

Novita AI 在 MiniMax Speech 02 系列中提供了四种不同的模型。每种模型针对不同场景进行设计,无论是需要录音室级别的旁白,还是快速交互式语音。
在接下来的部分中,我们将更详细地探讨这些模型之间的差异,帮助您为特定用例选择最佳选项。
MiniMax Speech 02 算法
“02”指的是什么?
| 术语 | 含义 |
|---|---|
| 02 | 指 MiniMax Speech 模型的第二代。 |
| TTS | 文本转语音:将书面文字转换为口头音频的技术。 |
| 异步 | 异步:语音在后台生成,并在准备好后交付,适用于长文本。 |
| HD | 高清/高保真:专注于生成非常逼真且高质量的音频。 |
| Turbo | 涡轮(低延迟):优先考虑速度和快速响应,适用于实时交互。 |
MiniMax Speech 02 模型对比
| 模型/API 名称 | 适用场景 | 优势 | 支持文本长度 |
|---|---|---|---|
| speech‑02‑hd 文本转语音 | 短文本、实时对话 | 极高的音频质量和自然度 | 最多约 5,000 字符 |
| speech‑02‑hd 异步长文本 TTS | 有声书、长内容 | 支持长文本,音频质量相同 | 最多数十万至数百万字符,排队处理 |
