

- Destaques Principais
- Explorando os Requisitos de VRAM do LLaMA 3.3 70B
- Como Selecionar uma GPU que Atenda aos Requisitos de VRAM do LLaMA 3.3 70B
- Desafios Técnicos para Servidores Domésticos
- Otimizando Servidores Domésticos para o LLaMA 3.3 70B
- Para Pequenos Desenvolvedores, Usar API para Acessar o LLaMA 3.3 70B Pode Ser Mais Econômico
- Conclusão
- Perguntas Frequentes
Destaques Principais
- Os 70 bilhões de parâmetros do LLaMA 3.3 70B exigem VRAM significativa, mesmo com quantização.
- GPUs como a NVIDIA RTX 3090 ou 4090 são recomendadas para executar o modelo de forma eficaz.
- Servidores domésticos podem enfrentar limitações em termos de VRAM, armazenamento, energia e refrigeração.
- Técnicas de otimização e configuração cuidadosa são cruciais para executar o LLaMA 3.3 70B localmente.
- Desenvolvedores independentes podem reduzir custos usando um serviço de API, como a Novita AI.
O LLaMA 3.3 70B é um modelo de linguagem robusto com desafios de benchmark para pessoas que executam servidores em casa, pois exige muita VRAM. Embora executar modelos de linguagem grandes no seu próprio computador possa oferecer privacidade e formas de personalização, pode ser demais para configurações médias de servidores domésticos. Este post analisará quanta VRAM o LLaMA 3.3 70B precisa e discutirá os problemas técnicos que isso cria para servidores domésticos.
Explorando os Requisitos de VRAM do LLaMA 3.3 70B

O LLaMA 3.3 70B é um modelo de linguagem em grande escala poderoso, com 70 bilhões de parâmetros, projetado para tarefas avançadas de processamento de linguagem natural, oferecendo desempenho impressionante para aplicações complexas de IA.
Requisitos Detalhados de Hardware
Para executar o LLaMA 3.3 70B, você precisa de um bom hardware que funcione bem em conjunto. A GPU, CPU e RAM devem se apoiar mutuamente para fornecer a potência e memória necessárias. Primeiramente, devemos entender o significado dos vários requisitos de hardware.
| Componente | Requisito |
|---|---|
| CPU | Mínimo 8 núcleos |
| RAM | Mínimo 32 GB; Recomendado 64 GB+ |
| VRAM | ~35 GB (quantização de 4 bits); até 141 GB (precisão mais alta) |
| GPU | Série NVIDIA RTX; A100 |
| Armazenamento | ~200 GB |
Comparando Requisitos de VRAM com Modelos Anteriores
O Llama 3.3 70B representa um avanço significativo na eficiência de modelos de IA, pois atinge desempenho comparável a modelos anteriores com centenas de bilhões de parâmetros, reduzindo drasticamente os requisitos de memória da GPU. Especificamente, o Llama 3.3, um modelo da Meta, pode operar com apenas 35 GB de VRAM usando técnicas de quantização, em comparação com os 148 GB exigidos pelo modelo maior Llama 3.1-70B ou 140 GB exigidos pelo Llama 2 70B. Essa otimização permite que os usuários economizem nos custos iniciais de GPU.
|||||
No entanto, apesar dessas melhorias, os custos gerais de implantação permanecem relativamente altos devido à necessidade de hardware avançado, despesas contínuas com eletricidade e pessoal especializado para manutenção e otimização.
Como Selecionar uma GPU que Atenda aos Requisitos de VRAM do LLaMA 3.3 70B
Certifique-se de que a GPU tenha VRAM suficiente para atender às necessidades do modelo. Escolha GPUs que possam gerenciar as tarefas pesadas enquanto permanecem estáveis.
Fatores que Afetam a GPU com o LLaMA 3.3 70B
- Capacidade de VRAM: Uma VRAM maior (pelo menos 24 GB) é crucial para executar modelos grandes como o LLaMA 3.3 70B sem limitações de memória. Mais VRAM garante um desempenho mais suave durante o carregamento do modelo e tarefas de inferência.
