

主なポイント
LLaMA 3.2 90Bモデルのファインチューニングには少なくとも180 GBのVRAMが必要であり、ローカル環境では困難です。
メモリ制限により、LLaMA 3.2 90Bのファインチューニングは困難を伴う可能性があります。
LoRAやQLoRAなどのパラメータ効率的ファインチューニング(PEFT)手法は、これらの課題を軽減するのに役立ちます。
クラウドベースのソリューションは、高価なローカルハードウェアに代わる コスト効率の良い代替手段 を提供します。Novita AIのGPUインスタンスを利用できます。登録時にコンテナディスク60GB、ボリュームディスク1GBが無料で提供され、無料枠を超えた場合は追加料金が発生します。
LLaMA 3.2ファミリーの大規模言語モデルは、テキスト生成から画像理解まで、さまざまな機能を提供します。これらのモデルの中でも 90Bバリアント は、そのサイズとマルチモーダル機能で際立っています。しかし、このような大規模モデルをファインチューニングするには、多くのユーザーにとって課題となる大量のVRAM(ビデオRAM)が必要です。この記事では、LLaMA 3.2 90Bのファインチューニングに必要なVRAM要件を詳しく解説し、このタスクに取り組むための実用的なガイドを提供します。
LLaMA 3.2 90BファインチューニングのVRAM要件分析
LLaMA 3.2 90Bモデルは、900億のパラメータを持つ大規模モデルです。このサイズは、推論とファインチューニングの両方に必要なVRAM量に直接影響します。このモデルは主に大規模アプリケーション向けに設計されており、そのためVRAM要件が高くなっています。
デュアル3090構成か、Mac M1/M2 Ultra 64-128GB(128推奨)のどちらかが望ましいでしょう。3090は、ビジョン、トレーニング、画像生成(Stable Diffusion/Flux)を行いたい場合に必要です。Macは純粋な推論に適しており、128GBでより高い量子化、大規模モデルの処理が可能で、非常に静かで消費電力もほとんどありません。
Redditより
詳細なハードウェア要件

他のモデルとのVRAM要件比較

ファインチューニングに適したGPUの選び方
