

NVIDIAのRTX 5090とRTX 6000 Adaは現在市場で最も強力なGPUの2つですが、どちらを選ぶかは単純な性能の比較だけでは判断できません。本当の問いは、適切なワークロードに適切なGPUをマッチさせるかどうかです。ラピッドプロトタイピング、大規模なAIトレーニング、エンタープライズグレードのデザイン・シミュレーションのいずれにおいても、RTX 5090はコンシューマーグレードの性能の頂点を提供する一方、RTX 6000 Adaは安定性、信頼性、拡張性が求められる環境向けに設計されたワークステーションクラスのソリューションです。
この記事では両GPUの仕様、性能、ユースケースを比較し、ご自身の要件や予算に最適なGPUを判断するお手伝いをします。
RTX 6000 vs RTX 5090:基本仕様
| 特徴 | RTX 5090 | RTX 6000 Ada |
| アーキテクチャ | Blackwell | Ada Lovelace |
| GPUメモリ | 32 GB GDDR7 | 48 GB GDDR6 |
| メモリインターフェース | 512-bit | 384-bit |
| メモリ帯域幅 | 1792 GB/s | 960 GB/s |
| エラー修正コード | いいえ | はい |
| CUDAコア | 21760 | 18176 |
| テンソルコア | 第5世代 | 第4世代 |
| RTコア | 第4世代 | 第3世代 |
| 消費電力 | 475~500W | 300W |
RTX 6000 vs RTX 5090:性能徹底解説
RTX 5090はNVIDIAの最も強力なコンシューマーGPUとして、生の速度の限界を押し上げるように設計されています。Blackwellアーキテクチャを搭載し、次世代GDDR7メモリ32GBと業界最高レベルの1792 GB/s帯域幅を組み合わせています。開発者やクリエイターでスピードを重視する方にとって、まさに性能の猛獣です。
- ピークメモリ帯域幅:1792 GB/sのスループットにより、AI強化グラフィックス、動画編集、生成メディア制作を加速します。
- 高度なテンソルコア & RTコア:第5世代テンソルコアと第4世代RTコアがリアルタイム可視化を強化し、よりスムーズなプロトタイピングとAI駆動のエフェクトを実現します。
- 迅速な反復作業:モデルやクリエイティブアプリケーションを迅速にテスト・改良する必要がある、個人または小規模チームの開発者に最適です。
- コストパフォーマンスに優れた性能:コンシューマークラスのGPUとして、ワークステーションカードと比較してより手頃なエントリーポイントを提供しながら、最先端の性能を発揮します。
RTX 6000 Adaは異なるアプローチを採用し、信頼性とプロフェッショナルグレードの導入を重視しています。Ada Lovelaceアーキテクチャを搭載し、ECC GDDR6メモリ48GBを装備しており、要求の厳しい大規模ワークロードに対して安定した一貫した性能を発揮するように設計されています。
- データ整合性のためのECCメモリ:エラー修正機能付きGDDR6は、大規模なデータセットの処理やミッションクリティカルなAIトレーニングにおいて安定した結果を保証します。
- 大規模AIトレーニング:第4世代テンソルコアとFP8精度により、前世代と比較して推論とトレーニングの性能が2倍以上向上しています。
- 仮想化対応:NVIDIA RTX Virtual Workstation (vWS)への対応により、複数のユーザーがGPUリソースを安全に共有できるため、分散チームに最適です。
- エンタープライズ信頼性:長時間のワークロード、CAD/CAEプロジェクト、大規模なシミュレーションなど、ダウンタイムやデータエラーが許容されない環境に最適化されています。
まとめ
- RTX 5090 → プロトタイピングやAI駆動のワークフローの実験において、スピード、柔軟性、手頃な価格を重視する開発者やクリエイターに最適です。
- RTX 6000 Ada → 協業や大規模なAIプロジェクトにおいて、安定性、メモリ整合性、拡張性を必要とするエンタープライズチームや研究者に最適です。
RTX 6000 vs RTX 5090:どちらを選ぶべき?
