

Ключевые моменты
Революционная архитектура ИИ
Включает такие инновации, как смесь экспертов (MoE), многоголовое латентное внимание (MLA) и предсказание нескольких токенов (MTP).
Требования к оборудованию
Минимальные: 8 ГБ VRAM, 8 ГБ ОЗУ, многоядерный процессор.
Рекомендуемые: от 16 ГБ ОЗУ, больше VRAM для более крупных моделей.
Работа только на процессоре возможна, но значительно медленнее.
Сложности
Сложная настройка и проблемы с производительностью на устройствах потребительского класса.
Облачная альтернатива
Novita AI: упрощает доступ через API, обходя ограничения локального оборудования.
В мире искусственного интеллекта обучение и запуск больших языковых моделей долгое время ассоциировались с высокими затратами на оборудование — особенно с зависимостью от высокопроизводительных графических процессоров NVIDIA, таких как A100 и H100, которые стали отраслевым стандартом. Однако новаторская архитектура DeepSeek меняет этот ландшафт. Эта революционная конструкция не только снижает зависимость от дорогого оборудования, но и открывает дверь в мир высокопроизводительного ИИ для более широкого круга разработчиков. В чём же уникальность инноваций DeepSeek? И как они бросают вызов доминированию NVIDIA на рынке ИИ-оборудования? Давайте разберёмся.
DeepSeek V3: пионерская архитектура ИИ
https://www.youtube.com/watch?v=s\_s2GS8zLTE
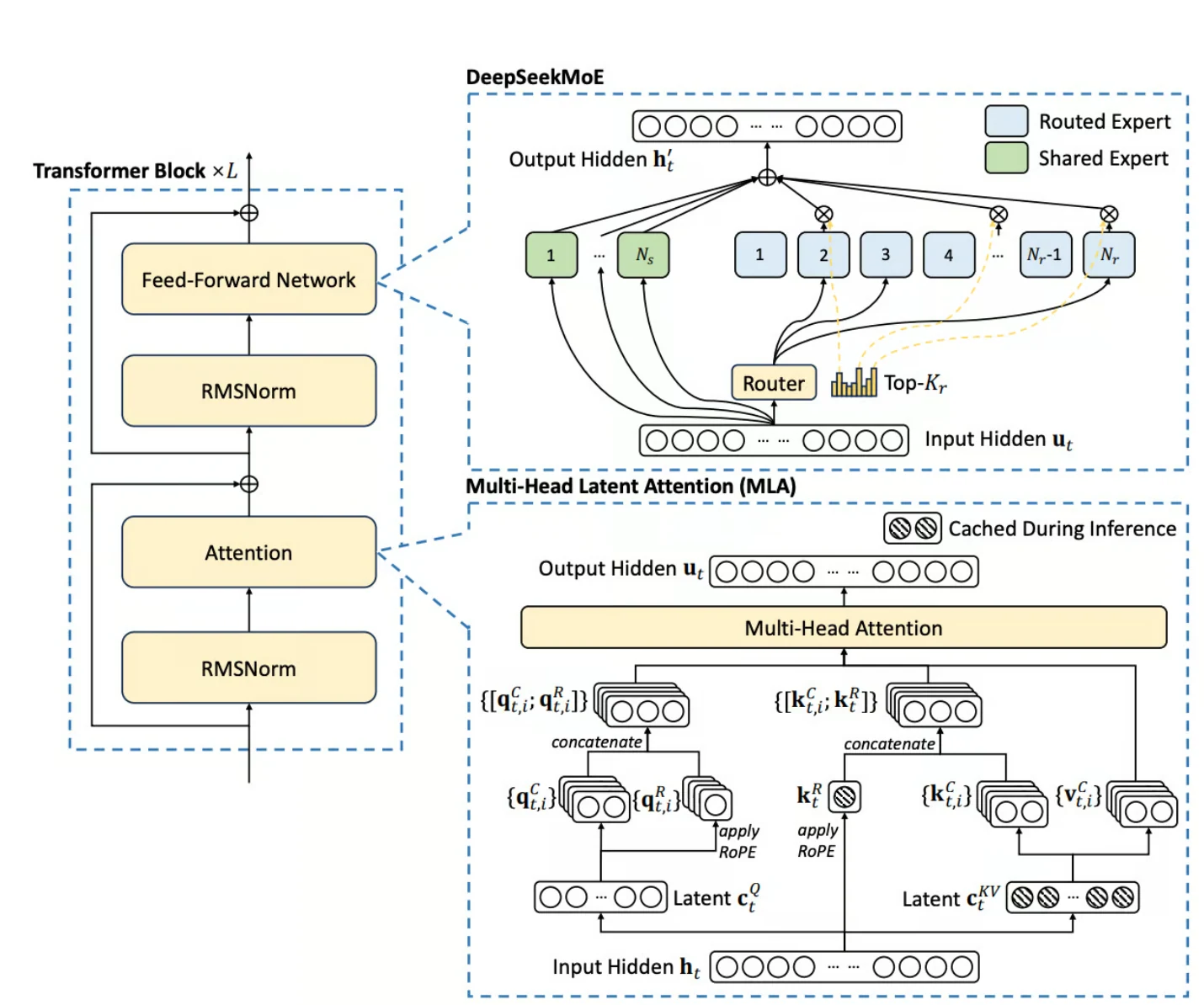
Архитектура смеси экспертов (MoE)
В основе DeepSeek V3 лежит сложная архитектура смеси экспертов (MoE), которая значительно отличается от традиционных плотных моделей. Эта парадигма позволяет модели выборочно активировать определённые подмножества параметров для разных входных данных, что даёт замечательные преимущества:
- Огромный масштаб с выборочной активацией:
DeepSeek V3 обладает впечатляющими 671 миллиардом параметров, но активирует лишь 37 миллиардов параметров на токен, оптимизируя вычислительную эффективность. - Динамический выбор эксперта:
Модель динамически выбирает экспертные подсети для каждого входного сигнала, снижая общие вычислительные затраты, сохраняя при этом высокую производительность. - Эффективное масштабирование с балансировкой нагрузки:
Используя более мелкозернистых экспертов и продвинутые методы балансировки нагрузки, DeepSeek V3 обеспечивает эффективный инференс при масштабировании.
Многоголовое латентное внимание (MLA)
DeepSeek V3 включает многоголовое латентное внимание (MLA) — передовой механизм, доработанный от его предшественника DeepSeek V2. MLA обеспечивает несколько ключевых улучшений производительности модели:
- Низкоранговая совместная компрессия:
MLA повышает эффективность инференса за счёт сжатия ключей и значений внимания с помощью низкоранговых методов, значительно сокращая потребление памяти. - Снижение требований к хранилищу:
Кэшируя только сжатые латентные векторы, MLA минимизирует объём хранилища ключей-значений во время инференса без потери качества внимания. - Оптимизированные длинные зависимости:
Этот механизм внимания способствует эффективной обработке больших объёмов информации, особенно в задачах, требующих длинных зависимостей.
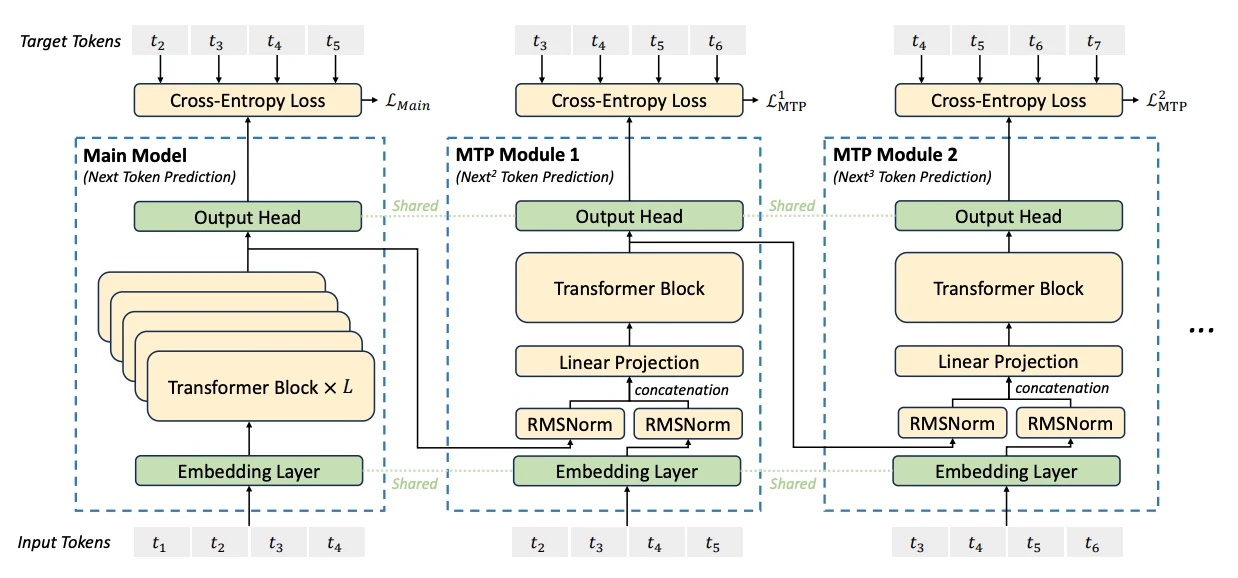
Предсказание нескольких токенов (MTP)
Ещё одним выдающимся нововведением DeepSeek V3 является цель обучения предсказанию нескольких токенов (MTP), которая переопределяет традиционные парадигмы предсказания следующего токена. Этот подход приносит ряд преобразующих преимуществ:
- Одновременное предсказание нескольких токенов:
Вместо предсказания только следующего токена MTP обучает модель предсказывать несколько будущих токенов на каждой позиции последовательности. - Уплотнённые сигналы обучения:
Увеличивая плотность сигналов обучения, MTP повышает эффективность использования данных и ускоряет обучение. - Улучшенное предварительное планирование представлений:
Эта цель позволяет модели разрабатывать более богатые контекстуальные представления, повышая производительность в задачах, требующих долгосрочного планирования или многошаговых рассуждений.
Дополнительные архитектурные особенности
DeepSeek V3 также выигрывает от ряда вспомогательных нововведений, оптимизирующих процессы обучения и инференса:
- DeepSeekMoE:
Специализированный механизм, оптимизирующий обучение слоёв MoE, обеспечивающий сбалансированное распределение рабочей нагрузки между экспертами и смягчающий дисбаланс. - Балансировка нагрузки без вспомогательных потерь:
Используя стратегию динамической настройки на основе смещений, DeepSeek V3 достигает эффективной балансировки нагрузки без использования функций вспомогательных потерь, сохраняя точность и эффективность. - Смешанная точность FP8:
Применение смешанной точности FP8 снижает затраты памяти и вычислений, сохраняя численную стабильность, что даёт значительный прирост эффективности использования ресурсов.
DeepSeek V3: снижение аппаратных барьеров
![]()
