

- A Estratégia de Modelos em Camadas
- Por que o Cache de Prompt é Importante para o OpenClaw
- Camada 1: Modelos de Potência — Quando Precisa Estar Correto
- Camada 2: Uso Diário — A Maioria das Tarefas, Melhor Custo-Benefício
- Camada 3: Modelos Econômicos — Tarefas Simples, Custo Mínimo
- Execute sua Pilha de Modelos no Novita AI
- NovitaClaw: Implante o OpenClaw em Um Comando
- Uma Nota sobre Dados de Uso do OpenRouter
- Conclusão
O OpenClaw rapidamente se tornou um dos frameworks de agentes de IA mais populares disponíveis — automatizando tarefas, gerenciando fluxos de trabalho e permanecendo online 24/7. Mas, depois de configurá-lo, a próxima pergunta é inevitável: qual modelo devo usar?
Não existe uma resposta única. A abordagem mais inteligente é uma estratégia em camadas: modelos premium para tarefas críticas, modelos intermediários capazes como uso diário e modelos baratos para lidar com trabalhos rotineiros em massa. Este guia apresenta recomendações específicas de modelos para cada camada — com preços, janelas de contexto e o que cada modelo faz de melhor.
A Estratégia de Modelos em Camadas
Escolher um modelo para tudo é como usar uma marreta para pendurar um quadro. Tarefas complexas de raciocínio exigem inteligência de fronteira, mas organização simples de arquivos não — e usar um modelo premium em cada solicitação queimará seu orçamento rapidamente.
As configurações mais eficazes do OpenClaw usam três camadas:
- Camada 1 (Potência): Os pesos pesados para tarefas críticas — raciocínio complexo, revisão de código, decisões de alto risco
- Camada 2 (Uso Diário): Cobrem a maior parte do trabalho real — geração de código, escrita de conteúdo, fluxos de trabalho de agente com várias etapas
- Camada 3 (Econômica): Lidam com tarefas simples a custo mínimo — organização de arquivos, perguntas e respostas básicas, automação rotineira
Aqui está o que recomendamos para cada camada.
Por que o Cache de Prompt é Importante para o OpenClaw
Os agentes OpenClaw mantêm prompts de sistema longos, arquivos de memória persistentes e históricos de conversa extensos — frequentemente enviando dezenas de milhares de tokens em cada solicitação. Sem cache, você paga o preço total de entrada por esses tokens repetidos toda vez.
O cache de prompt resolve isso. Quando um modelo suporta, o provedor armazena prefixos de entrada vistos anteriormente e os serve com um grande desconto em solicitações subsequentes. Para um agente OpenClaw sempre ativo, a economia é substancial:
- Prompts de sistema e arquivos de habilidades — carregados a cada turno, armazenados em cache automaticamente após a primeira solicitação
- Histórico de conversa — apenas as mensagens mais novas incorrem no custo total de entrada; tudo antes do limite do cache é descontado
- Arquivos de memória e contexto — MEMORY.md, RULES.md e outros arquivos de espaço de trabalho que raramente mudam entre turnos
No Novita AI, a maioria dos modelos recomendados suporta cache de prompt com redução de 50–90% no custo de entrada para tokens em cache. O preço do cache para cada modelo é listado junto com o preço padrão nas camadas abaixo.
Camada 1: Modelos de Potência — Quando Precisa Estar Correto
Algumas tarefas exigem o raciocínio mais forte disponível. Quando a precisão é inegociável ou um único erro é caro, estes são os modelos a serem usados.
Claude Sonnet 4.6 e Claude Opus 4.6
Os modelos Claude da Anthropic são amplamente considerados o padrão ouro para raciocínio complexo e seguimento de instruções nuançado. O Sonnet oferece um forte equilíbrio entre velocidade e inteligência para a maioria das tarefas avançadas, enquanto o Opus é a opção definitiva para trabalhos onde a precisão importa acima de tudo.
