

Wichtige Highlights
Das Fine-Tuning des LLaMA 3.2 90B Modells erfordert mindestens 180 GB VRAM, was es für lokale Einrichtungen herausfordernd macht.
Speicherbeschränkungen können das Fine-Tuning von LLaMA 3.2 90B erschweren.
Parametereffiziente Fine-Tuning-Methoden (PEFT) wie LoRA und QLoRA können helfen, diese Herausforderungen zu mildern.
Cloudbasierte Lösungen bieten eine kostengünstige Alternative zu teurer lokaler Hardware. Sie können GPU-Instanzen von Novita AI nutzen – Bei der Registrierung erhalten Sie 60 GB kostenlosen Container-Disk und 1 GB kostenlosen Volume-Disk. Wenn das kostenlose Limit überschritten wird, fallen zusätzliche Gebühren an.
Die LLaMA 3.2 Familie von großen Sprachmodellen bietet eine Reihe von Fähigkeiten, von Textgenerierung bis hin zu Bildverständnis. Unter diesen Modellen sticht die 90B-Variante aufgrund ihrer Größe und multimodalen Fähigkeiten hervor. Das Fine-Tuning eines so großen Modells erfordert jedoch eine erhebliche Menge an VRAM (Video-RAM), was für viele Benutzer eine Herausforderung darstellen kann. Dieser Artikel befasst sich mit den VRAM-Anforderungen für das Fine-Tuning von LLaMA 3.2 90B und bietet einen praktischen Leitfaden für diejenigen, die diese Aufgabe übernehmen möchten.
Analyse der VRAM-Anforderungen für das Fine-Tuning von LLaMA 3.2 90B
Das LLaMA 3.2 90B Modell ist ein großes Modell mit 90 Milliarden Parametern. Diese Größe wirkt sich direkt auf die Menge an VRAM aus, die sowohl für die Inferenz als auch für das Fine-Tuning benötigt wird. Das Modell ist hauptsächlich für groß angelegte Anwendungen konzipiert, was die höheren VRAM-Anforderungen erklärt.
Sie möchten entweder einen dualen 3090-Aufbau oder einen Mac M1/M2 Ultra 64-128GB (128 wird bevorzugt). Die 3090er werden gewünscht, wenn Sie Vision, Training oder Bildgenerierung (Stable Diffusion/Flux) durchführen möchten. Der Mac ist besser für reine Inferenz geeignet, da die 128GB mit höherer Quantisierung laufen, größere Modelle verarbeiten, sehr leise sind und kaum Strom verbrauchen.
Von Reddit
Detaillierte Hardwareanforderungen

Vergleich der VRAM-Anforderungen mit anderen Modellen

Wie wählt man eine geeignete GPU für das Fine-Tuning aus?
Die Auswahl der richtigen GPU ist entscheidend für das Fine-Tuning des LLaMA 3.2 90B Modells. Angesichts der VRAM-Anforderungen des Modells sind nicht alle GPUs geeignet.
Wichtige Auswahlkriterien
Bei der Auswahl einer GPU für das Fine-Tuning sollten Sie Folgendes beachten:
- VRAM-Kapazität: Der primäre Faktor, da das Modell etwa 180GB VRAM benötigt, um vollständig geladen zu werden.
- Rechenleistung: Die Fähigkeit der GPU, komplexe Berechnungen durchzuführen, beeinflusst die Trainingsgeschwindigkeit.
- Speicherbandbreite: Die Geschwindigkeit, mit der die GPU auf Daten zugreifen und sie verarbeiten kann, ist entscheidend für die Leistung.
- Kosten: High-End-GPUs können sehr teuer sein. Die Kosteneffizienz muss mit den Leistungsanforderungen abgewogen werden.
Empfohlene GPUs für das Fine-Tuning von LLaMA 3.2 90B
Angesichts dieser Kriterien sind hier einige empfohlene GPUs:
- NVIDIA A100: Diese GPU wird häufig als ideale Option genannt, mit 40GB-80GB VRAM je nach Modell. Mehrere A100s können verwendet werden, um die VRAM-Anforderungen zu erfüllen.
