

Entdecken Sie, wie die Integration eines leistungsstarken Text-to-Speech-Tools die Benutzererfahrung Ihrer Anwendung verbessern, Conversions steigern und Barrierefreiheit für alle gewährleisten kann. Dieser umfassende Leitfaden bietet Entwicklern wichtige Einblicke und praktische Strategien, um die Vorteile der Text-to-Speech-Technologie zu nutzen.
Wichtige Highlights
- Text-to-Speech-KI nutzt hochentwickelte künstliche Intelligenz, um Text in natürlich klingendes, hochwertiges Audio umzuwandeln, was das Verständnis und die Interaktion verbessert.
- Mit einer Vielzahl von Sprachoptionen in verschiedenen Sprachen und Akzenten erfüllt TTS-KI unterschiedliche Benutzerpräferenzen und -bedürfnisse und bietet eine kostengünstige Alternative zu traditionellen Voiceover-Methoden, wodurch Anpassung und Zugänglichkeit für potenzielle Nutzer verbessert werden.
- Nutzen Sie fortschrittliche Text-to-Speech-Technologie (TTS), um geschriebene Inhalte in natürlich klingendes Audio umzuwandeln und so Barrierefreiheit und Benutzerfreundlichkeit zu verbessern.
- Integrieren Sie führende TTS-APIs wie die TTS-Angebote von Novita AI in Ihre Anwendung, um Benutzern Anpassungsoptionen für Stimme, Wiedergabegeschwindigkeit und Lautstärke zu bieten und so ein personalisiertes TTS-Erlebnis zu liefern.
Einführung
Text-to-Speech-KI hat in verschiedenen Bereichen, einschließlich des Verfassens von Aufsätzen, an Popularität gewonnen, da sie eine einzigartige Möglichkeit bietet, sich mit geschriebenen Inhalten auseinanderzusetzen. In diesem Blog werden wir die Welt der Text-to-Speech-KI und -API sowie ihre wichtigsten Funktionen, Vorteile und praktischen Anwendungen erkunden.
Verstehen der Text-to-Speech-Technologie
Text-to-Speech-Technologie nutzt die Kraft der künstlichen Intelligenz, um geschriebenen Text in Sprache umzuwandeln. Die KI-Algorithmen analysieren den Text, interpretieren seine Bedeutung und erzeugen eine gesprochene Ausgabe, die der menschlichen Sprache sehr nahe kommt. Diese Technologie bietet den Nutzern ein immersives und ansprechendes Hörerlebnis, das ihr Verständnis und ihre Erinnerung an den Inhalt verbessert.
Die Qualität der von Text-to-Speech-KI erzeugten Sprache hat sich im Laufe der Jahre erheblich verbessert, wobei viele Tools anpassbare Stimmen bieten, die natürlich und menschenähnlich klingen. Benutzer können aus einer Vielzahl von Stimmen wählen, einschließlich verschiedener Akzente und Sprachen, um ihren Vorlieben und Bedürfnissen gerecht zu werden.
Hauptmerkmale von Text-to-Speech
Anpassbare Stimmen und Sprachen
Eines der Hauptmerkmale von Text-to-Speech für Aufsätze ist die Möglichkeit, Stimmen und Sprachen anzupassen. Text-to-Speech-Tools bieten eine breite Palette von Stimmen, einschließlich verschiedener Akzente und Sprachen. Benutzer können die Stimme auswählen, die ihren Bedürfnissen und Vorlieben am besten entspricht, was das Leseerlebnis angenehmer und immersiver macht.
Zuverlässigkeit
Text-to-Speech nutzt fortschrittliche Sprachsynthesetechniken, die natürlich klingende Sprache erzeugen. Diese hochwertige Audioausgabe ist entscheidend, um das Interesse des Zuhörers aufrechtzuerhalten und sicherzustellen, dass die Informationen klar und effektiv vermittelt werden. Der natürliche Fluss und die Intonation der synthetisierten Sprache machen die Inhalte nachvollziehbarer und leichter verständlich, was jedes Mal eine hochwertige und konsistente Audioausgabe verspricht.
Kosteneffizienz
Text-to-Speech bietet eine wirtschaftliche Lösung für Voiceovers, die professionelle Ergebnisse liefert, ohne die hohen Kosten, die mit der Beauftragung von Synchronsprechern oder der eigenen Aufnahme verbunden sind. Diese Technologie ist eine zugängliche und budgetfreundliche Option für Unternehmen und Pädagogen, die ihre Inhalte mit Audio anreichern möchten.