LLaMA 3.2 90Bモデルのファインチューニングには、適切なGPUの選択が重要です。モデルのVRAM要件を考えると、すべてのGPUが適しているわけではありません。
主な選択基準
ファインチューニング用のGPUを選択する際は、以下を考慮してください。
- VRAM容量 : 最も重要な要素で、モデルを完全にロードするには約180GBのVRAM が必要です。
- 計算能力: GPUが複雑な計算を実行する能力は、トレーニング速度に影響します。
- メモリ帯域幅: GPUがデータにアクセスして処理する速度は、パフォーマンスにとって重要です。
- コスト: ハイエンドGPUは非常に高価になる可能性があります。コスト効率とパフォーマンスのニーズのバランスを取る必要があります。
LLaMA 3.2 90BファインチューニングにおすすめのGPU
これらの基準に基づき、以下におすすめのGPUを挙げます。
- NVIDIA A100: このGPUは理想的な選択肢としてよく挙げられ、モデルに応じて40GB~80GBのVRAMを搭載しています。複数のA100を使用してVRAM要件を満たすことができます。
- NVIDIA RTX 3090: 24GBのVRAMでは単体では理想的ではありませんが、デュアル構成で使用可能です。ただし、より低い量子化やモデルの分割が必要になる場合があります。
- NVIDIA RTX 4090: RTX 3090と同様に、2枚のカードを使用すれば十分なVRAMを確保できますが、量子化や分割が必要になる場合があります。
- AMD MI60/MI100: これらは代替オプションで、十分なVRAMを提供できますが、特定のシステム構成が必要になる場合があります。
ファインチューニング実装ガイド
LLaMA 3.2 90Bのファインチューニングには、TransformersやAccelerateなどのライブラリを使用します。プロセスは、モデルのロード、データセットの準備、ハイパーパラメータの設定、トレーニング、ファインチューニング済みモデルの保存を含みます。LoRA(Low-Rank Adaptation)を使用すると、モデルのごく一部のみをファインチューニングすることでメモリ使用量を削減できます。
- 必要なライブラリを使用して適切な環境をセットアップします。