- Potência Computacional (TFLOPs): TFLOPs medem a velocidade da GPU em lidar com cálculos complexos. Uma GPU com TFLOPs mais altos pode acelerar a geração de texto e tarefas de aprendizado profundo, resultando em resultados mais rápidos.
- Custo e Compatibilidade: Equilibre o desempenho da GPU com seu orçamento. Verifique também a compatibilidade com seu hardware existente e frameworks de software para garantir uma integração suave em sua configuração.
GPUs Recomendadas para Executar o LLaMA 3.3 70B
Ao escolher uma GPU adequada e considerar várias variantes, leve em conta seu orçamento e nível de desempenho desejado.
Aqui está uma análise das GPUs recomendadas para diferentes necessidades:
| GPU | VRAM | TFLOPs (FP32) | Ideal para | Preço |
|---|---|---|---|---|
| NVIDIA RTX 4090 | 24GB | 82.57 | Configuração de GPU única de alto desempenho | $3.500,00 |
| NVIDIA RTX 3090 | 24GB | 35.58 | Configuração de GPU única ou dupla com boa relação custo-benefício | $1.425,00 |
| Dual NVIDIA RTX 3090 | 48GB | 71.16 | Alto desempenho, permite janelas de contexto maiores e paralelismo de modelo | $2.850,00 |
Para Pequenos Desenvolvedores, Alugar GPUs na Nuvem Pode Ser Mais Econômico
Ao comprar uma GPU, o preço pode ser mais alto. No entanto, alugar uma GPU na Nuvem de GPUs pode reduzir muito seus custos, pois é cobrado conforme a demanda. Assim como a NVIDIA RTX 4090, custa $0,35/hora na Novita AI, que é cobrada de acordo com o tempo de uso, economizando muito quando você não precisa.
Aqui está uma tabela para você:
| Provedor de Serviço | Preço da GPU (por hora) | Observações |
|---|---|---|
| Novita AI | $0.35 | |
| RunPod | $0.69 | Nuvem Segura |
| CoreWeave | Sem serviço |
Desafios Técnicos para Servidores Domésticos

Executar o LLaMA 3.3 70B em um servidor doméstico usando Python pode ser difícil. A maioria dos servidores domésticos não possui recursos suficientes para este modelo de linguagem grande. Você pode primeiro encontrar problemas com VRAM. Depois disso, problemas de armazenamento, energia e refrigeração também podem surgir.
- VRAM e Armazenamento Insuficientes: Um dos maiores desafios em executar o Llama 3.3 70B é a necessidade de VRAM substancial — aproximadamente 35 GB — e espaço de armazenamento amplo. GPUs de alto desempenho como a NVIDIA RTX 3090 ou A100 são frequentemente necessárias, tornando difícil para usuários com hardware padrão atender a essas demandas.
- Requisitos de Energia e Refrigeração: GPUs de alto desempenho consomem uma quantidade significativa de energia, muitas vezes excedendo 600 watts em configurações duais, o que pode sobrecarregar sistemas elétricos domésticos. Além disso, essas GPUs geram calor considerável, exigindo soluções de refrigeração eficazes para evitar superaquecimento, adicionando complexidade à configuração.
- Largura de Banda de Rede e Latência: Executar o Llama 3.3 de forma eficaz requer alta largura de banda de rede e baixa latência. Largura de banda insuficiente pode levar a transmissão lenta de dados e aumento da latência, impactando severamente o desempenho, especialmente em cenários com vários usuários onde respostas em tempo real são críticas.
- Escalabilidade e Configuração Multi-GPU: A escalabilidade representa um desafio significativo ao implantar o Llama 3.3. Embora possa ser executado em uma única GPU, utilizar múltiplas GPUs é necessário para um desempenho ideal. No entanto, configurar um ambiente multi-GPU é complexo e requer hardware compatível, tornando difícil para muitos usuários atingir os níveis de desempenho desejados.