GPT-5.4
O modelo mais capaz da OpenAI para trabalho profissional. O GPT-5.4 é um modo de raciocínio principal, com processamento padrão para comprimentos de contexto abaixo de 270K tokens. Ele se destaca em raciocínio complexo de várias etapas, geração de código e tarefas que exigem pensamento analítico profundo — tornando-o uma escolha natural para fluxos de trabalho de agente de alto risco onde a precisão justifica o custo premium.
Gemini 3 Flash Preview
O Gemini 3 Flash do Google oferece capacidade de nível de fronteira com tempos de resposta rápidos, sendo uma escolha sólida quando você precisa de velocidade e profundidade para tarefas exigentes.
💡Quando usar a Camada 1:
- Refatoração complexa de código em vários arquivos
- Análise de decisões de alto risco
- Tarefas onde um único erro é caro
- Revisão e validação de saídas críticas
⚖️A compensação: Esses modelos oferecem qualidade excepcional, mas têm um preço premium. Para um agente OpenClaw sempre ativo processando centenas de solicitações diariamente, executar a Camada 1 em todas as tarefas rapidamente se torna caro. É aí que entram as duas próximas camadas — cobrindo a grande maioria da carga de trabalho do seu agente por uma fração do custo.
Camada 2: Uso Diário — A Maioria das Tarefas, Melhor Custo-Benefício
É aqui que seu agente passa a maior parte do tempo pensando. Esses modelos equilibram custo e capacidade para o trabalho que realmente importa — e são bons o suficiente para que você raramente precise escalar para a Camada 1.
Kimi K2.5
O Kimi K2.5 da Moonshot AI tornou-se uma escolha de destaque para cargas de trabalho de agente. Construído em uma arquitetura MoE (Mixture-of-Experts), ele é especificamente otimizado para uso de ferramentas, planejamento de várias etapas e geração de código — exatamente as capacidades das quais os agentes OpenClaw mais dependem.
O que diferencia o K2.5 é seu desempenho como agente. Ele está entre os melhores modelos em benchmarks de codificação e sua precisão na chamada de ferramentas rivaliza com modelos muito mais caros. A janela de contexto de 262K é generosa o suficiente para fluxos de trabalho complexos envolvendo vários documentos ou longos históricos de conversa.
- Janela de contexto: 262K tokens
- Preço: $0,60/M entrada · $3,00/M saída · $0,10/M entrada em cache
- Pontos fortes: Capacidade de agente de alto nível pelo preço, excelente geração de código e uso de ferramentas, raciocínio robusto em várias etapas.
- Melhor para: O uso diário principal — escrita de código, fluxos de trabalho de agente em várias etapas, tarefas de pesquisa e qualquer coisa que exija chamadas de ferramentas.
Experimente o Kimi K2.5 no Novita Playground
GLM-5
O modelo principal da Z.ai representa um passo significativo em relação à série GLM-4. O GLM-5 compete com modelos de fronteira em tarefas de raciocínio e codificação, mantendo preços competitivos. Ele possui capacidades aprimoradas em raciocínio matemático, geração de código e saída estruturada — tornando-o particularmente adequado para fluxos de trabalho de agente que precisam de uso confiável de ferramentas.
- Janela de contexto: 202K tokens
- Preço: $1,00/M entrada · $3,20/M saída · $0,20/M entrada em cache
- Pontos fortes: Raciocínio forte, muito eficaz em saída estruturada e chamada de funções, desempenho competitivo em benchmarks contra modelos com preço 2–3× maior.
- Melhor para: Tarefas complexas de agente — análise de código, resolução de problemas em várias etapas, geração de relatórios e fluxos de trabalho com uso intenso de ferramentas.
Experimente o GLM-5 no Novita Playground
Qwen3.5-397B-A17B
O maior modelo da série Qwen 3.5 da Alibaba, construído em uma arquitetura MoE que ativa apenas uma fração de seus parâmetros totais por passo forward. Isso significa que você obtém inteligência de modelo grande por uma fração do custo esperado. Com uma janela de contexto de 262K, ele lida com sessões de agente estendidas e fluxos de trabalho com vários documentos sem degradação de contexto.