- NVIDIA RTX 3090: Obwohl sie aufgrund ihrer 24GB VRAM allein nicht ideal ist, kann ein dualer Aufbau verwendet werden, was jedoch eine niedrigere Quantisierung oder das Aufteilen des Modells erfordern kann.
- NVIDIA RTX 4090: Ähnlich wie die RTX 3090 können zwei dieser Karten ausreichend VRAM bieten, erfordern jedoch möglicherweise eine Quantisierung oder Aufteilung.
- AMD MI60/MI100: Dies sind alternative Optionen, die beträchtlichen VRAM bieten können, aber möglicherweise spezifische Systemkonfigurationen erfordern.
Anleitung zur Durchführung des Fine-Tunings
Das Fine-Tuning von LLaMA 3.2 90B beinhaltet die Verwendung von Bibliotheken wie Transformers und Accelerate. Der Prozess umfasst das Laden des Modells, die Vorbereitung eines Datensatzes, das Setzen von Hyperparametern, das Training und das Speichern des feinabgestimmten Modells. Die Verwendung von LoRA (Low-Rank Adaptation) kann den Speicherverbrauch reduzieren, indem nur ein kleiner Teil des Modells feinabgestimmt wird.
- Richten Sie eine geeignete Umgebung mit den erforderlichen Bibliotheken ein.
- Laden Sie das LLaMA 3.2 90B Modell und den Tokenizer.
- Bereiten Sie den Datensatz für das Fine-Tuning vor.
- Konfigurieren Sie LoRA, um den Speicherverbrauch während des Fine-Tunings zu reduzieren.
- Stellen Sie die Trainingsargumente ein, einschließlich Batch-Größe, Lernrate und Anzahl der Epochen.
- Verwenden Sie einen überwachten Fine-Tuning-Trainer, um das Modell zu trainieren und zu bewerten.
- Speichern Sie das feinabgestimmte Modell lokal und in einem Hub wie Hugging Face.
- Führen Sie den feinabgestimmten LoRA-Adapter mit dem Basismodell zusammen.
https://www.youtube.com/watch?v=nUeIjs3THNM
Technische Herausforderungen und Lösungen
Das Fine-Tuning des LLaMA 3.2 90B Modells ist nicht ohne Herausforderungen:
- Hoher VRAM-Bedarf: Die größte Herausforderung ist der enorme VRAM-Bedarf, der die Kapazität vieler consumer-GPUs übersteigt.
- Rechenintensität: Das Fine-Tuning eines Modells dieser Größe ist rechenintensiv und erfordert eine leistungsstarke CPU und GPU.
- Langsame Verarbeitung: Wenn die Hardware nicht ausreicht, kann der Prozess sehr langsam sein, was ihn für viele Anwendungen unpraktisch macht.
- Quantisierungs-Kompromisse: Während die Quantisierung den VRAM-Verbrauch reduziert, kann sie die Qualität des feinabgestimmten Modells beeinträchtigen.
Um diese Herausforderungen zu bewältigen, können verschiedene Lösungen eingesetzt werden:
- Quantisierung: Die Verwendung von Techniken wie 4-Bit-Quantisierung kann den VRAM-Fußabdruck des Modells reduzieren. Dies kann jedoch die Genauigkeit des Modells beeinträchtigen.
- Modell-Parallelität: Die Verteilung des Modells auf mehrere GPUs kann helfen, VRAM-Beschränkungen zu verwalten.
- Auslagerung in den Systemspeicher: Einige Systeme können Teile des Modells in den Arbeitsspeicher auslagern, was jedoch zu einer drastischen Leistungsminderung führt.
- LoRA (Low-Rank Adaptation): Diese Technik beinhaltet das Fine-Tuning nur eines kleinen Teils des Modells, wodurch der Speicherbedarf reduziert wird.
Alternative Lösungen – Cloud GPU
Schritt 1: Klicken Sie auf die GPU-Instanz
Wenn Sie ein neuer Abonnent sind, registrieren Sie bitte zuerst Ihren Account. Klicken Sie dann auf die Schaltfläche [GPU-Instanz](https://novita.ai/gpus/?utm_source=blogs_gpu&utm_medium=article&utm_campaign= fine-tuning-llama-3-3-70b-with-rtx-4090) auf unserer Webseite.