Anwendungsfälle und Vorteile von Text-to-Speech
Durch die Integration von Text-to-Speech-Technologie in Ihre Anwendung können Sie eine Vielzahl von Vorteilen erschließen, die Ihre Benutzererfahrung verbessern und Conversions steigern.
Verbesserung der Barrierefreiheit für Benutzer mit Sehbehinderungen
TTS ermöglicht es Benutzern mit Sehbehinderungen oder Leseschwierigkeiten, auf Ihre Inhalte zuzugreifen, was Ihre Anwendung inklusiver und konform mit Barrierefreiheitsstandards macht. Dadurch werden Ihre digitalen Erlebnisse einem breiteren Publikum zugänglich, unabhängig von ihren Fähigkeiten.
Verbesserung des Leseerlebnisses für Benutzer
Durch das Angebot von TTS-Funktionalität können Benutzer Inhalte in ihrem bevorzugten Format konsumieren, sei es durch Lesen oder Hören. Dies kommt individuellen Vorlieben und Bedürfnissen entgegen und führt zu einem ansprechenderen und personalisierten Benutzererlebnis.

Steigerung von Engagement und Conversions
Indem Sie Benutzern die Option bieten, Inhalte zu hören, können Sie das Engagement steigern und möglicherweise Conversions erhöhen, da Benutzer eher mit Ihrer Anwendung interagieren, wenn sie Informationen in ihrer bevorzugten Modalität konsumieren können.
Unterstützung von mobilen und freihändigen Interaktionen
TTS ermöglicht es Benutzern, unterwegs, freihändig und in Situationen, in denen das Lesen unpraktisch ist (z. B. beim Autofahren oder Trainieren), auf Ihre Inhalte zuzugreifen. Dies erweitert die Reichweite und Nutzbarkeit Ihrer Anwendung und macht sie für Benutzer in verschiedenen Kontexten zugänglicher.
Durch die Nutzung von Text-to-Speech-Technologie können Sie eine Welt voller Möglichkeiten für Ihre Anwendung erschließen, die Barrierefreiheit verbessern und ein außergewöhnliches Benutzererlebnis bieten, das Sie von der Konkurrenz abhebt.
Integration von Text-to-Speech in Ihre Anwendung
Die Implementierung von TTS-Funktionalität in Ihre Anwendung ist ein unkomplizierter Prozess, dank der Verfügbarkeit verschiedener APIs. Beliebte Optionen wie Novita AI bieten eine Reihe von Funktionen und Anpassungsoptionen sowie APIs, die die Leistungsfähigkeit Ihrer Anwendung oder Plattform verbessern können.
Bei der Integration von TTS sollten Sie Faktoren wie Audioqualität, Sprachunterstützung und Integrationskomplexität berücksichtigen, um eine nahtlose und qualitativ hochwertige Benutzererfahrung zu gewährleisten. Erkunden Sie außerdem Möglichkeiten, das TTS-Erlebnis zu personalisieren, z. B. indem Sie Benutzern erlauben, ihre bevorzugte Stimme auszuwählen und die Wiedergabegeschwindigkeit anzupassen.

Wie erstelle ich Ihre erste Text-to-Speech-Demo?
Das Erstellen von Voiceovers mit KI-Tools wie Novita AI ist ein einfacher Prozess. Folgen Sie diesen Schritten:
- Schritt 1: Gehen Sie zur Novita AI-Website und erstellen Sie ein Konto. Navigieren Sie zu „Text-to-Speech“ unter dem Reiter „Produkt“. Sie können den Effekt zuerst mit den folgenden Schritten testen.
- Schritt 2: Geben Sie den Text ein, zu dem Sie ein Voiceover wünschen.
- Schritt 3: Wählen Sie ein Sprachmodell aus, das Sie interessiert.
