

- Die abgestufte Modellstrategie
- Warum Prompt Caching für OpenClaw wichtig ist
- Stufe 1: Premium-Modelle – Wenn es richtig sein muss
- Stufe 2: Alltagsbegleiter – Die meisten Aufgaben, bester Wert
- Stufe 3: Budget-Modelle – Einfache Aufgaben, minimale Kosten
- Betreiben Sie Ihren Modell-Stack auf Novita AI
- NovitaClaw: OpenClaw mit einem Befehl bereitstellen
- Ein Hinweis zu OpenRouter-Nutzungsdaten
- Fazit
OpenClaw hat sich schnell zu einem der beliebtesten KI-Agent-Frameworks entwickelt – es automatisiert Aufgaben, verwaltet Workflows und bleibt rund um die Uhr online. Aber sobald es läuft, stellt sich unweigerlich die Frage: Welches Modell soll ich eigentlich verwenden?
Es gibt keine einzige richtige Antwort. Der cleverste Ansatz ist eine abgestufte Strategie: Premium-Modelle für kritische Aufgaben, leistungsfähige Mittelklasse-Modelle als tägliche Begleiter und günstige Modelle für die routinemäßige Massenabarbeitung. Dieser Leitfaden schlüsselt spezifische Modellempfehlungen für jede Stufe auf – mit Preisen, Kontextfenstern und den Stärken jedes Modells.
Die abgestufte Modellstrategie
Ein einziges Modell für alles auszuwählen, ist wie einen Vorschlaghammer zu benutzen, um ein Bild aufzuhängen. Komplexe Denkaufgaben erfordern Intelligenz auf Spitzenniveau, aber eine einfache Dateiorganisation nicht – und ein Premium-Modell für jede Anfrage zu verwenden, wird schnell Ihr Budget sprengen.
Die effektivsten OpenClaw-Setups nutzen drei Stufen:
- Stufe 1 (Premium): Die Schwergewichte für kritische Aufgaben – komplexes Denken, Code-Review, Entscheidungen mit hohem Risiko
- Stufe 2 (Alltagsbegleiter): Deckt die meiste reale Arbeit ab – Codegenerierung, Texterstellung, mehrschrittige Agent-Workflows
- Stufe 3 (Budget): Erledigt einfache Aufgaben zu minimalen Kosten – Dateiorganisation, einfache Fragen & Antworten, Routineautomatisierung
Hier ist unsere Empfehlung für jede Stufe.
Warum Prompt Caching für OpenClaw wichtig ist
OpenClaw-Agenten pflegen lange System-Prompts, persistente Speicherdateien und umfangreiche Konversationsverläufe – oft werden bei jeder Anfrage zehntausende von Tokens gesendet. Ohne Caching zahlen Sie jedes Mal den vollen Eingabepreis für diese wiederholten Tokens.
Prompt Caching löst dieses Problem. Wenn ein Modell dies unterstützt, speichert der Anbieter zuvor gesehene Eingabe-Präfixe und liefert sie bei nachfolgenden Anfragen zu einem stark reduzierten Preis. Für einen ständig laufenden OpenClaw-Agenten sind die Einsparungen erheblich:
- System-Prompts und Skill-Dateien – werden bei jedem Durchlauf geladen, nach der ersten Anfrage automatisch zwischengespeichert
- Konversationsverlauf – nur die neuesten Nachrichten verursachen volle Eingabekosten; alles vor der Cache-Grenze wird rabattiert
- Speicher- und Kontextdateien – MEMORY.md, RULES.md und andere Workspace-Dateien, die sich zwischen Durchläufen selten ändern
Auf Novita AI unterstützen die meisten empfohlenen Modelle Prompt Caching mit einer 50–90%igen Kostenreduktion für den Eingabeteil bei gecachten Tokens. Die Cache-Preise für jedes Modell sind unten zusammen mit den Standardpreisen aufgeführt.
Stufe 1: Premium-Modelle – Wenn es richtig sein muss
Manche Aufgaben erfordern die stärkste verfügbare Denkfähigkeit. Wenn Genauigkeit nicht verhandelbar ist oder ein einzelner Fehler teuer wird, sind dies die Modelle, die Sie verwenden sollten.