- LLaMA 3.2 90Bモデルとトークナイザをロードします。
- ファインチューニング用のデータセットを準備します。
- ファインチューニング中のメモリ使用量を削減するためにLoRAを構成します。
- バッチサイズ、学習率、エポック数を含むトレーニング引数を設定します。
- 教師ありファインチューニングトレーナーを使用してモデルをトレーニングおよび評価します。
- ファインチューニング済みモデルをローカルおよびHugging Faceなどのハブに保存します。
- ファインチューニング済みのLoRAアダプタをベースモデルとマージします。
https://www.youtube.com/watch?v=nUeIjs3THNM
技術的な課題と解決策
LLaMA 3.2 90Bモデルのファインチューニングには課題が伴います。
- 高いVRAM需要: 最大の課題は、多くのコンシューマグレードGPUの容量を超える膨大なVRAM要件です。
- 計算の複雑さ: このサイズのモデルのファインチューニングは計算集約的であり、強力なCPUとGPUが必要です。
- 処理の遅さ: ハードウェアが十分でない場合、処理が非常に遅くなり、多くのアプリケーションで実用的でなくなります。
- 量子化のトレードオフ: 量子化はVRAM使用量を削減しますが、ファインチューニング済みモデルの品質を低下させる可能性があります。
これらの課題を克服するために、さまざまな解決策を採用できます。
- 量子化: 4ビット量子化などの手法を使用すると、モデルのVRAMフットプリントを削減できます。ただし、モデルの精度に影響を与える可能性があります。
- モデル並列化: モデルを複数のGPUに分散することで、VRAMの制限を管理できます。
- システムRAMへのオフロード: 一部のシステムではモデルの一部をシステムRAMにオフロードできますが、パフォーマンスが大幅に低下します。
- LoRA(Low-Rank Adaptation): この手法はモデルのごく一部のみをファインチューニングするため、メモリ要件が削減されます。
代替ソリューション – クラウドGPU
ステップ1: GPUインスタンスをクリック
