

Novita AI 正在推出「Build Month」活動,為開發者提供所有主力產品最高 20% 的專屬優惠!
部署大型多模態模型對開發者而言仍充滿挑戰,原因包括高昂的基礎設施成本、複雜的部署流程,以及效能、精度與資源消耗之間難以取捨的權衡。這些挑戰在先進的視覺語言模型(如 GLM-4.6V)上尤為明顯,該模型需要大量的 VRAM、長上下文支援,以及視覺感知與工具執行之間的緊密整合。
本文將針對這些痛點,系統性地說明 GLM-4.6V 的架構創新、原生多模態函式呼叫機制、實用的 VRAM 與量化策略,以及在 Novita AI 雲端 GPU 上的低成本部署路徑。透過結合模型層級的洞察與具體的部署、計費指引,本文能協助開發者在構建、部署和擴展基於 GLM-4.6V 的應用程式時做出明智的決策。
GLM 4.6V 的高效能與高表現
GLM-4.6V 可將視覺張量直接傳入觸發函式呼叫的推理層,這表示模型實際上會在其潛在空間中「點擊」對應的圖像區域。這項能力由擴展版的 模型上下文協議(Model Context Protocol, MCP) 驅動,該協議標準化了視覺上下文傳遞給外部工具的流程。
原生多模態函式呼叫機制
| 傳統流程(視覺→文字→工具) | GLM-4.6V 流程(視覺→工具) |
|---|---|
| 步驟 1: 編碼圖像 → 向量 | 步驟 1: 編碼圖像 → 多模態向量 |
| 步驟 2: 向量 → 文字描述(「一個紅色方框」) | 步驟 2: 向量 → 直接路由器 |
| 步驟 3: 文字 → 邏輯 → 工具呼叫 | 步驟 3: 路由器 → 可執行動作 |