| speech‑02‑turbo 文本转语音 | 实时语音交互 | 响应快速、低延迟 | 最多约 5,000 字符 |
| speech‑02‑turbo 异步长文本 TTS | 实时交互中的长文本 | 平衡速度与可扩展性 | 支持长文本,处理速度快于同步模式 |
MiniMax Speech 02 自定义选项
- 丰富的语音库:
提供超过 300 种真实自然的声音,支持粤语、普通话、日语、韩语及多种主要语言的逼真输出。 - 高级语音控制:
可轻松调节每种语音的情感、音量、语速和输出格式,完美满足您的需求。 - 创新语音混合:
将多个现有声音组合,创建全新且独特的声音档案。 - 多种音频格式:
输出包括 FLAC、WAV、MP3 和 PCM 在内的多种音频格式,兼容性极佳。 - 实时流式传输:
享受无缝实时流式传输的即时音频交付,确保顺利集成到您的应用中。 - 高并发支持:
强大的基础设施即使在高负载和高请求量下也能保证可靠的性能。
MiniMax 如何改进语音合成?
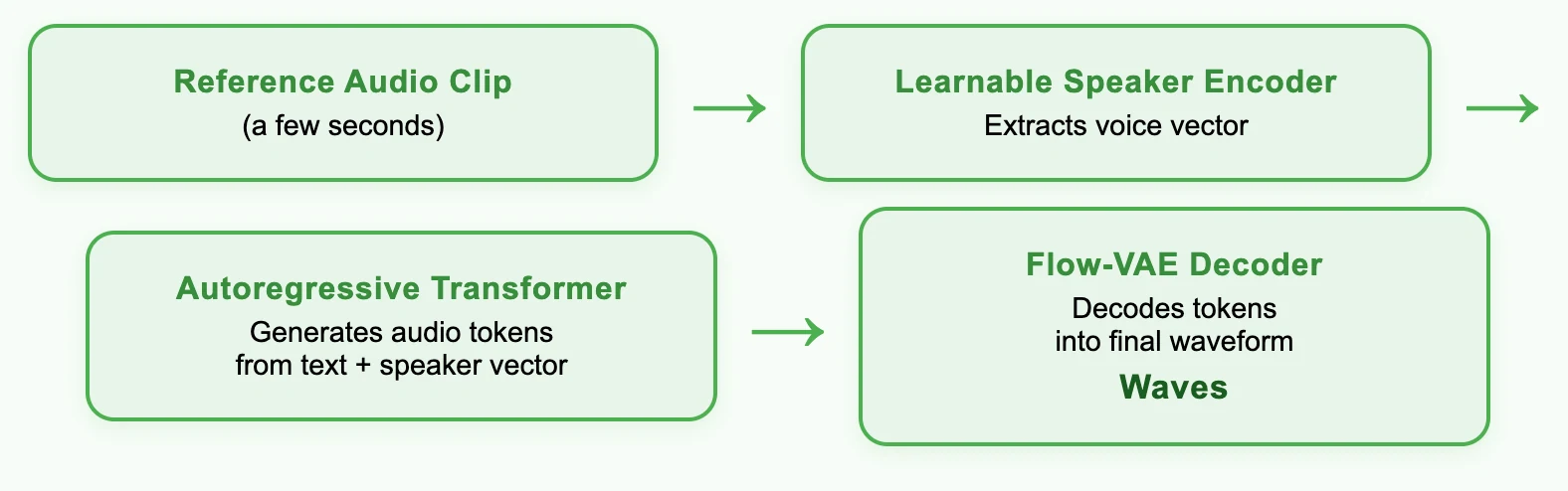
创新驱动,MiniMax 排名第一
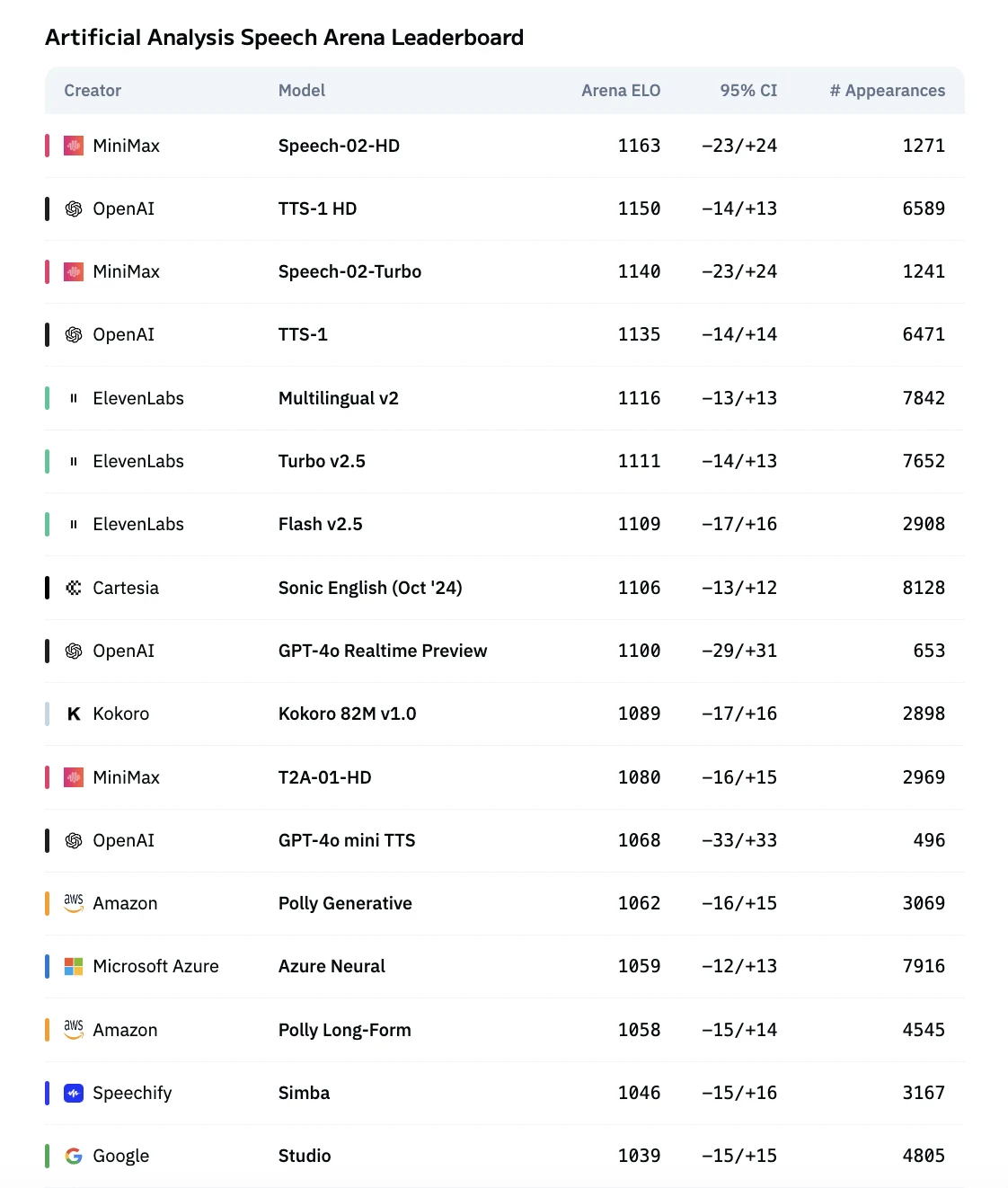
MiniMax Speech 02 用于实时或鲁棒语音识别
| 场景类型 | 核心目标 | 关键模型能力 | Speech‑02 适配方式 |