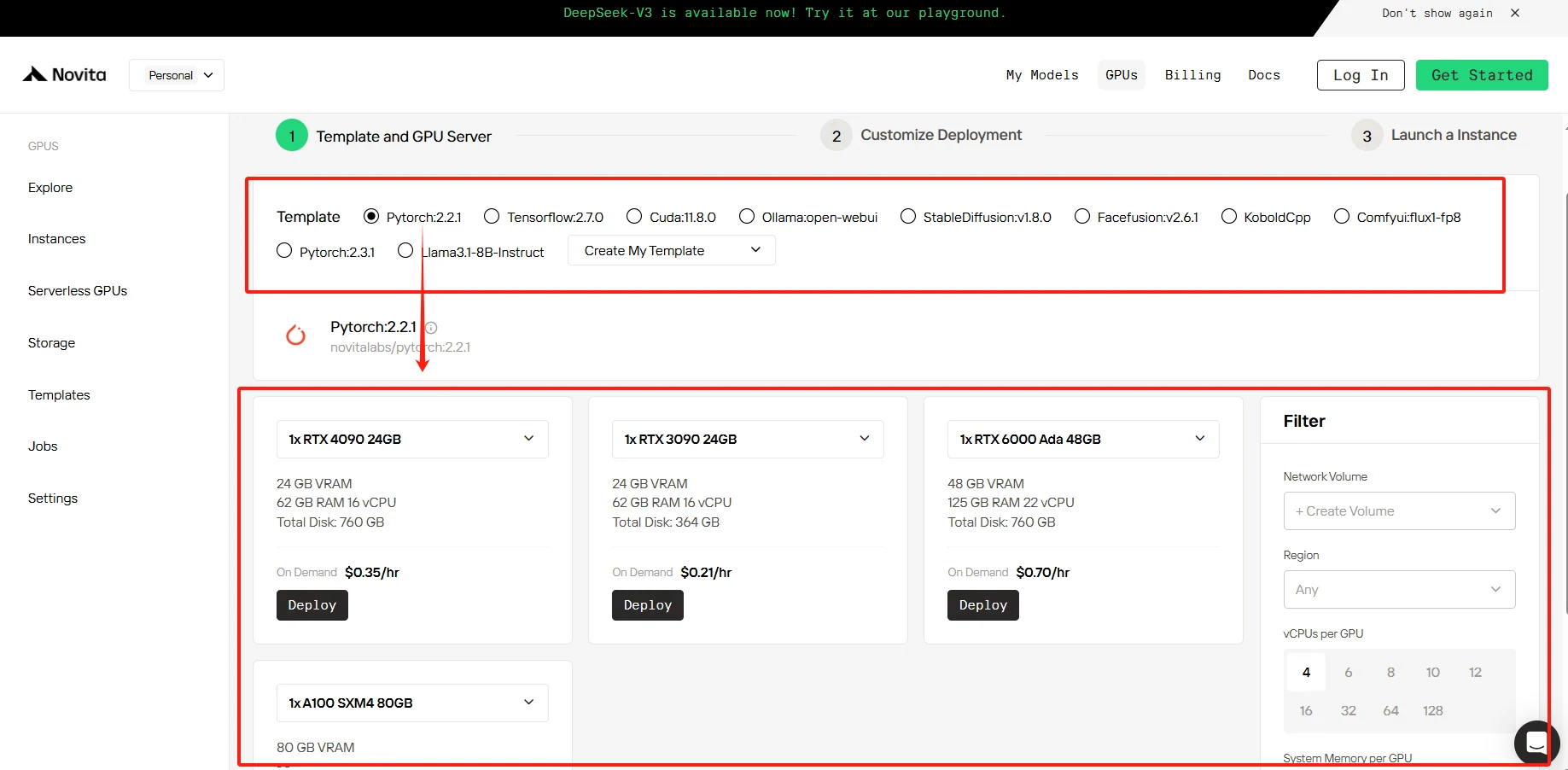
SCHRITT 2: Vorlage und GPU-Server
Sie können Ihre eigene Vorlage auswählen, einschließlich Pytorch, Tensorflow, Cuda, Ollama, je nach Ihren spezifischen Anforderungen. Darüber hinaus können Sie auch eigene Vorlagendaten erstellen, indem Sie auf die unterste Schaltfläche klicken.
