

Große Sprachmodelle (LLMs) wie Llama-3-Nemotron-Ultra-253B-V1 revolutionieren die KI und ermöglichen erweiterte logische Schlussfolgerungen, Codierung und mehrsprachige Chat-Funktionen. Um ihre volle Leistungsfähigkeit auszuschöpfen, benötigt man jedoch Zugang zu leistungsstarken GPUs – Hardware, die für Einzelpersonen und kleinere Organisationen oft unerschwinglich ist. Das Mieten von GPUs über Cloud-Plattformen hat sich als die praktischste und kosteneffektivste Lösung erwiesen, um diese hochmodernen Modelle auszuführen.
Llama-3-Nemotron-Ultra-253B-V1 verstehen
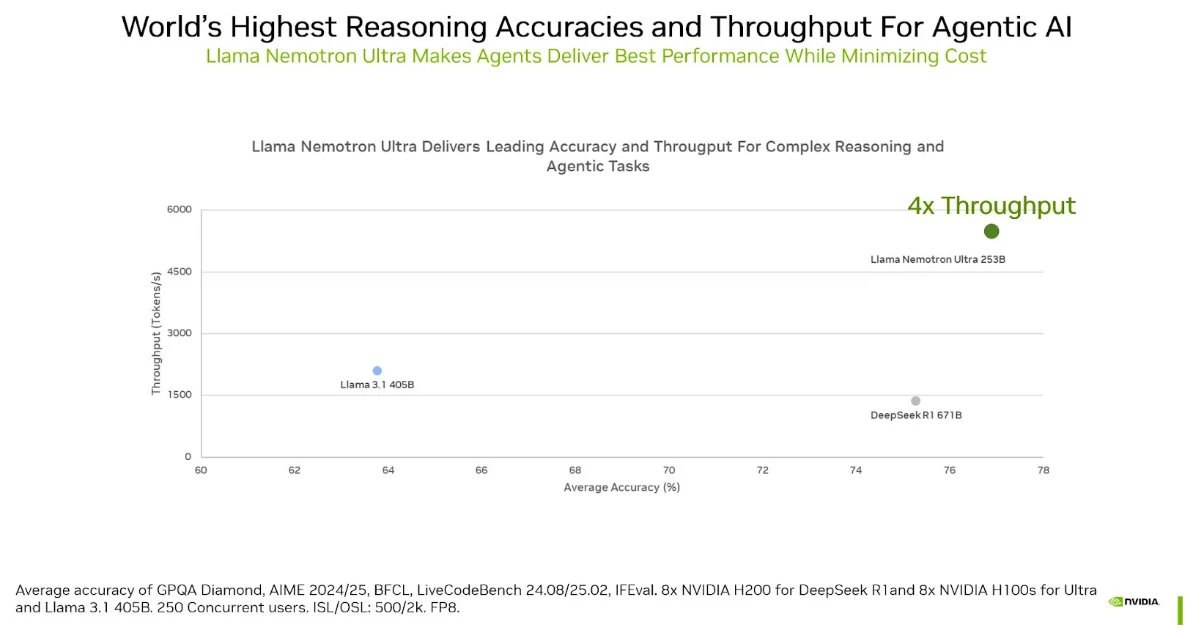
Llama-3-Nemotron-Ultra-253B-V1 ist das fortschrittliche LLM von NVIDIA, das auf Metas Llama-3.1-405B-Instruct basiert. Es ist für allgemeines logisches Denken, Chat, Codierung, Retrieval-Augmented Generation (RAG) und Tool-Aufrufe konzipiert. Das Modell verfügt über ein Kontextfenster von bis zu 128.000 Token und unterstützt mehrere Sprachen, darunter Englisch, Deutsch, Französisch, Italienisch, Portugiesisch, Hindi, Spanisch und Thai.
Was dieses Modell auszeichnet, ist seine Effizienz: Dank einer neuartigen Neural Architecture Search (NAS) und vertikaler Komprimierungsmethoden erreicht es eine hohe Genauigkeit bei gleichzeitiger Reduzierung des Speicherfußabdrucks und der Latenz. Das bedeutet, dass es komplexe Aufgaben mit weniger GPUs bewältigen kann, was es für kommerzielle und Forschungsanwendungen zugänglicher macht.
Quelle: https://www.nvidia.com/
Warum Sie leistungsstarke GPUs für Llama-3-Nemotron-Ultra-253B-V1 benötigen
GPU-Anforderungen für große Sprachmodelle
LLMs wie Llama-3-Nemotron-Ultra-253B-V1 sind rechenintensiv. Für die Inferenz ist das Modell so optimiert, dass es auf einem einzelnen Knoten mit 8× NVIDIA H100 GPUs mit jeweils 80 GB VRAM läuft. Das Training oder Feintuning eines solchen Modells erfordert noch mehr Rechenleistung, hohe Speicherbandbreite und schnelle Verbindungen.
Vorteile des Mietens von GPUs
- Kosteneffizienz: Das Mieten vermeidet die hohen Anschaffungskosten für den Kauf von GPUs sowie laufende Kosten für Wartung, Upgrades und Energieverbrauch.
- Zugang zu neuester Technologie: Mietdienste aktualisieren ihre Hardware häufig, sodass Sie die neuesten GPUs nutzen können, ohne sich um Veralterung sorgen zu müssen.
- Skalierbarkeit: Ressourcen können je nach Projektbedarf problemlos hoch- oder heruntergefahren werden – ideal für Experimente, Trainingsspitzen oder temporäre Einsätze.
- Schnellere Markteinführung: Die schnelle Bereitstellung und flexible Mietzeiträume ermöglichen es, innerhalb von Minuten mit dem Training oder der Inferenz zu beginnen, nicht innerhalb von Wochen.
