

重點摘要
- LLaMA 3.3 70B 的 700 億參數需要大量 VRAM,即使使用量化技術也是如此。
- 建議使用 NVIDIA RTX 3090 或 4090 等 GPU 來有效運行模型。
- 家庭伺服器在 VRAM、儲存空間、電源與散熱方面可能面臨限制。
- 最佳化技術與謹慎配置對於在本機運行 LLaMA 3.3 70B 至關重要。
- 獨立開發者可透過使用 API 服務(例如 Novita AI)來降低成本。
LLaMA 3.3 70B 是一款強大的語言模型,對於在家運行伺服器的人來說,其 VRAM 需求是一項基準挑戰。雖然在自己的電腦上運行大型語言模型能提供隱私與自訂化能力,但對一般家庭伺服器配置而言可能負擔過重。本文將探討 LLaMA 3.3 70B 所需的 VRAM 數量,並討論它為家庭伺服器帶來的技術問題。
探索 LLaMA 3.3 70B 的 VRAM 需求

LLaMA 3.3 70B 是一個擁有 700 億參數的大型語言模型,專為進階自然語言處理任務而設計,在複雜 AI 應用中提供令人印象深刻的效果。
詳細硬體需求
要運行 LLaMA 3.3 70B,您需要效能良好的硬體相互搭配。GPU、CPU 與 RAM 都應相互支援,以提供所需的運算能力與記憶體。首先,我們應了解各項硬體需求的涵義。
| 元件 | 需求 |
|---|---|
| CPU | 最少 8 核心 |
| RAM | 最少 32 GB;建議 64 GB 以上 |
| VRAM | ~35 GB(4 位元量化);較高精度可達 141 GB |
| GPU | NVIDIA RTX 系列;A100 |
| 儲存空間 | ~200 GB |
與先前模型的 VRAM 需求比較
Llama 3.3 70B 代表 AI 模型效率的重大進步,它在顯著降低 GPU 記憶體需求的同時,效能可與先前數千億參數的模型相媲美。具體來說,Meta 推出的 Llama 3.3 使用量化技術時,最低只需 35 GB 的 VRAM,而較大的 Llama 3.1-70B 需要 148 GB,Llama 2 70B 則需 140 GB。這項最佳化能讓使用者在初始 GPU 成本上節省開支。
| 模型 | 參數量 | VRAM 需求 | 建議 GPU |
|---|---|---|---|
| Llama 3.3 70B | 700 億 | 35 GB(FP16) | NVIDIA RTX 3090、A100 40GB |
| Llama 2 70B | 700 億 | 140 GB(FP16) | NVIDIA A100 80GB、2x3090 |
| Llama 3.1 70B | 700 億 | ~148 GB(FP16) | NVIDIA A100 80GB、2x3090 |
然而,儘管有這些改進,整體部署成本仍然相對較高,因為需要高效能硬體、持續的電費以及專業人員進行維護與最佳化。
如何選擇符合 LLaMA 3.3 70B VRAM 需求的 GPU
確保 GPU 擁有足夠的 VRAM 以滿足模型需求。選擇能夠在保持穩定的同時處理繁重任務的 GPU。
影響 GPU 與 LLaMA 3.3 70B 搭配的因素
- VRAM 容量: 較高的 VRAM(至少 24 GB)對於在沒有記憶體限制的情況下運行 LLaMA 3.3 70B 等大型模型至關重要。更多的 VRAM 可確保模型載入與推論任務時更流暢的效能。
- **運算能力(TFLOPs):**TFLOPs 衡量 GPU 處理複雜計算的速度。TFLOPs 更高的 GPU 能加速文字生成與深度學習任務,從而更快獲得結果。
- 成本與相容性: 在 GPU 效能與預算之間取得平衡。同時檢查與現有硬體及軟體框架的相容性,以確保順利整合。
運行 LLaMA 3.3 70B 的建議 GPU
在選擇合適的 GPU 並考慮不同變體時,請根據您的預算與期望效能水準來考量。
