

في أواخر عام 2025، تحول مشهد النماذج المتقدمة نحو “الاستدلال الهجين”—نماذج تتوقف للتفكير قبل إنشاء استجابة. يحدد نموذجان رئيسيان رائدان هذا العصر: Claude 4.5 Sonnet من Anthropic و GLM-4.7 من Z.AI. بينما يركز Claude على التميز الاحتكاري للوكلاء مع التحكم الأصلي بالكمبيوتر، تقدم GLM-4.7 بديلاً مفتوح الأوزان قويًا مع كفاءات تكلفة فريدة وقدرات رياضية متطورة.
GLM-4.7 مقابل Claude 4.5 Sonnet: مقدمة أساسية
يدمج كلا النموذجين استدلال “سلسلة التفكير” (CoT) مباشرة في عملية التوليد، لكنهما يتبعان نهجًا مختلفًا في البنية المعمارية والنشر.
| الميزة | GLM-4.7 | Claude 4.5 Sonnet |
| المطور | Z.AI (أوزان مفتوحة) | Anthropic (مصدر مغلق) |
| تاريخ الإصدار | 22 ديسمبر 2025 | 29 سبتمبر 2025 |
| البنية المعمارية | نموذج مختلط الخبراء (MoE) بمعاملات 358 مليار | نموذج استدلال هجين احتكاري |
| نافذة السياق | 200 ألف مدخل / 128 ألف مخرج | 200 ألف مدخل / 64 ألف مخرج |
GLM-4.7 مقابل Claude 4.5 Sonnet: المعايير
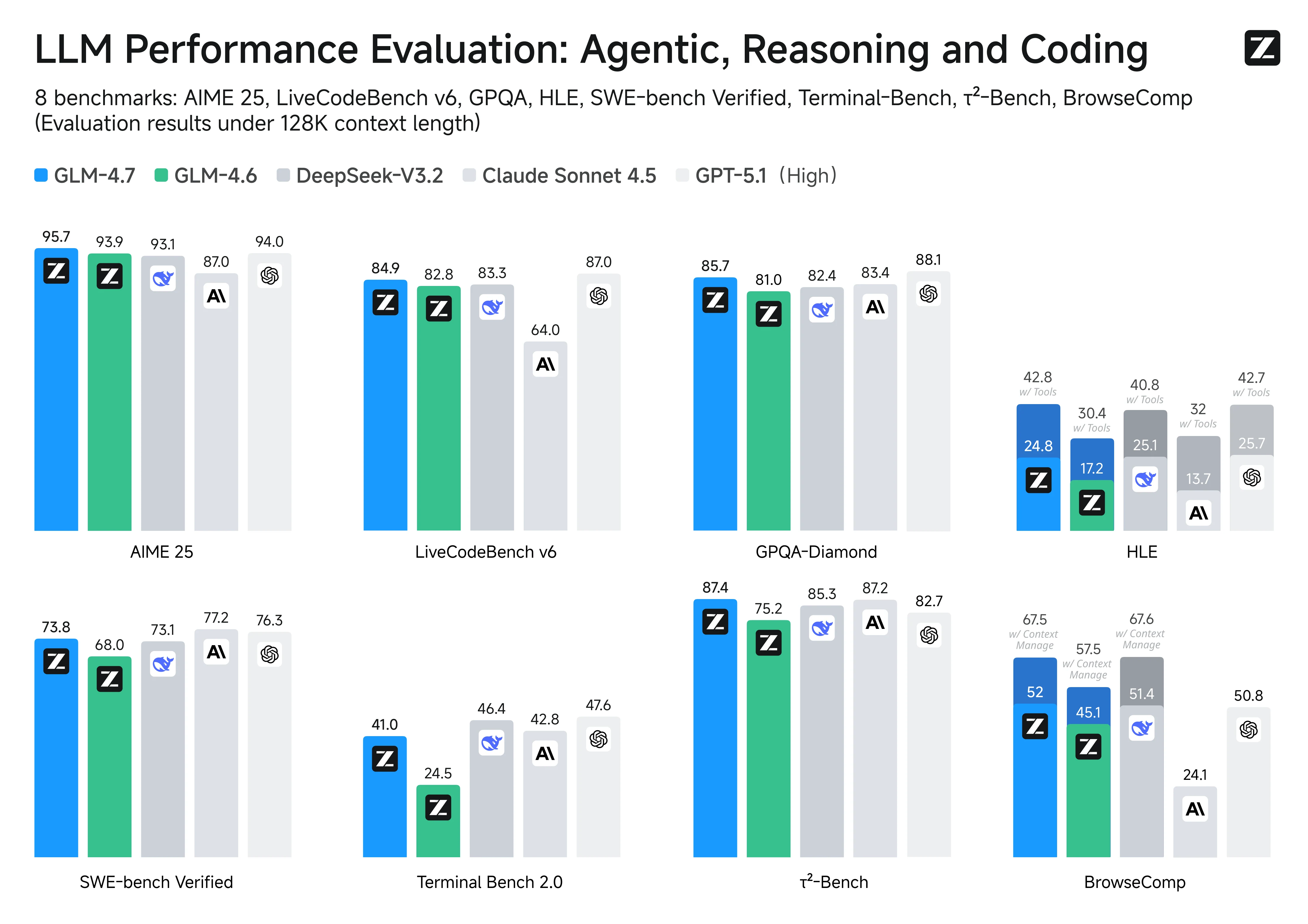
الرياضيات / استدلال بأسلوب الأولمبياد
- AIME 2025: GLM-4.7 95.7 مقابل Claude 87.0 (+8.7 لصالح GLM)