So wählen Sie die richtige GPU für Llama-3-Nemotron-Ultra-253B-V1
Die benötigten Spezifikationen verstehen
Bei der Auswahl von GPUs für Llama-3-Nemotron-Ultra-253B-V1 sollten Sie Folgendes beachten:
- VRAM: Das Modell ist so ausgelegt, dass es für die Inferenz auf einen einzelnen 8×H100-Knoten passt. Jede NVIDIA H100-80GB GPU verfügt über 80 GB VRAM, sodass der gesamte benötigte VRAM etwa 640 GB (8 × 80 GB) beträgt.
- Rechenleistung: NVIDIA H100 und A100 sind die erste Wahl aufgrund ihrer KI-optimierten Architektur und hohem Durchsatz.
- Bandbreite: Eine hohe Speicherbandbreite gewährleistet eine schnellere Datenübertragung, was für große Modelle entscheidend ist.
- Verbindung: NVLink oder ähnliche schnelle Verbindungen sind für Multi-GPU-Setups wichtig.
Top-GPUs für Llama-3-Nemotron-Ultra-253B-V1
Basierend auf den Anforderungen des Modells werden folgende GPUs empfohlen:
| GPU-Modell | VRAM | Bester Anwendungsfall |
|---|---|---|
| NVIDIA H100 | 80GB | Inferenz & Training, erste Wahl |
| NVIDIA A100 | 40/80GB | Training, groß angelegte Inferenz |
| NVIDIA RTX 6000 Ada | 48GB | Kleinere LLMs, Prototyping |
Schritt-für-Schritt-Anleitung zum Mieten von GPUs für Ihre KI-Modelle
Novita AI ist eine führende Plattform, die flexible und effiziente Cloud-GPU-Computing-Ressourcen für Unternehmen und Forscher bietet. Mit erstklassigen GPUs wie der H100 und RTX 4090 unterstützt Novita AI die Bereitstellung und das Training komplexer KI-Modelle und bietet Zugang zu leistungsstarker Rechenleistung ohne hohe Hardware-Investitionen. Das Pay-as-you-go-Modell und die benutzerfreundliche Oberfläche machen die Plattform ideal für Projekte, die Hochleistungsrechnen erfordern, wie das Training großer Modelle wie Llama-3 und Nemotron-Ultra 253B.
Das Mieten von GPUs für anspruchsvolle KI-Aufgaben wie das Training oder die Bereitstellung von Llama-3 und Nemotron-Ultra 253B ist mit Plattformen wie Novita AI unkompliziert. Hier ist eine Schritt-für-Schritt-Anleitung für den Einstieg:
Schritt 1: Erstellen Sie ein Konto
Starten Sie in wenigen Minuten: Erstellen Sie Ihr Konto auf der Plattform von Novita AI und navigieren Sie zu unserem GPU-Marktplatz. Durchstöbern Sie unsere kuratierte Auswahl an leistungsstarken Instanzen mit detaillierten Spezifikationen und Benchmark-Daten. Wählen Sie Ihre optimale Konfiguration basierend auf Ihren Modellanforderungen und starten Sie Ihre Instanz mit nur wenigen Klicks. Unser optimierter Bereitstellungsprozess stellt sicher, dass Sie sich auf das Wesentliche konzentrieren können – Ihre KI-Entwicklung.