- Janela de contexto: 262K tokens
- Preço: $0,60/M entrada · $3,60/M saída
- Pontos fortes: Desempenho de raciocínio e codificação próximo da fronteira, excelente manuseio de contexto longo, inferência MoE eficiente.
- Melhor para: Tarefas que precisam de capacidade máxima a um preço intermediário — geração de código complexo, raciocínio analítico e tarefas de pesquisa de contexto longo.
Experimente o Qwen3.5-397B-A17B no Novita Playground
💡Para que a Camada 2 é boa:
- Geração e depuração de código
- Criação e edição de conteúdo
- Fluxos de trabalho de agente em várias etapas
- Tarefas de pesquisa e análise
- Uso de ferramentas e chamada de funções
Camada 3: Modelos Econômicos — Tarefas Simples, Custo Mínimo
Esses modelos lidam com trabalho de alto volume e baixa complexidade. Eles são surpreendentemente capazes para tarefas diretas e mantêm sua conta de tokens sob controle.
DeepSeek V3.2
O mais recente modelo de uso geral da DeepSeek, construído em uma arquitetura MoE que oferece desempenho forte em codificação, matemática e raciocínio geral a preços baixíssimos. Seu design eficiente significa que você obtém saída de qualidade sem custos premium.
- Janela de contexto: 163K tokens
- Preço: $0,269/M entrada · $0,40/M saída · $0,13/M entrada em cache
- Pontos fortes: Excelente relação custo-desempenho, boa capacidade de codificação, velocidade de inferência rápida.
- Melhor para: Tarefas rotineiras de agente, extração de dados, formatação de texto e perguntas e respostas gerais.
Experimente o DeepSeek V3.2 no Novita Playground
GLM-4.7 Flash
O modelo otimizado para velocidade da Zhipu AI, projetado para cenários de alto rendimento onde a latência de resposta importa mais do que a profundidade máxima de raciocínio. Ele suporta bem tanto chinês quanto inglês, tornando-o uma escolha forte para configurações de agente multilíngue.
- Janela de contexto: 200K tokens
- Preço: $0,07/M entrada · $0,40/M saída · $0,01/M entrada em cache
- Pontos fortes: Um dos modelos mais baratos disponíveis com janela de contexto de 200K. Tempos de resposta muito rápidos. Forte em saída estruturada e seguimento de instruções.
- Melhor para: Tarefas de alto volume e baixa complexidade — sumarização, classificação, formatação de dados e fluxos de trabalho de notificação.
Experimente o GLM-4.7 Flash no Novita Playground
MiniMax M2.5
O M2.5 da MiniMax é um versátil com boa relação custo-benefício que supera seu preço. Ele lida bem com análise de documentos e conversas estendidas, com uma longa janela de contexto que suporta fluxos de trabalho de múltiplos turnos sem degradação.
- Janela de contexto: 204K tokens
- Preço: $0,30/M entrada · $1,20/M saída · $0,03/M entrada em cache
- Pontos fortes: Desempenho confiável em contexto longo, bom em seguir instruções complexas, forte suporte multilíngue.
- Melhor para: Tarefas que exigem um pouco mais de capacidade do que os modelos mais baratos — sumarização de documentos, conversas de múltiplos turnos e rascunho de conteúdo.
Experimente o MiniMax M2.5 no Novita Playground
💡Para que a Camada 3 é boa:
- Gerenciamento e organização de arquivos
- Respostas a perguntas simples
- Formatação e extração de dados
- Notificações e resumos rotineiros
Execute sua Pilha de Modelos no Novita AI
Todos os modelos das Camadas 2 e 3 recomendados acima — Kimi K2.5, GLM-5, Qwen3.5-397B-A17B, DeepSeek V3.2, GLM-4.7 Flash e MiniMax M2.5 — estão disponíveis no Novita AI através de uma única chave de API.
