

NVIDIA的RTX 5090和RTX 6000 Ada是当今最强大的GPU之一,但二者之间的选择并不只是看原始性能。真正的核心问题是如何将合适的GPU匹配到合适的工作负载——无论是快速原型开发、大规模AI训练,还是企业级设计和仿真。虽然RTX 5090代表了消费级性能的巅峰,但RTX 6000 Ada是专为稳定性、可靠性和可扩展性至关重要的环境打造的工作站级解决方案。
本文将从规格、性能和使用场景三个维度对比两款GPU,帮助你确定哪款更符合你的需求和预算。
RTX 6000 vs RTX 5090:基础特性
| 特性 | RTX 5090 | RTX 6000 Ada |
| 架构 | Blackwell | Ada Lovelace |
| 显存 | 32 GB GDDR7 | 48 GB GDDR6 |
| 显存接口 | 512-bit | 384-bit |
| 显存带宽 | 1792 GB/s | 960 GB/s |
| 纠错码(ECC) | 否 | 是 |
| CUDA核心数 | 21760 | 18176 |
| Tensor核心 | 第5代 | 第4代 |
| RT核心 | 第4代 | 第3代 |
| 功耗 | 475~500W | 300W |
RTX 6000 vs RTX 5090:性能深度解析
RTX 5090是NVIDIA最强大的消费级GPU,旨在将原始性能推向极限。基于Blackwell架构打造,它搭载了32GB下一代GDDR7显存,以及业界领先的1792 GB/s带宽。对于追求高效开发者和创作者而言,它是一款性能猛兽。
- 峰值显存带宽:凭借1792 GB/s的吞吐量,它可以加速AI增强图形、视频编辑和生成式媒体创作。
- 先进的Tensor与RT核心:第5代Tensor核心和第4代RT核心提升了实时可视化能力,支持更流畅的原型开发和AI驱动特效。
- 快速迭代:非常适合独立开发或小团队开发者,能够快速测试和迭代模型或创意应用。
- 高性价比性能:作为消费级GPU,相比工作站显卡,它的入手门槛更低,同时仍能提供最先进的性能。
RTX 6000 Ada则走的是不同的路线,更侧重可靠性和专业级部署。基于Ada Lovelace架构打造,配备48GB ECC GDDR6显存,专为需要稳定、一致性能的高要求大规模工作负载设计。
- ECC显存保障数据完整性:纠错GDDR6显存可确保处理海量数据集或关键任务AI训练时的结果稳定。
- 大规模AI训练:第4代Tensor核心支持FP8精度,推理和训练性能相比上一代提升超过2倍。
- 虚拟化就绪:支持NVIDIA RTX虚拟工作站(vWS),允许多个用户安全共享GPU资源,非常适合分布式团队。
- 企业级可靠性:针对长时间运行的工作负载、CAD/CAE项目和大规模仿真优化,杜绝停机或数据错误。
核心要点
- RTX 5090 → 最适合看重速度、灵活性和性价比的开发者和创作者,适合原型开发或测试AI驱动工作流。
- RTX 6000 Ada → 最适合需要稳定性、内存完整性和可扩展性的企业团队和研究人员,适合协作式或大规模AI项目。
RTX 6000 vs RTX 5090:如何选择?