| 延遲: 高(文字生成開銷) | 延遲: 降低 37% |
| 精度: 低(語義近似) | 精度: 高(坐標級精度) |
| 成功率: 中等 | 成功率: 提升 18% |
視覺反饋迴圈與自我修正
GLM-4.6V 的設計靈感來自智譜 AI 的 UI2Code^N 研究,它針對視覺任務實現了強化學習(RL)迴圈,這個流程模擬了人類的「執行、檢查、修正」工作流:
- 執行: 模型根據視覺提示生成程式碼(例如網站的 HTML)。
- 觀察: 模型呼叫渲染工具,將自己生成的程式碼可視化。
- 審核: 模型使用其視覺編碼器,將渲染結果與原始目標圖像進行比對。
- 修正: 模型檢測出差異(例如「按鈕的內距太小」),並反覆迭代優化程式碼。
這項「視覺審核」能力是 GLM-4.6V 能實現像素級前端複製的關鍵,也讓它與那些 essentially 根據文字描述「猜測」CSS 的模型區分開來。
上下文視窗動態特性
128,000 標記的上下文視窗是企業工作流的關鍵功能。從實際應用角度來看,這項容量可以實現:
- 文件分析: 單次處理包含複雜圖表和表格的 150 頁財務報告。
- 影片理解: 分析 1 小時的影片檔案(例如講座或監控錄影),提取特定事件或摘要。
- 程式碼庫理解: 讀取整個儲存庫的文件和核心檔案,執行架構重構。
與純文字模型僅以詞數計算「長上下文」不同,在視覺語言模型(VLM)中,這個視窗必須容納視覺嵌入的大量標記佔用。GLM-4.6V 採用「視覺-語言壓縮對齊」技術(靈感來自 Glyph)來壓縮視覺標記,確保高解析度圖像不會過早耗盡上下文視窗的容量。
GLM 4.6V 的開發者生態系