Então, quais são as maneiras de otimizar servidores domésticos?
Otimizando Servidores Domésticos para o LLaMA 3.3 70B
1. Dicas de Configuração para Máxima Eficiência
Certifique-se de manter seu sistema operacional, drivers e frameworks de IA atualizados. Isso ajuda a obter as atualizações de desempenho mais recentes e corrigir bugs. Você também pode considerar o undervolting da sua GPU. Isso significa diminuir um pouco a voltagem da GPU. Pode ajudar a reduzir o consumo de energia e o calor sem diminuir muito o desempenho.
Pense em usar contêineres Docker para criar um espaço separado e fácil de gerenciar para executar o LLaMA 3.3 70B. Isso pode ajudar a gerenciar dependências e evitar problemas de software, tornando sua configuração mais simples de lidar.
2. Gerenciamento de Memória
Mesmo que você tenha uma GPU poderosa, um bom gerenciamento de memória é muito importante ao usar um modelo como o LLaMA 3.3 70B. É fundamental alocar memória bem e usar técnicas de otimização. Um método a experimentar é o gradient checkpointing. Esta técnica é frequentemente usada durante o treinamento, mas também pode ajudar durante a inferência para reduzir o uso de memória. Isso economiza memória, mesmo que leve um pouco mais de tempo para computar.
Além disso, considere usar poda e quantização de modelos de transformadores. Poda significa remover conexões menos importantes no modelo. Isso pode tornar o modelo menor e usar menos memória, geralmente mantendo seu desempenho. Mas para pequenos desenvolvedores, como eles podem reduzir ainda mais os custos enquanto garantem a eficácia do modelo?
Para Pequenos Desenvolvedores, Usar API para Acessar o LLaMA 3.3 70B Pode Ser Mais Econômico
Quando você tiver tentado todos os métodos de otimização e sua aplicação de IA ainda exigir muito custo, é hora de procurar uma opção de API mais econômica.
Como o Acesso por API Reduz Custos de Hardware para o LLaMA 3.3 70B
O acesso por API ao LLaMA 3.3 70B permite que organizações usem o modelo sem investimentos pesados em hardware de alto desempenho, pois podem aproveitar serviços em nuvem como a Novita e pagar apenas pelos recursos computacionais que consomem. Isso reduz significativamente os custos iniciais.
Além disso, os serviços de API frequentemente apresentam escalonamento automático, que ajusta os recursos com base na demanda, evitando o provisionamento excessivo e otimizando a alocação de recursos. A infraestrutura da Novita pode escalar rapidamente para atender à demanda, lidando com atualizações de modelo e escalonamento de dados de forma eficiente offline, garantindo desempenho contínuo sem atrasos.
Novita AI: a Opção Mais Adequada.
Passo 1: Clique em GPU Instance
Se você é um novo assinante, registre-se primeiro em nossa conta. Em seguida, clique no botão [GPU Instance](https://novita.ai/gpus/?utm_source=blogs_gpu&utm_medium=article&utm_campaign= fine-tuning-llama-3-3-70b-with-rtx-4090) em nossa página da web.