以下是針對不同需求的建議 GPU 分類:
| GPU | VRAM | TFLOPs (FP32) | 適合用途 | 價格 |
|---|---|---|---|---|
| NVIDIA RTX 4090 | 24GB | 82.57 | 高效能單 GPU 配置 | $3,500.00 |
| NVIDIA RTX 3090 | 24GB | 35.58 | 高性價比單 GPU 或雙 GPU 配置 | $1,425.00 |
| 雙 NVIDIA RTX 3090 | 48GB | 71.16 | 高效能,支援更大的上下文視窗與模型並行 | $2,850.00 |
對小型開發者而言,在雲端租用 GPU 可能更符合成本效益
購買 GPU 時價格可能較高。然而,在 GPU 雲端租用 GPU 能大幅降低成本,因為它按需計費。例如 Novita AI 的 NVIDIA RTX 4090 每小時僅需 $0.35,按使用時間計費,在不需要時能省下不少費用。
以下表格供您參考:
| 服務供應商 | GPU 價格(每小時) | 備註 |
|---|---|---|
| Novita AI | $0.35 | |
| RunPod | $0.69 | 安全雲端 |
| CoreWeave | 無服務 |
家庭伺服器面臨的技術挑戰

在使用 Python 於家庭伺服器上運行 LLaMA 3.3 70B 可能相當困難。多數家庭伺服器缺乏足夠資源來運行這類大型語言模型。首先您可能會遇到 VRAM 問題。接著儲存空間、電源與散熱問題也會接踵而來。
- VRAM 與儲存空間不足: 運行 Llama 3.3 70B 的最大挑戰之一是需大量 VRAM(約 35 GB)及充足的儲存空間。通常需要 NVIDIA RTX 3090 或 A100 等高階 GPU,這對僅有標準硬體的使用者而言難以滿足需求。
- 電源與散熱需求: 高效能 GPU 耗電量巨大,雙 GPU 配置下常超過 600 瓦,可能對家庭電力系統造成負擔。此外,這些 GPU 會產生大量熱能,需要有效的散熱解決方案以防止過熱,增加了設置的複雜性。
- 網路頻寬與延遲: 有效運行 Llama 3.3 需要高速網路頻寬與低延遲。頻寬不足可能導致資料傳輸緩慢與延遲增加,尤其對需即時回應的多使用者場景,會嚴重影響效能。
- 可擴展性與多 GPU 配置: 部署 Llama 3.3 時,可擴展性是一大挑戰。雖然能在單一 GPU 上運行,但要達到最佳效能,仍需使用多個 GPU。然而,建立多 GPU 環境相當複雜,且需相容硬體,使許多使用者難以達到理想的效能水準。
那麼,有哪些方法可以最佳化家庭伺服器呢?
為 LLaMA 3.3 70B 最佳化家庭伺服器
1. 實現最大效率的配置技巧
確保作業系統、驅動程式與 AI 框架保持最新,以獲得最新的效能提升與錯誤修復。您也可以考慮對 GPU 進行降壓(undervolting),即稍微降低 GPU 電壓,有助於在不顯著影響效能的情況下減少功耗與發熱。
建議使用 Docker 容器 來建立獨立且易於管理的環境,以運行 LLaMA 3.3 70B。這有助於管理依賴項並避免軟體衝突,使配置更易於管理。
2. 記憶體管理
即使擁有強大的 GPU,良好的記憶體管理對於使用 LLaMA 3.3 70B 等模型仍非常重要。合理分配記憶體並使用最佳化技巧是關鍵。可以嘗試的一種方法是 梯度檢查點(gradient checkpointing)。這項技術常用於訓練期間,但在推論時也可幫助降低記憶體使用量。儘管計算時間可能略長,但能節省記憶體。
此外,可以考慮使用 transformer 模型剪枝(pruning)與量化(quantization)。剪枝是指移除模型中較不重要的連接,這能縮小模型大小並減少記憶體使用,同時通常能維持效能。但對於小型開發者,如何在確保模型效果的同時進一步降低成本呢?