GLM-4.6V 是最早原生支援擴展版模型上下文協議(MCP)的模型之一,該協議作為 AI 模型與整合開發環境(IDE)之間的標準化「握手協議」。
| 能力 | 描述 |
|---|---|
| 一鍵整合 | 只需少於 10 行設定,即可將 GLM-4.6V 連接至 VS Code 或 Cursor。 |
| 上下文感知 | 模型會自動接收檔案樹、開啟的分頁和終端機狀態作為上下文。 |
| 視覺拖放 | 開發者可將截圖拖入 IDE,模型會自動生成對應的前端程式碼組件。 |
| 本地部署 | MCP 伺服器可指向本地 vLLM 實例,確保專有程式碼完全離線運行。 |
GLM 4.6V 的 VRAM 需求與量化策略
雖然 GLM-4.6V 的活躍參數量較低(120 億),但權重的儲存需求仍然很高(1060 億)。要以原生精度(FP16)搭配完整上下文視窗運行完整模型,需要企業級叢集。不過,結合激進量化(INT4)與 MoE 卸載(將專家參數儲存在系統記憶體中,依需求調入 GPU VRAM),即可讓模型在專業級工作站上運行,僅會略微降低推理速度。
| 模型變體 | 精度 | 上下文長度 | VRAM 估算 | 推薦硬體配置 |
|---|---|---|---|---|
| GLM-4.6V (106B) | FP16 / BF16 | 128K(完整) | 640 GB - 720 GB | 8 張 H100(80GB)或 8 張 A100(80GB) |
| GLM-4.6V (106B) | FP16 / BF16 | 短(推理用) | 96 GB - 120 GB | 2 張 A6000(48GB)或 4 張 RTX 3090/4090 |