Unser Dienst bietet Zugang zu leistungsstarken GPUs wie der NVIDIA RTX 4090, jede mit beträchtlichem VRAM und RAM, um sicherzustellen, dass selbst die anspruchsvollsten KI-Modelle effizient trainiert werden können. Sie können je nach Bedarf auswählen.
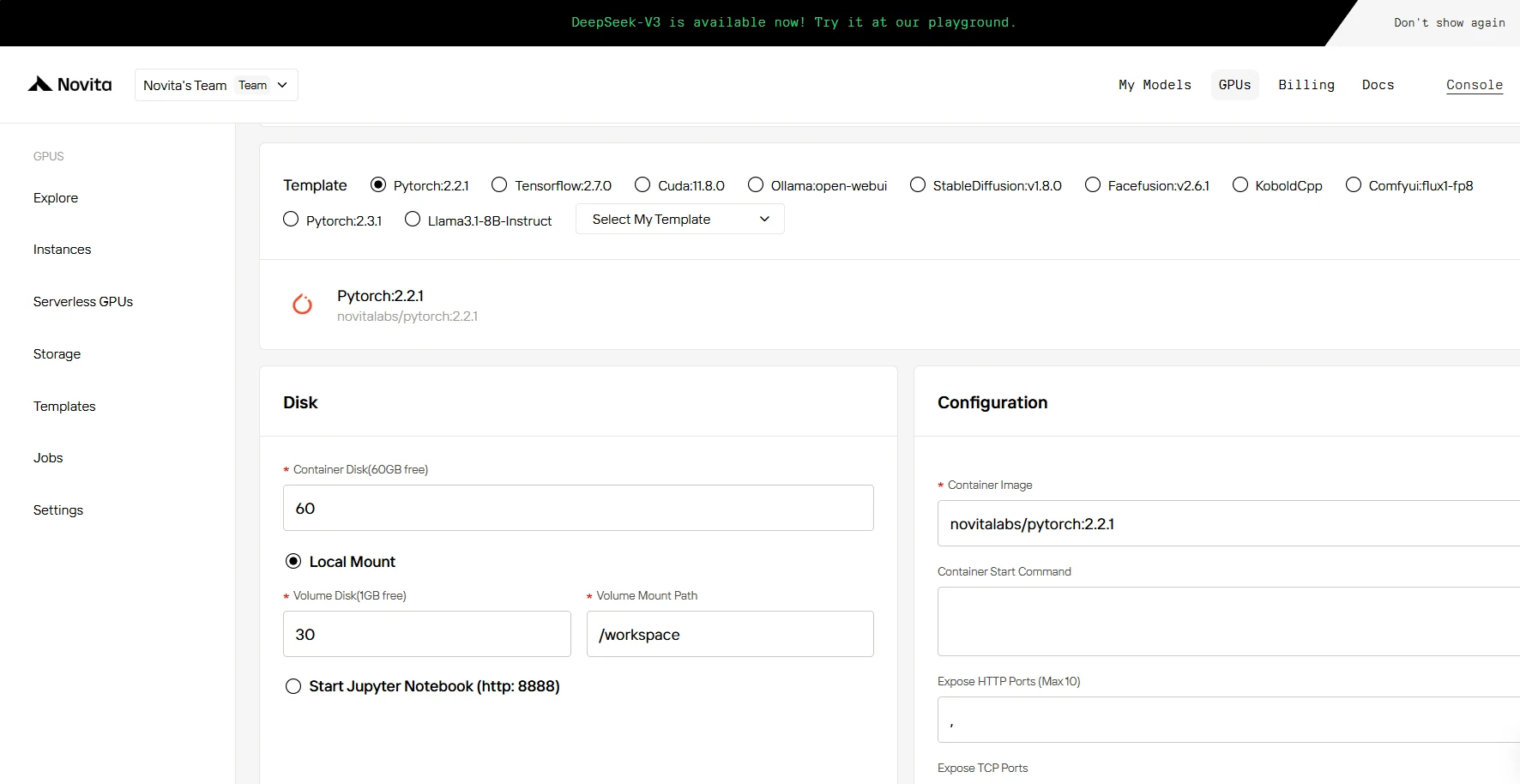
SCHRITT 3: Bereitstellung anpassen
In diesem Abschnitt können Sie diese Daten nach Ihren eigenen Bedürfnissen anpassen. Es gibt 60 GB kostenlosen Container-Disk und 1 GB kostenlosen Volume-Disk. Wenn das kostenlose Limit überschritten wird, fallen zusätzliche Gebühren an.
