

隨著 Qwen 3 Coder 480B A35B Instruct 的迅速崛起,許多開發者都迫不及待地想了解在本機執行這個強大模型需要什麼條件。本指南將幫助你了解本地部署所需的硬體(尤其是 VRAM)和技術需求,並與 API 及雲端 GPU 方案進行比較。
什麼是 Qwen 3 Coder 480B A35B Instruct?
Qwen 3 Coder 480B A35B Instruct 是阿里巴巴第三代 Qwen 模型,專為程式碼最佳化,總參數 480B(每次啟用 35B),並經過訓練以遵循使用者指令。
A35B 的意義為何?
- Qwen 3:阿里巴巴 Qwen 大型語言模型的第三代。
- Coder:專精於程式設計和程式碼相關任務。
- 480B:模型總共擁有 4800 億個參數(“B” = billion)。
- A35B:每次推理使用 350 億個「活躍」參數(常見於混合專家模型)。
- Instruct:經過微調以更準確地遵循人類指令或提示。
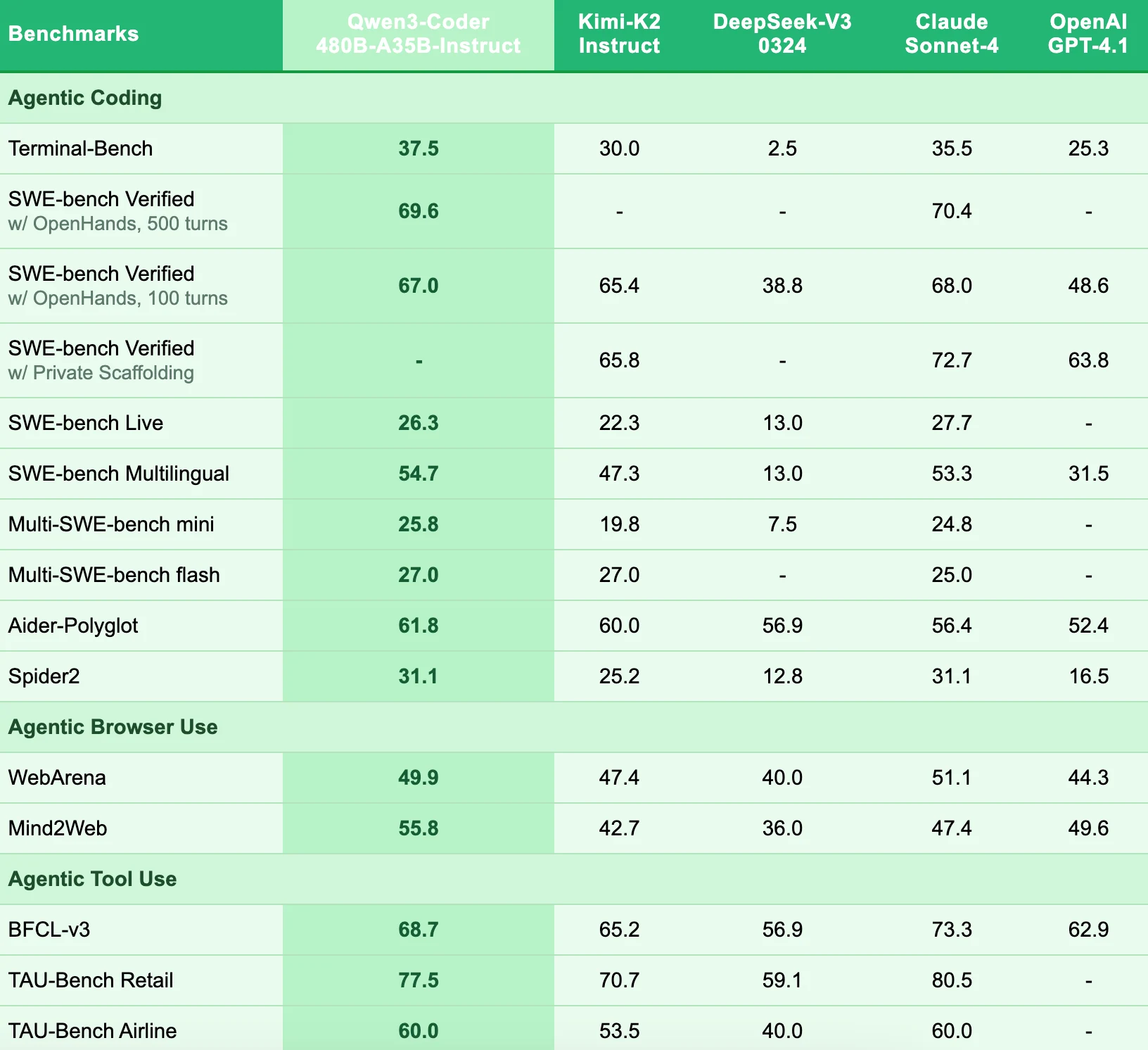
Qwen 3 Coder 480B 架構與評測

指令遵循的優勢
透過大規模混合專家(MoE)架構、廣泛的強化學習(尤其是長時序多輪 RL),以及高品質指令資料的高比例,Qwen 3 Coder 480B 不僅能理解複雜指令,還能自主呼叫工具並進行多步驟規劃,實現真正的代理式、逐步且動態適應的指令遵循——遠遠超越一般程式碼模型的「靜態程式碼生成」典範。

Qwen 3 Coder 480B A35B VRAM
Qwen 3 Coder 推理 VRAM
| 量化方式 | 大小 (GB) | 建議硬體 |
|---|---|---|
| 未量化 (FP16) | 960 | 雲端或大型企業伺服器 |
| Q4_K_M | 290 | 高階伺服器(320GB+ RAM),或 Apple Mac Studio (M4) 512GB |
