

مع الانتشار السريع لـ Qwen 3 Coder 480B A35B Instruct، يتوق العديد من المطورين لمعرفة ما يلزم لتشغيل هذا النموذج القوي محليًا. سيساعدك هذا الدليل على فهم متطلبات الأجهزة (خاصة VRAM) والمتطلبات التقنية للنشر المحلي، ومقارنتها مع خيارات API وGPU السحابي.
ما هو Qwen 3 Coder 480B A35B Instruct؟
Qwen 3 Coder 480B A35B Instruct هو نموذج الجيل الثالث من Alibaba، مُحسَّن للبرمجة، بإجمالي 480 مليار معلمة (35 مليار نشطة في المرة الواحدة)، ومُدرَّب على اتباع تعليمات المستخدم.
ماذا يعني A35B؟
- Qwen 3: الجيل الثالث من نماذج اللغة الكبيرة لشركة Alibaba.
- Coder: مُتخصص في البرمجة والمهام المتعلقة بالكود.
- 480B: إجمالي 480 مليار معلمة في النموذج (حيث “B” = مليار).
- A35B: 35 مليار معلمة “نشطة” تُستخدم لكل استدلال (شائع في نماذج خبراء الخليط).
- Instruct: مُضبط بدقة لاتباع تعليمات البشر أو الأوامر بدقة أكبر.
بنية Qwen 3 Coder 480B والمقاييس

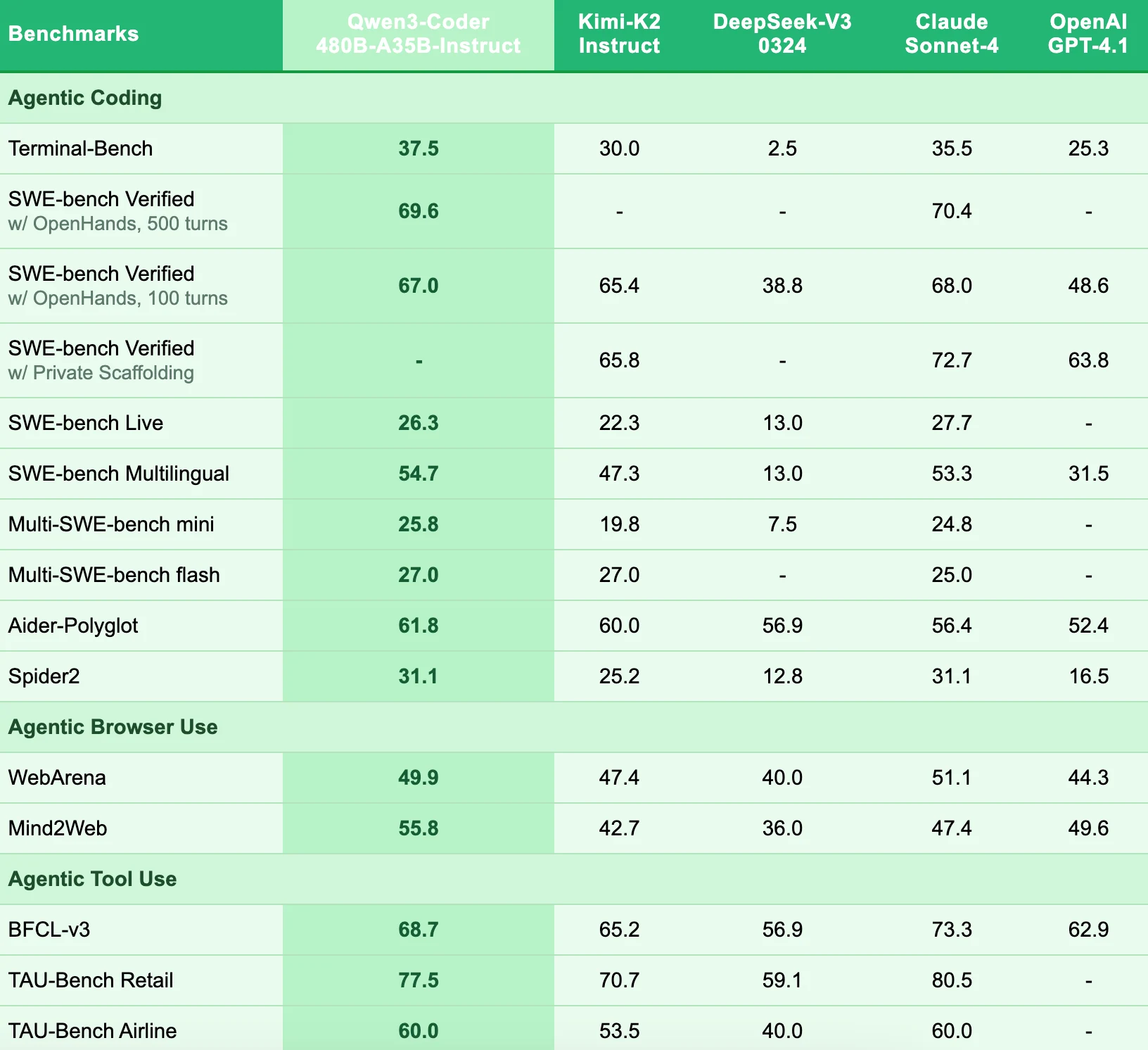
مزايا اتباع التعليمات
من خلال بنية خبراء الخليط (MoE) واسعة النطاق، والتعلم المعزز الشامل (خاصة التعلم المعزز متعدد الأدوار طويل الأمد)، ونسبة عالية من بيانات التعليمات عالية الجودة، لا