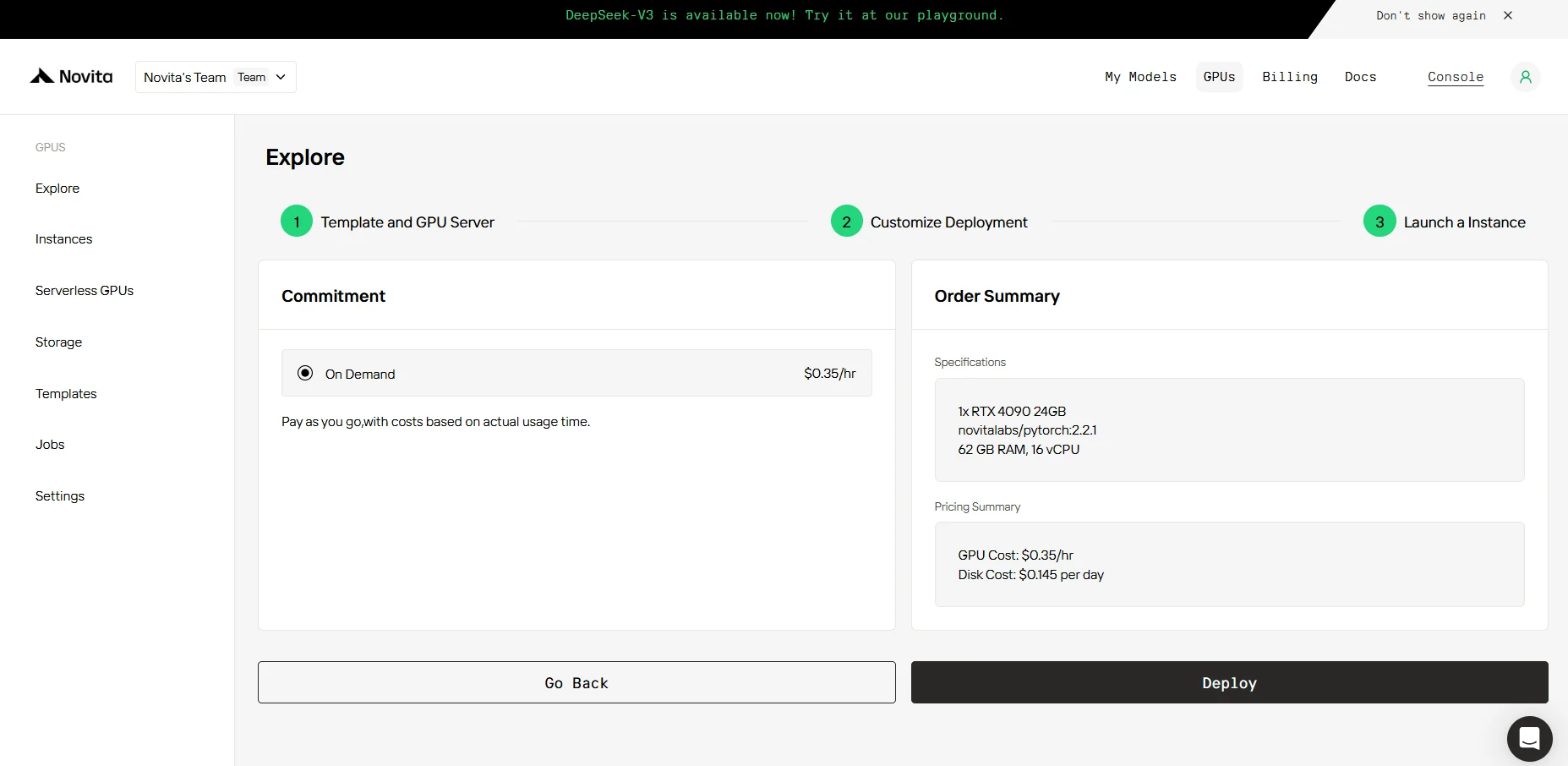
SCHRITT 4: Starten Sie eine Instanz
Ob für Forschung, Entwicklung oder Bereitstellung von KI-Anwendungen – die Novita AI GPU-Instanz mit CUDA 12 bietet eine leistungsstarke und effiziente GPU-Computing-Erfahrung in der Cloud.