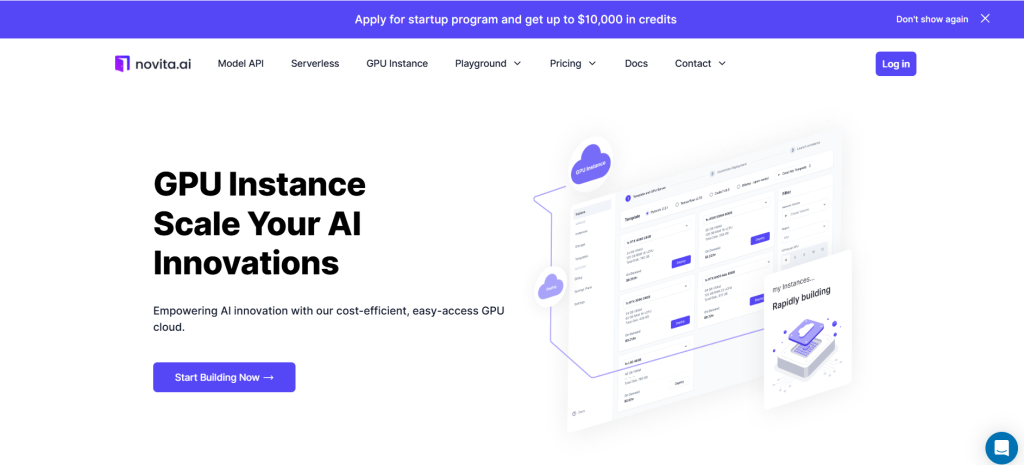
PASSO 2: Template e Servidor GPU
Você pode escolher seu próprio template, incluindo Pytorch, Tensorflow, Cuda, Ollama, de acordo com suas necessidades específicas. Além disso, você também pode criar seus próprios dados de template clicando no último botão. Em seguida, nosso serviço fornece acesso a GPUs de alto desempenho, como a NVIDIA RTX 4090, cada uma com VRAM e RAM substanciais, garantindo que mesmo os modelos de IA mais exigentes possam ser treinados de forma eficiente. Você pode escolher com base em suas necessidades.
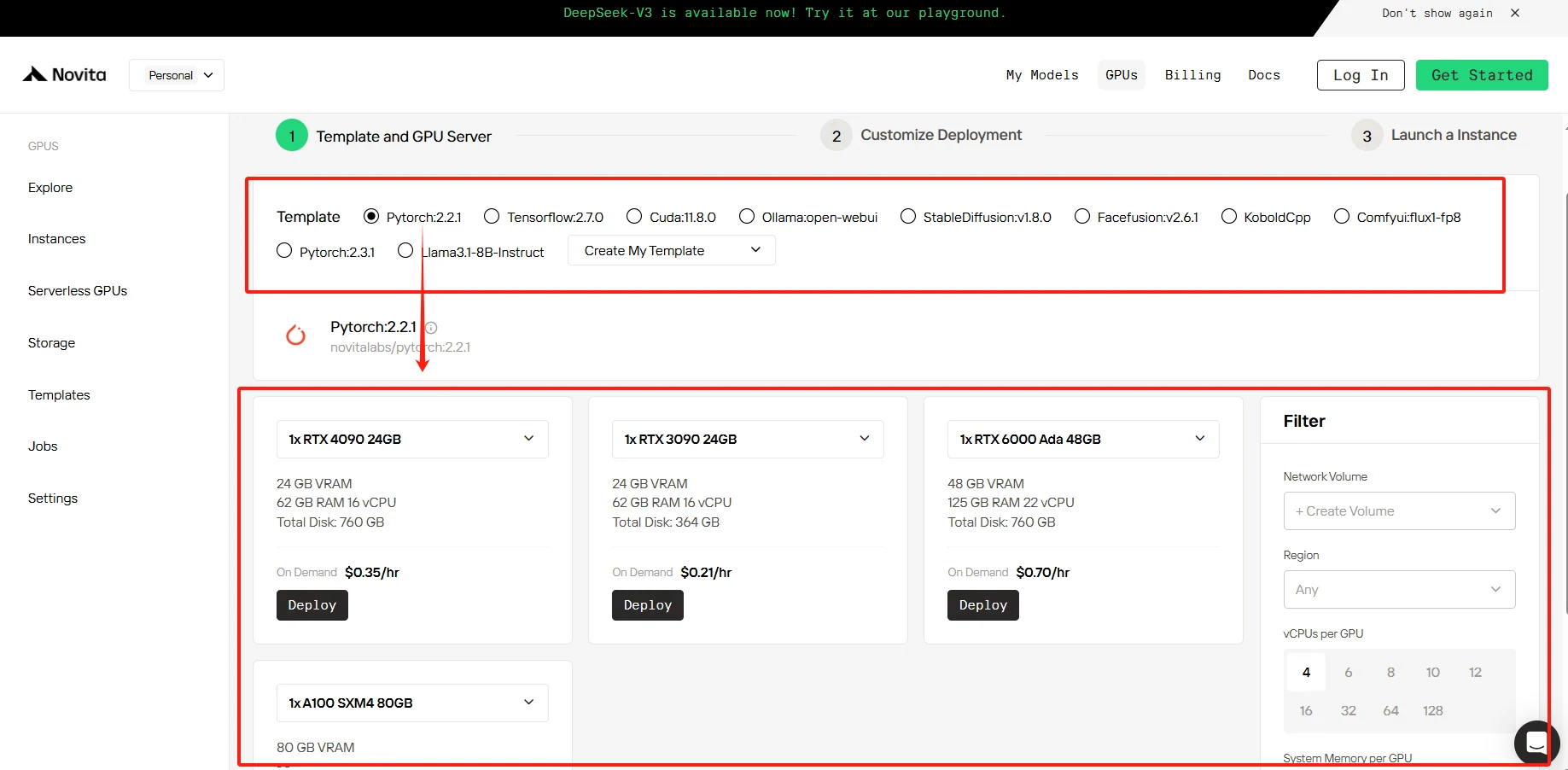
PASSO 3: Personalizar a Implantação
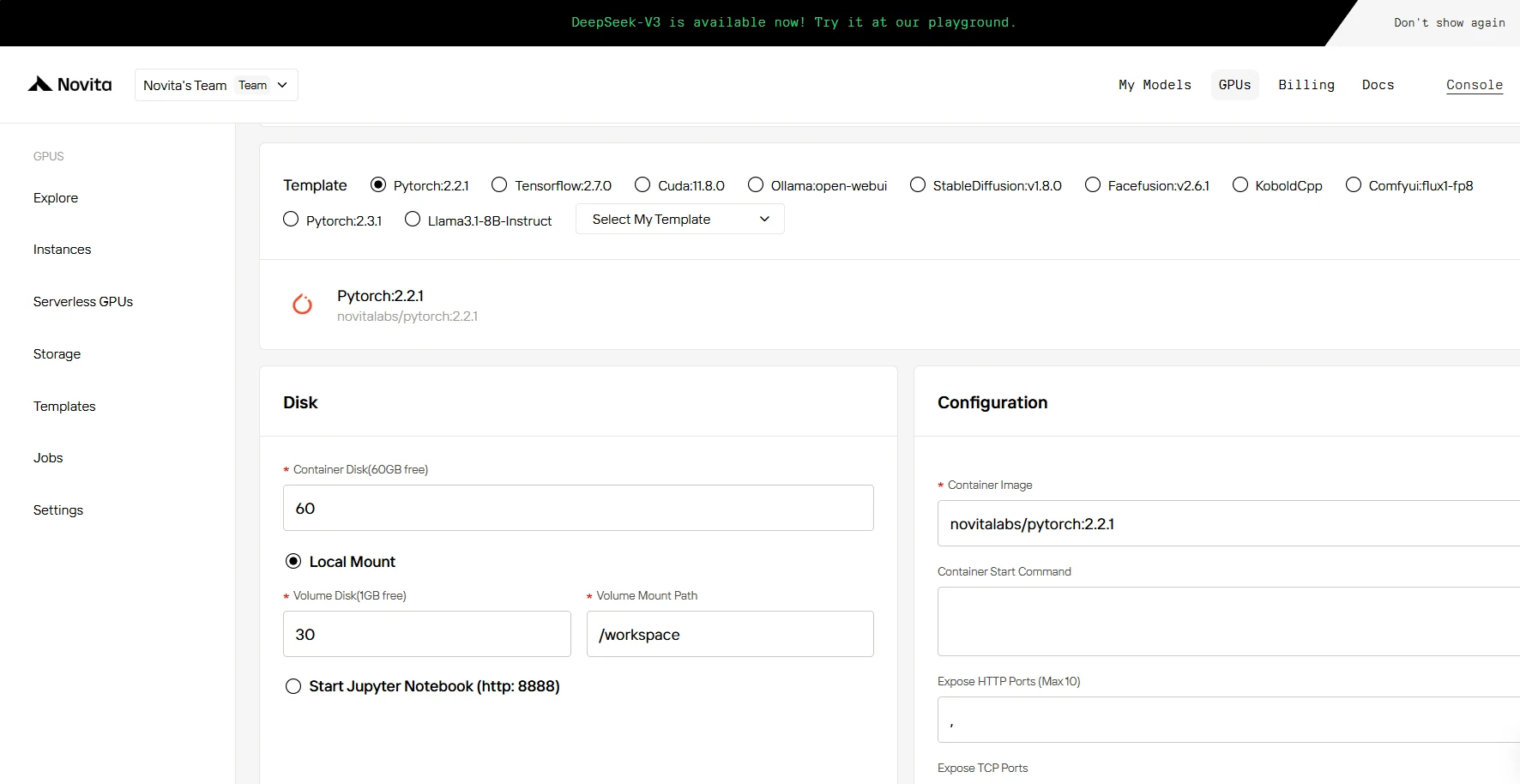