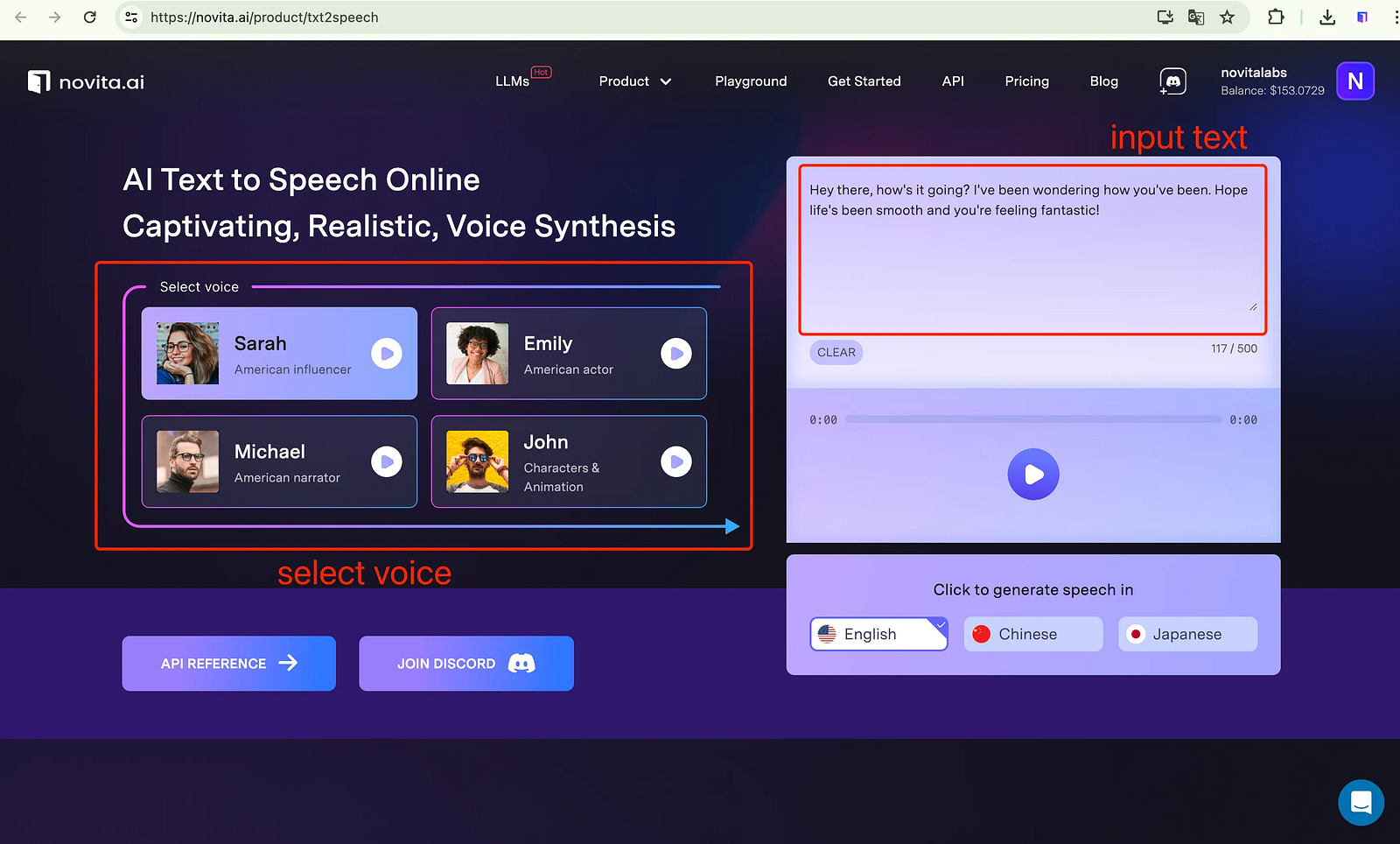
- Schritt 4: Klicken Sie auf die Schaltfläche „Generieren“ und warten Sie.
- Schritt 5: Sobald der Vorgang abgeschlossen ist, können Sie eine Vorschau anhören. Wenn es Ihren Anforderungen entspricht, können Sie die Ausgabe herunterladen und anwenden.
Wie erstelle ich ein Text-to-Speech-Tool mit APIs in Novita AI?
Um ein kommerzielles TTS-Tool zu erstellen, recherchieren Sie vorhandene Tools, definieren Sie Ihre Zielgruppe und Funktionen, entwerfen Sie eine intuitive Benutzeroberfläche, stellen Sie eine hohe Audioqualität sicher und testen Sie gründlich. Berücksichtigen Sie Skalierbarkeit und Benutzerfeedback für kontinuierliche Verbesserungen.
Sie können die Text-to-Speech-API verwenden, um ein solches Tool schnell zu erstellen. Die Verwendung der Novita AI Text-to-Speech-API bietet schnelle, ausdrucksstarke und zuverlässige Sprachsynthese. Mit einer Echtzeitlatenz von unter 300 ms, verschiedenen Sprachstilen und nahtloser Integration sorgt sie für hochwertiges, anpassbares Audio für verbesserte Podcast-Benutzererlebnisse.