البرمجة (بنمط المعايير)
- LiveCodeBench-v6: GLM-4.7 84.9 مقابل Claude 64.0 (+20.9 لصالح GLM)
هندسة البرمجيات في العالم الحقيقي
- SWE-bench Verified: GLM-4.7 73.8 مقابل Claude 77.2 (+3.4 لصالح Claude)
مهام الطرفية الوكيلة
- Terminal Bench 2.0: GLM-4.7 41.0 مقابل Claude 42.8 (+1.8 لصالح Claude؛ متقاربان جدًا)
استخدام الأدوات / استدعاء الأدوات التفاعلي
- τ²-Bench: GLM-4.7 87.4 مقابل Claude 87.2 (متساويان إلى حد كبير)
- HLE (مع الأدوات): GLM-4.7 42.8 مقابل Claude 32.0 (+10.8 لصالح GLM)
مهام الويب / تقييم بأسلوب التصفح
- BrowseComp: GLM-4.7 52.0 مقابل Claude 24.1 (+27.9 لصالح GLM)
- BrowseComp (مع إدارة السياق): GLM-4.7 67.5 (لم يتم الإبلاغ عن Claude في ذلك الصف في نفس الجدول)
💡التفسير:
- إذا كانت أولويتك هي الاستدلال الرياضي و البرمجة بنمط المعايير، فإن GLM-4.7 يتقدم بقوة (AIME, LiveCodeBench).
- إذا كانت أولويتك هي هندسة البرمجيات الحقيقية، فإن Claude يتقدم في SWE-bench Verified.
- بالنسبة لـ استخدام الأدوات التفاعلي، الصورة مختلطة: τ²-Bench تعادل، لكن GLM-4.7 أعلى في HLE المعزز بالأدوات و BrowseComp في الجدول المنشور.
