

关键亮点
训练
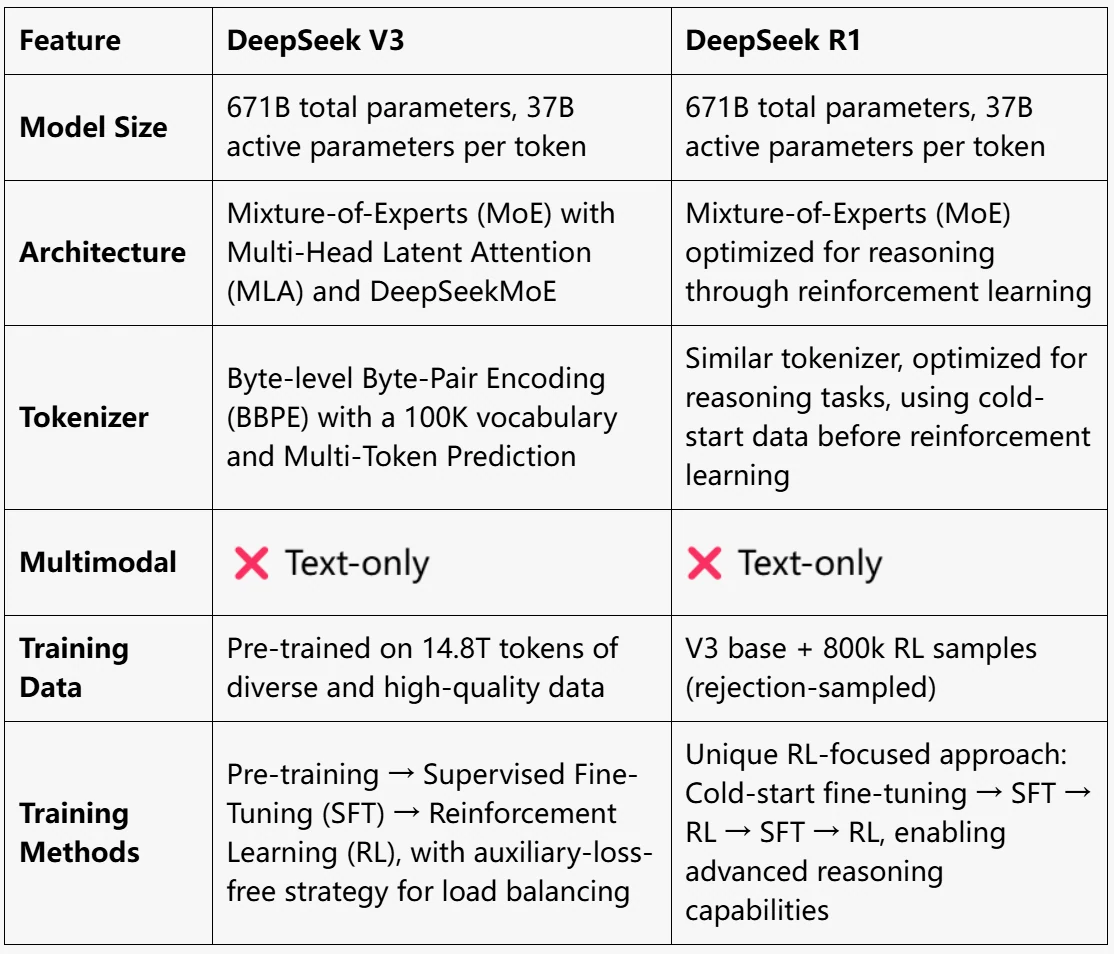
DeepSeek V3:采用传统的预训练(14.8T tokens)→ 监督微调(SFT)→ 强化学习(RL)流程。
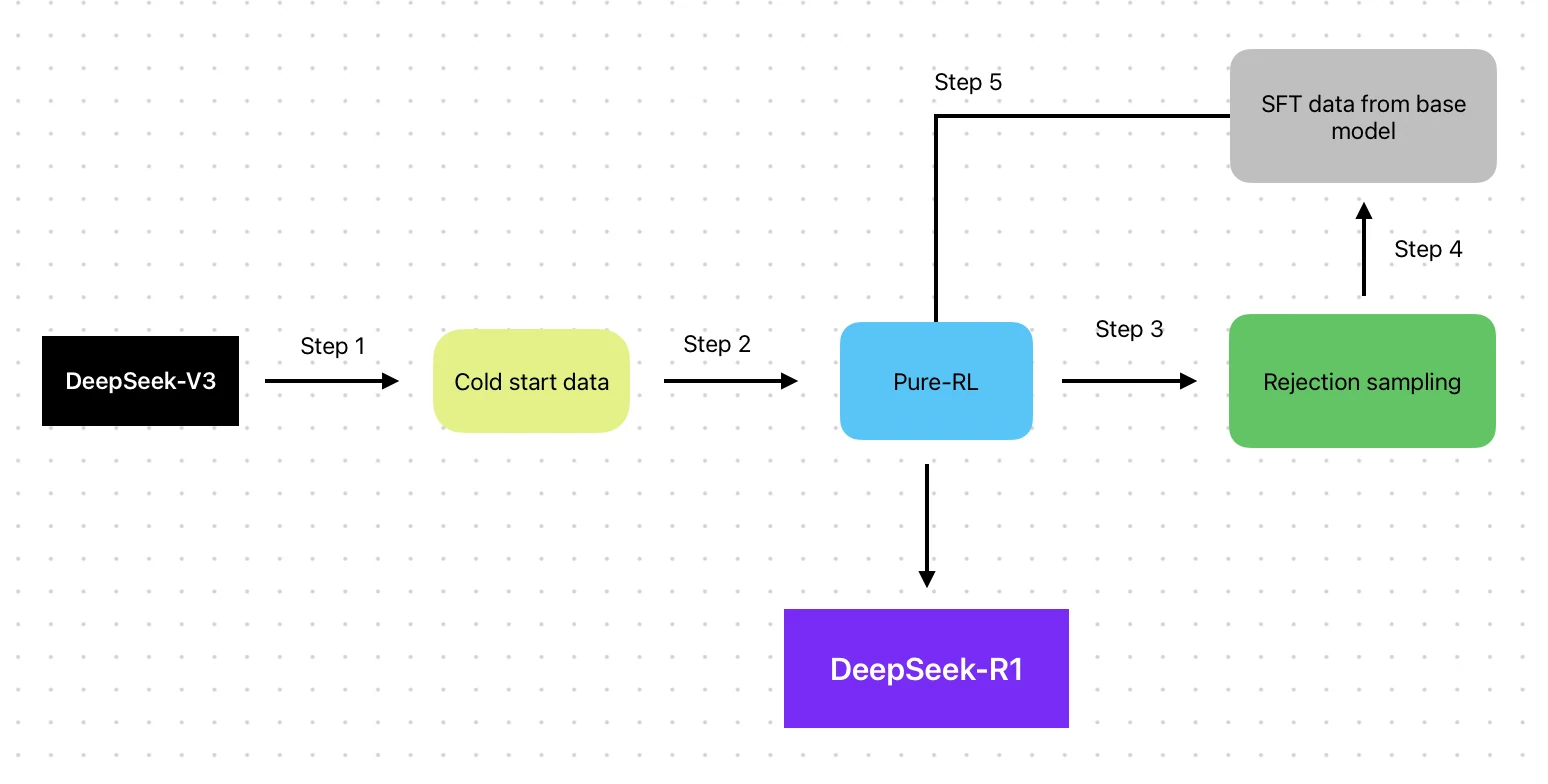
DeepSeek R1:侧重于以 RL 为核心的训练方法,从冷启动微调开始,并融合多个 RL 阶段以优化推理能力。
基准测试表现
DeepSeek V3:在各项基准上表现强劲,MMLU 得分 87.4%,MATH-500 得分 90.0%。
DeepSeek R1:在推理密集型任务中表现优异,Codeforces 得分 96.3%,MATH-500 得分 97.3%,在特定领域挑战上超越 V3。
应用场景
DeepSeek V3:通用型模型,适用于自然语言理解、代码编写和文本生成,广泛应用于教育、内容创作和业务自动化。
DeepSeek R1:针对高级推理任务(如逻辑推理和多步骤问题求解)进行了优化,适合医疗、金融、法律服务等行业特定场景。
如果您希望在自己用例中评估 DeepSeek V3 与 R1——注册后,Novita AI 将提供 $0.5 的免费额度助您起步!
