

Destaques Principais
Arquitetura de IA Revolucionária
Apresenta inovações como Mixture-of-Experts (MoE), Multi-Head Latent Attention (MLA) e Multi-Token Prediction (MTP).
Requisitos de Hardware
Mínimo: 8 GB de VRAM, 8 GB de RAM, CPU multi-core.
Recomendado: 16 GB+ de RAM, mais VRAM para modelos maiores.
Execução apenas com CPU é mais lenta, mas possível.
Desafios
Configuração complexa e problemas de desempenho em dispositivos de consumo.
Alternativa Baseada em Nuvem
Novita AI: Simplifica o acesso via APIs, evitando limitações de hardware local.
No mundo da inteligência artificial, treinar e executar modelos de linguagem de grande porte sempre foi sinônimo de altos custos de hardware — especialmente a dependência de GPUs de ponta da NVIDIA, como A100 e H100, que se tornaram o padrão da indústria. No entanto, a arquitetura inovadora do DeepSeek está remodelando esse cenário. Este design revolucionário não só reduz a dependência de hardware caro, mas também abre as portas para IA de alto desempenho para uma gama mais ampla de desenvolvedores. Então, o que torna as inovações do DeepSeek tão únicas? E como elas desafiam o domínio da NVIDIA no mercado de hardware de IA? Vamos mergulhar para explorar.
DeepSeek V3: Arquitetura de IA Pioneira
https://www.youtube.com/watch?v=s\_s2GS8zLTE
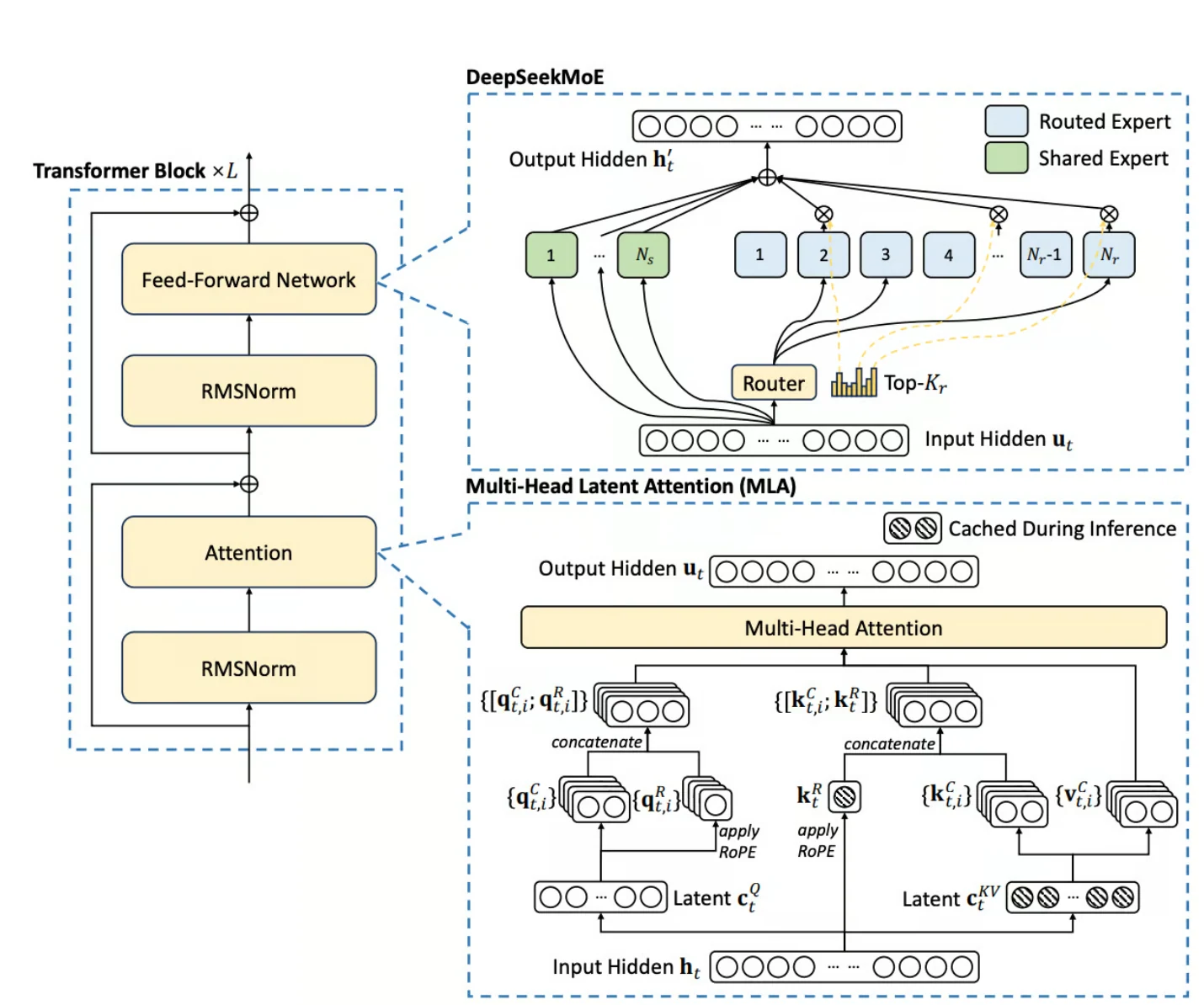
Arquitetura Mixture-of-Experts (MoE)
No núcleo do DeepSeek V3 está sua sofisticada arquitetura Mixture-of-Experts (MoE), um afastamento significativo dos modelos densos tradicionais. Esse paradigma permite que o modelo ative seletivamente subconjuntos específicos de parâmetros para diferentes entradas, resultando em benefícios notáveis:
- Escala Massiva com Ativação Seletiva:
O DeepSeek V3 possui impressionantes 671 bilhões de parâmetros, mas ativa apenas 37 bilhões de parâmetros por token, otimizando a eficiência computacional. - Seleção Dinâmica de Especialistas:
O modelo seleciona dinamicamente sub-redes de especialistas para cada entrada, reduzindo os custos computacionais gerais enquanto mantém alto desempenho. - Escalabilidade Eficiente com Balanceamento de Carga:
Ao empregar especialistas mais refinados e técnicas avançadas de balanceamento de carga, o DeepSeek V3 garante inferência eficiente em termos de recursos enquanto escala de forma eficaz.
Multi-Head Latent Attention (MLA)
O DeepSeek V3 incorpora Multi-Head Latent Attention (MLA), um mecanismo de ponta refinado a partir de seu predecessor, DeepSeek V2. O MLA impulsiona vários avanços importantes no desempenho do modelo:
- Compressão Conjunta de Baixo Posto:
O MLA melhora a eficiência da inferência ao comprimir chaves e valores de atenção por meio de técnicas de baixo posto, reduzindo significativamente a sobrecarga de memória. - Requisitos de Armazenamento Reduzidos:
Ao armazenar em cache apenas vetores latentes comprimidos, o MLA minimiza o armazenamento de chave-valor durante a inferência sem sacrificar a qualidade da atenção. - Dependências de Longo Alcance Otimizadas:
Esse mecanismo de atenção é fundamental para processar informações em grande escala de forma eficiente, especialmente em tarefas que exigem dependências de longo alcance.
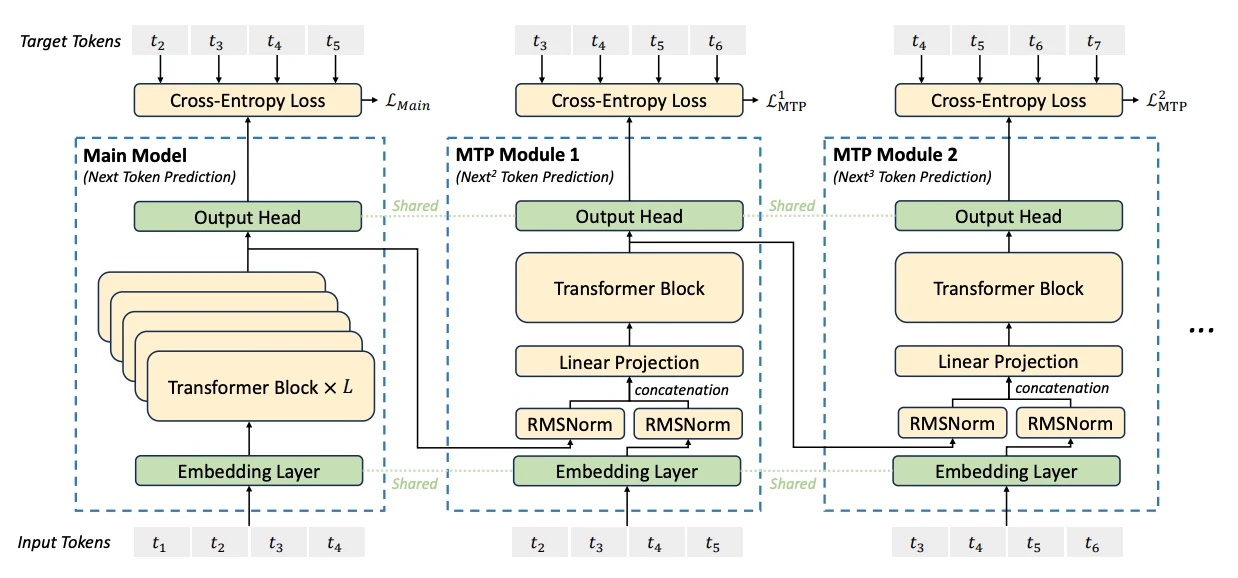
Multi-Token Prediction (MTP)
Uma inovação de destaque no DeepSeek V3 é seu objetivo de treinamento Multi-Token Prediction (MTP), que redefine os paradigmas tradicionais de predição do próximo token. Essa abordagem introduz vários benefícios transformadores:
- Predição Simultânea de Múltiplos Tokens:
Em vez de prever apenas o próximo token, o MTP treina o modelo para prever múltiplos tokens futuros em cada posição da sequência. - Sinais de Treinamento Densificados:
Ao aumentar a densidade dos sinais de treinamento, o MTP melhora a eficiência dos dados e acelera o aprendizado. - Pré-Planejamento Aprimorado de Representações:
Esse objetivo permite que o modelo desenvolva representações contextuais mais ricas, impulsionando o desempenho em tarefas que exigem planejamento de longo prazo ou raciocínio em várias etapas.
Recursos Adicionais da Arquitetura
O DeepSeek V3 também se beneficia de várias inovações auxiliares que otimizam seus processos de treinamento e inferência:
- DeepSeekMoE:
Um mecanismo especializado que otimiza o treinamento das camadas MoE, garantindo distribuição equilibrada da carga de trabalho entre os especialistas, mitigando desequilíbrios. - Balanceamento de Carga Sem Perda Auxiliar:
Ao alavancar uma estratégia de ajuste dinâmico baseada em viés, o DeepSeek V3 alcança balanceamento de carga eficaz sem depender de funções de perda auxiliares, mantendo precisão e eficiência. - Estrutura de Precisão Mista FP8:
A adoção de precisão mista FP8 reduz os custos de memória e computação, preservando a estabilidade numérica, oferecendo um impulso significativo à eficiência dos recursos.
DeepSeek V3: Reduzindo as Barreiras de Hardware
![]()
