen
Mindestens: 8 GB VRAM, 8 GB RAM, Multi-Core-CPU.
Empfohlen: 16 GB+ RAM, mehr VRAM für größere Modelle.
Reiner CPU-Betrieb ist möglich, aber langsamer.
Herausforderungen
Komplexe Einrichtung und Leistungsprobleme auf Geräten der Verbraucherklasse.
Cloud-basierte Alternative
Novita AI: Vereinfacht den Zugriff über APIs, um lokale Hardwareeinschränkungen zu vermeiden.
In der Welt der künstlichen Intelligenz waren Training und Betrieb großer Sprachmodelle lange Zeit gleichbedeutend mit hohen Hardwarekosten – insbesondere der Abhängigkeit von High-End-GPUs wie NVIDIA A100 und H100, die zum Industriestandard geworden sind. Die bahnbrechende Architektur von DeepSeek verändert diese Landschaft jedoch grundlegend. Dieses revolutionäre Design reduziert nicht nur die Abhängigkeit von teurer Hardware, sondern öffnet auch einem breiteren Kreis von Entwicklern die Tür zu leistungsstarker KI. Was macht die Innovationen von DeepSeek so einzigartig? Und wie fordern sie NVIDIAs Dominanz im KI-Hardwaremarkt heraus? Lassen Sie uns eintauchen und das erkunden.
DeepSeek V3: Wegweisende KI-Architektur
https://www.youtube.com/watch?v=s\_s2GS8zLTE
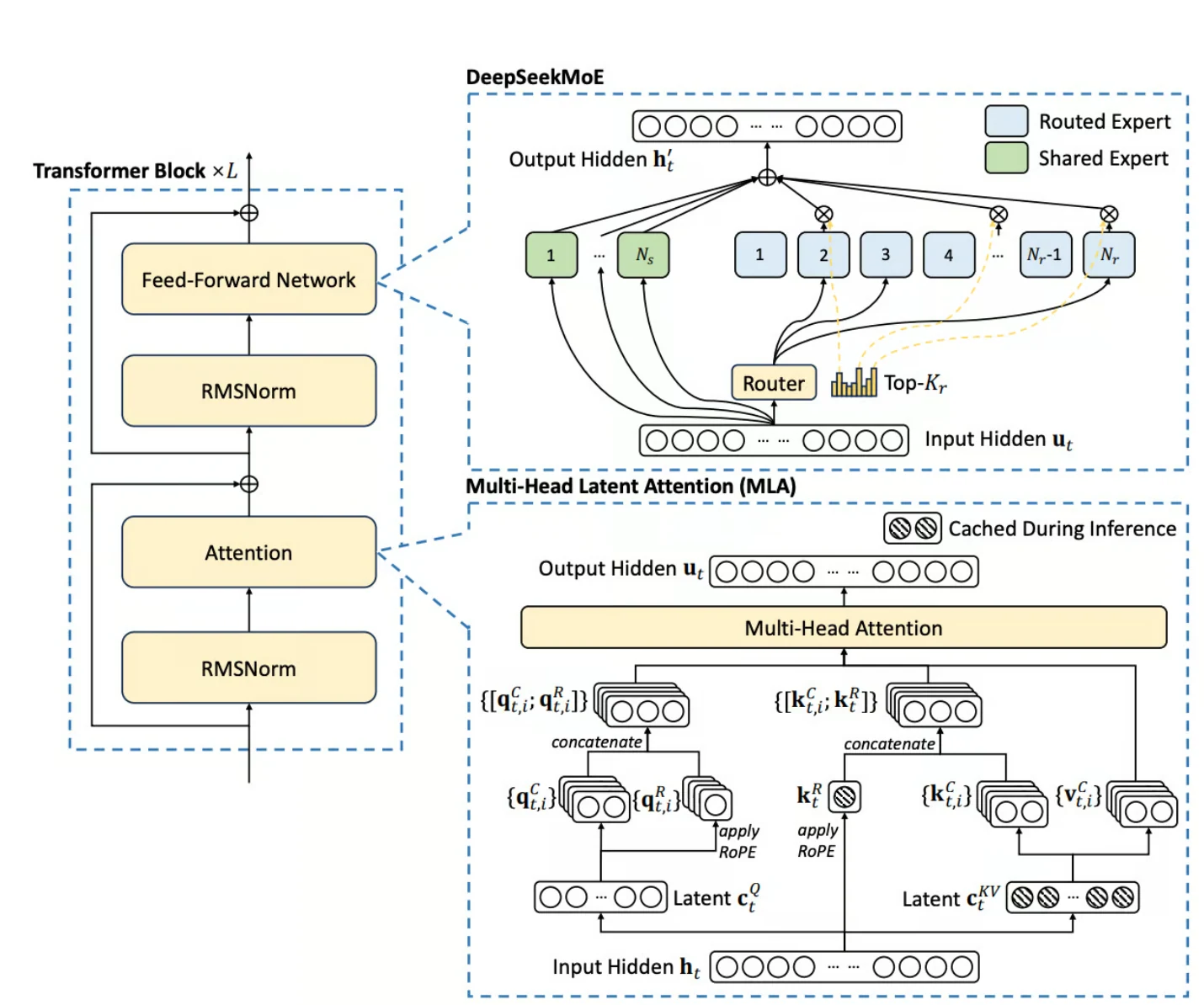
Mixture-of-Experts (MoE)-Architektur
Im Kern von DeepSeek V3 steht seine ausgeklügelte Mixture-of-Experts (MoE)-Architektur, eine bedeutende Abkehr von traditionellen dichten Modellen. Dieses Paradigma ermöglicht es dem Modell, für verschiedene Eingaben selektiv bestimmte Teilmengen von Parametern zu aktivieren, was zu bemerkenswerten Vorteilen führt:
- Massive Skalierung mit selektiver Aktivierung:
DeepSeek V3 verfügt über beeindruckende 671 Milliarden Parameter, aktiviert aber nur 37 Milliarden Parameter pro Token, was die Recheneffizienz optimiert. - Dynamische Expertenauswahl:
Das Modell wählt für jede Eingabe dynamisch Experten-Subnetzwerke aus, wodurch die Gesamtrechenkosten gesenkt werden, während die hohe Leistung erhalten bleibt. - Effizientes Scaling mit Lastverteilung:
Durch die Verwendung feiner unterteilter Experten und fortschrittlicher Lastverteilungstechniken gewährleistet DeepSeek V3 eine ressourceneffiziente Inferenz bei gleichzeitiger effektiver Skalierung.
Multi-Head Latent Attention (MLA)
DeepSeek V3 enthält Multi-Head Latent Attention (MLA), einen hochmodernen Mechanismus, der von seinem Vorgänger DeepSeek V2 verfeinert wurde. MLA treibt mehrere wichtige Fortschritte in der Modellleistung voran:
- Low-Rank-Joint-Kompression:
MLA verbessert die Inferenzeffizienz, indem es Aufmerksamkeits-Keys und -Values durch Low-Rank-Techniken komprimiert, was den Speicherbedarf erheblich reduziert. - Reduzierter Speicherbedarf:
Durch das Caching nur komprimierter latenter Vektoren minimiert MLA die Speicherung von Key-Values während der Inferenz, ohne die Aufmerksamkeitsqualität zu beeinträchtigen. - Optimierte Langstreckenabhängigkeiten:
Dieser Aufmerksamkeitsmechanismus hilft, große Informationsmengen effizient zu verarbeiten, insbesondere bei Aufgaben, die Langstreckenabhängigkeiten erfordern.