|---|---|---|---|
| 实时语音合成 | 快速响应与流式播放 | 超低延迟、实时输出、自然音色语调、多语言支持 | Speech‑02‑Turbo 即时生成音频,支持最多约 5,000 字符流式输出,延迟极小,适合对话应用 |
| 鲁棒语音识别(用于 ASR) | 合成语音必须清晰、可识别且高质量 | 卓越的语音清晰度、发音准确且错误率低、节奏语调良好 | Speech‑02‑HD 用于生成高保真语音,词错误率低、说话人相似度高、音频质量优良 |
如何接入 MiniMax Speech 02?
步骤 1:登录并进入模型库
登录您的账户,点击 模型库 按钮。
步骤 2:选择您的模型
浏览可用选项,选择适合您需求的模型。
步骤 3:开始免费试用
开始免费试用,探索所选模型的功能。
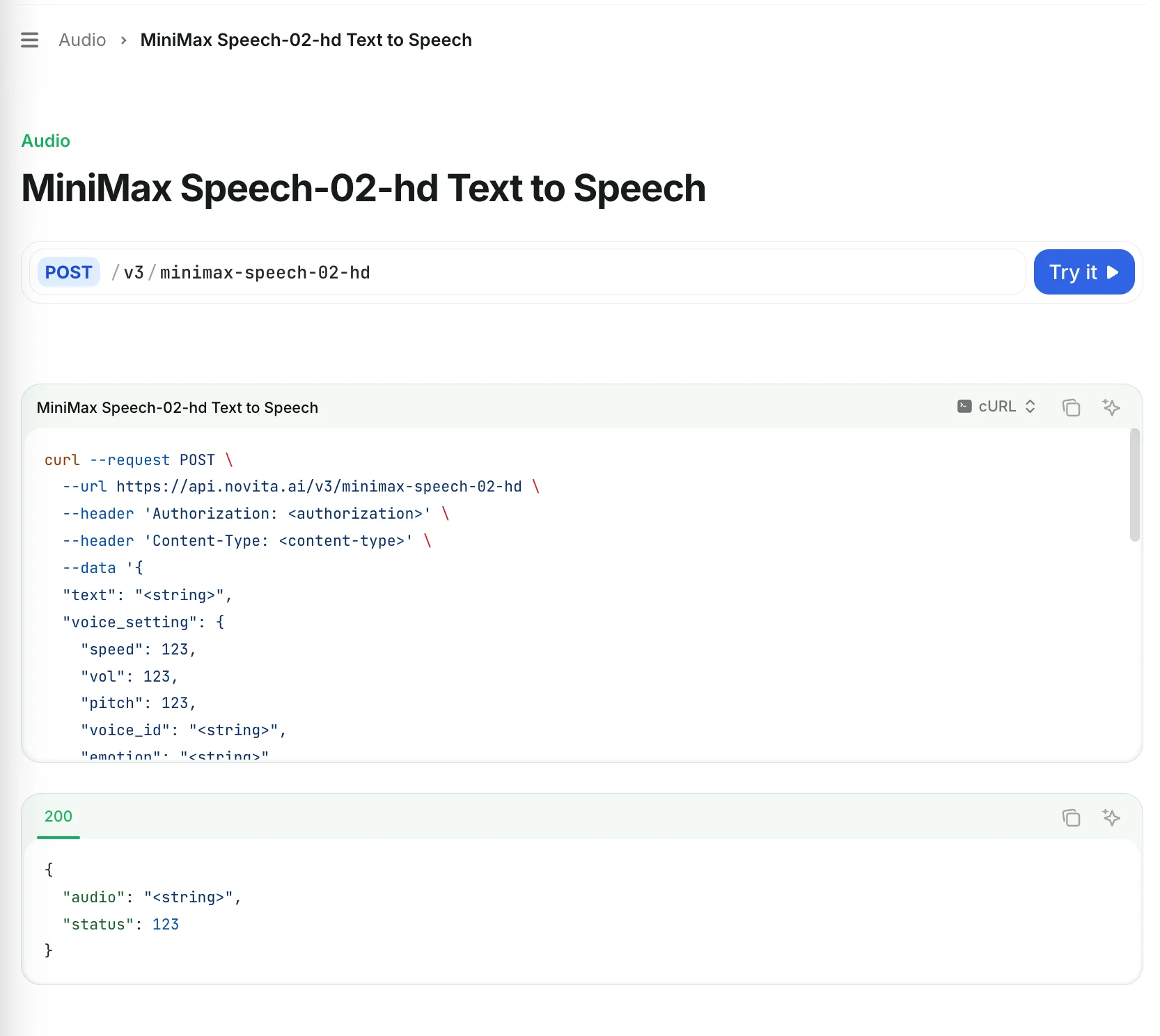
点击 “试用” 查看每个字段的含义,并选择值以自定义您的 API 设置。
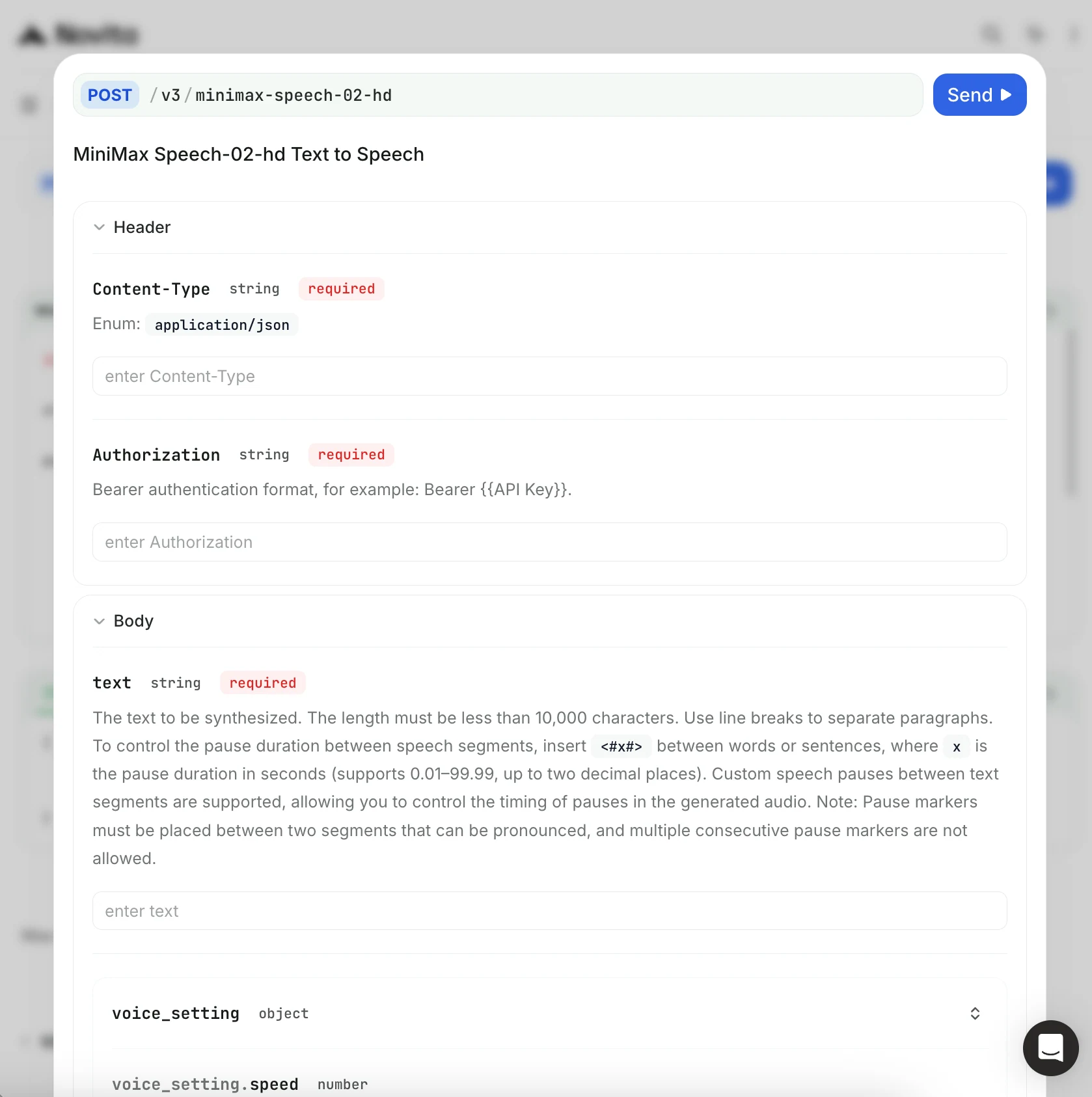
步骤 4:获取您的 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入“设置”页面,您可以按照图片所示复制 API 密钥。

步骤 5:安装 API