新規登録の方は、まずアカウントを登録してください。次に、Webページ上の[GPUインスタンス](https://novita.ai/gpus/?utm_source=blogs_gpu&utm_medium=article&utm_campaign= fine-tuning-llama-3-3-70b-with-rtx-4090)ボタンをクリックします。
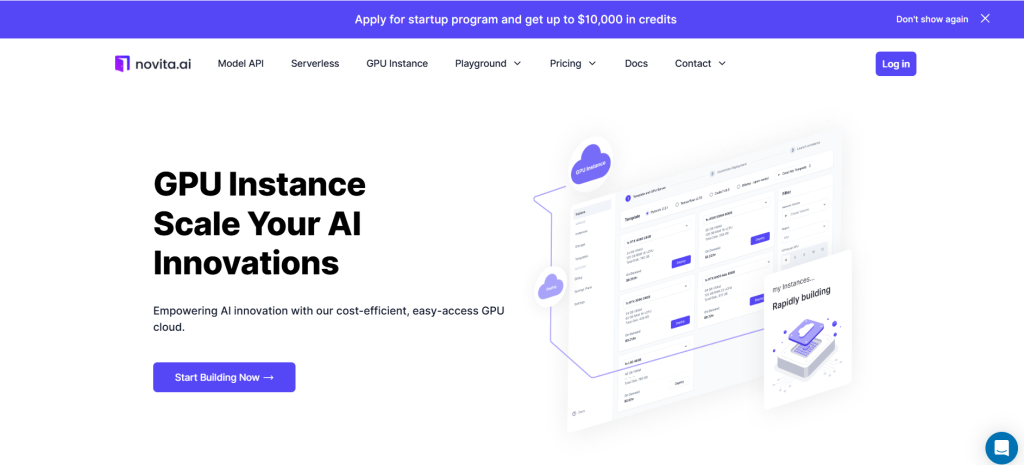
ステップ2: テンプレートとGPUサーバー
特定のニーズに応じて、Pytorch、Tensorflow、Cuda、Ollamaなどのテンプレートを選択できます。さらに、一番下のボタンをクリックして独自のテンプレートデータを作成することもできます。
次に、当サービスではNVIDIA RTX 4090などの高性能GPUへのアクセスを提供し、各GPUは十分なVRAMとRAMを備えており、最も要求の厳しいAIモデルでも効率的にトレーニングできます。ニーズに基づいて選択してください。
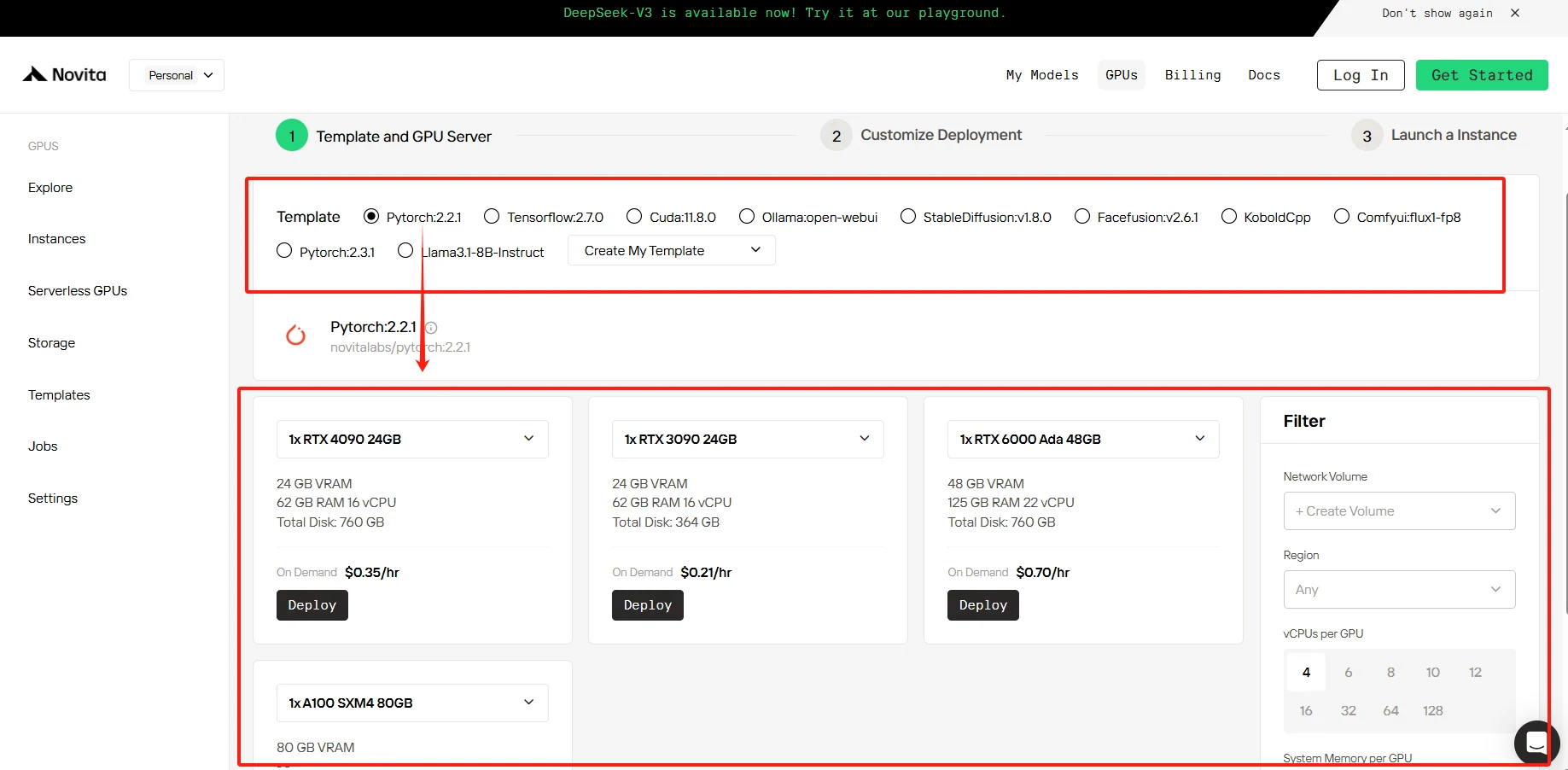
ステップ3: デプロイのカスタマイズ
このセクションでは、必要に応じてデータをカスタマイズできます。コンテナディスク60GB、ボリュームディスク1GBが無料で提供され、無料枠を超えた場合は追加料金が発生します。
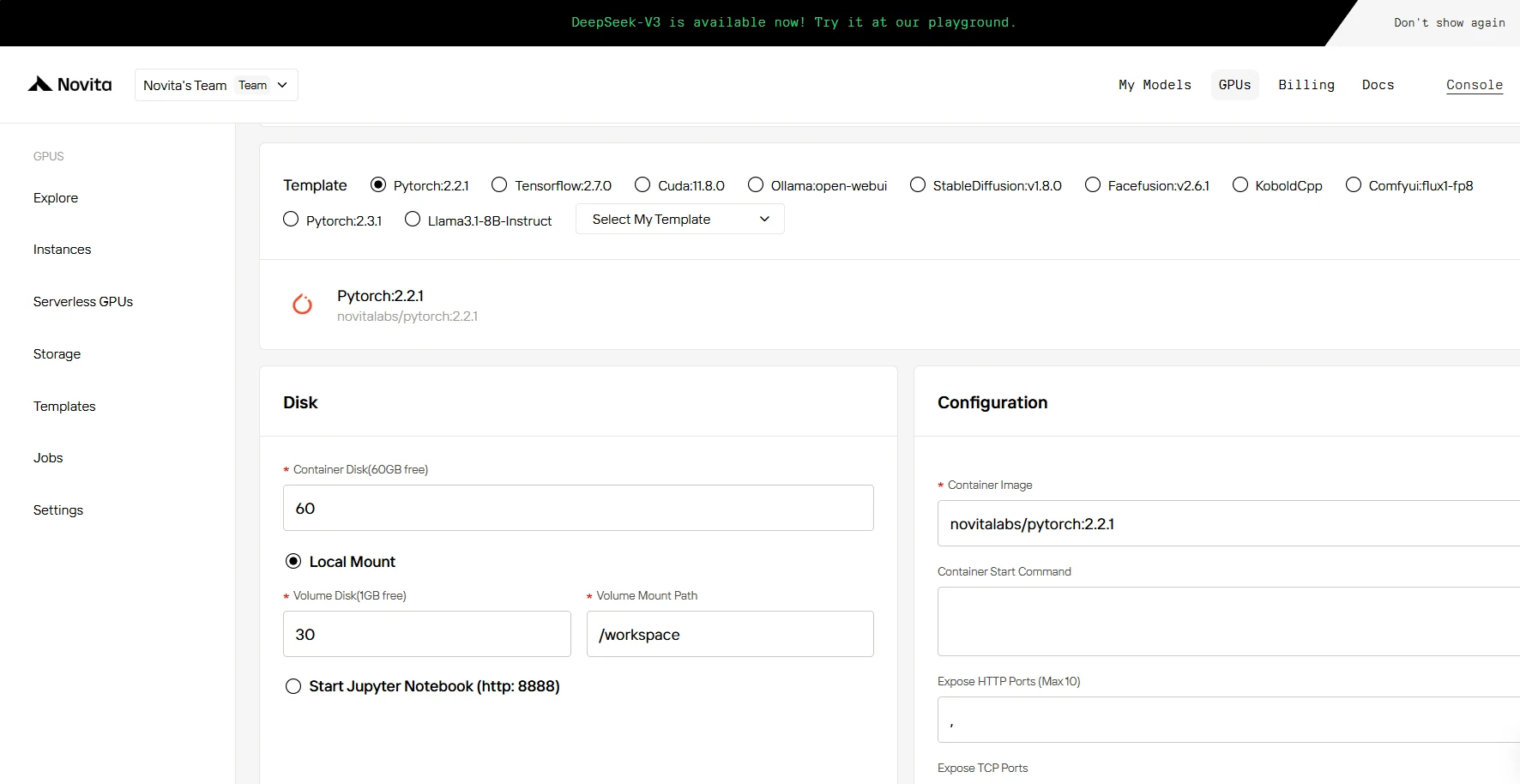
ステップ4: インスタンスを起動
AIアプリケーションの研究、開発、デプロイのいずれにおいても、CUDA 12を搭載したNovita AI GPUインスタンスは、クラウド上で強力かつ効率的なGPUコンピューティング体験を提供します。
クラウドGPUインスタンスを選ぶ理由
クラウドGPUインスタンスは、特にLLaMA 3.3 70Bのような大規模モデルの場合、ローカルファインチューニングに代わる有効な選択肢です。以下を提供します。
- ワークロードの需要に基づくスケーラブルなGPUリソース
- NVIDIA A100やV100などの高性能GPUへのアクセス
- コスト効率の良い従量課金モデル
- 簡素化されたデプロイワークフロー
- ローカルハードウェアの制限を回避する能力
Novita AI GPUインスタンスサービス