RTX 5090は特にクリエイティブや実験的なワークフローで効果を発揮します。1792 GB/sの帯域幅と第9世代NVENCエンコーダーを活用したAI搭載動画編集で優れた性能を発揮し、Adobe Premiere ProやDaVinci Resolveなどのアプリケーションで超高速のエクスポートとAI駆動のエフェクトを実現します。さらに、第5世代テンソルコアが生成メディアと3Dレンダリングを加速し、リアルタイム可視化とよりスムーズなクリエイティブな実験を可能にします。また、コンシューマークラスの手頃な価格から、小規模なAIモデルのプロトタイピングや新しいクリエイティブアプリケーションのテストを行うインディー開発者にも最適です。さらに、動画超解像やAI搭載ストリーミング強化、リアルタイム音声・動画エフェクトなど、幅広いAI強化ユースケースに対応しています。
RTX 6000 Adaは、信頼性と拡張性が不可欠なワークロード向けに設計されています。48GBのECC GDDR6メモリを搭載し、大規模AIトレーニングと推論のデータ整合性を保証するため、エンタープライズや研究環境に最適です。さらに、前世代と比較してFP32スループットが2倍になり、エンジニアリング・シミュレーションのワークロード、特にCAD/CAEやその他の複雑なモデリングタスクを加速します。また、NVIDIA RTX Virtual Workstation (vWS)への対応により、複数の開発者や研究者がGPUリソースを安全に共有できるため、分散チームにとって重要な機能です。その結果、RTX 6000 AdaはミッションクリティカルなAI・3Dプロジェクトに必要なエンタープライズレベルの信頼性を提供し、建築ビジュアライゼーションや科学シミュレーションなどの長時間のタスクにおいて予測可能でエラーのない性能を実現します。
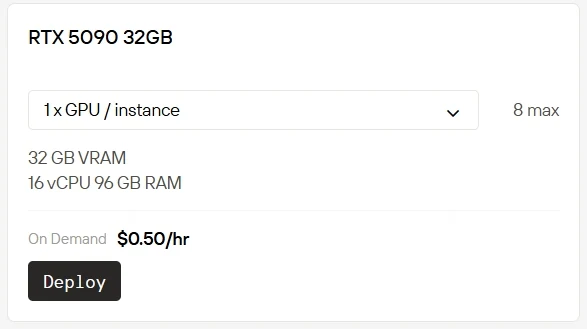
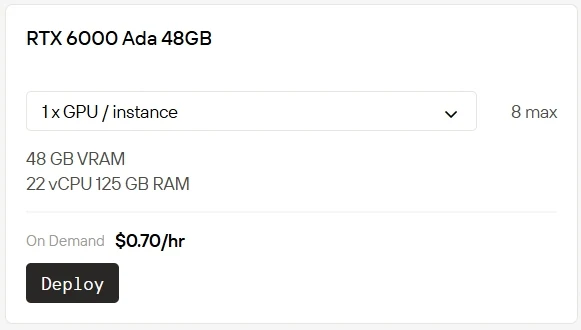
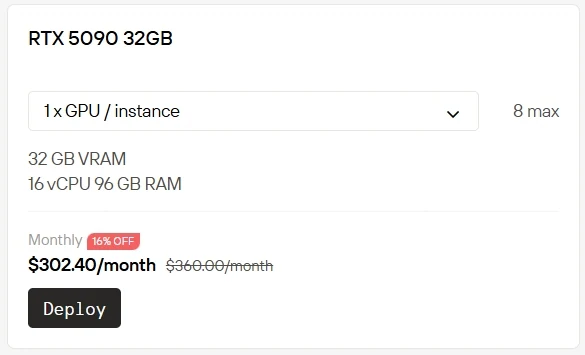
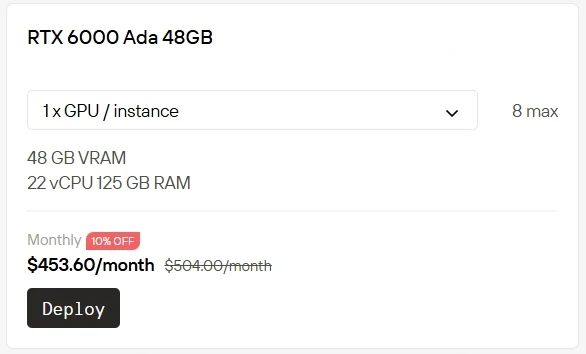
高性能GPUを自前で所有・運用することはコストがかかり、負担も大きくなります。Novita AIは現在、クラウド上でRTX 5090を1時間あたり$0.50、RTX 6000を1時間あたり$0.70で即座に利用できるGPUインスタンスサービスを提供しています。その他の課金オプションも用意されています:Spotは割引料金を提供する一方、利用可能枠が変動する柔軟なプランです。On-Demandはシンプルな従量課金モデルで即座に利用できます。Subscriptionは長期的で予測可能な利用に対して安定したコスト削減を提供します。
Spotは50% OFF!
On-Demand
Subscriptionは割引あり!