對小型開發者而言,使用 API 存取 LLaMA 3.3 70B 可能更符合成本效益
當您已嘗試所有最佳化方法,但 AI 應用程式的成本仍然過高時,就該考慮更經濟實惠的 API 方案了。
API 存取如何降低 LLaMA 3.3 70B 的硬體成本
透過 API 存取 LLaMA 3.3 70B,組織無需投入鉅資購買高階硬體,即可使用模型;他們可藉助 Novita 等雲端服務,僅為實際消耗的運算資源付費。這能大幅降低前期成本。
此外,API 服務通常具備自動擴展功能,能根據需求調整資源,避免過度配置並最佳化資源配置。Novita 的基礎設施能快速擴展以滿足需求,同時在離線時高效處理模型更新與資料擴展,確保不間斷的效能。
Novita AI:最合適的選擇
步驟 1: 點選「GPU Instance」
如果您是新用戶,請先註冊帳戶。然後在網頁上點選 [GPU Instance](https://novita.ai/gpus/?utm_source=blogs_gpu&utm_medium=article&utm_campaign= fine-tuning-llama-3-3-70b-with-rtx-4090) 按鈕。
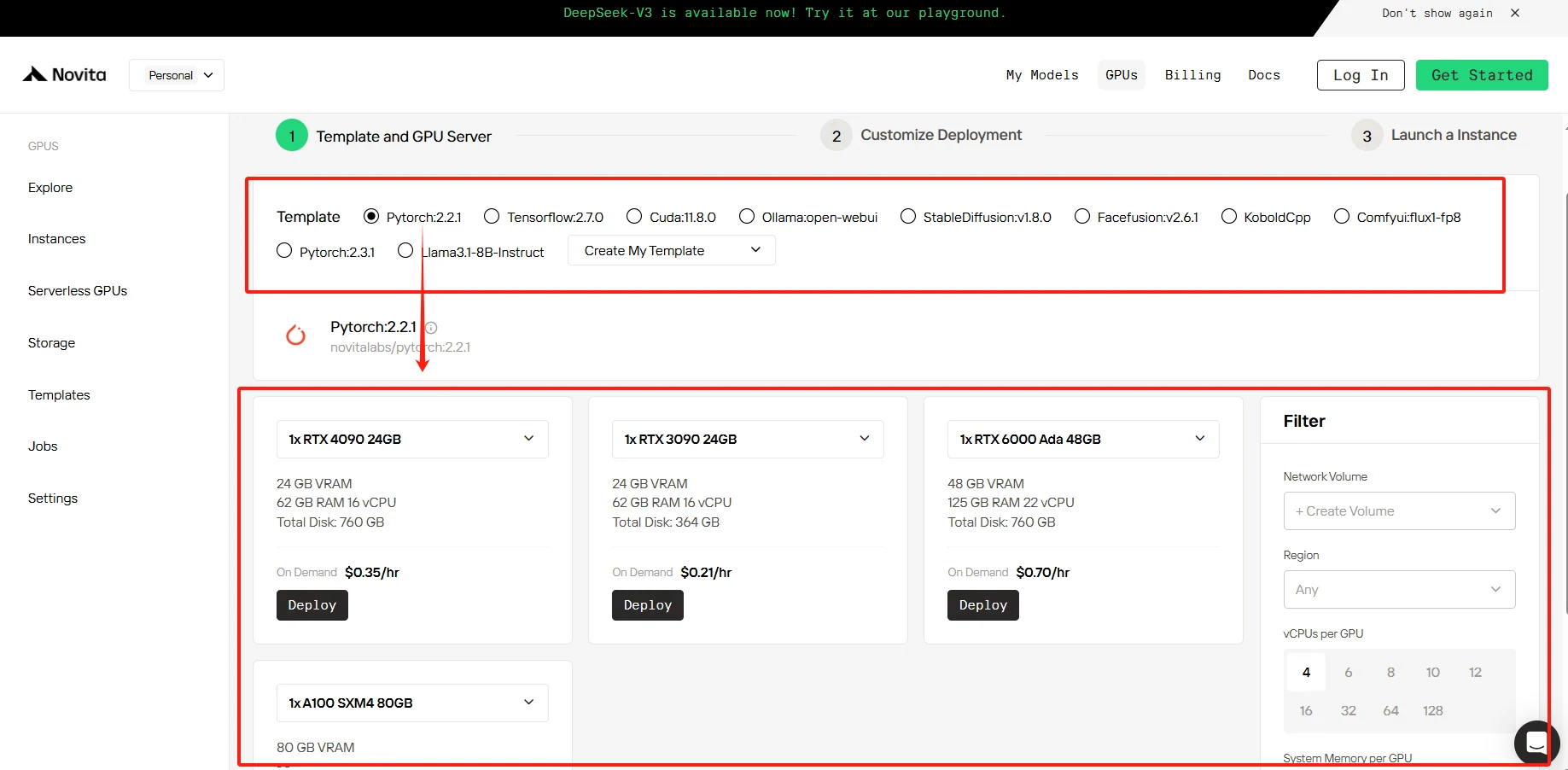
步驟 2: 模板與 GPU 伺服器
您可以根據具體需求選擇自己的模板,包括 PyTorch、TensorFlow、CUDA、Ollama 等。此外,您也可以點擊最後一個選項建立自訂模板資料。接著,我們的服務提供高效能 GPU(如 NVIDIA RTX 4090)的存取,每個 GPU 都配備充足的 VRAM 與 RAM,確保即使是最嚴苛的 AI 模型也能高效訓練。您可以根據需求進行選擇。