AI 领域因 DeepSeek V3 和 R1 模型的推出而发生了革命性变化。这些先进的语言模型代表了自然语言处理与推理能力的重大里程碑。本文将对 DeepSeek V3 和 DeepSeek R1 进行详细对比,深入探讨它们的特性、性能及实际应用。
模型基础介绍
首先,我们来了解每个模型的基本特征。
DeepSeek V3
- 发布日期:2024 年 12 月 27 日
- 模型规格:
- 主要特点:
- 模型大小:671B 参数(每 token 激活 37B)
- 分词器:基于 SentencePiece 的多语言分词器
- 支持语言:专注于中文、英文和日文
- 多模态:纯文本
- 上下文窗口:128K tokens
- 存储格式:FP8/BF16 推理
- 架构:混合专家(MoE)+ 多头潜注意力
- 训练方法:预训练 → 监督微调(SFT)→ 强化学习(RL)
- 训练数据:预训练使用 14.8T tokens
DeepSeek R1
- 发布日期:2025 年 1 月 21 日
- 模型规格:
- 主要特点:
- 模型大小:671B 参数(每 token 激活 37B)
- 分词器:增强版分词器,带自我反思标签
- 支持语言:多语言,具备文化适应性
- 多模态:纯文本
- 上下文窗口:128K tokens
- 存储格式:支持 Q8/Q5 量化
- 架构:混合专家(MoE)+ RL 增强训练管道
- 训练方法:基于 V3 基础,采用 RL 管道(SFT → RL → SFT → RL)
- 训练数据:V3 基础数据 + RL 优化数据
模型对比
共同点:
- 模型大小相同(671B 参数,每 token 激活 37B)。
- 均使用混合专家(MoE)架构。
- 在多语言模型(英文和中文)中表现出色。
主要差异:
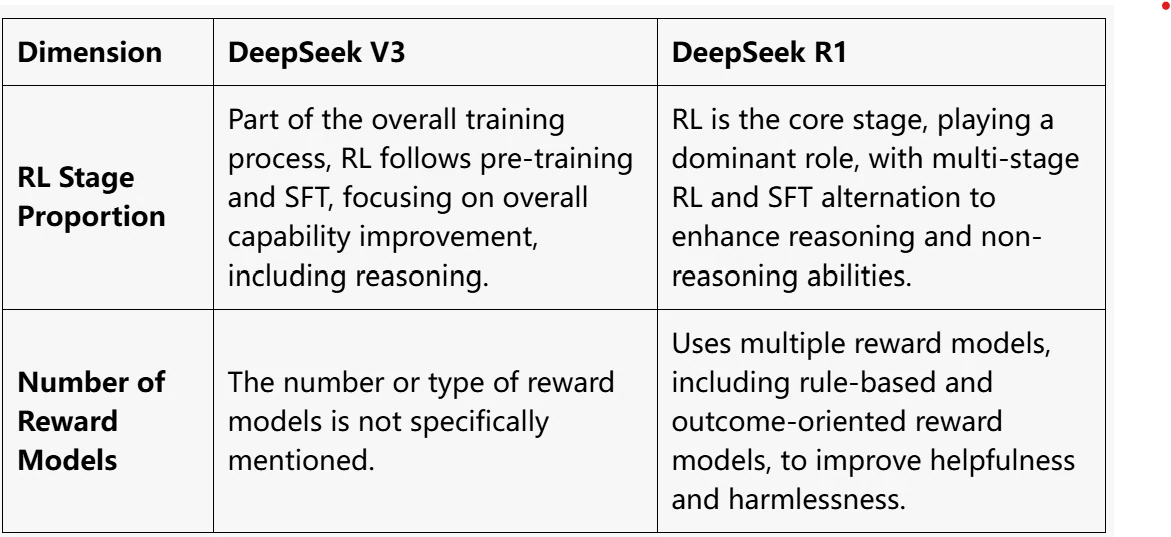
- 训练方法:V3 采用传统的预训练、监督微调(SFT)和强化学习(RL)管道。相比之下,R1 侧重于以 RL 为核心的方法,融合冷启动微调和奖励机制以增强推理能力。
速度对比
如果您想亲自测试,可以在 Novita AI 网站上开始免费试用。
速度对比