O DeepSeek V3 foi projetado com eficiência e escalabilidade em mente, oferecendo requisitos de hardware flexíveis adaptados às suas variantes de modelo e cenários de implantação. Abaixo está um detalhamento das especificações mínimas e recomendadas de hardware necessárias para executar o DeepSeek V3 de forma eficaz.
Requisitos de Hardware e Recomendações de Configuração
-
Sistema Operacional
- Windows 10 ou mais recente
- macOS 10.15 ou posterior
- Linux (Ubuntu 18.04+)
-
CPU
- Processador multi-core (mínimo 4 núcleos)
-
GPU
- GPUs NVIDIA recomendadas para inferência mais rápida
- Mais VRAM necessária para o modelo completo de 671B
- Execução apenas com CPU possível, mas significativamente mais lenta
-
Memória (RAM)
- 8 GB: Suficiente para as versões menores (1,5B ou 7B)
- 16 GB ou mais: Recomendado para modelos intermediários (14B ou 32B)
-
Armazenamento
- 4–50 GB de espaço livre necessário, dependendo do tamanho do R1 baixado
-
Requisitos de Software
- Python 3.10 para scripts oficiais do R1
Comparação com Outros Modelos
| Modelo | GPU (VRAM) | RAM | Armazenamento |
| DeepSeek V3 | Mínimo 8 GB de VRAM | 8~16 GB | 4–50 GB de espaço livre necessário |
| Llama 3.3 70B | 24-48 GB | Mínimo 32 GB | Pelo menos 200 GB |
| Qwen 2.5 72B | 24 GB | Mínimo 32 GB | / |
DeepSeek V3 Localmente: Eficiente, Mas Desafiador
Embora o DeepSeek V3 introduza uma arquitetura mais eficiente em termos de hardware, certos desafios permanecem, particularmente para usuários com recursos limitados ou dispositivos de consumo:
- Limitações do Hardware de Consumo:
Executar o modelo completo de 671 bilhões de parâmetros localmente requer poder computacional significativo, muitas vezes excedendo as capacidades de laptops ou desktops padrão. Mesmo variantes menores do modelo podem ter dificuldades em dispositivos com memória de GPU ou capacidade de CPU limitadas. - Problemas de Instalação e Configuração:
O processo de configuração envolve várias etapas técnicas, como clonar o repositório, instalar dependências e converter pesos do modelo. Essas tarefas exigem familiaridade com ferramentas de linha de comando e gerenciamento de ambientes de software, o que pode ser uma barreira para usuários menos técnicos. - Gargalos de Desempenho em Dispositivos Antigos:
Dispositivos antigos ou com baixo desempenho podem sofrer degradação severa de desempenho, levando a processamento mais lento, travamentos ou até falhas. Modelos maiores podem sobrecarregar rapidamente os recursos do sistema, tornando-os impraticáveis para esse hardware.