Claude Sonnet 4.6 & Claude Opus 4.6
Anthropics Claude-Modelle gelten weithin als der Goldstandard für komplexes Denken und nuancierte Befehlsausführung. Sonnet bietet eine gute Balance aus Geschwindigkeit und Intelligenz für die meisten fortgeschrittenen Aufgaben, während Opus die ultimative Option für Arbeiten ist, bei denen es auf Präzision ankommt.
GPT-5.4
OpenAIs leistungsfähigstes Modell für professionelle Arbeit. GPT-5.4 ist ein Flaggschiff-Denkmodus mit Standardverarbeitung für Kontextlängen unter 270K Tokens. Es zeichnet sich durch komplexes mehrschrittiges Denken, Codegenerierung und Aufgaben aus, die tiefes analytisches Denken erfordern – was es zu einer natürlichen Wahl für risikoreiche Agent-Workflows macht, bei denen Präzision den Premiumpreis rechtfertigt.
Gemini 3 Flash Preview
Googles Gemini 3 Flash bietet Fähigkeiten auf Spitzenniveau mit schnellen Antwortzeiten, was es zu einer soliden Wahl macht, wenn Sie sowohl Geschwindigkeit als auch Tiefe für anspruchsvolle Aufgaben benötigen.
💡Wann Stufe 1 verwenden:
- Komplexes codeübergreifendes Refactoring
- Risikoanalysen bei Entscheidungen
- Aufgaben, bei denen ein einzelner Fehler teuer ist
- Überprüfung und Validierung kritischer Ausgaben
⚖️Der Trade-off: Diese Modelle liefern außergewöhnliche Qualität, aber zu einem Premiumpreis. Für einen ständig laufenden OpenClaw-Agenten, der täglich hunderte von Anfragen verarbeitet, wird die Verwendung von Stufe 1 für jede Aufgabe schnell teuer. Hier kommen die nächsten beiden Stufen ins Spiel – sie decken die überwiegende Mehrheit der Arbeitslast Ihres Agenten zu einem Bruchteil der Kosten ab.
Stufe 2: Alltagsbegleiter – Die meisten Aufgaben, bester Wert
Hier verbringt Ihr Agent den Großteil seiner Denkzeit. Diese Modelle balancieren Kosten und Fähigkeiten für die Arbeit, die wirklich zählt – und sie sind gut genug, sodass Sie selten auf Stufe 1 zurückgreifen müssen.
Kimi K2.5
Moonshot AIs Kimi K2.5 hat sich zu einer herausragenden Wahl für agentische Arbeitslasten entwickelt. Basierend auf einer MoE-Architektur (Mixture-of-Experts) ist es speziell für die Werkzeugnutzung, mehrschrittige Planung und Codegenerierung optimiert – genau die Fähigkeiten, auf die OpenClaw-Agenten am meisten angewiesen sind.
Was K2.5 auszeichnet, ist seine agentische Leistung. Es gehört zu den Top-Modellen in Coding-Benchmarks und seine Genauigkeit bei Tool-Aufrufen kann mit wesentlich teureren Modellen mithalten. Das 262K-Kontextfenster ist großzügig genug für komplexe Workflows mit mehreren Dokumenten oder langen Konversationsverläufen.
- Kontextfenster: 262K Tokens
- Preise: 0,60 $/M Eingabe · 3,00 $/M Ausgabe · 0,10 $/M gecachte Eingabe
- Stärken: Hervorragende agentische Fähigkeit für den Preis, exzellente Codegenerierung und Werkzeugnutzung, starkes mehrschrittiges Denken.
- Am besten geeignet für: Der Allrounder für den täglichen Gebrauch – Code schreiben, mehrschrittige Agent-Workflows, Rechercheaufgaben und alles, was Tool-Aufrufe erfordert.