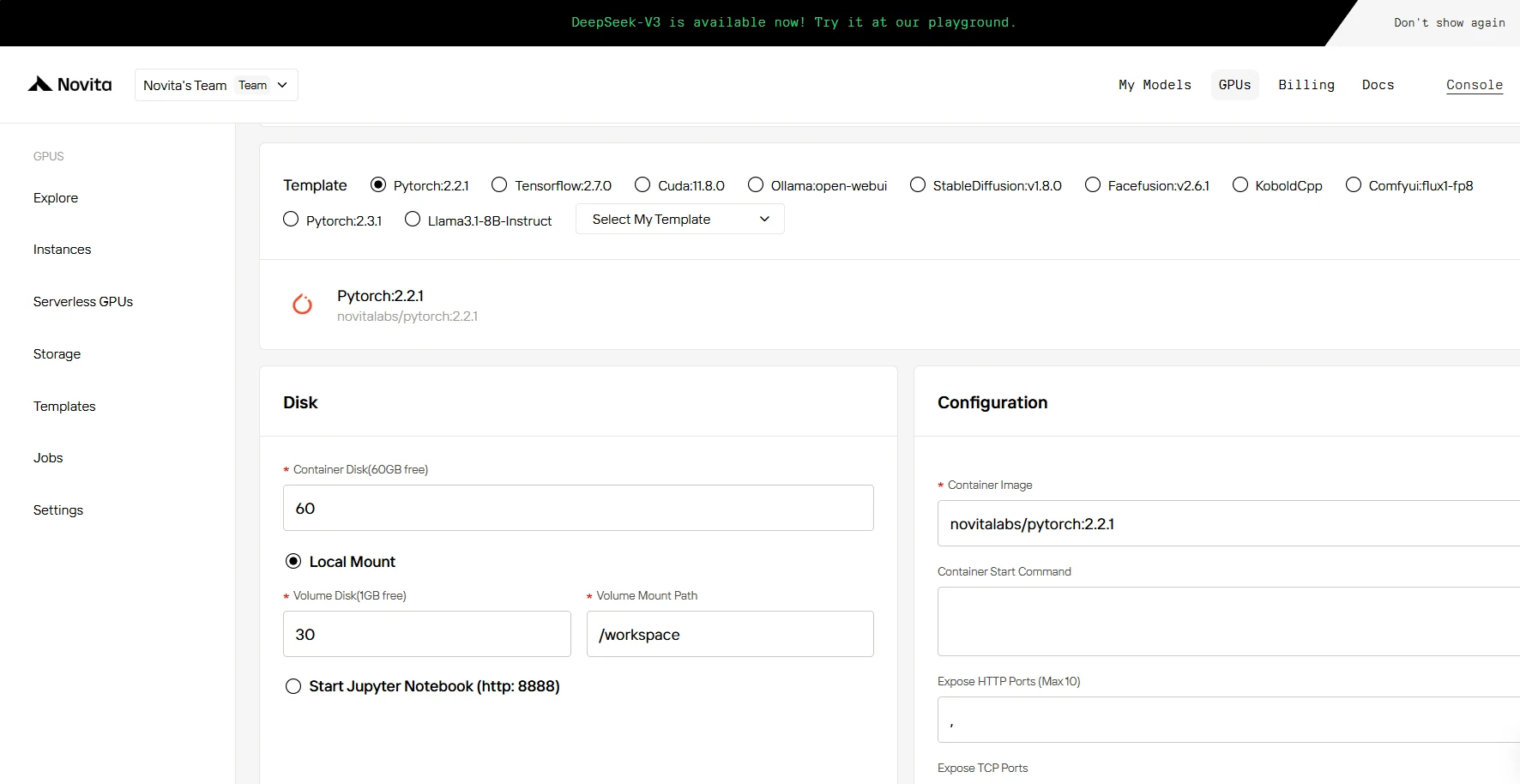
步驟 3: 自訂部署
在此部分,您可以根據自身需求自訂此資料。容器磁碟提供 60GB 免費空間,卷磁碟提供 1GB 免費空間,若超過免費限制將產生額外費用。
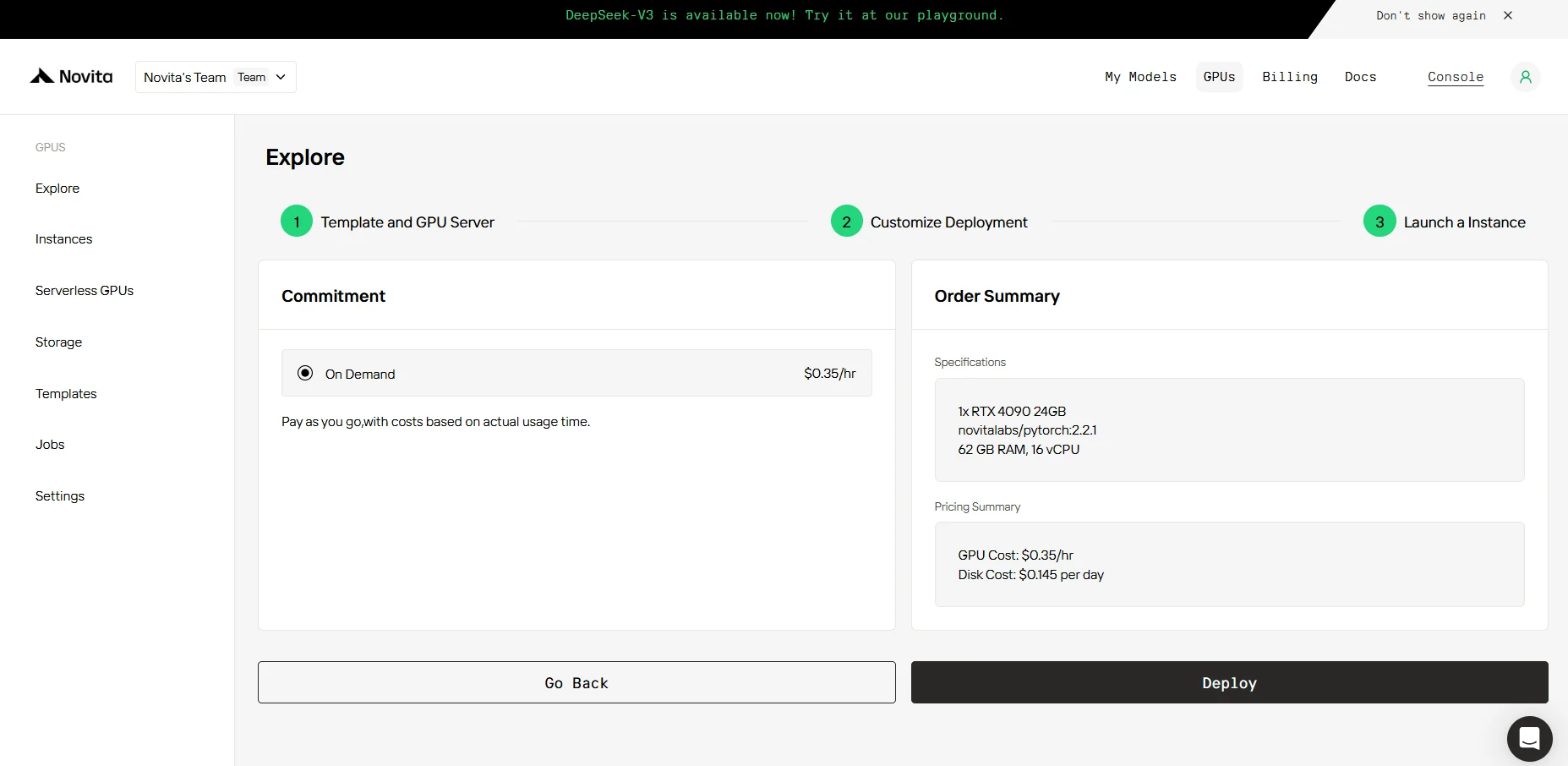
步驟 4: 啟動 執行個體
無論是研究、開發或部署 AI 應用程式,配備 CUDA 12 的 Novita AI GPU Instance 都能在雲端提供強大且高效的 GPU 運算體驗。
結論
總結來說,在家庭中部署 LLaMA 3.3 70B 極具挑戰性,因為它需要約 35 GB 的高 VRAM,這需要昂貴的硬體,對獨立開發者而言可能不可行。然而,API 存取提供了一個實用的解決方案。透過使用 Novita AI 等雲端服務,開發者無需投資昂貴基礎設施即可使用 LLaMA 3.3 70B,僅需為消耗的資源付費。
常見問題
1. 運行 LLaMA 3.3 70B 所需的最低 VRAM 是多少?
對於 LLaMA 3.3 70B,建議 GPU 至少擁有 24GB VRAM,這有助於載入模型參數並順利執行推論任務。
2. 如何最佳化現有家庭伺服器以滿足 LLaMA 3.3 70B 的需求?
要改善家庭伺服器,重點是升級 GPU 以獲得足夠的 VRAM。您也可以嘗試量化等方法,以降低模型的記憶體使用量,並在現有配置中提升效能。
Novita AI 是全方位的雲端平台,助力您的 AI 願望。藉由無縫整合的 API、無伺服器運算與 GPU 加速,我們提供經濟高效的工具,助您快速打造並擴展 AI 驅動的業務。告別基礎設施煩惱,立即免費開始使用 — Novita AI 讓您的 AI 夢想成真。
推薦閱讀