| GLM-4.6V (106B) | FP8(量化後) | 128K | 320 GB | 4 張 H100(80GB) |
| GLM-4.6V (106B) | INT4(量化後) | 短 | 64 GB | 1 張 A100(80GB)或 3 張 RTX 3090/4090 |
| GLM-4.6V-Flash (9B) | FP16 | 128K | 24 GB | 1 張 RTX 3090/4090(24GB) |
| GLM-4.6V-Flash (9B) | INT4 | 短 | 6-8 GB | RTX 3060 / 筆電 GPU |
使用 vLLM 與 Docker 部署
對於選擇自行部署的開發者,vLLM 是推薦的推理引擎,因其支援張量並行(Tensor Parallelism, TP)與連續批處理(continuous batching)。
部署配置(Docker)
要在 4 張 GPU 的環境下使用 vLLM 部署 106B 模型,請使用以下配置模式。請注意 GLM-4.5/4.6 架構的專用參數(--tool-call-parser、--enable-expert-parallel)。
關鍵參數:
--tensor-parallel-size 4:將模型分散到 4 張 GPU 上運行,是將 106B 權重裝入記憶體的必備設定。--tool-call-parser glm45:啟動 GLM 原生函式呼叫格式的專用解析邏輯。--enable-expert-parallel:優化 MoE 專家參數在設備間的分佈,平衡計算負載。--max-model-len:控制上下文視窗大小。若硬體允許,可將此值設為65536或128000,用於定義 KV 快取的記憶體緩衝區。