Kimi K2.5 im Novita Playground testen
GLM-5
Z.AIs Flaggschiff-Modell stellt einen bedeutenden Fortschritt gegenüber der GLM-4-Serie dar. GLM-5 konkurriert mit Spitzenmodellen bei Denk- und Code-Aufgaben und behält gleichzeitig wettbewerbsfähige Preise. Es bietet verbesserte Fähigkeiten im mathematischen Denken, bei der Codegenerierung und bei strukturierten Ausgaben – was es besonders geeignet für Agent-Workflows macht, die zuverlässige Tool-Nutzung erfordern.
- Kontextfenster: 202K Tokens
- Preise: 1,00 $/M Eingabe · 3,20 $/M Ausgabe · 0,20 $/M gecachte Eingabe
- Stärken: Starkes Denken, sehr effektiv bei strukturierten Ausgaben und Funktionsaufrufen, wettbewerbsfähige Benchmark-Leistung im Vergleich zu Modellen zum 2-3-fachen Preis.
- Am besten geeignet für: Komplexe Agent-Aufgaben – Code-Analyse, mehrschrittige Problemlösung, Berichterstellung und Workflows mit starker Tool-Nutzung.
GLM-5 im Novita Playground testen
Qwen3.5-397B-A17B
Das größte Modell in Alibabas Qwen 3.5 Serie, basierend auf einer MoE-Architektur, die pro Durchlauf nur einen Bruchteil der Gesamtparameter aktiviert. Das bedeutet, Sie erhalten die Intelligenz eines großen Modells zu einem Bruchteil der erwarteten Kosten. Mit einem 262K-Kontextfenster bewältigt es verlängerte Agent-Sitzungen und Multi-Dokument-Workflows ohne Kontextverschlechterung.
- Kontextfenster: 262K Tokens
- Preise: 0,60 $/M Eingabe · 3,60 $/M Ausgabe
- Stärken: Beinahe-Spitzenleistung beim Denken und Codieren, exzellente Handhabung langer Kontexte, effiziente MoE-Inferenz.
- Am besten geeignet für: Aufgaben, die maximale Leistung zu mittleren Preisen benötigen – komplexe Codegenerierung, analytisches Denken und Forschung mit langen Kontexten.
Qwen3.5-397B-A17B im Novita Playground testen
💡Wofür Stufe 2 gut ist:
- Codegenerierung und Fehlerbehebung
- Inhaltserstellung und -bearbeitung
- Mehrschrittige Agent-Workflows
- Recherche- und Analyseaufgaben
- Werkzeugnutzung und Funktionsaufrufe
Stufe 3: Budget-Modelle – Einfache Aufgaben, minimale Kosten
Diese Modelle erledigen Aufgaben mit hohem Volumen und geringer Komplexität. Sie sind für einfache Aufgaben überraschend leistungsfähig und halten Ihre Token-Kosten unter Kontrolle.
DeepSeek V3.2
DeepSeek’s neuestes Allgemeinmodell, basierend auf einer MoE-Architektur, die starke Leistung bei Code, Mathematik und allgemeinem Denken zu günstigsten Preisen liefert. Sein effizientes Design bedeutet, dass Sie qualitativ hochwertige Ausgaben ohne Premiumkosten erhalten.
- Kontextfenster: 163K Tokens
- Preise: 0,269 $/M Eingabe · 0,40 $/M Ausgabe · 0,13 $/M gecachte Eingabe
- Stärken: Exzellentes Preis-Leistungs-Verhältnis, solide Code-Fähigkeiten, schnelle Inferenzgeschwindigkeit.
- Am besten geeignet für: Routinemäßige Agent-Aufgaben, Datenextraktion, Textformatierung und allgemeine Fragen & Antworten.
DeepSeek V3.2 im Novita Playground testen
GLM-4.7 Flash
Das geschwindigkeitsoptimierte Modell von Zhipu AI, entwickelt für Hochdurchsatz-Szenarien, in denen die Antwortlatenz wichtiger ist als die Spitzendenktiefe. Es unterstützt sowohl Chinesisch als auch Englisch gut, was es zu einer starken Wahl für mehrsprachige Agent-Setups macht.