| unsloth Q4_K_XL | 276 | 類似 Q4_K_M,或多 GPU 配置:12-13 張 RTX 3090/4090,9-10 張 RTX 5090,或 3 張 Blackwell RTX Pro 6000 |
| unsloth Q2_K_XL | 180 | Apple Mac M2 Ultra 192GB 統一記憶體 |
| Q3_K_L | 115 | 桌上型電腦配備 24GB VRAM GPU 與 128GB+ 系統 RAM |
Qwen 3 Coder 微調 VRAM
| 量化類型 | 模型大小 (GB) |
|---|---|
| FP32 | 9281.92 |
| BF16 | 6706.92 |
| FP8 | 5419.42 |
Qwen 3 Coder 最低 VRAM
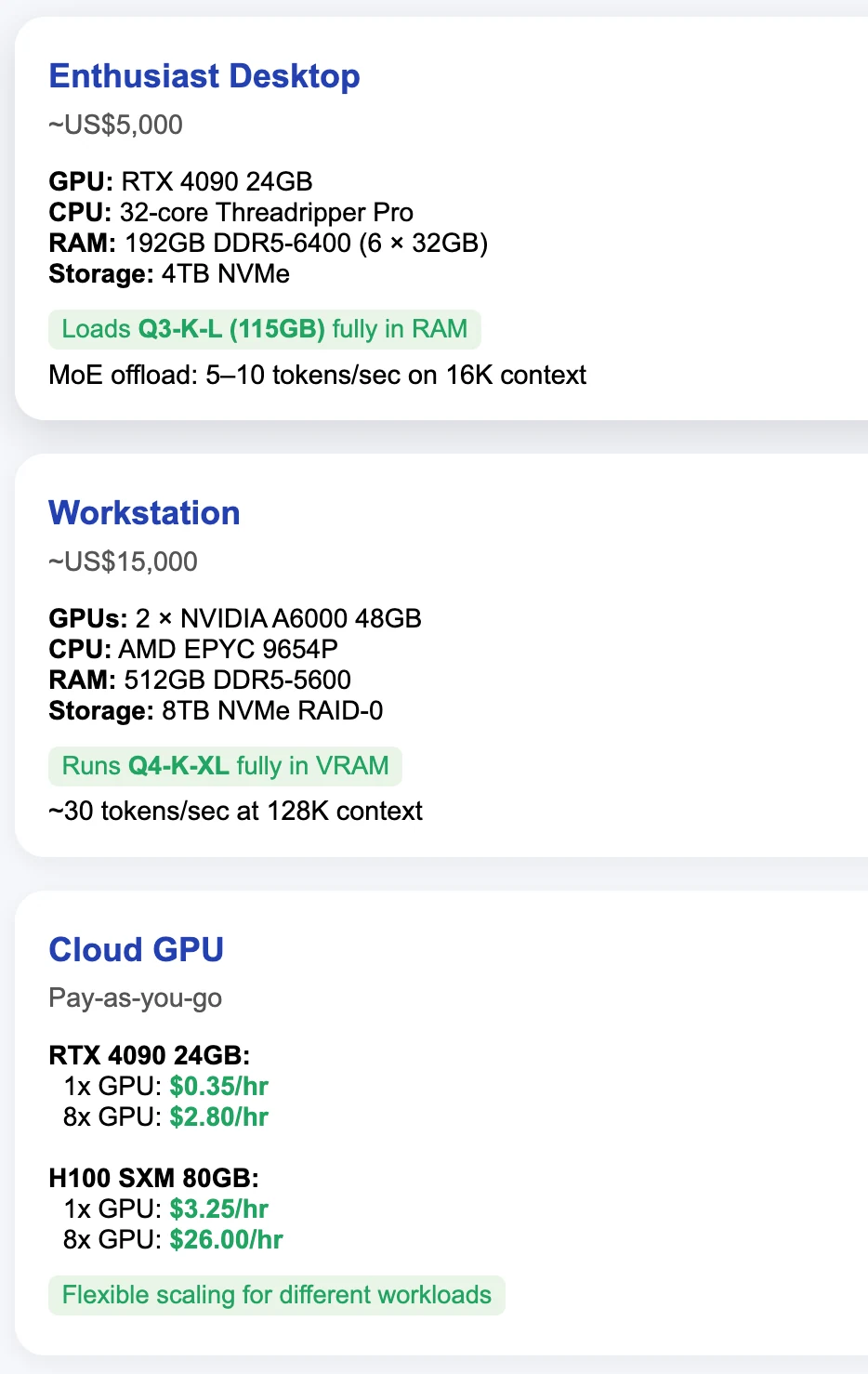
節省記憶體的小技巧
-
選擇性 GPU 卸載:
- 將路由器和自注意力層留在 GPU 上以保持速度,同時使用正規表示式遮罩從系統 RAM 串流較大的專家前饋(FFN)權重。這能在效能與記憶體使用之間取得平衡。
-
動態 2 位元量化:
- Unsloth Dynamic Q2-K-XL 使用自適應 2 位元量化,約可保留原始模型 98% 的準確度,同時將記憶體需求減半。
-
KV 快取量化:
- 使用如
--cache-type-k q4_1 --cache-type-v q4_1等選項,可將鍵值快取的大小縮減四倍,模型效能損失低於 1 個困惑度(pp)。
- 使用如
-
Flash Attention 與高吞吐模式:
- 使用
-DGGML_CUDA_FA_ALL_QUANTS=ON編譯llama.cpp,為所有量化類型啟用高效的 Flash Attention。使用llama-parallel支援高吞吐的多用戶推理。
- 使用
-
上下文截斷:
- 對於聊天機器人應用,將對話歷史限制在 8,000–16,000 個 token。每增加 32,000 個 token,FP16 KV 快取記憶體使用量約增加 6 GB。
-
批次處理:
- 在單次前向傳遞中處理多個請求。vLLM 和 llama.cpp 的高吞吐模式等解決方案,透過分攤路由器開銷來有效服務多個使用者。
VRAM 使用量比較
| 功能 | Qwen3 Coder 480B A35B Instruct | DeepSeek V3 0324 | Kimi K2 |
|---|---|---|---|
| GPU 型號 | H100 | H100 | H100 |
| 使用的 GPU 數量 | 12 GPU | 24 GPU | 32 GPU |
| 總價格 | 每張 GPU 從 NVIDIA 直接購買 $30000 | 每張 GPU 從 NVIDIA 直接購買 $30000 | 每張 GPU 從 NVIDIA 直接購買 $30000 |
| 雲端 GPU 價格 (Novita AI) | $30.72/hr | $61.44/hr | $81.92/hr |
另一個有效的方法:使用 API
Novita AI 提供 Qwen3 Coder 480B A35B Instruct API,具備 **262K 上下文 **、**66K 最大輸出 **、**6.82 秒延遲 **、**76.35 TPS 吞吐量 **,費用為 **$0.95/輸入 ** 和 $5/輸出,為最大化 Qwen 3 的程式碼代理潛力提供強力支援。
Novita AI
| 面向 | API | 本機 GPU | 雲端 GPU |
|---|---|---|---|
| 設定 | 即時 | 複雜 | 中等 |
| 維護 | 無 | 高 | 中等 |
| 成本 | 最高/單位 | 最低(大規模) | 中等 |
| 可擴展性 | 自動 | 困難 | 容易 |
| 隱私 | 資料傳出 | 完全本機 | 資料傳出 |
| 自訂性 | 最低 | 最高 | 高 |
| 最適合 | 快速啟動、中小規模、無基礎架構 | 大型穩定工作負載、最大隱私 | 大型/變動工作負載、自訂模型 |
步驟 1:登入你的帳戶,然後點選「模型庫」按鈕。

步驟 2:選擇你的模型
瀏覽可用選項,選擇符合你需求的模型。
步驟 3:開始免費試用