Esses desafios destacam a necessidade de equilíbrio entre as ambiciosas capacidades do DeepSeek e os requisitos práticos de hardware para usuários comuns.
Acessando uma Alternativa ao DeepSeek V3: API como Novita AI
Dados os desafios de executar o DeepSeek V3 em hardware limitado ou de consumo, a Novita AI oferece uma alternativa mais prática e amigável:
- Acessibilidade Baseada em Nuvem:
A Novita AI elimina a necessidade de hardware local de ponta ao alavancar infraestrutura em nuvem, tornando capacidades avançadas de IA acessíveis em qualquer dispositivo com conexão à internet. - Configuração Simplificada:
A Novita AI não requer instalação complexa ou gerenciamento de dependências. Os usuários podem acessar seus recursos diretamente por meio de uma interface web ou API, evitando os obstáculos técnicos de configurar o DeepSeek V3. - Eficiência de Custos:
Em vez de investir em GPUs caras e lidar com altos custos de eletricidade, os usuários podem pagar pelos serviços da Novita AI com base no uso, tornando-a mais econômica para muitos cenários.
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

[Experimente o DeepSeek V3 Demo Agora!](https://novita.ai/models/llm/deepseek-deepseek_v3/?utm_source=blog_llm&utm_medium=article&utm_campaign= what-are-the-requirements-for-deepseek-v3-inference)
Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.

Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos a você uma nova chave de API. Acessando a página “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o Novita AI LLM. Este é um exemplo de uso de chat completions API para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_v3"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Ao se registrar, a Novita AI fornece um crédito de $0,5 para você começar!
Se os créditos gratuitos acabarem, você pode pagar para continuar usando.
O DeepSeek V3 marca um grande salto na IA de código aberto com sua arquitetura avançada e desempenho. No entanto, a implantação local apresenta desafios de hardware e técnicos. Soluções baseadas em API, como a Novita AI, oferecem uma alternativa mais acessível e escalável. À medida que a IA evolui, o DeepSeek V3 impulsionará aplicações mais eficientes, cabendo ao usuário escolher entre uso local e via API conforme suas necessidades e recursos.
Perguntas Frequentes
Como o DeepSeek V3 e o Llama 3.3 70B se comparam em termos de benchmarks e casos de uso?
O DeepSeek V3 é superior para tarefas de codificação e matemática, enquanto o Llama 3.3 70B se destaca em aplicações de linguagem geral e multilíngues.
O que é uma arquitetura Mixture-of-Experts (MoE) e por que é importante?
MoE usa vários “especialistas” para processar tokens de entrada específicos, melhorando a eficiência e o desempenho em tarefas complexas. É mais eficiente computacionalmente do que modelos densos, mas ainda requer bastante hardware.
Quais são os requisitos de VRAM para o DeepSeek V3?
Os requisitos de VRAM para o DeepSeek V3 variam conforme a precisão. Para FP16, o modelo de 671B requer aproximadamente 1.543 GB de VRAM, enquanto com quantização de 4 bits, requer aproximadamente 386 GB de VRAM. Os parâmetros ativos são 37B.
Novita AI é a plataforma em nuvem completa que impulsiona suas ambições de IA. APIs integradas, serverless, instância GPU — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA realidade.