透過雲端 GPU 更高效且低成本存取 GLM 4.6V 的方法
Novita AI 提供四種 GPU 計費模式,以滿足不同工作负载模式與成本需求。
計費模式 計費方式 資源可用性 成本等級 中斷風險 典型使用場景 隨需應變(Pay-as-you-go) 按實際運行時間計費(每秒或每小時) 高,可隨時啟動或停止實例 中 無 開發與測試、模型除錯、變動或不可預測的工作负载 搶占式實例 以折扣價按運行時間計費 中,取決於可用閒置容量 低(通常比隨需應變便宜約 50%) 是,實例可能被搶占 批次作業、離線推理、容錯訓練、成本敏感的工作负载 訂閱 / 預留方案 固定月費或年費計費 高,專屬且可預測的資源 中低(比隨需應變便宜) 無 長期穩定工作负载、生產系統、持續訓練或推理 無伺服器 GPU 計費 按每次執行實際消耗的運算資源計費 自動隨需求擴展 低至中(僅為實際使用量付費) 無(平台全托管) 事件驅動推理、突發流量、基於 API 的模型服務、極低運維開費
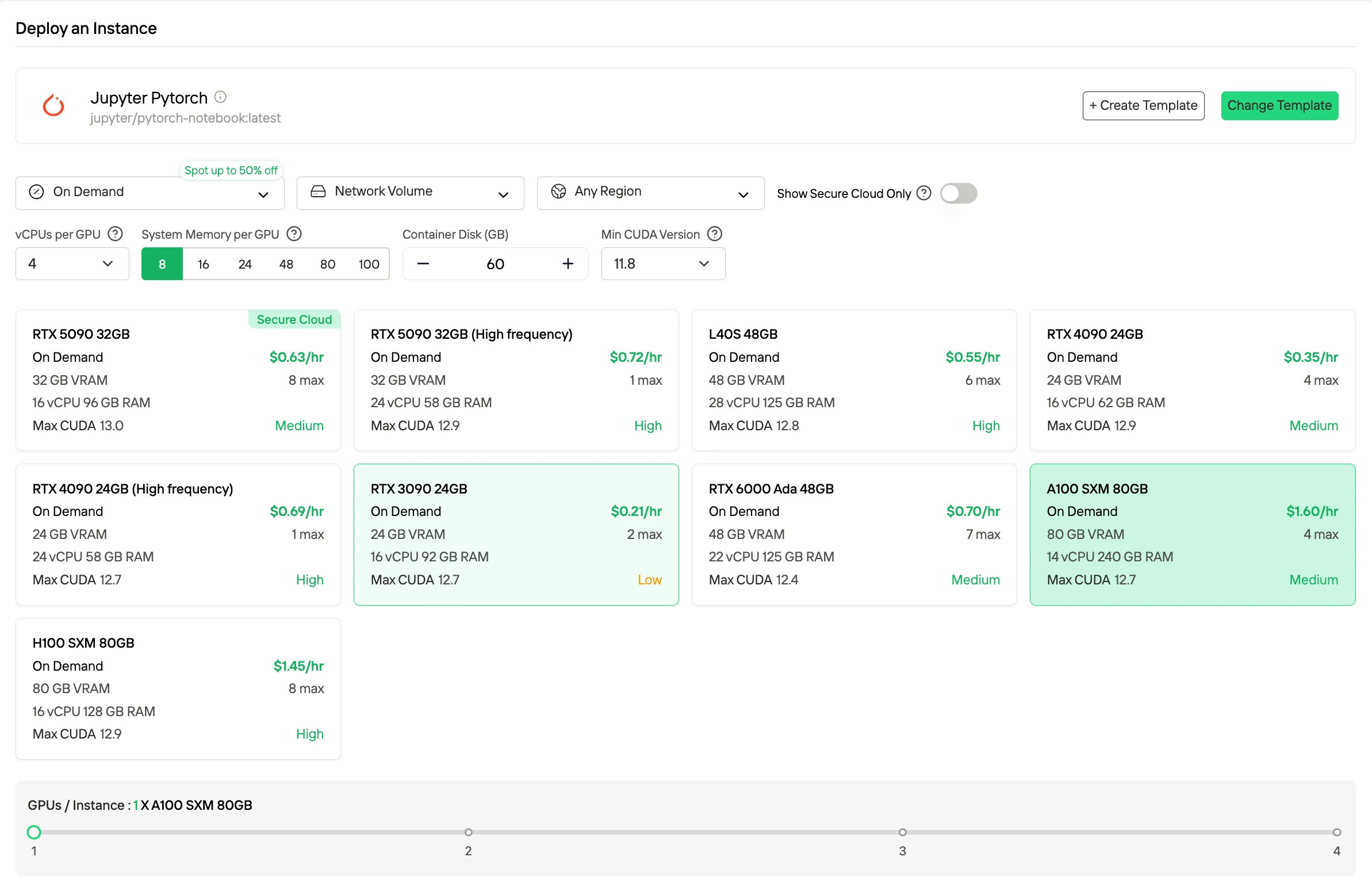
1. 隨需應變(Pay-as-you-go)
隨需應變是標準的消費模式,GPU 運算資源嚴格按運行時間計費,通常以每秒或每小時為單位,無需長期承諾或預留。它提供最大的靈活性,非常適合變動型工作负载、間歇性使用和早期實驗,因為僅在實例運行時才會產生費用。儲存和輔助資源(包括磁碟和網路)也按使用量計費。