開始免費試用,探索所選模型的能力。
步驟 4:取得你的 API 金鑰
為了驗證 API,我們將提供一個新的 API 金鑰。進入「設定」頁面,你可以按照圖片指示複製 API 金鑰。

步驟 5:安裝 API
使用程式語言專用的套件管理器安裝 API。
安裝後,將必要的函式庫匯入你的開發環境。使用你的 API 金鑰初始化 API,開始與 Novita AI LLM 互動。以下是 Python 使用者使用聊天補全 API 的範例。
pip install 'openai>=1.0.0'
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 131072
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen 3 Coder 480B A35B Instruct 為程式碼導向的大型語言模型樹立了新標竿,但若想在本機執行,也伴隨著顯著的硬體需求。對大多數使用者而言,直接使用 API 或租用雲端 GPU 是體驗其能力最快的方式,而擁有先進基礎設施的大型企業則可以考慮本機部署。仔細權衡你的需求、預算和技術資源,選擇最佳方式來發揮 Qwen 3 Coder 的強大力量。
常見問題
什麼是 Qwen 3 Coder 480B A35B Instruct?
它是阿里巴巴第三代、專精於程式碼的 AI 模型,擁有 4800 億個參數(每次推理啟用 350 億),專為精確且複雜的指令遵循而設計。
「A35B」是什麼意思?
它代表每次推理時使用的「活躍 350 億」參數,得益於混合專家(MoE)架構。
如何快速試用 Qwen 3 Coder?
註冊 Novita AI 等提供商,取得你的 API 金鑰,然後使用簡單的 Python 程式碼開始發送請求——無需硬體或設定。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 來部署 AI 模型,同時也提供價格實惠且可靠的 GPU 雲端服務,用於建置和擴展應用。