- Kontextfenster: 200K Tokens
- Preise: 0,07 $/M Eingabe · 0,40 $/M Ausgabe · 0,01 $/M gecachte Eingabe
- Stärken: Eines der günstigsten Modelle mit einem 200K-Kontextfenster. Sehr schnelle Antwortzeiten. Stark bei strukturierten Ausgaben und Befehlsausführung.
- Am besten geeignet für: Aufgaben mit hohem Volumen und geringer Komplexität – Zusammenfassung, Klassifizierung, Datenformatierung und Benachrichtigungs-Workflows.
GLM-4.7 Flash im Novita Playground testen
MiniMax M2.5
MiniMax’ M2.5 ist ein fähiger Allrounder, der über seinem Preisniveau agiert. Es verarbeitet Dokumentenanalyse und längere Unterhaltungen gut, mit einem langen Kontextfenster, das mehrschrittige Workflows ohne Verschlechterung unterstützt.
- Kontextfenster: 204K Tokens
- Preise: 0,30 $/M Eingabe · 1,20 $/M Ausgabe · 0,03 $/M gecachte Eingabe
- Stärken: Zuverlässige Leistung bei langen Kontexten, gut darin, komplexe Anweisungen zu befolgen, starke mehrsprachige Unterstützung.
- Am besten geeignet für: Aufgaben, die etwas mehr Leistung benötigen als die günstigsten Modelle – Dokumentenzusammenfassung, mehrschrittige Unterhaltungen und Inhaltsentwürfe.
MiniMax M2.5 im Novita Playground testen
💡Wofür Stufe 3 gut ist:
- Dateiverwaltung und -organisation
- Einfache Fragen & Antworten
- Datenformatierung und -extraktion
- Routinemäßige Benachrichtigungen und Zusammenfassungen
Betreiben Sie Ihren Modell-Stack auf Novita AI
Alle oben empfohlenen Modelle der Stufen 2 und 3 – Kimi K2.5, GLM-5, Qwen3.5-397B-A17B, DeepSeek V3.2, GLM-4.7 Flash und MiniMax M2.5 – sind auf Novita AI über einen einzigen API-Schlüssel verfügbar.
Warum das für OpenClaw-Benutzer wichtig ist:
- OpenAI/Anthropic-kompatibles API-Format – direkt in die Modellkonfiguration von OpenClaw einsteckbar, ohne benutzerdefinierte Adapter
- Ein API-Schlüssel, mehrere Modelle – Wechsel zwischen den Stufen ohne separate Konten verwalten zu müssen
- Prompt Caching bei den meisten Modellen – reduziert erheblich die Eingabekosten und beschleunigt Antworten bei langen Kontext-Agent-Sitzungen
- Pay-per-Token – keine Abonnements oder Mindestverpflichtungen
Sie können diese Modelle auch interaktiv auf dem Novita AI Playground testen – einer webbasierten Umgebung, um mit Prompts zu experimentieren, Parameter visuell zu erkunden und sofortiges Feedback zu erhalten, bevor Sie sie in OpenClaw einsetzen.
Eine Schritt-für-Schritt-Anleitung zur Integration von Modellen wie Kimi K2.5 in Ihre OpenClaw-Agenten – inklusive Telegram-Bot-Einrichtung und erweiterter Konfiguration – finden Sie in unserem detaillierten Tutorial: Kimi K2.5 in OpenClaw (Clawdbot) verwenden: Schnelleinrichtung für Telegram-Agenten mit Novita.
Das detaillierte Tutorial lesen
NovitaClaw: OpenClaw mit einem Befehl bereitstellen
Möchten Sie Ihren OpenClaw-Agenten rund um die Uhr in der Cloud laufen lassen, ohne sich um Infrastruktur zu kümmern? NovitaClaw bringt Sie mit einem Befehl ans Ziel.