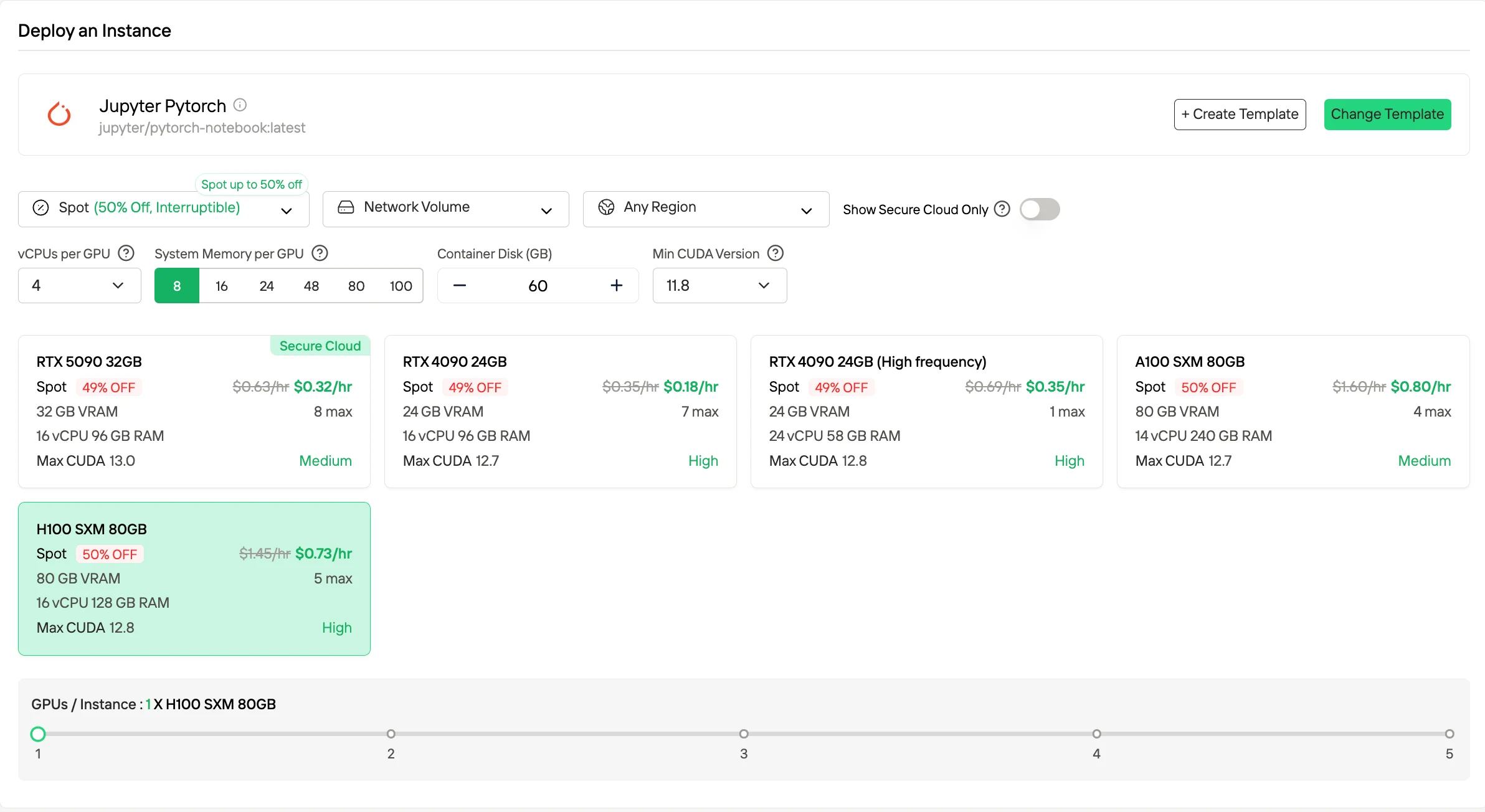
2. 搶占式實例
搶占式實例透過利用閒置的 GPU 容量,提供大幅降低的每小時價格,通常比隨需應變費率便宜約 50%。這類實例可能被平台搶占。Novita 透過提供 1 小時的保護窗口和提前終止通知來降低此風險。這種計費模式適合容錯或批次工作负载,可接受偶爾的運行中斷。
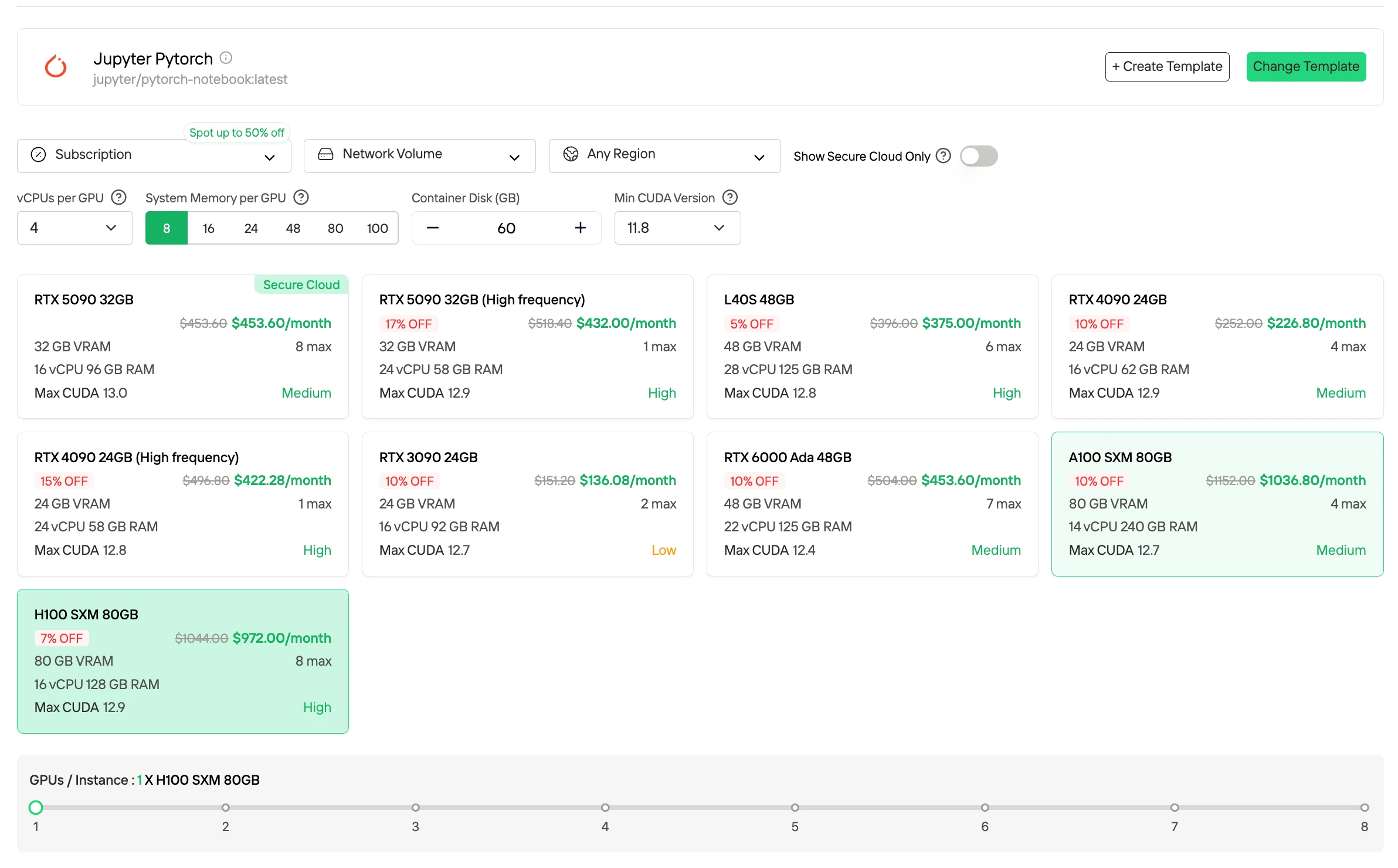
3. 訂閱 / 預留方案
訂閱和預留方案提供月費或年費選項,提供專屬且可用性可預測的 GPU 資源。與隨需應變計費相比,這些方案通常以更低的有效單位成本換取更長的承諾期限,最適合需要穩定運算資源的穩定、持續性工作负载和生產環境。
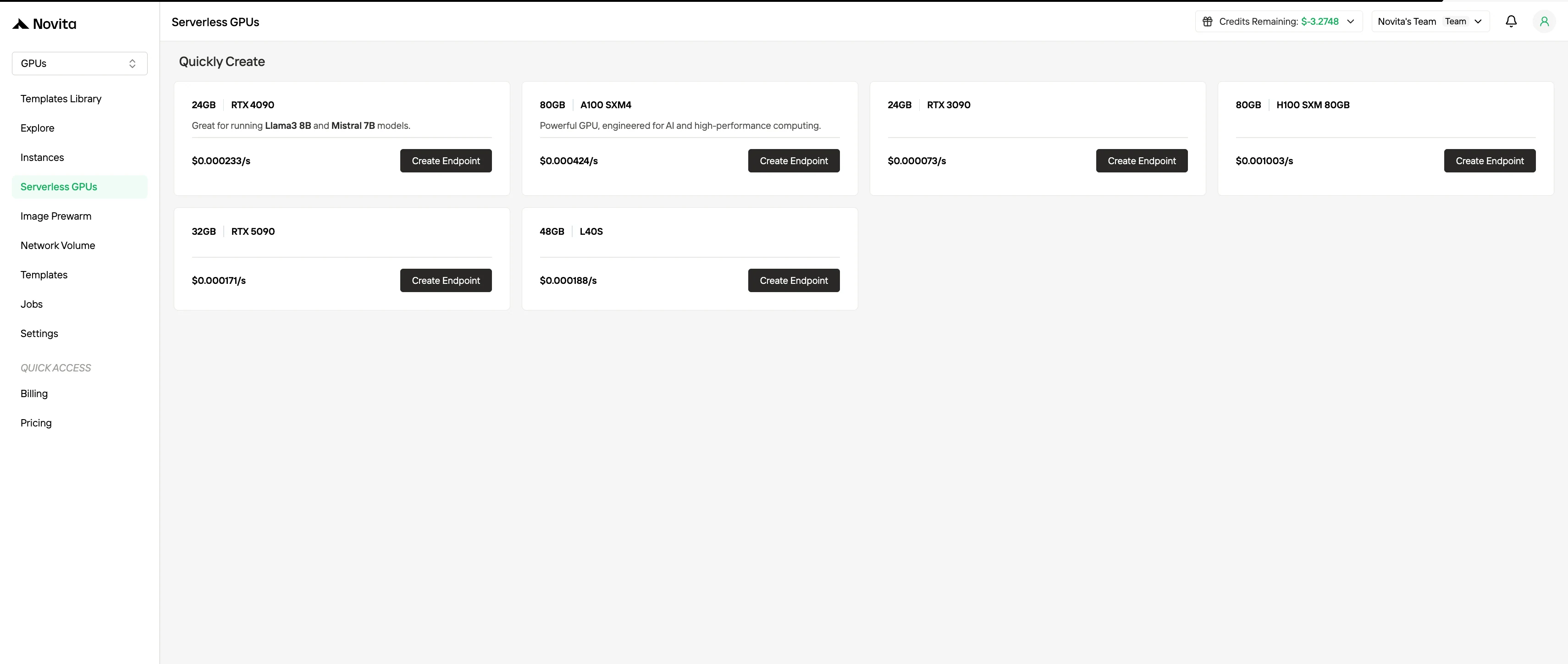
4. 無伺服器 GPU 計費
無伺服器 GPU 計費會自動根據工作负载需求擴展 GPU 資源,無需手動管理實例。使用者僅需為實際消耗的運算資源付費,而非為預留的實例付費。這種模式非常適合事件驅動或高度彈性的工作负载,能在最小化運維開銷的同時提升成本效益。
Novita AI 也提供範本功能,旨在大幅降低部署基於 GPU 的 AI 工作负载時的操作與認知開銷。開發者无需從頭手動組裝環境,範本系統提供預先配置、可立即投入生產的映像檔,捆綁了作業系統、CUDA 與 cuDNN 版本、深度學習框架、推理引擎,部分範本甚至包含完整配置的模型服務堆疊。
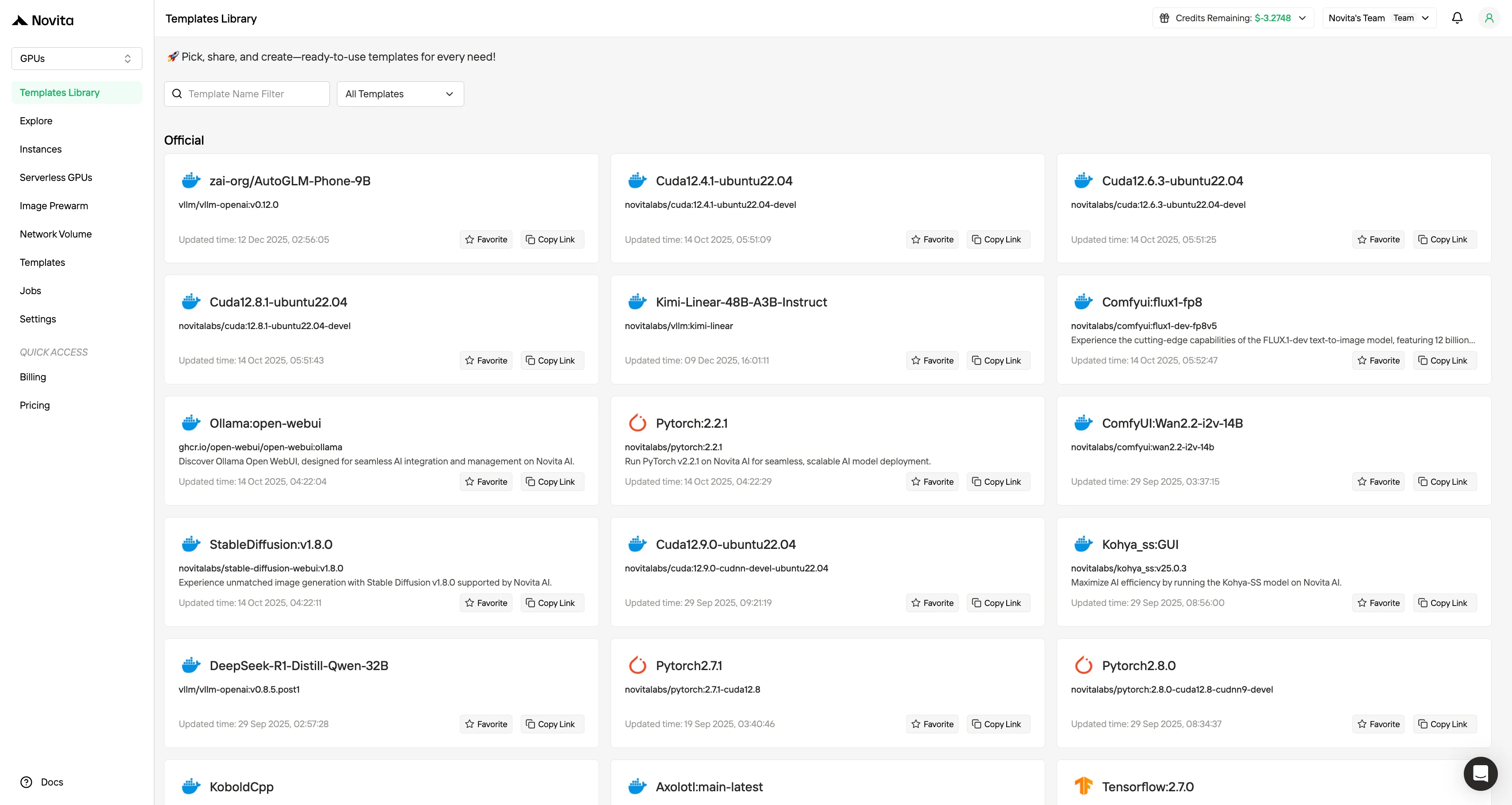
如何在 Novita AI 上部署 GLM 4.6V