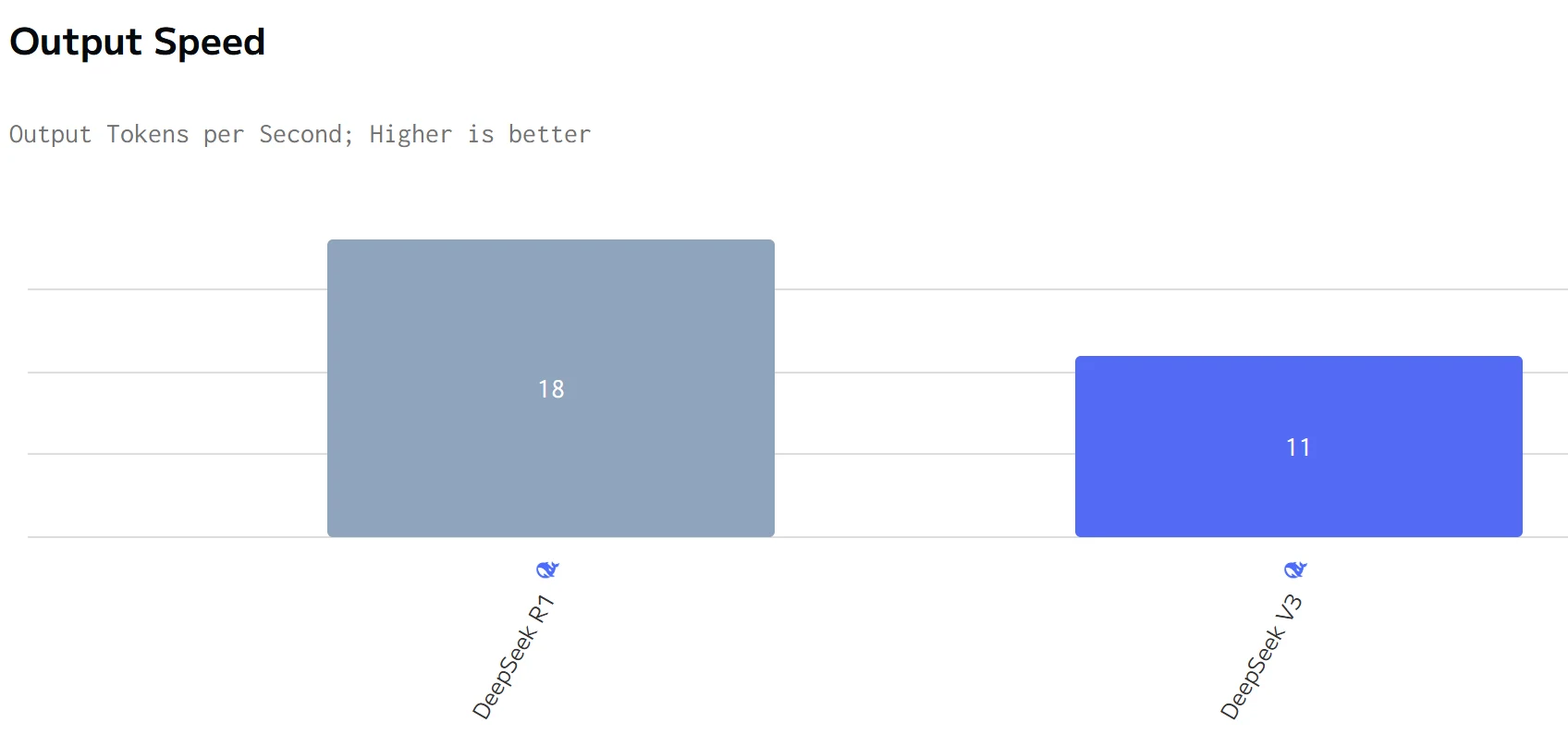
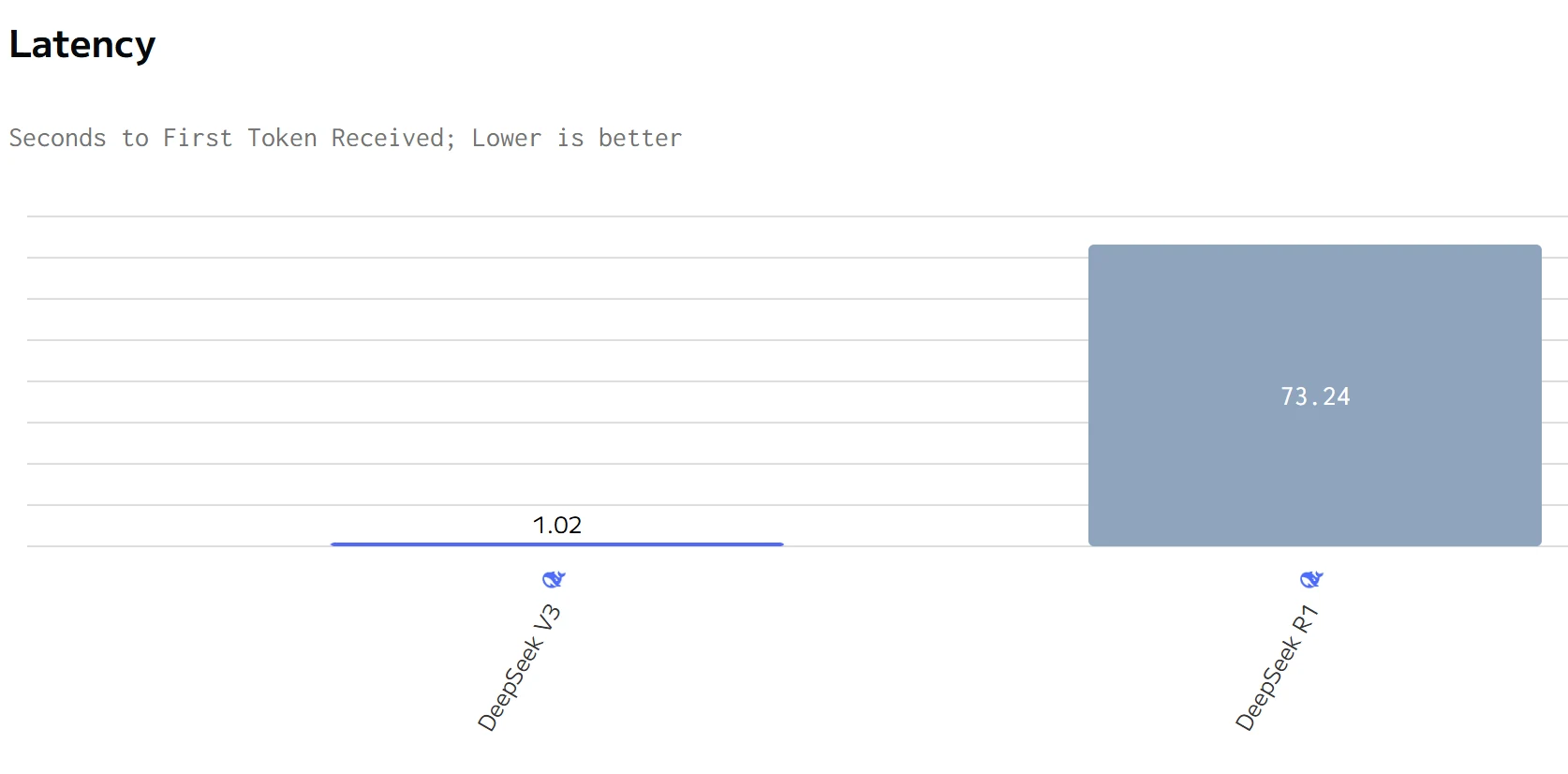
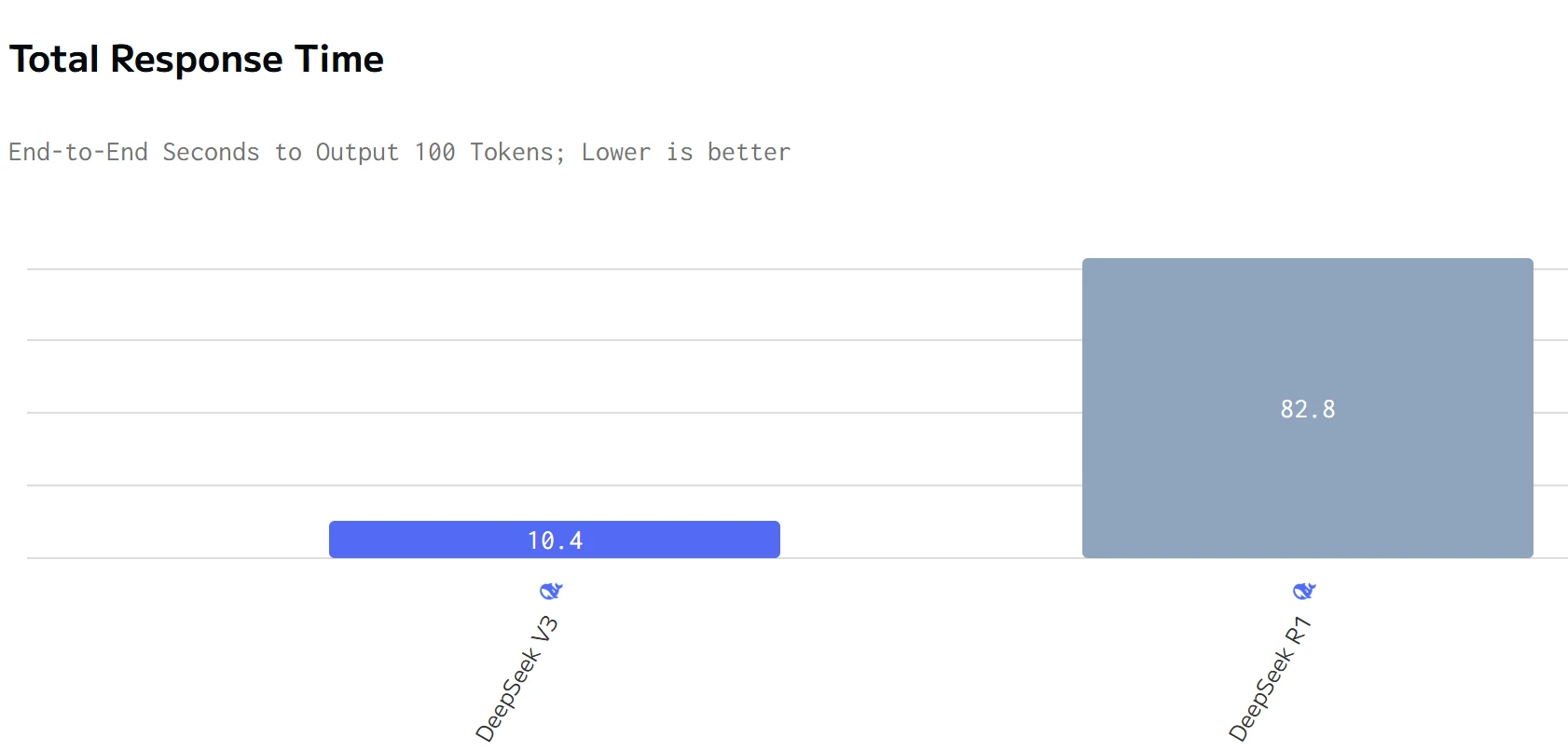
数据来源:artificialanalysis
成本对比
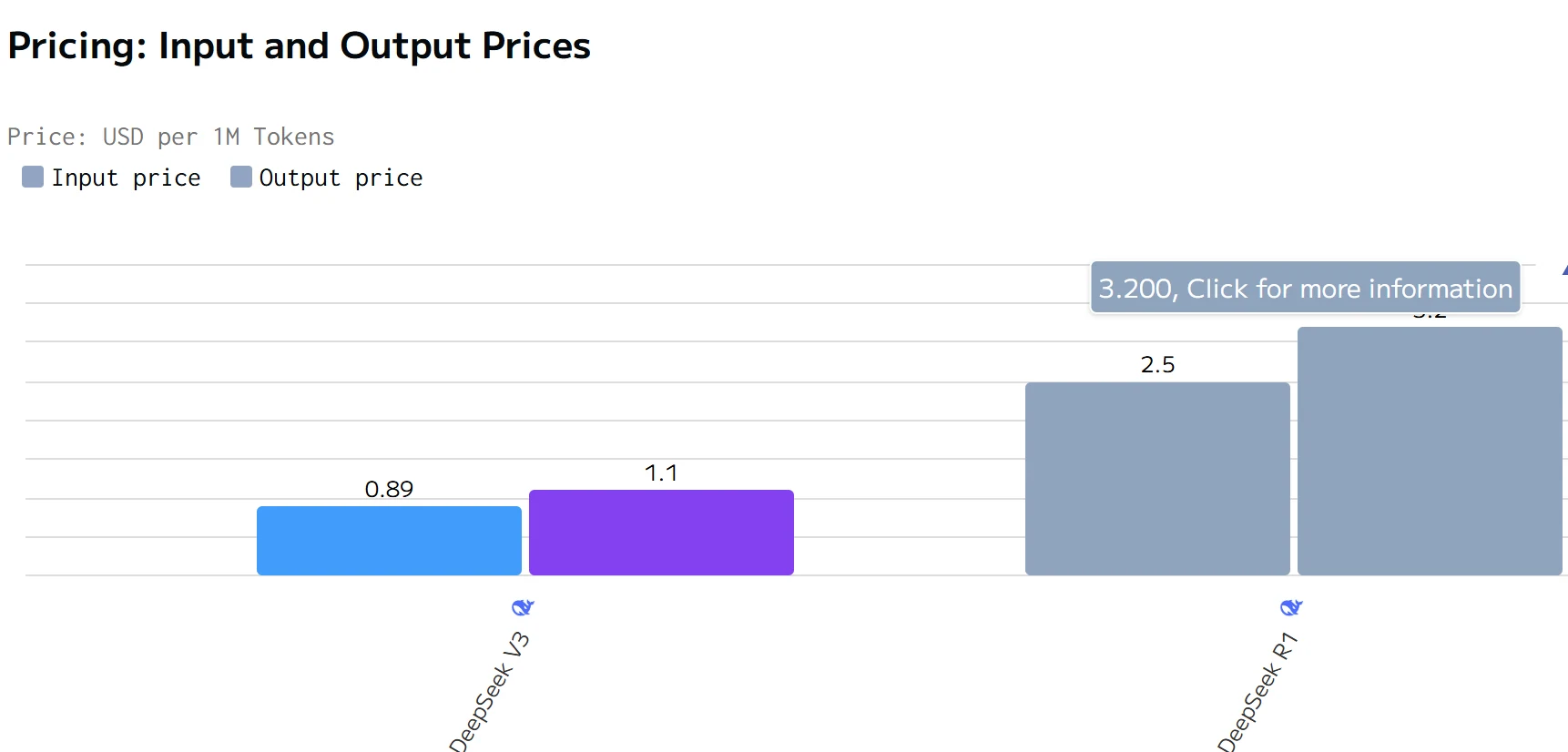
数据来源:artificialanalysis
DeepSeek R1 在输出速度上超越 DeepSeek V3,但总响应时间更长。DeepSeek R1 的输入和输出价格均显著高于 DeepSeek V3。
基准测试对比
了解了每个模型的基本特征后,我们来深入分析它们在各项基准上的表现。通过对比,可以更清晰地展示它们在不同领域的优势。
| 基准测试 | DeepSeek-R1 (%) | DeepSeek-V3 (%) |
|---|---|---|
| Codeforces | 96.3 | 63.6 |
| GPQA Diamond | 71.5 | 62.1 |
| MATH-500 | 97.3 | 90.0 |