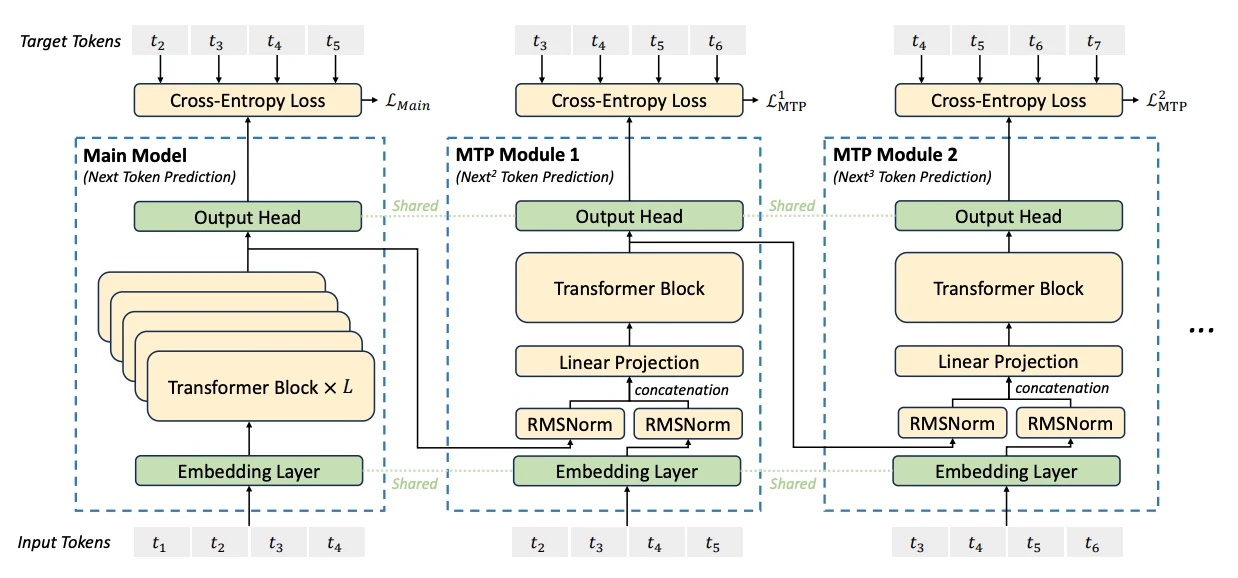
Multi-Token Prediction (MTP)
Eine herausragende Innovation in DeepSeek V3 ist sein Multi-Token Prediction (MTP)-Trainingsziel, das die traditionellen Paradigmen der Vorhersage des nächsten Tokens neu definiert. Dieser Ansatz bringt mehrere transformative Vorteile mit sich:
- Gleichzeitige Vorhersage mehrerer Tokens:
Anstatt nur das nächste Token vorherzusagen, trainiert MTP das Modell, mehrere zukünftige Tokens an jeder Sequenzposition vorherzusagen. - Verdichtete Trainingssignale:
Durch die Erhöhung der Dichte der Trainingssignale verbessert MTP die Dateneffizienz und beschleunigt das Lernen. - Verbesserte Vorausplanung von Repräsentationen:
Dieses Ziel ermöglicht es dem Modell, reichhaltigere kontextuelle Repräsentationen zu entwickeln, was die Leistung bei Aufgaben verbessert, die langfristige Planung oder mehrschrittiges Denken erfordern.
Zusätzliche Architekturmerkmale
DeepSeek V3 profitiert auch von mehreren ergänzenden Innovationen, die seine Trainings- und Inferenzprozesse optimieren:
- DeepSeekMoE:
Ein spezialisierter Mechanismus, der das Training von MoE-Layern optimiert, eine ausgewogene Arbeitslastverteilung über alle Experten sicherstellt und Ungleichgewichte abmildert. - Hilfsverlustfreie Lastverteilung:
Durch eine biasbasierte dynamische Anpassungsstrategie erreicht DeepSeek V3 eine effektive Lastverteilung, ohne auf Hilfsverlustfunktionen angewiesen zu sein, und bewahrt so Genauigkeit und Effizienz. - FP8-Mixed-Precision-Framework:
Die Einführung von FP8 Mixed Precision reduziert sowohl Speicher- als auch Rechenkosten, während die numerische Stabilität erhalten bleibt, was einen erheblichen Schub für die Ressourceneffizienz bietet.