他のGPUプロバイダーと比較して、当社の価格には最大の利点 があります。以下の表をご覧ください。
| サービスプロバイダー | rtx 4090の価格(1x GPUあたり1時間) |
|---|---|
| Novita AI | $0.35 |
| Vast AI | $0.316-$1.073 |
| CoreWeave | サービスなし |
結論
LLaMA 3.2 90Bモデルのファインチューニングは、主に高いVRAM要件のために重大な課題をもたらします。量子化やモデル並列化などのソリューションはこれらの課題を軽減するのに役立ちますが、多くのユーザーにとってローカル設定は依然として非現実的かもしれません。クラウドベースのソリューションは、この強力なモデルをファインチューニングするために必要なリソースを提供し、コスト効率が高くアクセスしやすい代替手段を提供します。最終的に、ローカルでファインチューニングするかクラウドで行うかの決定は、プロジェクトの特定のリソースと要件に依存します。研究者や開発者は、LLaMA 3.2 90Bモデルのファインチューニングプロセスに着手する前に、自身のニーズと利用可能なリソースを慎重に検討する必要があります。
よくある質問
Llama 3.3 70Bのサイズ:Llama 3.2はデバイス上で使用できますか? その方法は?
Llama 3.2はデバイス上での使用を目的として設計されており、特に1Bおよび3Bモデルでは、Llama.cppやTransformers.jsなどのオープンソースライブラリを使用して、CPU、GPU、Webブラウザを含むさまざまなデバイスで実行できます。
基本的なテキスト生成以外に、Llama 3.2の実用的なアプリケーションにはどのようなものがありますか?
Llama 3.2には、多言語知識検索、要約、画像キャプション作成、ヘルスケア、金融、カスタマーサービスなどの分野でAIアシスタントとして機能するなど、多様なアプリケーションがあります。
Novita AIは、AIの野心を実現するオールインワンのクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス – 必要なコスト効率の高いツール。インフラストラクチャを排除し、無料で始めて、AIのビジョンを現実にしましょう。