يفهم Qwen 3 Coder 480B التعليمات المعقدة فحسب، بل يمكنه أيضًا استدعاء الأدوات بشكل مستقل والتخطيط عبر خطوات متعددة، محققًا اتباعًا حقيقيًا للتعليمات بشكل وكيل وخطوة بخطوة وقابل للتكيف ديناميكيًا - وهو ما يتجاوز بكثير نموذج “توليد الكود الثابت” لنماذج البرمجة النموذجية.

ذاكرة VRAM لـ Qwen 3 Coder 480B A35B
ذاكرة VRAM للاستدلال باستخدام Qwen 3 Coder
| نوع التكميم | الحجم (GB) | الأجهزة الموصى بها |
|---|---|---|
| غير مقسم (FP16) | 960 | خوادم سحابية أو خوادم مؤسسية كبيرة |
| Q4_K_M | 290 | خادم عالي الأداء مع 320GB+ من RAM، أو Apple Mac Studio (M4) 512GB |
| unsloth Q4_K_XL | 276 | مشابه لـ Q4_K_M، أو إعدادات متعددة GPUs: 12-13x RTX 3090/4090، 9-10x RTX 5090، أو 3x Blackwell RTX Pro 6000 |
| unsloth Q2_K_XL | 180 | Apple Mac M2 Ultra مع 192GB من الذاكرة الموحدة |
| Q3_K_L | 115 | كمبيوتر مكتبي مع GPU سعة 24GB VRAM و 128GB+ من RAM النظام |
ذاكرة VRAM لضبط دقيق لـ Qwen 3 Coder
| نوع التكميم | حجم النموذج (GB) |
|---|---|
| FP32 | 9281.92 |
| BF16 | 6706.92 |
| FP8 | 5419.42 |
الحد الأدنى من VRAM لـ Qwen 3 Coder
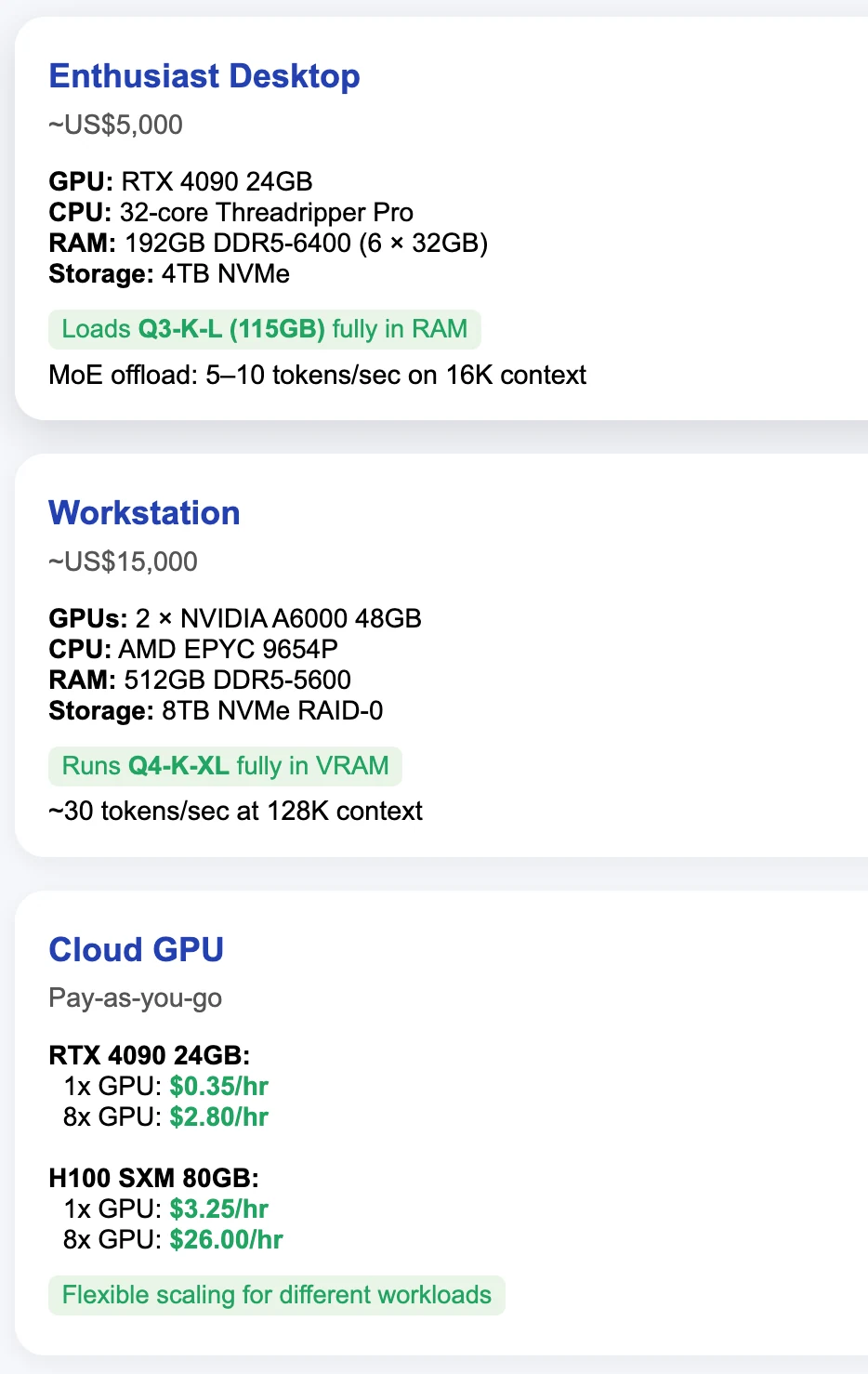