Nesta seção, você pode personalizar esses dados de acordo com suas próprias necessidades. Há 60 GB gratuitos no Container Disk e 1 GB gratuito no Volume Disk; se o limite gratuito for excedido, serão cobradas taxas adicionais.
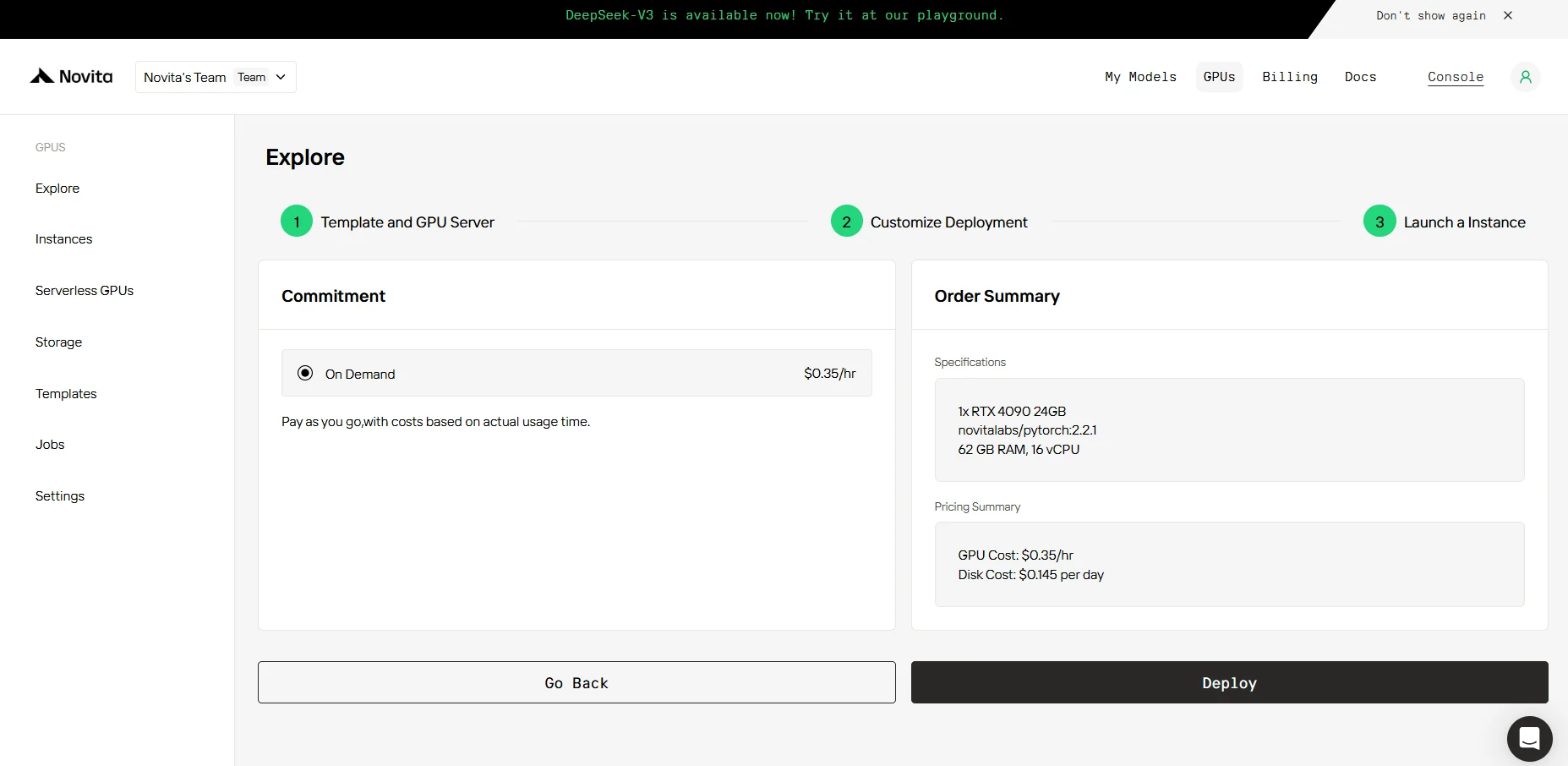
PASSO 4: Iniciar uma instância
Seja para pesquisa, desenvolvimento ou implantação de aplicações de IA, a GPU Instance da Novita AI equipada com CUDA 12 oferece uma experiência de computação GPU poderosa e eficiente na nuvem.
Conclusão
Em conclusão, implantar o LLaMA 3.3 70B em casa é desafiador devido aos seus altos requisitos de VRAM, cerca de 35 GB, que exigem hardware caro que pode não ser viável para desenvolvedores independentes. No entanto, o acesso