GLM-4.7 مقابل Claude 4.5 Sonnet: السرعة وزمن الاستجابة
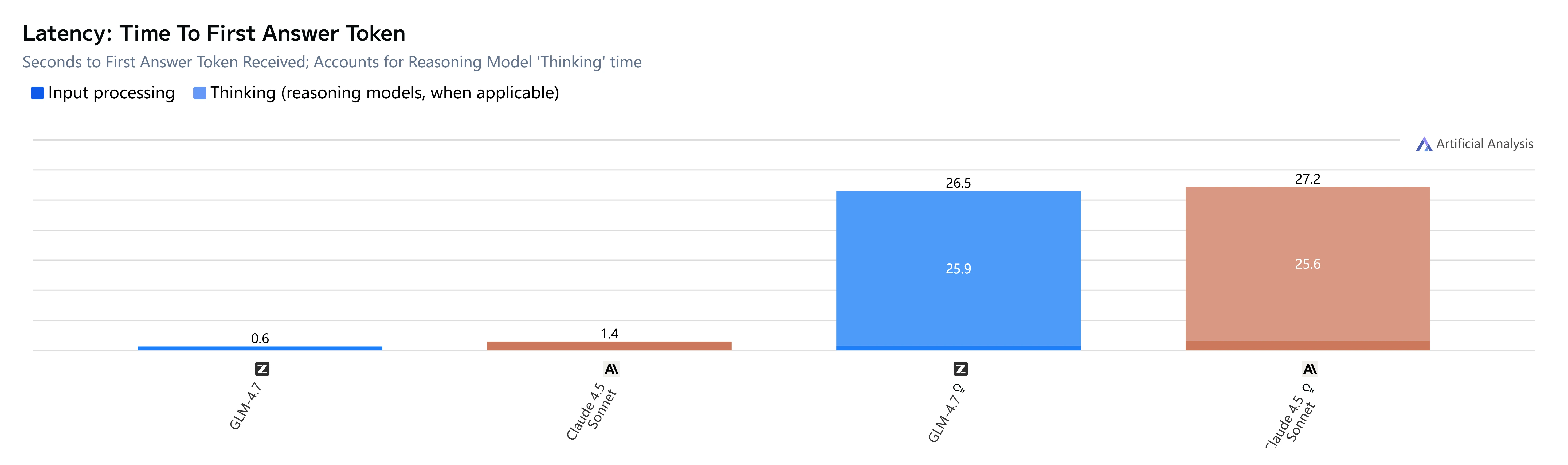
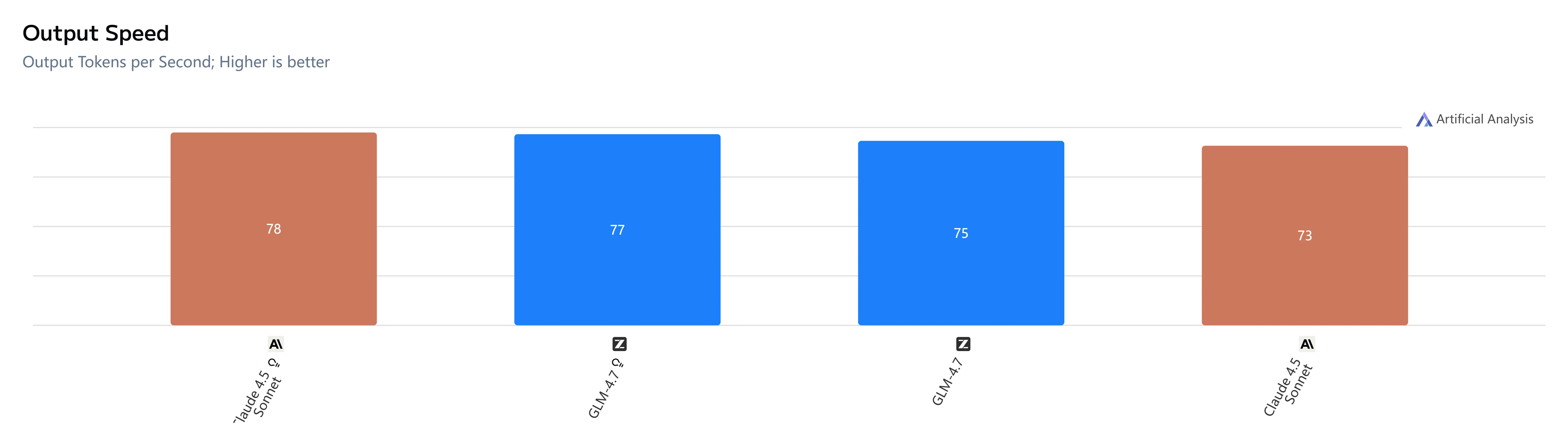
🤖الخلاصة الرئيسية:
تتمتع GLM-4.7 بميزة بسيطة في الاستجابات “السريعة”، بينما في سيناريوهات الاستدلال العميق يتصرف النموذجان بشكل متشابه—لذلك فإن تحسين السرعة المتصورة يتعلق معظمه بالتحكم في وقت دخول النموذج في التفكير الطويل بدلاً من الاختيار بين النموذجين بناءً على سرعة فك التشفير وحدها.