安装后,将必要的库导入到您的开发环境中。使用您的 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是面向 Python 用户 使用聊天补全 API 的示例。
import requests
url = "https://api.novita.ai/v3/minimax-speech-02-hd"
payload = {
"text": "<string>",
"voice_setting": {
"speed": 123,
"vol": 123,
"pitch": 123,
"voice_id": "<string>",
"emotion": "<string>",
"english_normalization": True
},
"audio_setting": {
"sample_rate": 123,
"bitrate": 123,
"format": "<string>",
"channel": 123
},
"pronunciation_dict": { "tone": [{}] },
"timber_weights": [
{
"voice_id": "<string>",
"weight": 123
}
],
"stream": True,
"language_boost": "<string>",
"output_format": "<string>"
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())
步骤 6:切换到其他模型
您可以点击左上角的侧边栏来选择不同的音频模型。Novita AI 还提供语音克隆功能。
MiniMax Speech 02 是一款表现出色的文本转语音解决方案,能够生成高保真且低延迟的音频。凭借丰富的语音选项、高级控制以及对实时和大规模应用的强大支持,MiniMax Speech 02 适用于广泛的语音合成场景。其创新特性和易于自定义的特点,使其在语音 AI 模型中名列第一。
常见问题
MiniMax Speech 02 中的“02”是什么意思?
“02”指 MiniMax Speech 模型的第二代,代表了质量和速度方面的显著提升。
MiniMax Speech 02 能处理长文本吗?
可以。异步模型(HD 异步和 Turbo 异步)专为处理长内容(如有声书)而设计,支持多达数百万字符。
它支持实时流式传输吗?
支持。MiniMax Speech 02 的 Turbo 模式提供超低延迟的实时流式传输,非常适合交互式或对话式应用。
Novita AI 是全方位云平台,助力您的 AI 梦想。集成 API、无服务器、GPU 实例——您需要的经济高效工具。无需基础设施,免费开始,让您的 AI 愿景成为现实。