نصائح لتوفير الذاكرة
-
تفريغ GPU انتقائي:
- احتفظ بطبقات التوجيه والانتباه الذاتي على GPU للسرعة، مع دفق أوزان التغذية الأمامية (FFN) الأكبر للمستخدمين من RAM النظام باستخدام التصفية القائمة على regex. هذا يوازن بين الأداء واستهلاك الذاكرة.
-
التكميم الديناميكي ثنائي البت:
- يستخدم Unsloth Dynamic Q2-K-XL تكميمًا تكيفيًا ثنائي البت، يحافظ على حوالي 98٪ من دقة النموذج الأصلي، مع تقليل متطلبات الذاكرة إلى النصف.
-
تكميم ذاكرة التخزين المؤقت KV:
- استخدام خيارات مثل
--cache-type-k q4_1 --cache-type-v q4_1يقلل حجم ذاكرة التخزين المؤقت للمفاتيح والقيم بمقدار أربع مرات، مع فقدان أقل من نقطة واحدة في معامل الحيرة (pp) في أداء النموذج.
- استخدام خيارات مثل
-
الانتباه السريع ووضع الإنتاجية العالية:
- قم بتجميع
llama.cppمع-DGGML_CUDA_FA_ALL_QUANTS=ONلتمكين الانتباه السريع (Flash-Attention) الفعال لجميع أنواع التكميم. استخدمllama-parallelلدعم استدلال متعدد المستخدمين بإنتاجية عالية.
- قم بتجميع
-
تحديد السياق:
- بالنسبة لتطبيقات chatbot، حدد تاريخ المحادثة إلى 8,000–16,000 رمزًا. كل 32,000 رمز إضافي يزيد استخدام ذاكرة التخزين المؤقت KV بنمط FP16 بحوالي 6 جيجابايت.