GLM-4.7 مقابل Claude 4.5 Sonnet: التكلفة
تقدم GLM-4.7 ميزة تكلفة كبيرة. يقارن الجدول التالي أسعار Novita AI لـ GLM-4.7 مع أسعار Anthropic المباشرة لواجهة برمجة التطبيقات.
| النموذج | المزود | سعر المدخل (لكل مليون رمز) | سعر المخرج (لكل مليون رمز) |
| GLM-4.7 | Novita AI | $0.60 | $2.20 |
| Claude 4.5 Sonnet | Anthropic | $3.00 | $15.00 |
🎉الآثار المترتبة على التكلفة:
GLM-4.7 أرخص 5 مرات في المدخلات وأرخص بنحو 6.8 مرة في المخرجات مقارنة بـ Claude 4.5 Sonnet. للتطبيقات التي تتطلب استدلالًا مكثفًا (الذي يولد رموز مخرجات أكثر)، توفر GLM-4.7 تخفيضًا هائلاً في النفقات التشغيلية.
كيفية الوصول إلى GLM 4.7 على منصة Novita AI
توفر منصة Novita AI وصولًا مرنًا وصديقًا للمطورين إلى GLM-4.7، مما يتيح لك استخدام نموذج الاستدلال الهجين عالي الأداء هذا عبر البحث، الإنتاج، وسير عمل الذكاء الاصطناعي الوكيل. سواء كنت تستكشف الرياضيات المتقدمة، أو توليد الأكواد على نطاق واسع، أو تبني أنظمة مستقلة ذات كفاءة تكلفة عالية، تقدم Novita AI البنية التحتية للبدء بسرعة.
الخيار 1: استخدام مساحة اللعب (Playground)
(متاح الآن – لا يتطلب برمجة)
- وصول فوري: أنشئ حسابًا وابدأ في تجربة GLM-4.7 في ثوانٍ.
- واجهة تفاعلية: اختبر الأوامر، وبدل سلوك الاستدلال، وافحص مخرجات السياق الطويل في الوقت الفعلي.
- مقارنة النماذج: قارن GLM-4.7 مع النماذج الرائدة الأخرى لتقييم عمق الاستدلال، وكفاءة التكلفة، وجودة المخرجات.
تعد مساحة اللعب مثالية للنماذج الأولية، وتجربة الأوامر، وتقييم نقاط قوة GLM-4.7 في الرياضيات، واستخدام الأدوات، وتوليد الأكواد عالية الجماليات قبل دمجها في أنظمة الإنتاج.
الخيار 2: التكامل عبر واجهة برمجة التطبيقات (API)
(للمطورين)
أدخل GLM-4.7 إلى تطبيقاتك باستخدام واجهة برمجة التطبيقات الموحدة المتوافقة مع OpenAI من Novita AI.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
قم بتسجيل الدخول (أو إنشاء حساب جديد) إلى حسابك في Novita AI وانتقل إلى مكتبة النماذج.
الخطوة 2: اختيار GLM-4.7
تصفح النماذج المتاحة واختر GLM-4.7 بناءً على متطلبات عبء العمل الخاص بك.
الخطوة 3: بدء الفترة التجريبية المجانية
فعل الفترة التجريبية المجانية لاستكشاف خصائص الاستدلال، والسياق الطويل، والأداء مقابل التكلفة لـ GLM-4.7.
الخطوة 4: الحصول على مفتاح واجهة برمجة التطبيقات (API Key)
افتح صفحة الإعدادات لإنشاء ونسخ مفتاح واجهة برمجة التطبيقات الخاص بك للمصادقة.
الخطوة 5: تثبيت واستدعاء واجهة برمجة التطبيقات (مثال بلغة بايثون)
فيما يلي مثال بسيط باستخدام واجهة برمجة تطبيقات إكمال الدردشة مع لغة بايثون:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
يتيح لك هذا الإعداد التحكم في عمق الاستدلال، واستخدام الرموز، وسلوك التوليد—مفيد بشكل خاص عند الاستفادة من التفكير على مستوى الدور لإدارة التكلفة وزمن الاستجابة.