DeepSeek V3: Senkung der Hardware-Hürden
![]()
DeepSeek V3 ist auf Effizienz und Skalierbarkeit ausgelegt und bietet flexible Hardwareanforderungen, die auf seine Modellvarianten und Einsatzszenarien zugeschnitten sind. Nachfolgend finden Sie eine detaillierte Aufschlüsselung der Mindest- und empfohlenen Hardwarespezifikationen, die für den effektiven Betrieb von DeepSeek V3 erforderlich sind.
Hardware-Anforderungen und Konfigurationsempfehlungen
-
Betriebssystem
- Windows 10 oder neuer
- macOS 10.15 oder später
- Linux (Ubuntu 18.04+)
-
CPU
- Multi-Core-Prozessor (mindestens 4 Kerne)
-
GPU
- NVIDIA GPUs empfohlen für schnellere Inferenz
- Mehr VRAM für das vollständige 671B-Modell erforderlich
- Reiner CPU-Betrieb möglich, aber deutlich langsamer
-
Arbeitsspeicher (RAM)
- 8 GB: Ausreichend für kleinste Versionen (1,5B oder 7B)
- 16 GB oder mehr: Empfohlen für mittlere Modelle (14B oder 32B)
-
Speicherplatz
- 4–50 GB freier Speicher erforderlich, abhängig von der heruntergeladenen R1-Größe
-
Software-Anforderungen
- Python 3.10 für die offiziellen R1-Skripte
Vergleich mit anderen Modellen
| Modell | GPU (VRAM) | RAM | Speicher |
| DeepSeek V3 | Mindestens 8 GB VRAM | 8–16 GB | 4–50 GB freier Speicher erforderlich |
| Llama 3.3 70B | 24–48 GB | Mindestens 32 GB | Mindestens 200 GB |
| Qwen 2.5 72B | 24 GB | Mindestens 32 GB | / |
DeepSeek V3 lokal: Effizient, aber herausfordernd
Während DeepSeek V3 eine hardwareeffizientere Architektur einführt, bleiben bestimmte Herausforderungen bestehen, insbesondere für Benutzer mit begrenzten Ressourcen oder Geräten der Verbraucherklasse:
- Einschränkungen von Consumer-Hardware:
Der lokale Betrieb des vollständigen 671B-Parameter-Modells erfordert erhebliche Rechenleistung, die oft die Fähigkeiten von Standard-Laptops oder -Desktops übersteigt. Selbst kleinere Modellvarianten können auf Geräten mit begrenztem GPU-Speicher oder CPU-Kapazität Probleme bereiten. - Installations- und Einrichtungsprobleme:
Der Einrichtungsprozess umfasst mehrere technische Schritte wie das Klonen des Repositorys, das Installieren von Abhängigkeiten und das Konvertieren von Modellgewichten. Diese Aufgaben setzen Vertrautheit mit Befehlszeilenwerkzeugen und der Verwaltung von Softwareumgebungen voraus, was für weniger technisch versierte Benutzer eine Hürde darstellen kann. - Leistungsengpässe auf älteren Geräten:
Ältere oder schwächere Geräte können unter schwerwiegender Leistungsverschlechterung leiden, was zu langsameren Verarbeitungszeiten, Verzögerungen oder sogar Abstürzen führt. Größere Modelle können die Systemressourcen schnell überlasten, was sie für solche Hardware unpraktisch macht.