por API oferece uma solução prática. Ao usar serviços em nuvem, como a Novita AI, os desenvolvedores podem utilizar o LLaMA 3.3 70B sem investir em infraestrutura cara, pagando apenas pelos recursos que consomem.
Perguntas Frequentes
1. Qual é o requisito mínimo de VRAM para executar o LLaMA 3.3 70B?
Para o LLaMA 3.3 70B, é melhor ter pelo menos 24 GB de VRAM em sua GPU. Isso ajuda a carregar os parâmetros do modelo e realizar tarefas de inferência bem.
2. Como posso otimizar meu servidor doméstico existente para atender às demandas do LLaMA 3.3 70B?
Para melhorar seu servidor doméstico, concentre-se em atualizar sua GPU. Isso fornecerá VRAM suficiente. Você também pode tentar métodos como quantização. Isso ajuda a reduzir o uso de memória do modelo e pode impulsionar o desempenho em sua configuração atual.
Novita AI é a plataforma de nuvem tudo-em-um que impulsiona suas ambições de IA. Com APIs perfeitamente integradas, computação serverless e aceleração GPU, fornecemos as ferramentas econômicas que você precisa para construir e escalar rapidamente seu negócio orientado por IA. Elimine as dores de cabeça de infraestrutura e comece gratuitamente - a Novita AI torna seus sonhos de IA realidade.
Leitura Recomendada
1.Quanta Memória RAM o Llama 3.1 70B Usa?
2.Apresentando o Llama3 405B: Lançamentos de LLM Abertamente Disponíveis
3.Llama 3.3 70B: Recursos, Guia de Acesso e Comparação de Modelos