الخيار 3: سير عمل الوكلاء المتعددين باستخدام OpenAI Agents SDK
ابنِ أنظمة وكلاء متعددين متطورة باستخدام GLM-4.7 كعامل استدلال أو متخصص في الأدوات:
- تكامل مفتاح التشغيل: استخدم GLM-4.7 في أي سير عمل لوكلاء OpenAI.
- أنماط وكلاء متقدمة: دعم التوجيه، ونقل المهام، واستدعاء الأدوات، والأوضاع المختلطة “تفكير / عدم تفكير”.
- تكيف فعال من حيث التكلفة: مثالي لسربات الوكلاء الكبيرة أو مهام الاستدلال الثقيل رياضياً على نطاق واسع.
هذا النهج مناسب جدًا لدمج GLM-4.7 مع نماذج أخرى—على سبيل المثال، استخدام GLM-4.7 للاستدلال الرياضي والبرمجة المنظمة، بينما تفوض مهام مستوى نظام التشغيل إلى وكلاء آخرين.
الخيار 4: الاتصال بالمنصات الخارجية
- أدوات التطوير: ادمج GLM-4.7 مع بيئات التطوير المتكاملة (IDEs) وأدوات برمجة الذكاء الاصطناعي مثل Cursor و Trae و Qwen Code و Cline عبر واجهة برمجة التطبيقات المتوافقة مع OpenAI من Novita AI.
- أطر التنسيق: اربط GLM-4.7 بـ LangChain و Dify و CrewAI و Langflow ومنصات التنسيق الأخرى باستخدام موصلات رسمية.
- النظام البيئي لـ Hugging Face: تعمل Novita AI كمزود استدلال رسمي لـ Hugging Face، مما يضمن توافقًا واسعًا عبر النظام البيئي للتعلم الآلي مفتوح المصدر.
الخلاصة
يعد Claude Sonnet 4.5 الخيار الأقوى عندما تكون أولويتك هي نتائج هندسة البرمجيات في العالم الحقيقي (مثل التقدم في SWE-bench Verified) وعندما يعتمد منتجك على قدرات التفاعل مع الكمبيوتر المدعومة بأدوات الاستخدام الحاسوبي من Anthropic.
يعد GLM-4.7 خيارًا جذابًا عندما تريد نموذجًا مفتوح الأوزان مع نتائج منشورة قوية في الاستدلال الرياضي، و البرمجة بنمط المعايير، وعدة تقييمات بأسلوب الأدوات/التصفح، مع تقديم ميزة تسعير كبيرة بأسعار Novita.
الأسئلة الشائعة
هل GLM أفضل من Sonnet؟
GLM-4.7 أفضل من حيث التكلفة، والرياضيات، والنشر المحلي، بينما Claude 4.5 Sonnet أفضل من حيث الموثوقية، والاستخدام الحاسوبي، والسلامة المؤسسية.
اختر GLM-4.7 إذا كنت تسعى إلى تحسين التكاليف، والبرمجة على نطاق واسع، والرياضيات المتقدمة، أو تحتاج إلى الاستضافة الذاتية.
اختر Sonnet إذا كنت بحاجة إلى وكيل برمجة الأكثر موثوقية، وأدوات استخدام حاسوبي قوية، وسلامة/امتثال صارمة.
ما هو GLM 4.7؟
GLM-4.7 هو نموذج اللغة الكبير الرائد لـ Z.ai، مصمم للبرمجة المعززة والاستدلال/التنفيذ متعدد الخطوات الأكثر استقرارًا، ويتم إصداره كنموذج رسمي مفتوح الأوزان (متاح على Hugging Face).
ما هو Claude Sonnet 4.5؟
Claude Sonnet 4.5 هو النموذج الرائد متعدد الأغراض في عائلة Claude من Anthropic، مسوق للاستخدام الإنتاجي اليومي والمهام المعقدة، ومتاح عبر واجهة برمجة تطبيقات Claude كـ claude-sonnet-4-5 مع تسعير يبدأ من 3 دولارات لكل مليون رمز مدخل + 15 دولارًا لكل مليون رمز مخرج.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، مع توفير سحابة GPU بأسعار معقولة وموثوقة للبناء والتوسع.