RTX 5090在创意和实验性工作流中表现尤为突出。它在AI驱动的视频编辑场景中表现优异,凭借1792 GB/s带宽和第9代NVENC编码器,可在Adobe Premiere Pro和DaVinci Resolve等应用中实现极速导出和AI驱动特效。此外,它的第5代Tensor核心可加速生成式媒体和3D渲染,支持实时可视化和更流畅的创意实验。同时,这款显卡的消费级定价使其成为独立开发者原型开发小型AI模型和测试新创意应用的理想选择。最后,它支持广泛的AI增强用例,从视频超分辨率、AI驱动的直播增强,到实时音视频特效。
RTX 6000 Ada则专为可靠性和规模至关重要的工作负载打造。配备48GB ECC GDDR6显存,它可确保大规模AI训练和推理场景下的数据完整性,非常适合企业和研究环境。此外,相比上一代翻倍的FP32吞吐量可加速工程和仿真工作负载,尤其是CAD/CAE和其他复杂建模任务。同时,对NVIDIA RTX虚拟工作站(vWS)的支持允许多个开发者或研究人员安全共享GPU资源,这是分布式团队的关键功能。因此,RTX 6000 Ada能够提供企业级可靠性,满足关键任务AI和3D项目的需求,在长时间运行的任务(如建筑可视化或科学仿真)中确保可预测、无错误的性能。
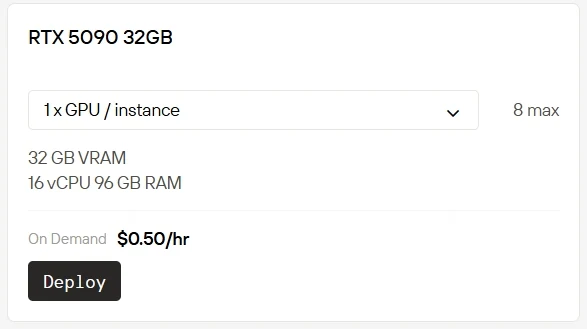
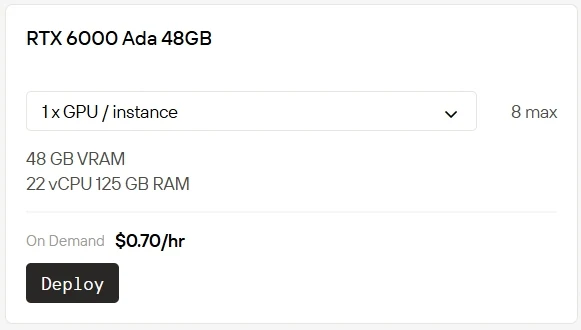
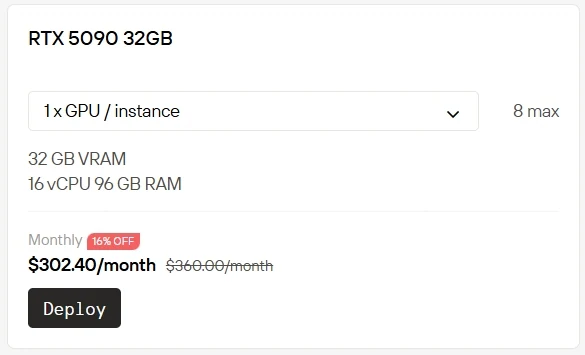
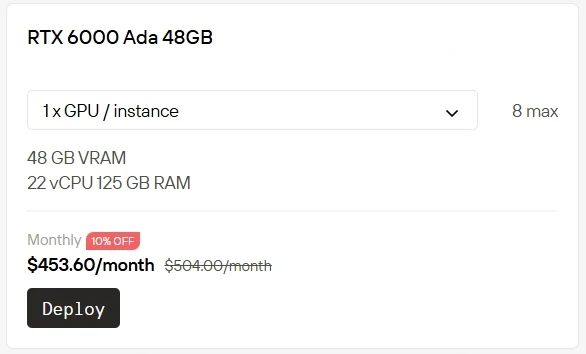
本地购置和运行高端GPU成本高昂且维护复杂。Novita AI 现推出GPU实例服务,可让你即时在云端使用RTX 5090(仅需$0.50/小时)和RTX 6000(仅需$0.70/小时)。我们还提供更多计费选项:Spot实例提供折扣费率,可用性灵活但存在波动;On-Demand实例支持即开即用,按需付费的简单模式;Subscription订阅实例则为长期、可预测的使用场景提供稳定的成本优惠。
Spot实例享5折优惠!
按需实例(On-Demand)
订阅实例(Subscription)享折扣!