Warum Cloud-GPU-Instanzen wählen?
Cloud-GPU-Instanzen bieten eine praktikable Alternative zum lokalen Fine-Tuning, insbesondere für große Modelle wie LLaMA 3.3 70B. Sie bieten:
- Skalierbare GPU-Ressourcen basierend auf der Arbeitslast
- Zugang zu leistungsstarken GPUs wie NVIDIA A100 oder V100
- Kostengünstige Pay-as-you-go-Preismodelle
- Vereinfachte Bereitstellungs-Workflows
- Die Möglichkeit, lokale Hardwarebeschränkungen zu umgehen
Novita AI GPU-Instanzdienste
Im Vergleich zu anderen GPU-Anbietern hat unser Preis den größten Vorteil. Hier ist eine Tabelle für Sie:
| Anbieter | Preis für rtx 4090 (1x GPU pro Stunde) |
|---|---|
| Novita AI | $0.35 |
| Vast AI | $0.316-$1.073 |
| CoreWeave | Kein Dienst |
Fazit
Das Fine-Tuning des LLaMA 3.2 90B Modells stellt erhebliche Herausforderungen dar, vor allem aufgrund seiner hohen VRAM-Anforderungen. Während Lösungen wie Quantisierung und Modell-Parallelität diese Herausforderungen mildern können, ist eine lokale Einrichtung für viele Benutzer möglicherweise immer noch unpraktisch. Cloudbasierte Lösungen bieten eine kostengünstige und zugängliche Alternative und stellen die notwendigen Ressourcen für das Fine-Tuning dieses leistungsstarken Modells bereit. Letztendlich hängt die Entscheidung, ob lokal oder in der Cloud feinabgestimmt wird, von den spezifischen Ressourcen und Anforderungen des Projekts ab. Forscher und Entwickler sollten ihre Bedürfnisse und verfügbaren Ressourcen sorgfältig abwägen, bevor sie mit dem Fine-Tuning-Prozess für das LLaMA 3.2 90B Modell beginnen.
Häufig gestellte Fragen
Kann Llama 3.2 auf dem Gerät verwendet werden? Wie?
Llama 3.2 ist für den Einsatz auf dem Gerät konzipiert, insbesondere mit den Modellen 1B und 3B, unter Verwendung von Open-Source-Bibliotheken wie Llama.cpp und Transformers.js, um auf verschiedenen Geräten ausgeführt zu werden, einschließlich CPUs, GPUs und Webbrowsern.
Was sind einige praktische Anwendungen von Llama 3.2 über die grundlegende Textgenerierung hinaus?
Llama 3.2 hat vielfältige Anwendungen, darunter mehrsprachige Wissensabfrage, Zusammenfassung, Bildunterschriftenerstellung und als KI-Assistenten in Bereichen wie Gesundheitswesen, Finanzen und Kundenservice.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, serverlose GPU-Instanz – die kostengünstigen Tools, die Sie brauchen. Infrastruktur eliminieren, kostenlos starten und Ihre KI-Vision Wirklichkeit werden lassen.
Empfohlene Lektüre
So wählen Sie die beste GPU für LLM-Inferenz aus: Benchmarking-Erkenntnisse
Warum die VRAM-Anforderungen von LLaMA 3.3 70B eine Herausforderung für Heimserver darstellen