Novita AIの柔軟なGPUインスタンスを今すぐ始めよう
Novita AIはRTX 5090とRTX 6000 Adaの両方のオプションを提供するエンタープライズグレードのクラウドGPUインフラを提供し、開発者や企業が初期資本投資の負担なく高性能コンピューティングを活用できるようにします。
ステップ1:アカウント登録
当社のウェブサイトからNovita AIアカウントを作成してください。登録後、「GPUs」タブに移動して利用可能なリソースを確認し、利用を開始できます。
ステップ2:GPUを選択
多様なニーズに合わせた複数の事前設定テンプレートを提供しているほか、カスタムテンプレートを作成する柔軟性も備えています。大容量のVRAMとRAMを搭載した強力なRTX 5090およびRTX 6000 Ada GPUにアクセスできるため、非常に複雑なAIモデルのトレーニングも効率的に行えます。
事前設定テンプレートライブラリ
多彩なGPUオプションを探索
ステップ3:デプロイをカスタマイズ
オペレーティングシステムや設定を選択して環境を構成し、AIワークロードに最適な性能を確保してください。プロジェクトを即座に開始できるよう、60GBの無料コンテナディスクストレージから始められ、必要に応じて追加のスペースをシームレスに拡張できるため、柔軟でコストパフォーマンスの高いソリューションを提供します。
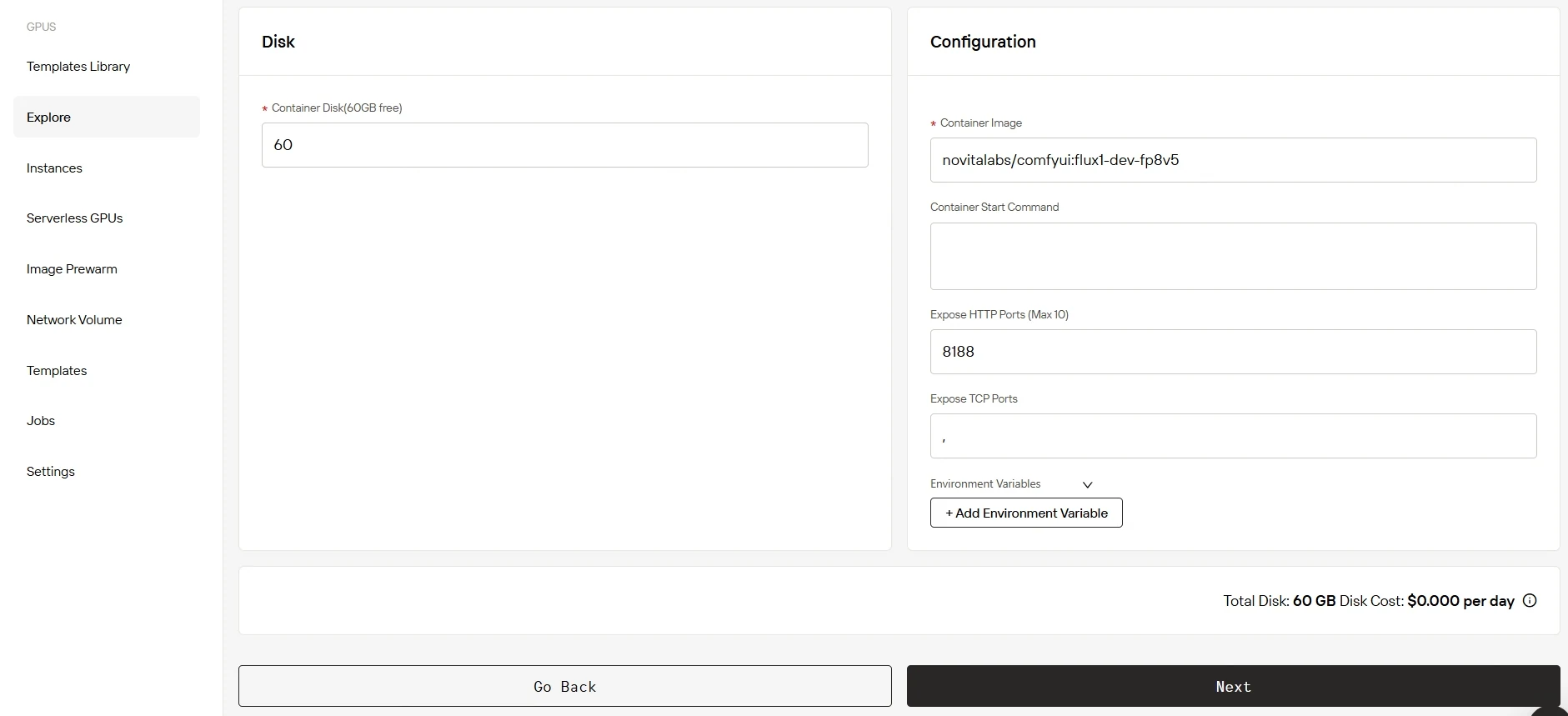