在Novita AI上使用灵活GPU实例快速上手
Novita AI提供企业级云GPU基础设施,同时支持RTX 5090和RTX 6000 Ada选项,让开发者和企业无需承担前期资本投入,即可享受高性能计算能力。
步骤1:注册账号
通过我们的网站创建Novita AI账号。注册完成后,进入“GPUs”标签页即可查看可用资源,开启你的使用之旅。
步骤2:选择GPU
我们提供多种预配置模板以满足不同需求,同时也支持自定义配置。你可以使用配备大容量显存和内存的RTX 5090和RTX 6000 Ada GPU,即使训练高度复杂的AI模型也能高效完成。
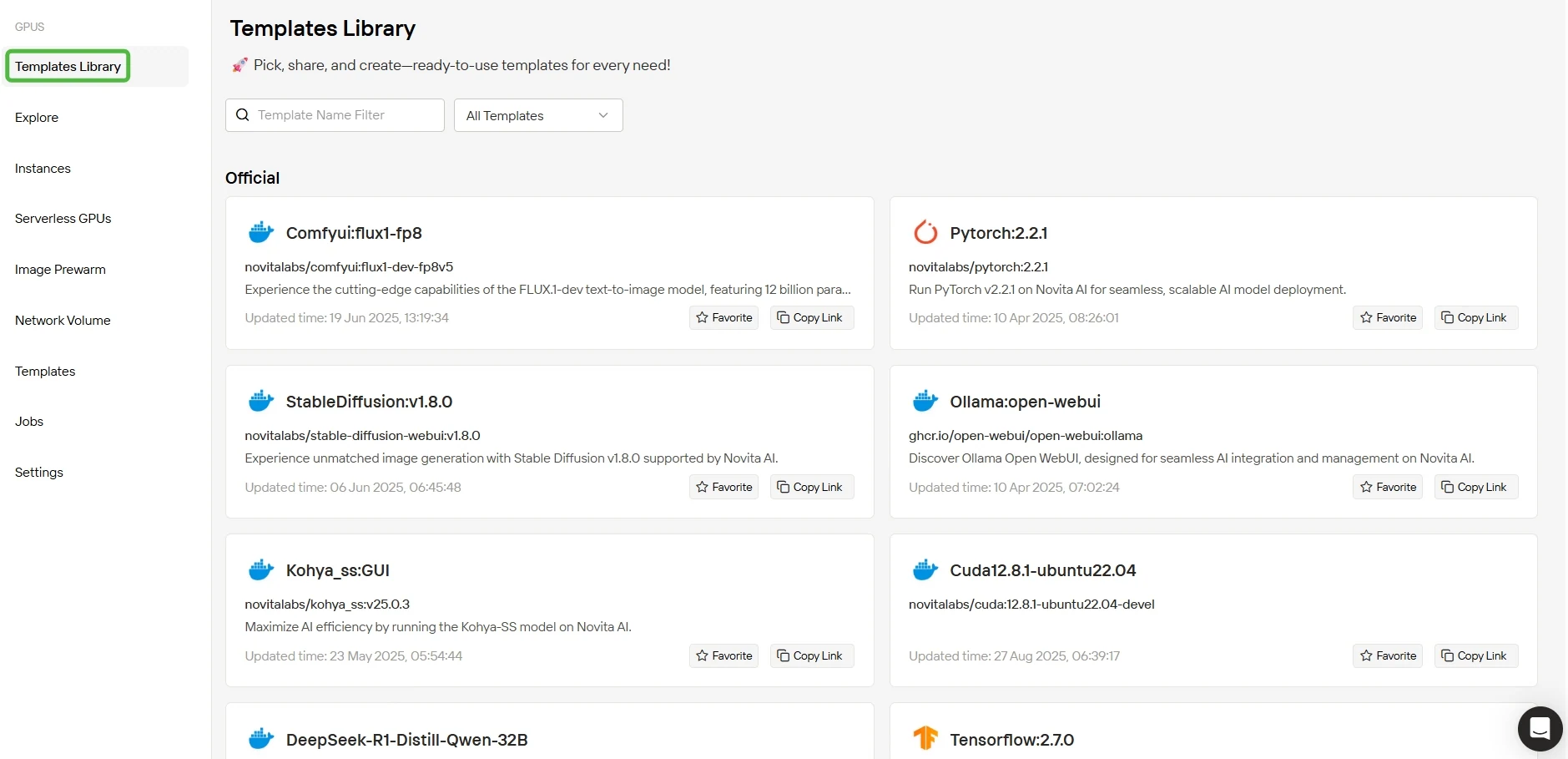 预配置模板库
预配置模板库
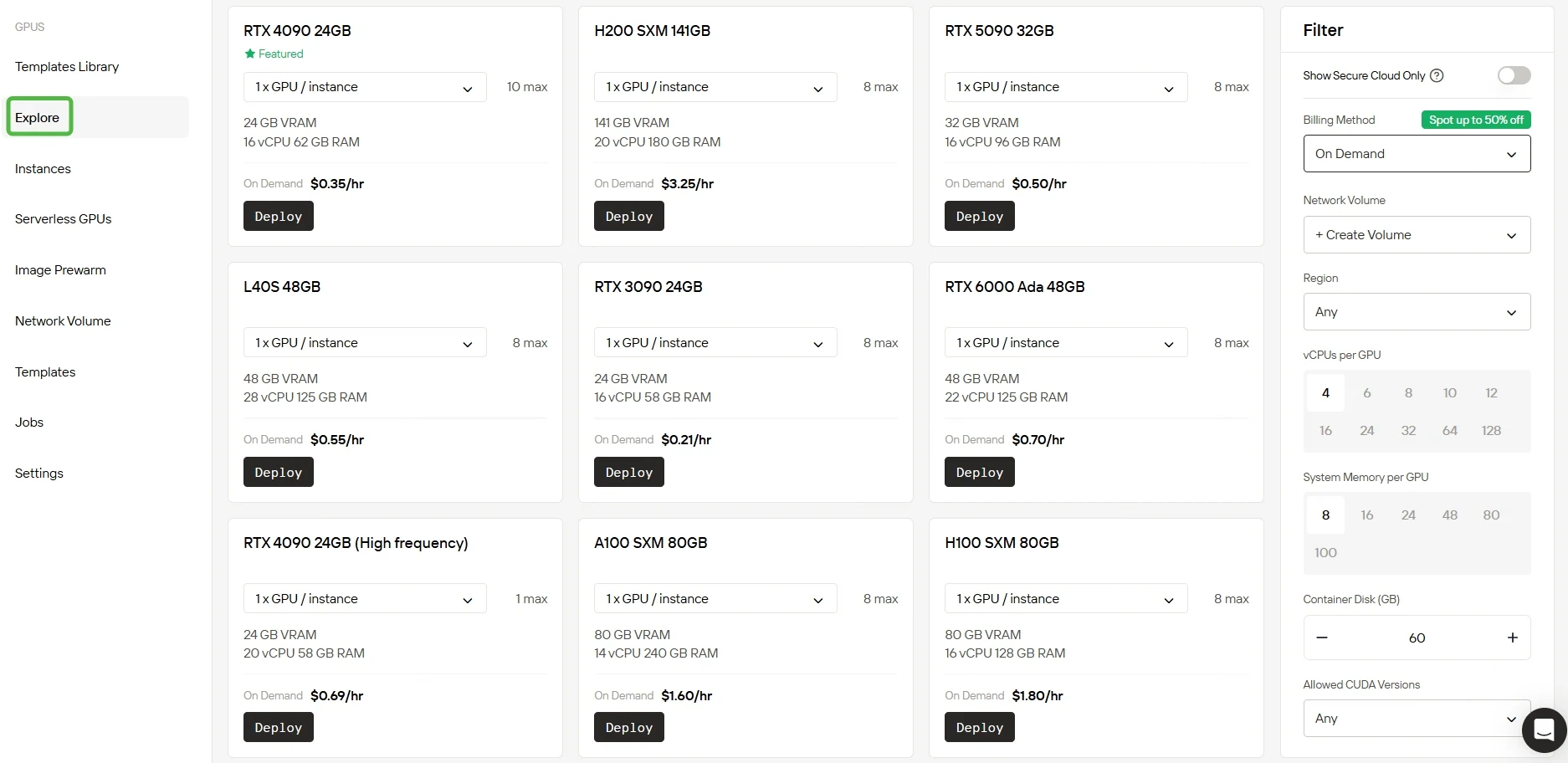 探索多样化的GPU选项
探索多样化的GPU选项
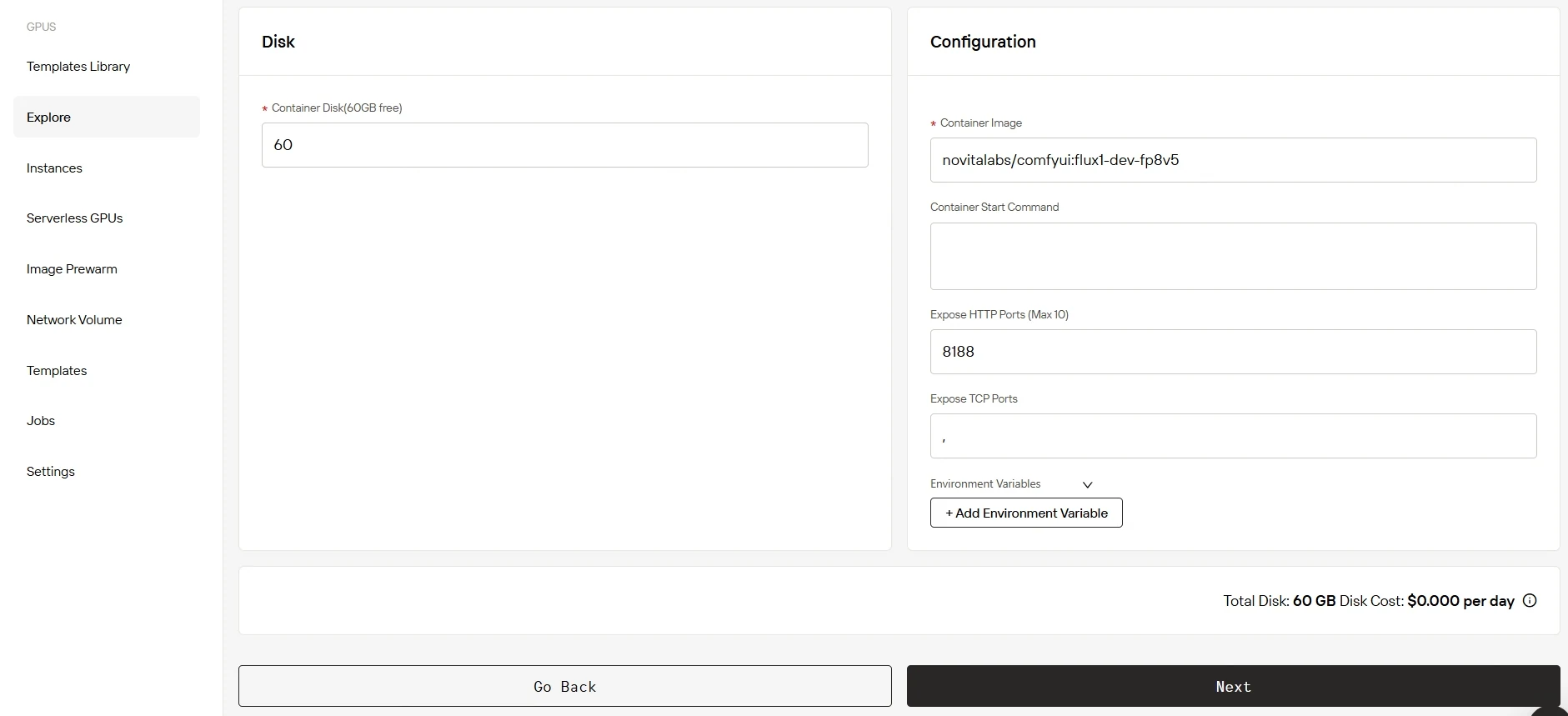
步骤3:自定义部署配置
根据你的需求选择操作系统和配置项,确保AI工作负载获得最佳性能。