步驟 1:註冊帳號
透過我們的官方網站建立 Novita AI 帳號。註冊完成後,前往左側邊欄的「探索」板塊,查看我們的 GPU 產品,開啟您的 AI 開發之旅。

步驟 2:選擇範本與 GPU 伺服器
根據您的專案需求,選擇對應的範本(如 PyTorch、TensorFlow 或 CUDA)。接著選擇您偏好的 GPU 配置,可選方案包括強大的 L40S、RTX 4090 或 A100 SXM4,每種配置的 VRAM、記憶體和儲存規格各不相同。
步驟 3:自訂部署並啟動實例
選擇您偏好的作業系統和配置選項,自訂您的環境,確保能為您的特定 AI 工作负载和開發需求提供最佳效能。完成後,您的高效能 GPU 環境將在幾分鐘內就緒,可立即開始您的機器學習、渲染或計算專案。
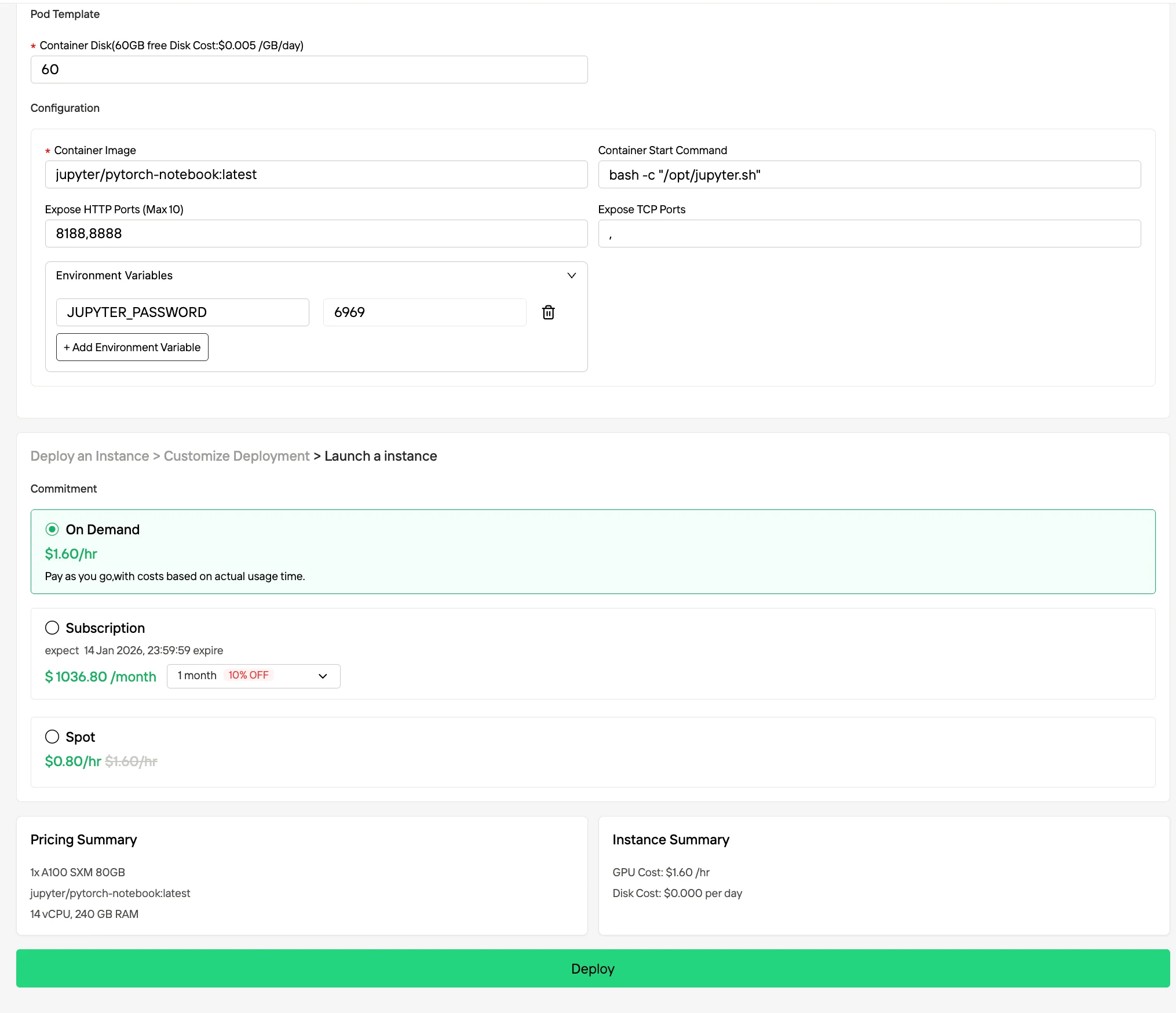
步驟 4:監控部署進度
前往實例管理頁面進入控制台,這個儀表板可讓您即時追蹤部署狀態。
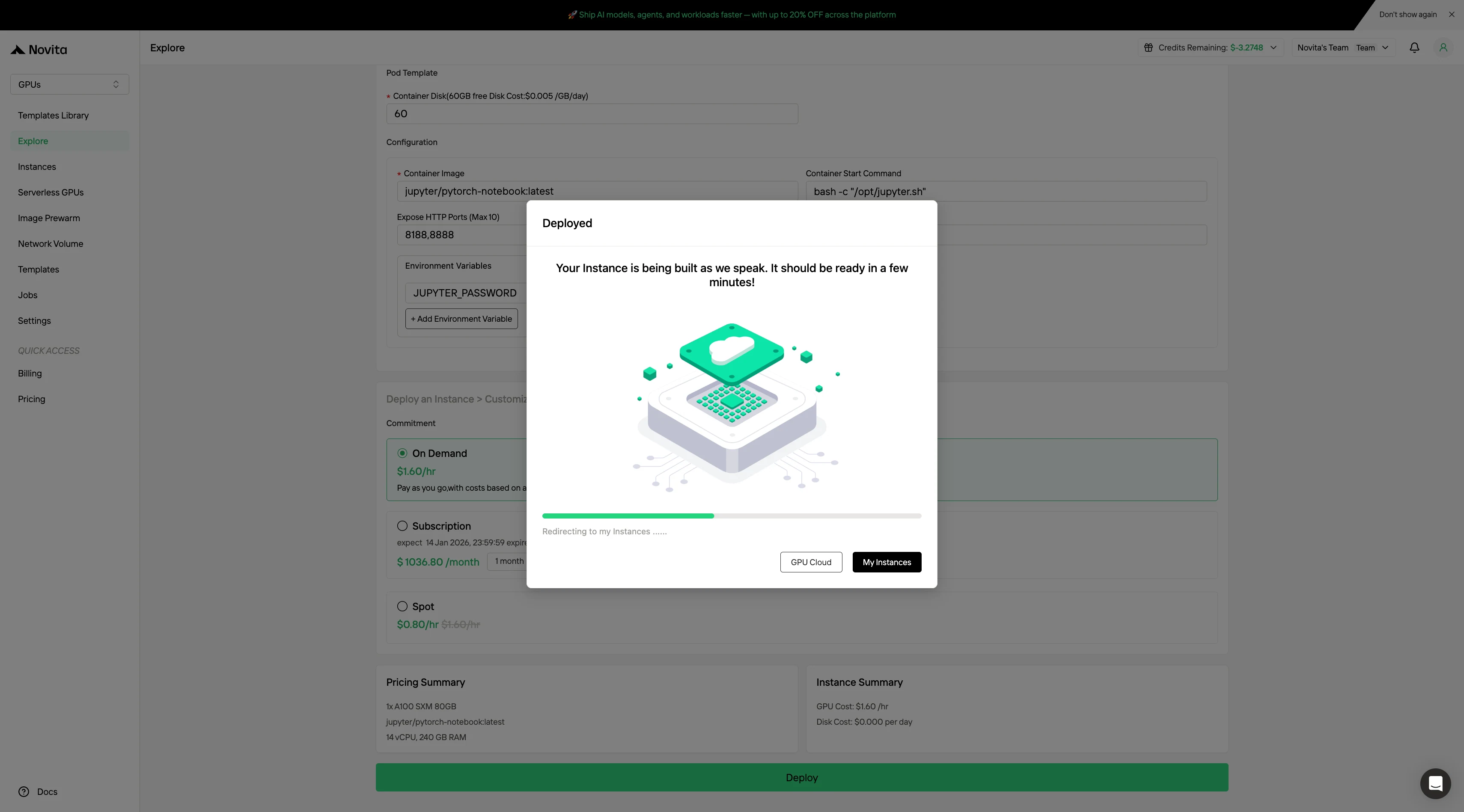
步驟 5:查看映像檔拉取狀態
點擊對應的實例,監控容器映像檔的下載進度。根據網路狀況,這個流程可能需要幾分鐘時間。
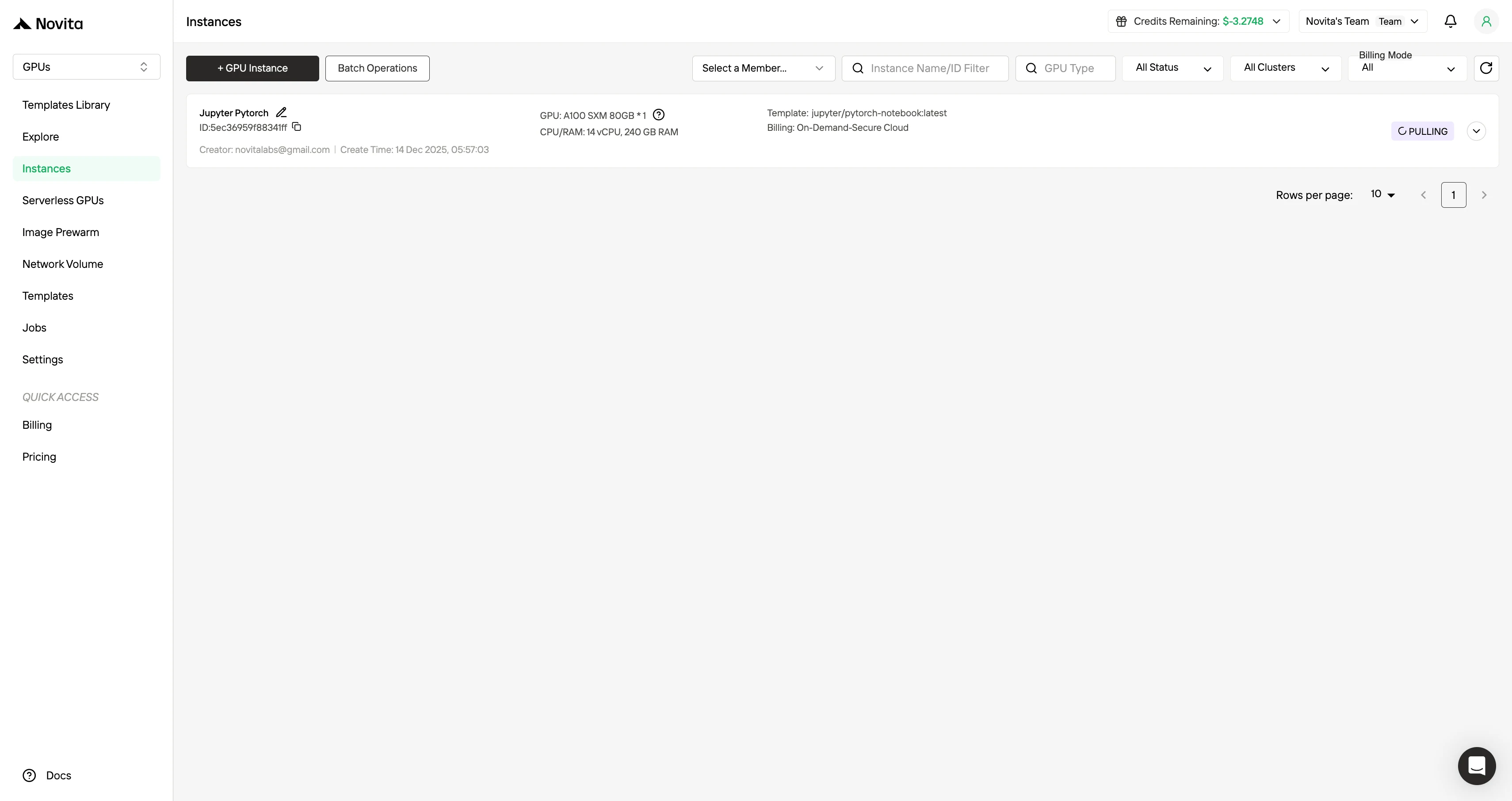
步驟 6:驗證部署成功
實例啟動後,會開始拉取模型。點擊「日誌」→「實例日誌」監控模型下載進度,若在實例日誌中看到
"Application startup complete."訊息,即表示部署流程已成功完成。點擊「連接」,再點擊 →「連接至 HTTP 服務 [Port 8000]」。由於這是 API 服務,您需要複製對應地址。