DeepSeek V3 спроектирован с учётом эффективности и масштабируемости, предлагая гибкие требования к оборудованию в зависимости от вариантов модели и сценариев развёртывания. Ниже приведена подробная разбивка минимальных и рекомендуемых аппаратных спецификаций, необходимых для эффективной работы DeepSeek V3.
Требования к оборудованию и рекомендации по конфигурации
-
Операционная система
- Windows 10 или новее
- macOS 10.15 или новее
- Linux (Ubuntu 18.04+)
-
Процессор
- Многоядерный процессор (минимум 4 ядра)
-
GPU
- Рекомендуются графические процессоры NVIDIA для более быстрого инференса
- Требуется больше VRAM для полной модели на 671 млрд параметров
- Работа только на процессоре возможна, но значительно медленнее
-
Память (ОЗУ)
- 8 ГБ: достаточно для самых маленьких версий (1,5B или 7B)
- 16 ГБ или более: рекомендуется для моделей среднего размера (14B или 32B)
-
Хранилище
- Требуется от 4 до 50 ГБ свободного места в зависимости от загруженного размера R1
-
Программные требования
- Python 3.10 для официальных скриптов R1
Сравнение с другими моделями
| Модель | GPU (VRAM) | ОЗУ | Память |
| DeepSeek V3 | Минимум 8 ГБ VRAM | 8–16 ГБ | Требуется от 4 до 50 ГБ свободного места |
| Llama 3.3 70B | 24–48 ГБ | Минимум 32 ГБ | Не менее 200 ГБ |
| Qwen 2.5 72B | 24 ГБ | Минимум 32 ГБ | / |
DeepSeek V3 локально: эффективно, но непросто
Хотя DeepSeek V3 представляет более эффективную с точки зрения оборудования архитектуру, остаются определённые сложности, особенно для пользователей с ограниченными ресурсами или устройствами потребительского класса:
- Ограничения потребительского оборудования:
Запуск полной модели на 671 млрд параметров локально требует значительных вычислительных мощностей, часто превышающих возможности стандартных ноутбуков или ПК. Даже меньшие варианты модели могут испытывать трудности на устройствах с ограниченной памятью GPU или возможностями процессора. - Проблемы установки и настройки:
Процесс настройки включает несколько технических шагов, таких как клонирование репозитория, установка зависимостей и преобразование весов модели. Эти задачи требуют знакомства с командной строкой и управления программными средами, что может стать барьером для менее технически подкованных пользователей. - Узкие места производительности на старых устройствах:
Старые или маломощные устройства могут испытывать серьёзное снижение производительности, приводящее к замедлению обработки, задержкам или даже сбоям. Более крупные модели могут быстро перегрузить ресурсы системы, делая их непрактичными для такого оборудования.