[Jetzt Novita AI ausprobieren](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Taming the Beast: How to Rent GPUs for Llama-3 and Nemotron-Ultra 253B)
Schritt 2: Wählen Sie Ihre GPU
Erleben Sie unvergleichliche Rechenleistung mit unserer hochmodernen GPU-Infrastruktur. Unsere Plattform bietet die neuesten NVIDIA GPUs mit außergewöhnlicher Leistung für große Sprachmodelle. Mit umfangreicher VRAM-Kapazität und optimierten RAM-Konfigurationen stellen wir sicher, dass Ihre KI-Modelle mit höchster Effizienz trainieren. Wählen Sie aus unserer umfassenden Vorlagenbibliothek oder erstellen Sie Ihre eigene Lösung – unsere Plattform passt sich Ihrem Workflow an.

[Testen Sie die Hochleistungs-GPUs von Novita AI](https://novita.ai/gpus-console/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Taming the Beast: How to Rent GPUs for Llama-3 and Nemotron-Ultra 253B)
Schritt 3: Passen Sie Ihr Setup an
Starten Sie mit 60 GB kostenlosem Container-Disk-Speicher und skalieren Sie nahtlos, wenn Ihre Projekte wachsen. Unsere flexiblen Speicherlösungen passen sich Ihren Anforderungen an, egal ob Sie Prototypen erstellen oder in die Produktion gehen. Wählen Sie zwischen der Flexibilität des Pay-as-you-go-Modells oder kosteneffizienten Abonnementplänen – alle mit sofortiger Bereitstellung und ohne versteckte Kosten.

Details zu den spezifischen Abonnementstufen und Preisen finden Sie in der folgenden Tabelle:
| Option | RTX 3090 24 GB | RTX 4090 24 GB | RTX 6000 Ada 48GB | H100 SXM 80 GB |
| 1–5 Monate | 136,00 $/Monat (10 % Rabatt) | 226,80 $/Monat (10 % Rabatt) | 453,60 $/Monat (10 % Rabatt) | 1.872,72 $/Monat (10 % Rabatt) |
| 6–11 Monate | 129,00 $/Monat (15 % Rabatt) | 206,64 $/Monat (18 % Rabatt) | 428,40 $/Monat (15 % Rabatt) | 1.664,64 $/Monat (20 % Rabatt) |
| 12 Monate | 113,40 $/Monat (25 % Rabatt) | 189,00 $/Monat (25 % Rabatt) | 403,20 $/Monat (20 % Rabatt) | 1.498,18 $/Monat (28 % Rabatt) |
Schritt 4: Starten Sie Ihre Instanz
Wählen Sie Ihren Weg zur Leistung: flexibles On-Demand-Pricing oder kosteneffiziente Abonnementpläne. Überprüfen Sie Ihre individuell angepasste Konfiguration und die Preisdetails und starten Sie Ihre Instanz mit einem einzigen Klick. Ihre GPU-Umgebung ist sofort bereit – keine komplexe Einrichtung, kein Warten. Beginnen Sie sofort mit Innovationen.

Fazit
Das Mieten von GPUs ist die praktischste, skalierbarste und kosteneffektivste Lösung für den Betrieb fortschrittlicher Modelle wie Llama-3 und Nemotron-Ultra 253B. Indem Sie die Anforderungen Ihres Modells verstehen und die richtige Hardware auswählen, können Sie die volle Leistungsfähigkeit moderner KI nutzen, ohne den Aufwand des Hardwarebesitzes. Egal, ob Sie ein einzelner Forscher oder ein KI-Team in einem Unternehmen sind – GPU-Mietplattformen bieten Ihnen erstklassige Rechenleistung auf Knopfdruck, sodass Sie sich auf das Bauen, Experimentieren und Innovieren mit den neuesten großen Sprachmodellen konzentrieren können.
Häufig gestellte Fragen
Welche GPU-Spezifikationen sollte ich beim Mieten für Llama-3-Nemotron-Ultra-253B-V1 beachten?
Achten Sie auf GPUs mit mindestens 80 GB VRAM (wie NVIDIA H100 oder A100), hoher Speicherbandbreite und Unterstützung für die neuesten KI-optimierten Architekturen (Hopper oder Ampere). Multi-GPU-Konfigurationen mit schnellen Verbindungen (z. B. NVLink) werden für eine optimale Leistung empfohlen.
Kann ich Llama-3-Nemotron-Ultra-253B-V1 für kommerzielle Anwendungen nutzen?
Ja, das Modell ist für den kommerziellen Einsatz bereit und kann in Produktionsumgebungen für eine Vielzahl fortgeschrittener KI-Aufgaben integriert werden.
Worauf sollte ich bei einem GPU-Mietanbieter achten?
Wichtige Faktoren sind verfügbare GPU-Modelle und VRAM, Skalierungsoptionen, Preise, Einrichtungsaufwand und Unterstützung für Ihren bevorzugten Software-Stack (CUDA, PyTorch, TensorFlow).
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=The Uncertain Future of GPU Pricing: Why Cloud GPUs Offer Stability in 2025) ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitzustellen.
Empfohlene Lektüre
[Die Leistungsfähigkeit der Llama 3 Modelle entdecken](http://Discover the Power of Llama 3 Models)
[Llama 3 meistern: So nutzen Sie es auf 3 Arten](http://Mastering Llama 3: How to Use it in 3 Approaches)
[Fortgeschrittene KI-Entwicklung mit Llama 3 400B](http://Advanced AI Development with Llama 3 400B)