Als nächstes führen wir Sie durch einfache Schritte, um Ihnen das Verständnis zu erleichtern.
- Schritt 1. Anforderungen verstehen: Definieren Sie klar die Ziele des Projekts, die Zielgruppe und die benötigten Funktionen.
- Schritt 2. API integrieren: Integrieren Sie die Novita AI Text-to-Speech-API in Ihr Backend-System für die Sprachsynthese.
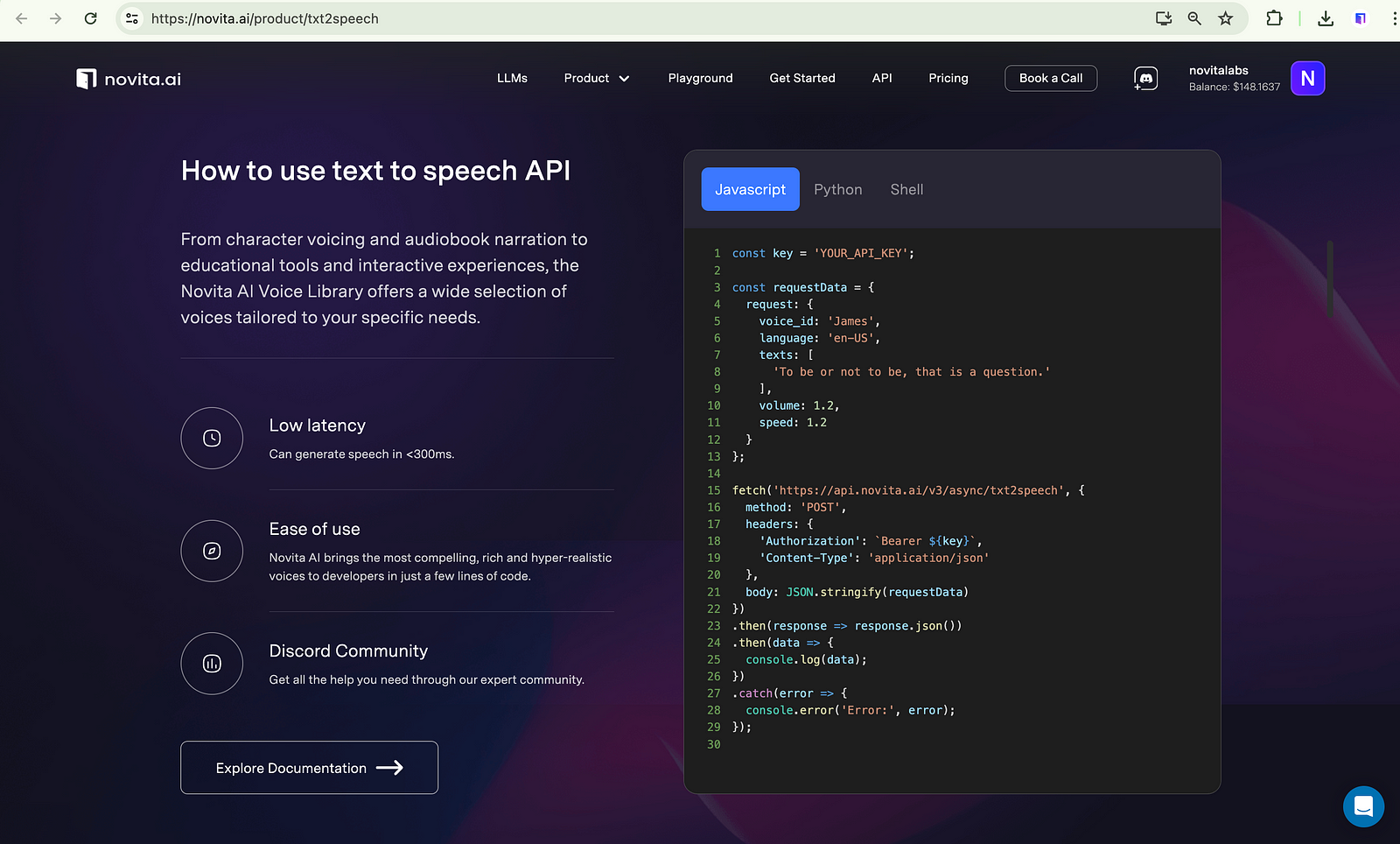
- Schritt 3. Benutzeroberfläche entwickeln: Erstellen Sie eine benutzerfreundliche Oberfläche zur Texteingabe und Anpassung der Spracheinstellungen.