Эти сложности подчёркивают необходимость баланса между амбициозными возможностями DeepSeek и практическими требованиями к оборудованию для обычных пользователей.
Альтернативный доступ к DeepSeek V3: API, как Novita AI
Учитывая сложности запуска DeepSeek V3 на ограниченном или потребительском оборудовании, Novita AI предлагает более практичную и удобную альтернативу:
- Облачная доступность:
Novita AI устраняет необходимость в дорогом локальном оборудовании, используя облачную инфраструктуру, что делает передовые возможности ИИ доступными на любом устройстве с подключением к интернету. - Упрощённая настройка:
Novita AI не требует сложной установки или управления зависимостями. Пользователи могут получить доступ к её функциям напрямую через веб-интерфейс или API, обходя технические препятствия настройки DeepSeek V3. - Экономическая эффективность:
Вместо инвестиций в дорогие графические процессоры и оплаты высоких счетов за электроэнергию пользователи могут платить за услуги Novita AI по факту использования, что делает её более экономичной для многих сценариев.
Шаг 1: Войдите в систему и откройте библиотеку моделей
Войдите в свою учётную запись и нажмите кнопку Model Library (Библиотека моделей).

Попробуйте DeepSeek V3 Demo прямо сейчас!
Шаг 2: Выберите свою модель
Просмотрите доступные варианты и выберите модель, подходящую для ваших задач.

Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.

Шаг 4: Получите свой API-ключ
Для аутентификации с помощью API мы предоставим вам новый API-ключ. Перейдите на страницу «Settings» (Настройки) и скопируйте API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.

После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с Novita AI LLM. Вот пример использования chat completions API для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_v3"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
После регистрации Novita AI предоставляет кредит в размере 0,5 $, чтобы вы могли начать!
Если бесплатные кредиты закончатся, вы можете оплатить дальнейшее использование.
DeepSeek V3 знаменует собой большой скачок в области открытого ИИ благодаря своей передовой архитектуре и производительности. Однако локальное развёртывание сопряжено с аппаратными и техническими проблемами. Решения на основе API, такие как Novita AI, предлагают более доступную и масштабируемую альтернативу. По мере развития ИИ DeepSeek V3 будет способствовать созданию более эффективных приложений, а выбор между локальным и API-использованием будет зависеть от потребностей и ресурсов пользователя.
Часто задаваемые вопросы
Как сравниваются DeepSeek V3 и Llama 3.3 70B по бенчмаркам и вариантам использования?
DeepSeek V3 превосходит конкурентов в задачах программирования и математики, тогда как Llama 3.3 70B сильна в общих языковых и многоязычных приложениях.
Что такое архитектура смеси экспертов (MoE) и почему она важна?
MoE использует несколько «экспертов» для обработки конкретных входных токенов, повышая эффективность и производительность для сложных задач. Она более вычислительно эффективна, чем плотные модели, но по-прежнему требовательна к оборудованию.
Каковы требования к VRAM для DeepSeek V3?
Требования к VRAM для DeepSeek V3 зависят от точности. Для FP16 модель на 671 млрд параметров требует примерно 1 543 ГБ VRAM, а при 4-битном квантовании — примерно 386 ГБ VRAM. Активные параметры составляют 37 млрд.
Novita AI — это универсальная облачная платформа, расширяющая ваши ИИ-амбиции. Интегрированные API, бессерверные вычисления, GPU Instance — экономически эффективные инструменты, которые вам нужны. Откажитесь от инфраструктуры, начните бесплатно и воплотите своё ИИ-видение в реальность.