NovitaClaw ist ein Bereitstellungstool, das auf Novita Agent Sandbox basiert und eine vollständig konfigurierte OpenClaw-Instanz von Ihrem Terminal aus bereitstellt. Drei Schritte, jede Plattform:
Schritt 1: NovitaClaw installieren
sudo pip3 install novitaclaw
Schritt 2: API-Schlüssel setzen
export NOVITA_API_KEY=sk_your_api_key
Schritt 3: Starten
novitaclaw launch
Schritt 1: NovitaClaw installieren
pip install novitaclaw
Schritt 2: API-Schlüssel setzen
$env:NOVITA_API_KEY = "sk_your_api_key"
Schritt 3: Starten
novitaclaw launch
Das war’s. In weniger als einer Minute erhalten Sie:
- Einen 24/7 OpenClaw-Agenten – keine Sitzungsbeschränkungen, keine manuellen Neustarts. Ihr Agent bleibt so lange online, wie Sie ihn brauchen.
- Vor konfiguriert mit Novita-Modellen – Ihr abgestufter Modell-Stack ist sofort einsatzbereit. Wechseln Sie jederzeit über die Weboberfläche zwischen den Modellen.
- Multi-Channel-Unterstützung – Verbinden Sie Telegram, Discord und andere Messaging-Plattformen, damit Ihr Agent überall erreichbar ist.
- Automatische Wiederherstellung – Falls der Agent abstürzt, startet er automatisch neu und stellt die letzte funktionierende Konfiguration wieder her. Kein Datenverlust, kein manuelles Eingreifen.
- Integrierter Web-Terminal und Dateimanager – Greifen Sie direkt vom Browser aus auf die Umgebung Ihres Agenten zu, zum Debuggen und zur Dateiverwaltung.
Die zugrunde liegende Sandbox läuft auf 2 vCPU und 4 GB RAM – ausgelegt für echte Produktions-Workloads, nicht für Demos. Jedes Modell auf der Novita-Plattform wird unterstützt, und Sie können eigene API-Schlüssel von Drittanbietern für Modelle wie Claude oder Gemini mitbringen, falls Sie Zugriff auf Stufe 1 benötigen.
👉 Die vollständige Einrichtungsanleitung – einschließlich Modellkonfiguration, Telegram-Bot-Integration und erweiterten Optionen – finden Sie unter NovitaClaw: OpenClaw mit einem Befehl in der Cloud ausführen.
Die vollständige NovitaClaw-Einrichtungsanleitung lesen
Ein Hinweis zu OpenRouter-Nutzungsdaten
Für diejenigen, die neugierig sind, was die breitere Community verwendet: OpenClaw ist derzeit die App mit der höchsten täglichen Nutzung auf OpenRouter und verarbeitete bis März 2026 12,6 Billionen Tokens über 348 Modelle.
Die Top-Modelle nach Token-Volumen sind Step 3.5 Flash (2,2T), MiniMax M2.5 (1,3T), Kimi K2.5 (962B), Claude Sonnet 4.6 (805B) und GLM 5 Turbo (579B). Es ist erwähnenswert, dass einige Modelle an der Spitze aufgrund von Werbeaktionen oder kostenlosen Stufen eine erhöhte Nutzung aufweisen können, daher spiegelt das rohe Token-Volumen nicht immer direkt die Modellqualität wider. Die in diesem Artikel empfohlene abgestufte Strategie basiert auf einer Kombination aus Nutzungsmustern, Modellfähigkeiten und Community-Feedback aus der Praxis.