| MMLU | 90.8 | 87.4 |
这些结果表明,DeepSeek-R1 在推理密集型和特定领域任务(如 Codeforces 和 MATH-500)上优化得更好,而 DeepSeek-V3 在这些基准上表现强劲,但略低一些。
如果您想查看更多对比,可以参考以下文章:
应用场景
DeepSeek V3
- 适用于广泛的任务,包括自然语言理解、代码编写和基础问题求解。
- 可应用于教育、内容创作和业务自动化等行业。
- 在文本生成、代码补全和数学推理等领域表现出色。
- 通用型模型,适合多种应用场景。
DeepSeek R1
- 针对需要高级推理、逻辑推断和数学问题求解的任务进行了定制。
- 适合处理医疗、金融和法律服务等领域的复杂行业特定挑战。
- 在需要长链思维(CoT)推理的任务中尤为有效,例如诊断复杂问题、分析多步骤场景以及从大量数据中综合洞察。
通过 Novita AI 实现接入与部署
Novita AI 是一个 AI 云平台,为开发者提供简单 API 来轻松部署 AI 模型,同时提供经济可靠的 GPU 云服务,用于构建和扩展模型。
步骤 1:登录并访问模型库
登录您的账户,点击 模型库 按钮。

步骤 2:选择模型
浏览可用选项,选择满足您需求的模型。

步骤 3:开始免费试用
开始免费试用,探索所选模型的功能。

步骤 4:获取 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入“设置”页面,如图所示复制 API 密钥。

步骤 5:安装 API
使用您编程语言对应的包管理器安装 API。

安装完成后,在开发环境中导入必要的库。使用您的 API 密钥初始化客户端,即可与 Novita AI LLM 进行交互。以下是一个 Python 用户使用聊天补全 API 的示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_v3"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
注册后,Novita AI 将提供 $0.5 的免费额度助您起步!
如果免费额度用完,您可以付费继续使用。
DeepSeek V3 和 DeepSeek R1 是两款功能强大的 LLM,各有优势。DeepSeek V3 是一款通用型模型,以其高效性和在各类任务上的强劲表现而著称。而 DeepSeek R1 则是一款针对高级推理进行优化的专用模型。选择哪个模型取决于应用的具体需求。两款模型都是该领域的重要进步,凭借其性能、效率以及开源可访问性,对现有模型形成了挑战。
常见问题解答
DeepSeek V3 和 R1 的主要区别是什么?
DeepSeek V3 是通用型模型,而 R1 专为高级推理任务设计。
这些模型需要特殊硬件吗?
是的,两款模型都很大,需要高性能硬件,特别是具有大容量显存的 GPU。
模型是如何训练的?
DeepSeek V3 在 14.8 万亿 tokens 上进行了预训练。DeepSeek R1 基于 DeepSeek V3,通过微调和强化学习来获得推理能力。
Novita AI 是一体化云平台,助力您的 AI 雄心。集成 API、无服务器、GPU 实例——您所需的经济高效工具。无需基础设施,免费开始,让您的 AI 愿景成为现实。