要對您的模型發送請求,請將範例地址***「http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai」***替換為您實際對外暴露的地址,複製以下程式碼即可存取您的私有模型!
GLM-4.6V 透過原生視覺到工具的執行能力、視覺反饋迴圈以及長上下文理解功能,在單一統一架構下實現了多模態推理的重大突破。雖然其全精度部署需要企業級硬體,但量化與 MoE 卸載技術讓 GLM-4.6V 能服務於更廣泛的開發者群體。Novita AI 進一步降低採用門檻,提供靈活的 GPU 計費模式、預配置範本與流暢的部署流程。GLM-4.6V 與 Novita AI 結合,為構建下一代多模態應用提供了實用、可擴展且高成本效益的基礎。
常見問題
GLM-4.6V 與傳統視覺語言模型有何不同?
GLM-4.6V 支援原生多模態函式呼叫,能直接執行視覺到工具的流程,无需經過中間的文字生成步驟。
為什麼 GLM-4.6V 在全精度下需要如此大的 VRAM?
雖然 GLM-4.6V 的活躍參數量有限,但其 1060 億的儲存權重與長上下文 KV 快取大幅增加了 VRAM 需求。
GLM-4.6V 如何實現像素級的前端精度?
GLM-4.6V 使用基於強化學習的視覺審核迴圈,將渲染輸出與目標圖像進行比對。
Novita AI 是全能雲端平台,助力您實現 AI 抱負。整合 API、無伺服器服務、GPU 實例——您需要的低成本工具應有盡有。免除基礎設施煩惱,免費開始使用,讓您的 AI 願景成為現實。