Por que isso é importante para usuários do OpenClaw:
- Formato de API compatível com OpenAI/Anthropic — conecte-se diretamente à configuração de modelo do OpenClaw sem adaptadores personalizados
- Uma chave de API, vários modelos — alterne entre camadas sem gerenciar contas separadas
- Cache de prompt na maioria dos modelos — reduz significativamente os custos de entrada e acelera as respostas para sessões de agente com contexto longo
- Pagamento por token — sem assinaturas ou compromissos mínimos
Você também pode experimentar esses modelos interativamente no Novita AI Playground — um ambiente baseado na web para experimentar prompts, explorar parâmetros visualmente e obter feedback instantâneo antes de implantar no OpenClaw.
Para um guia passo a passo sobre como integrar modelos como o Kimi K2.5 em seus agentes OpenClaw — incluindo configuração de bot do Telegram e configuração avançada — confira nosso tutorial detalhado: Use o Kimi K2.5 no OpenClaw (Clawdbot): Configuração Rápida para Agentes do Telegram com o Novita.
NovitaClaw: Implante o OpenClaw em Um Comando
Quer seu agente OpenClaw rodando 24/7 na nuvem sem gerenciar infraestrutura? O NovitaClaw te leva até lá em um comando.
O NovitaClaw é uma ferramenta de implantação construída no Novita Agent Sandbox que provisiona uma instância totalmente configurada do OpenClaw a partir do seu terminal. Três passos, qualquer plataforma:
Passo 1: Instalar o NovitaClaw
sudo pip3 install novitaclaw
Passo 2: Definir sua chave de API
export NOVITA_API_KEY=sk_your_api_key
Passo 3: Iniciar
novitaclaw launch
Passo 1: Instalar o NovitaClaw
pip install novitaclaw
Passo 2: Definir sua chave de API
$env:NOVITA_API_KEY = "sk_your_api_key"
Passo 3: Iniciar
novitaclaw launch
Pronto. Em menos de um minuto, você obtém:
- Um agente OpenClaw 24/7 — sem limites de sessão, sem reinicializações manuais. Seu agente permanece online pelo tempo que você precisar.
- Pré-configurado com modelos Novita — sua pilha de modelos em camadas está pronta para uso. Alterne modelos a qualquer momento através das configurações da interface web.
- Suporte a múltiplos canais — conecte Telegram, Discord e outras plataformas de mensagens para que seu agente esteja acessível onde quer que você esteja.
- Recuperação automática — se o agente falhar, ele reinicia automaticamente e restaura a última configuração funcional. Sem perda de dados, sem intervenção manual.
- Terminal Web e Gerenciador de Arquivos integrados — acesse o ambiente do seu agente diretamente do navegador para depuração e gerenciamento de arquivos.
O sandbox subjacente executa em 2 vCPU e 4 GB de RAM — dimensionado para cargas de trabalho de produção reais, não para demonstrações. Todos os modelos da plataforma Novita são suportados, e você pode trazer suas próprias chaves de API de terceiros para modelos como Claude ou Gemini, se precisar de acesso à Camada 1.
👉 Para o guia de configuração completo — incluindo configuração de modelo, integração com bot do Telegram e opções avançadas, veja NovitaClaw: Execute o OpenClaw na Nuvem com Um Comando.
Leia o Guia Completo de Configuração do NovitaClaw
Uma Nota sobre Dados de Uso do OpenRouter
Para os curiosos sobre o que a comunidade mais ampla usa: o OpenClaw é atualmente o aplicativo #1 classificado no OpenRouter por uso diário, processando 12,6 trilhões de tokens em 348 modelos em março de 2026.
Os principais modelos por volume de tokens incluem Step 3.5 Flash (2,2T), MiniMax M2.5 (1,3T), Kimi K2.5 (962B), Claude Sonnet 4.6 (805B) e GLM 5 Turbo (579B). Vale notar que alguns modelos próximos ao topo podem ter uso elevado devido a eventos promocionais ou disponibilidade de nível gratuito, então o volume bruto de tokens nem sempre reflete diretamente a qualidade do modelo. A estratégia em camadas recomendada neste artigo é baseada em uma combinação de padrões de uso, capacidades dos modelos e feedback real da comunidade.