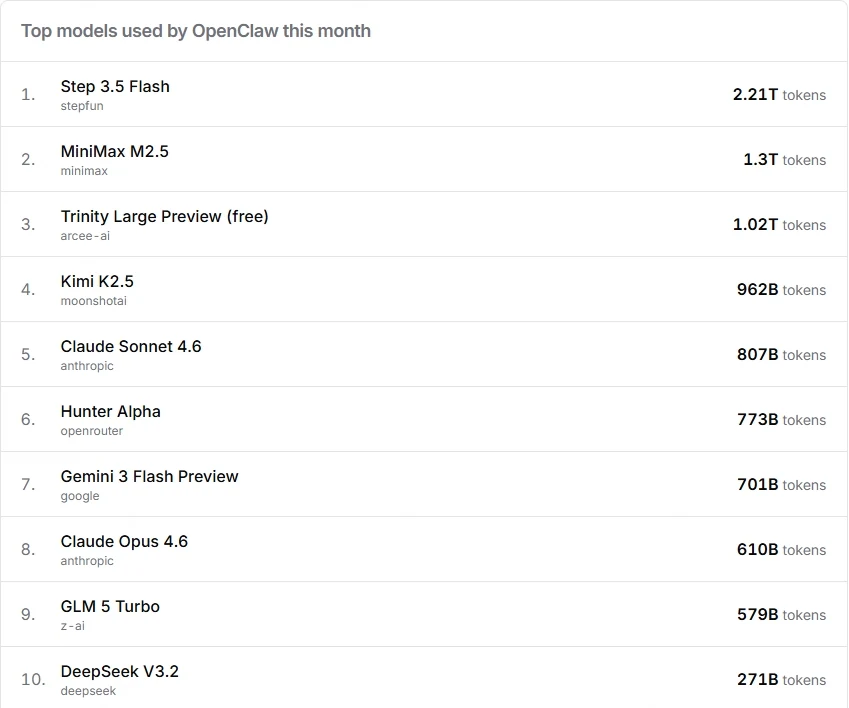
Von OpenRouter
Fazit
Die effektivsten OpenClaw-Setups verlassen sich nicht auf ein einzelnes Modell – sie staffeln drei Stufen. Premium-Modelle wie Claude übernehmen die Momente, die höchste Genauigkeit erfordern. Alltagsbegleiter wie Kimi K2.5 und GLM-5 erledigen das eigentliche Denken zu angemessenen Kosten. Und Budget-Modelle wie DeepSeek V3.2 und GLM-4.7 Flash absorbieren die routinemäßige Massenarbeit.
Mit Novita AI können Sie auf alle Empfehlungen der Stufen 2 und 3 über eine einzige API zugreifen. Und mit NovitaClaw können Sie den gesamten Stack mit einem Befehl bereitstellen – keine Infrastruktur erforderlich.
Novita AI ist eine Cloud-Plattform für KI und Agenten, die Entwicklern und Startups hilft, Modelle und agentische Anwendungen mit hoher Leistung, Zuverlässigkeit und Kosteneffizienz zu erstellen, bereitzustellen und zu skalieren.
Häufig gestellte Fragen
Was ist das beste Modell für OpenClaw?
Es gibt nicht das eine beste Modell – es hängt von Ihrem Anwendungsfall ab. Für die meisten Benutzer funktioniert ein abgestufter Ansatz am besten: ein Alltagsbegleiter wie Kimi K2.5 oder GLM-5 für allgemeine Aufgaben, mit Budget-Modellen wie DeepSeek V3.2 für einfache Arbeiten. Alle sind auf Novita AI über einen API-Schlüssel verfügbar.
Ist Novita AI mit OpenClaw kompatibel?
Ja. Novita AI bietet ein OpenAI/Anthropic-kompatibles API-Format, das bedeutet, es kann direkt in die Modellkonfiguration von OpenClaw eingebunden werden, ohne dass benutzerdefinierte Adapter erforderlich sind. Es bietet zudem keine Ratenbegrenzungen und Pay-per-Token-Preise – beides wichtig für ständig laufende Agenten.
Wie richte ich OpenClaw mit Novita AI ein?
Zwei Optionen. Wenn Sie OpenClaw bereits betreiben, konfigurieren Sie es einfach mit Ihrem Novita-API-Schlüssel – die API ist OpenAI/Anthropic-kompatibel, Sie müssen also nur die Basis-URL und den Modellnamen aktualisieren. Eine detaillierte Anleitung finden Sie in unserem Schritt-für-Schritt-Tutorial. Wenn Sie lieber von Grund auf neu beginnen möchten, stellt NovitaClaw eine vollständig konfigurierte Instanz mit einem Befehl bereit (novitaclaw launch) mit 24/7-Verfügbarkeit und automatischer Wiederherstellung. Details finden Sie in der NovitaClaw-Einrichtungsanleitung.