-
التجميع:
- معالجة طلبات متعددة في تمرير أمامي واحد. تساعد حلول مثل vLLM وأوضاع الإنتاجية العالية في
llama.cppفي خدمة العديد من المستخدمين بكفاءة من خلال توزيع تكلفة التوجيه.
- معالجة طلبات متعددة في تمرير أمامي واحد. تساعد حلول مثل vLLM وأوضاع الإنتاجية العالية في
مقارنة استخدام VRAM
| الميزة | Qwen3 Coder 480B A35B Instruct | DeepSeek V3 0324 | Kimi K2 |
|---|---|---|---|
| طراز GPU | H100 | H100 | H100 |
| عدد GPUs المستخدمة | 12 GPU | 24 GPU | 32 GPU |
| السعر الإجمالي | 30000 دولار لكل GPU مباشرة من NVIDIA | 30000 دولار لكل GPU مباشرة من NVIDIA | 30000 دولار لكل GPU مباشرة من NVIDIA |
| سعر GPU السحابي (Novita AI) | 30.72 دولار/ساعة | 61.44 دولار/ساعة | 81.92 دولار/ساعة |
طريقة فعالة أخرى: استخدام API
توفر Novita AI واجهات برمجة تطبيقات Qwen3 Coder 480B A35B Instruct مع سياق 262 ألفًا، خرج أقصى 66 ألفًا، زمن انتقال 6.82 ثانية، إنتاجية 76.35 TPS، وتكاليف 0.95 دولار/إدخال و5 دولارات/إخراج، مما يوفر دعمًا قويًا لتعظيم إمكانات وكيل الكود الخاص بـ Qwen 3.
Novita AI
| الجانب | API | GPU محلي | GPU سحابي |
|---|---|---|---|
| الإعداد | فوري | معقد | معتدل |
| الصيانة | لا شيء | عالية | متوسطة |
| التكلفة | الأعلى/وحدة | الأدنى (على نطاق واسع) | متوسطة |
| قابلية التوسع | تلقائية | صعبة | سهلة |
| الخصوصية | البيانات تخرج | محلية بالكامل | البيانات تخرج |
| التخصيص | الأقل | الأكثر | عالية |
| الأفضل لـ | بداية سريعة، صغير/متوسط، بدون بنية تحتية | أحمال عمل كبيرة ومستقرة، أقصى خصوصية | أحمال عمل كبيرة/متغيرة، نماذج مخصصة |
الخطوة 1: سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ النسخة التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف إمكانيات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للتوثيق مع API، سنوفر لك مفتاح API جديد. عند الدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: قم بتثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك.
بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام واجهة chat completions API لمستخدمي Python.
pip install 'openai>=1.0.0'
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 131072
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
يضع Qwen 3 Coder 480B A35B Instruct معيارًا جديدًا لنماذج اللغة الكبيرة المُركزة على الكود، ولكنه يأتي أيضًا مع متطلبات أجهزة كبيرة إذا كنت ترغب في تشغيله محليًا. بالنسبة لمعظم المستخدمين، يعد الوصول المباشر إلى API أو استئجار GPU سحابي أسرع طريقة لتجربة إمكانياته، بينما يمكن للمؤسسات الكبيرة ذات البنية التحتية المتقدمة التفكير في النشر المحلي. قم بتقييم احتياجاتك وميزانيتك ومواردك التقنية بعناية لاختيار أفضل طريقة لتسخير قوة Qwen 3 Coder.
الأسئلة المتداولة
ما هو Qwen 3 Coder 480B A35B Instruct؟
إنه نموذج الذكاء الاصطناعي من الجيل الثالث لشركة Alibaba والمتخصص في الكود، مع 480 مليار معلمة (35 مليار نشطة لكل استدلال)، مصمم لاتباع التعليمات المعقدة بدقة.
ماذا يعني “A35B”؟
يعني “35 مليار نشطة” من المعلمات المستخدمة خلال كل استدلال، وذلك بفضل بنية خبراء الخليط (Mixture-of-Experts).
كيف يمكنني تجربة Qwen 3 Coder بسرعة؟
قم بالتسجيل في مزود مثل Novita AI واحصل على مفتاح API الخاص بك وابدأ في إرسال الطلبات باستخدام كود Python بسيط - لا حاجة لأي أجهزة أو إعداد.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة API بسيطة، مع توفير GPU سحابي بأسعار معقولة وموثوق لبناء وتوسيع النطاق.