Diese Herausforderungen verdeutlichen die Notwendigkeit einer Balance zwischen den ambitionierten Fähigkeiten von DeepSeek und den praktischen Hardwareanforderungen für den täglichen Gebrauch.
Zugang zu einer DeepSeek V3-Alternative: API wie Novita AI
Angesichts der Herausforderungen beim Betrieb von DeepSeek V3 auf begrenzter oder Consumer-Hardware bietet Novita AI eine praktischere und benutzerfreundlichere Alternative:
- Cloud-basierte Zugänglichkeit:
Novita AI macht leistungsstarke lokale Hardware überflüssig, indem es Cloud-Infrastruktur nutzt, sodass erweiterte KI-Funktionen auf jedem Gerät mit Internetverbindung verfügbar sind. - Vereinfachte Einrichtung:
Novita AI erfordert keine komplexe Installation oder Abhängigkeitsverwaltung. Benutzer können auf die Funktionen direkt über eine Weboberfläche oder API zugreifen und umgehen so die technischen Hürden der Einrichtung von DeepSeek V3. - Kosteneffizienz:
Anstatt in teure GPUs zu investieren und hohe Stromkosten zu tragen, zahlen Benutzer für die Dienste von Novita AI nutzungsbasiert, was für viele Szenarien wirtschaftlicher ist.
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

[DeepSeek V3 Demo jetzt ausprobieren!](https://novita.ai/models/llm/deepseek-deepseek_v3/?utm_source=blog_llm&utm_medium=article&utm_campaign= what-are-the-requirements-for-deepseek-v3-inference)
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.

Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API erhalten Sie einen neuen API-Schlüssel. Rufen Sie die Seite „Einstellungen“ auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<IHR Novita AI API-Schlüssel>",
)
model = "deepseek/deepseek_v3"
stream = True # oder False
max_tokens = 2048
system_content = """Sei ein hilfreicher Assistent"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Bei der Registrierung stellt Novita AI ein Guthaben von 0,50 $ zur Verfügung, damit Sie loslegen können!
Wenn das kostenlose Guthaben aufgebraucht ist, können Sie bezahlen, um es weiter zu nutzen.
DeepSeek V3 ist mit seiner fortschrittlichen Architektur und Leistung ein bedeutender Sprung im Bereich der Open-Source-KI. Allerdings stellen der lokale Betrieb Hardware- und technische Herausforderungen dar. API-basierte Lösungen wie Novita AI bieten eine zugänglichere und skalierbarere Alternative. Während sich die KI weiterentwickelt, wird DeepSeek V3 effizientere Anwendungen vorantreiben, wobei die Wahl zwischen lokalem und API-Einsatz von den Benutzeranforderungen und -ressourcen abhängt.
Häufig gestellte Fragen
Wie schneiden DeepSeek V3 und Llama 3.3 70B in Bezug auf Benchmarks und Anwendungsfälle ab?
DeepSeek V3 ist bei Programmier- und Mathematikaufgaben überlegen, während Llama 3.3 70B bei allgemeinen Sprach- und mehrsprachigen Anwendungen glänzt.
Was ist eine Mixture-of-Experts (MoE)-Architektur und warum ist sie wichtig?
MoE verwendet mehrere „Experten“, um bestimmte Eingabe-Tokens zu verarbeiten, was die Effizienz und Leistung bei komplexen Aufgaben verbessert. Es ist recheneffizienter als dichte Modelle, aber dennoch hardwareintensiv.
Wie hoch sind die VRAM-Anforderungen für DeepSeek V3?
Die VRAM-Anforderungen für DeepSeek V3 variieren je nach Präzision. Für FP16 benötigt das 671B-Modell etwa 1.543 GB VRAM, bei 4-Bit-Quantisierung etwa 386 GB VRAM. Die aktiven Parameter betragen 37B.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, serverlos, GPU-Instanz – die kosteneffizienten Tools, die Sie brauchen. Verzichten Sie auf Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