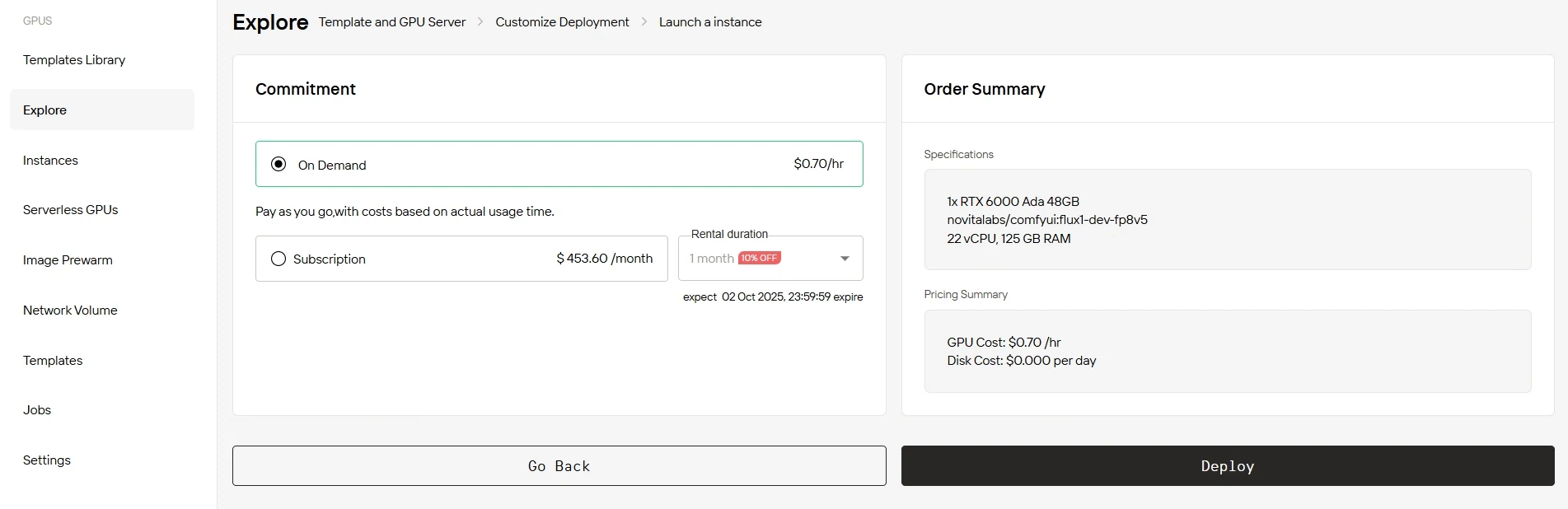
ステップ4:インスタンスを起動
「Deploy」をクリックしてデプロイを開始してください。数分以内に高性能GPU環境が準備完了し、機械学習、レンダリング、計算プロジェクトをすぐに開始できます。
結論
- RTX 5090を選ぶべき場合:生の性能が最優先の場合。4Kゲーミング、AIワークロード、高度なレンダリング向けに設計されており、最も要求の厳しいプロジェクトに対して最先端のスピードと性能を提供します。ただし、消費電力とコストが高くなる点に注意してください。
- RTX 6000 Adaを選ぶべき場合:安定性が最も重要である場合。大規模なAIモデル、シミュレーション、3Dデザインをエラーや中断なく処理するように設計されています。信頼性の高いメモリ、高速なワークフロー、強力なチーム共有機能により、ミッションクリティカルな作業にエンタープライズグレードの安心感を提供します。
- 価格対性能を重視する場合、Novita AIのようなクラウドプラットフォームを利用することで、必要なときにRTX 5090と6000 Adaの性能を活用でき、高性能GPUコンピューティングを手軽かつ手頃な価格で利用できます。
よくある質問
*Novita AIは、シンプルなAPIでAIモデルをデプロイする簡単な方法を開発者に提供するAIクラウドプラットフォームであり、AIの構築・スケーリングのための手頃で信頼性の高いGPUクラウドも提供しています。