初始提供60GB免费容器存储空间,无需前期成本即可启动项目,后续可根据需求灵活扩容,提供高性价比的灵活解决方案。
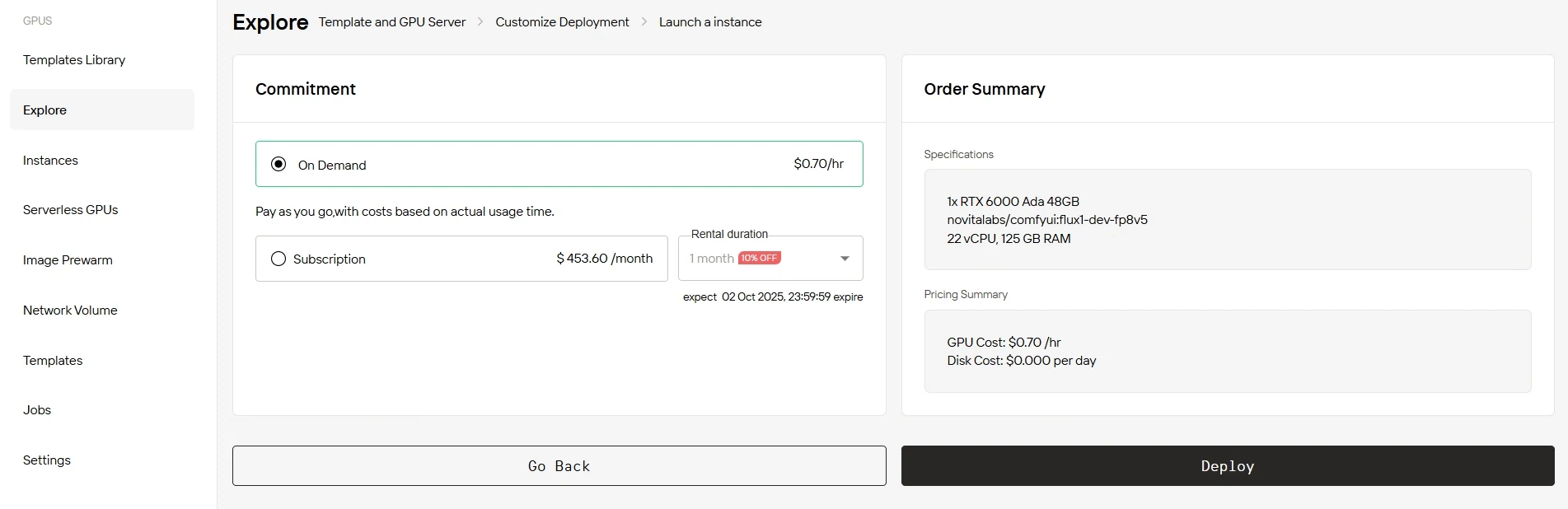
步骤4:启动实例
点击“部署”按钮启动部署流程。几分钟内,你的高性能GPU环境即可就绪,你可以立即开始机器学习、渲染或计算类项目。
结论
- 如果你最看重原始性能,选择RTX 5090。它专为4K游戏、AI工作负载和高级渲染设计,为最具挑战性的项目提供顶尖的速度和算力,不过功耗和成本也相对更高。
- 如果你最看重稳定性,选择RTX 6000 Ada。它专为处理大规模AI模型、仿真和3D设计打造,不会出现错误或中断。凭借可靠的显存、更快的工作流和强大的团队共享支持,它为关键任务工作提供企业级保障。
- 如果你更看重性价比,像Novita AI 这样的云平台可以让你按需使用RTX 5090和6000 Ada的算力,轻松、实惠地获得高端GPU计算能力。
常见问题
*Novita AI 是一个AI云平台,为开发者提供简单的API来部署AI模型,同时提供高性价比、可靠的GPU云服务,用于AI模型的构建和扩展。