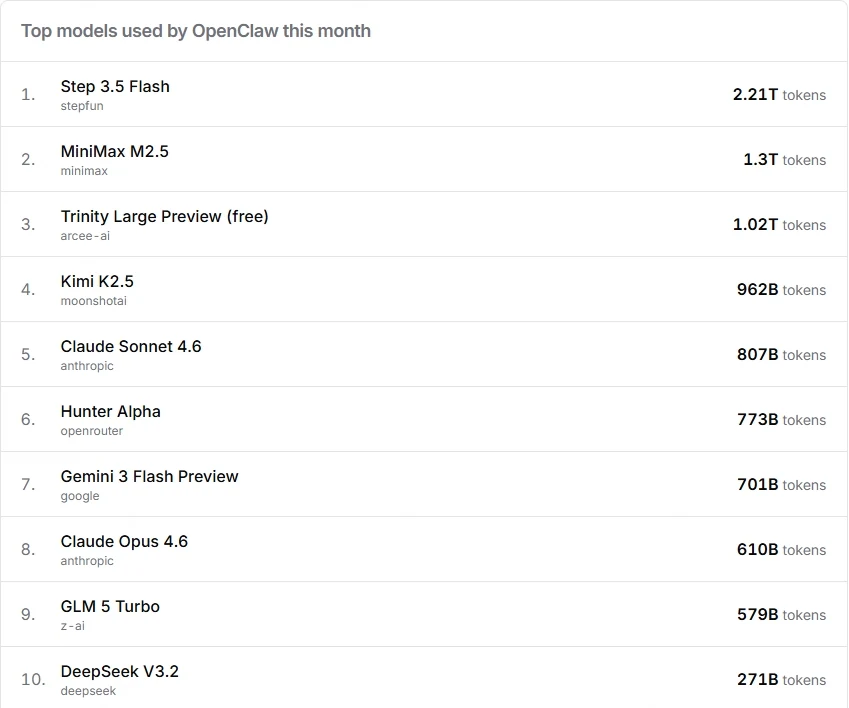
Fonte: OpenRouter
Conclusão
As configurações mais eficazes do OpenClaw não dependem de um único modelo — elas usam três camadas. Modelos de potência como o Claude lidam com os momentos que exigem precisão máxima. Modelos de uso diário como Kimi K2.5 e GLM-5 fazem o pensamento real a um custo razoável. E modelos econômicos como DeepSeek V3.2 e GLM-4.7 Flash absorvem o trabalho rotineiro de alto volume.
Com o Novita AI, você pode acessar todas as recomendações das Camadas 2 e 3 através de uma única API. E com o NovitaClaw, você pode implantar toda a pilha em um comando — sem necessidade de infraestrutura.
Novita AI é uma plataforma de nuvem de IA e agentes que ajuda desenvolvedores e startups a construir, implantar e escalar modelos e aplicações de agentes com alto desempenho, confiabilidade e eficiência de custos.
Perguntas Frequentes
Qual é o melhor modelo para OpenClaw?
Não existe um único melhor modelo — depende do seu caso de uso. Para a maioria dos usuários, uma abordagem em camadas funciona melhor: um modelo de uso diário como Kimi K2.5 ou GLM-5 para tarefas gerais, com modelos econômicos como DeepSeek V3.2 para trabalhos simples. Todos estes estão disponíveis no Novita AI através de uma chave de API.
O Novita AI é compatível com OpenClaw?
Sim. O Novita AI fornece um formato de API compatível com OpenAI/Anthropic, o que significa que ele se conecta diretamente à configuração de modelo do OpenClaw sem a necessidade de adaptadores personalizados. Também oferece sem limites de taxa e preço por token — ambos importantes para agentes sempre ativos.
Como configurar o OpenClaw com o Novita AI?
Duas opções. Se você já tem o OpenClaw em execução, basta configurá-lo com sua chave de API Novita — a API é compatível com OpenAI/Anthropic, então você só precisa atualizar a URL base e o nome do modelo. Veja nosso tutorial passo a passo para um guia detalhado. Se preferir começar do zero, o NovitaClaw implanta uma instância totalmente configurada em um comando (novitaclaw launch) com disponibilidade 24/7 e recuperação automática. Veja o guia de configuração do NovitaClaw para detalhes.