- Schritt 4. Authentifizierung implementieren: Stellen Sie sichere Mechanismen zur Benutzerauthentifizierung und -berechtigung sicher.
- Schritt 5. Testen und bereitstellen: Testen Sie das Tool gründlich, stellen Sie es in einer Produktionsumgebung bereit und überwachen Sie seine Leistung zur kontinuierlichen Verbesserung.
Best Practices und Strategien für Entwickler
Um ein nahtloses und optimiertes Text-to-Speech-Erlebnis zu gewährleisten, beachten Sie die folgenden Best Practices:
- Anpassungsoptionen anbieten: Ermöglichen Sie Benutzern, ihr TTS-Erlebnis zu personalisieren, indem Sie Optionen zur Auswahl der Stimme, Anpassung der Wiedergabegeschwindigkeit und Regelung der Lautstärke bereitstellen. Diese Anpassung kann die Benutzerzufriedenheit erheblich steigern.
- Für Leistung optimieren: Überwachen Sie die Leistung der TTS-Integration und optimieren Sie sie bei Bedarf, um eine reibungslose Wiedergabe und minimale Latenz zu gewährleisten, insbesondere bei Echtzeitanwendungen.
- Benutzerfeedback einholen: Sammeln Sie kontinuierlich Feedback von Ihren Benutzern und iterieren Sie die TTS-Integration basierend auf ihren Vorlieben und Vorschlägen. Dies hilft Ihnen, das Erlebnis zu verfeinern und Ihre Anwendung relevant zu halten.
- Plattformübergreifende Fähigkeiten nutzen: Nutzen Sie die plattformübergreifende Natur von TTS-APIs, um ein konsistentes Erlebnis auf verschiedenen Geräten und Betriebssystemen zu bieten und so die Zugänglichkeit für alle Ihre Benutzer sicherzustellen.
Fazit
Text-to-Speech-KI ist mehr als nur eine unterstützende Technologie – sie ist ein Katalysator für Innovation in Bildungs- und Berufsfeldern. Indem sie Informationen zugänglich und ansprechend macht, demokratisiert sie das Lernen und befähigt Kreative. Während wir weiter in das digitale Zeitalter vordringen, ist die Integration solcher KI-Tools keine Luxus mehr, sondern eine Notwendigkeit, um sicherzustellen, dass wir alle mit der sich schnell entwickelnden Welt des Wissens und der Kommunikation Schritt halten können.
Häufig gestellte Fragen
Was ist Text-to-Speech-Technologie (TTS) und wie funktioniert sie?
Text-to-Speech-Technologie verwendet KI-Algorithmen, um geschriebenen Text in gesprochene Worte umzuwandeln und bietet ein Hörerlebnis, das der menschlichen Sprache sehr nahe kommt.
Wie kann ich das Text-to-Speech-Erlebnis für meine Benutzer anpassen?
Die Anpassung kann Optionen für verschiedene Stimmtypen, Akzente, Wiedergabegeschwindigkeiten und Lautstärkeregelungen umfassen und so ein personalisiertes Erlebnis gewährleisten.
Was ist der beste kostenlose KI-Stimmengenerator?
Die beste kostenlose KI-Stimmengenerator-Option variiert je nach Ihren genauen Anforderungen. Novita könnte eine gute Lösung für Entwickler sein, die API-Zugriff und Interoperabilität mit anderen Ressourcen benötigen.
Welche Optimierungsstrategien sollte ich bei der Integration von TTS berücksichtigen?
Zu den Best Practices gehören das Anbieten umfangreicher Anpassungsoptionen, die Optimierung der Leistung, die Nutzung plattformübergreifender Fähigkeiten und das Einholen von Benutzerfeedback für fortlaufende Verbesserungen.
Novita AI – die Komplettlösung für grenzenlose Kreativität, die Ihnen Zugang zu über 100 APIs bietet. Von Bildgenerierung und Sprachverarbeitung bis hin zu Audioverbesserung und Videobearbeitung – günstig nach Pay-as-you-go-Modell, befreit Sie von der Wartung von GPUs, während Sie Ihre eigenen Produkte entwickeln. Testen Sie es kostenlos.
Empfohlene Lektüre



