

Ключевые моменты
Обучение
DeepSeek V3: Следует традиционному конвейеру: предварительное обучение (14,8 трлн токенов) → контролируемая точная настройка (SFT) → обучение с подкреплением (RL).
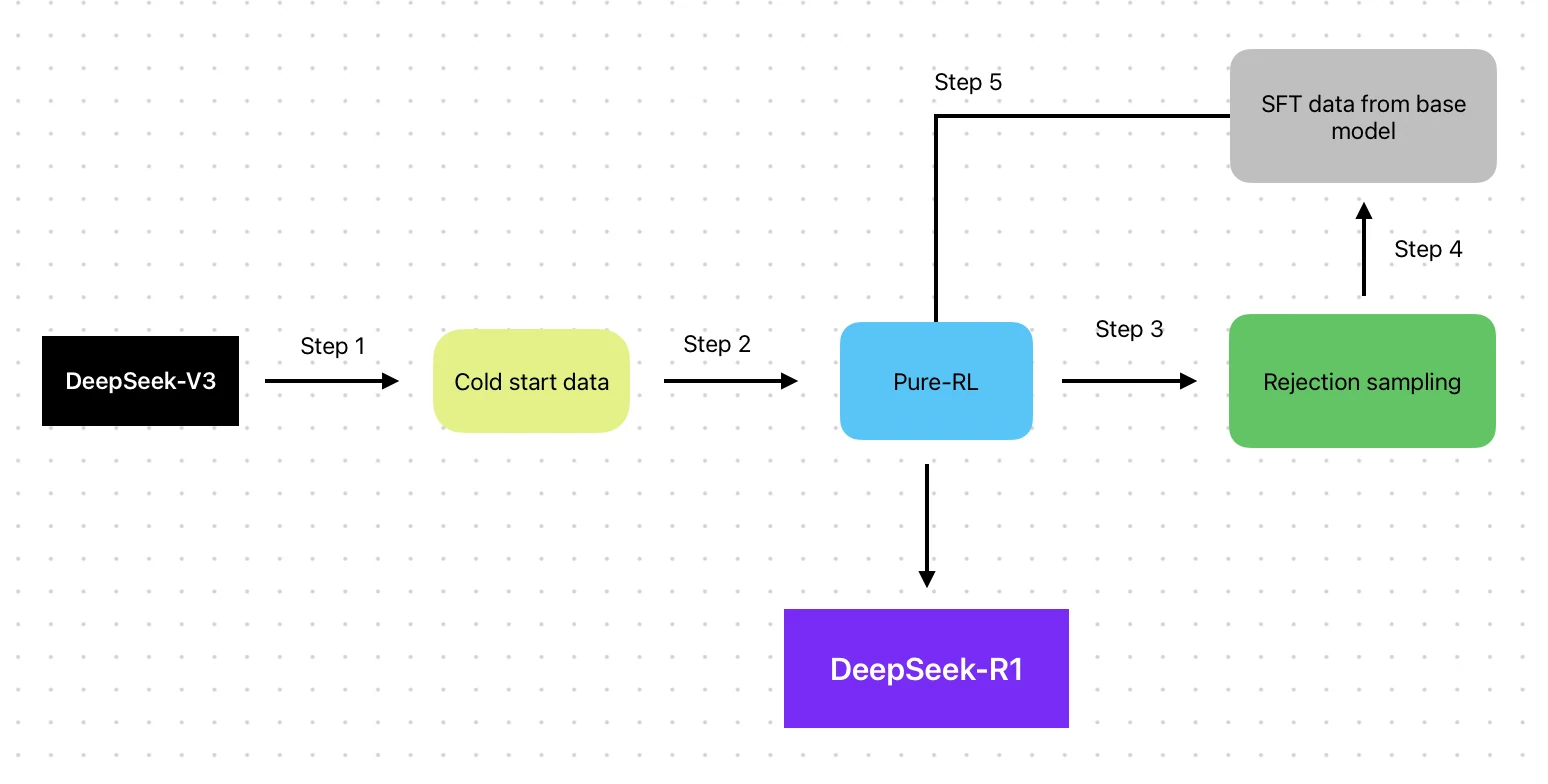
DeepSeek R1: Фокусируется на подходе обучения с акцентом на RL, начиная с «холодного старта» (cold-start fine-tuning) и интегрируя несколько этапов RL для оптимизации рассуждений.
Производительность на бенчмарках
DeepSeek V3: Высокая общая производительность на бенчмарках, достигающая 87,4% на MMLU и 90,0% на MATH-500.
DeepSeek R1: Превосходит в задачах, требующих интенсивных рассуждений: 96,3% на Codeforces и 97,3% на MATH-500, опережая V3 в специализированных доменных задачах.
Применение
DeepSeek V3: Универсальная модель общего назначения, подходящая для понимания естественного языка, написания кода и генерации текста, широко применяется в образовании, создании контента и бизнес-автоматизации.
DeepSeek R1: Оптимизирована для продвинутых задач рассуждения, таких как логический вывод и многошаговое решение проблем, идеально подходит для здравоохранения, финансов, юридических услуг и других отраслевых сценариев.
Если вы хотите оценить DeepSeek V3 и R1 на своих собственных задачах — после регистрации Novita AI предоставляет кредит в размере $0,5 для начала работы!
Мир ИИ был революционизирован появлением моделей DeepSeek V3 и R1. Эти продвинутые языковые модели представляют собой значительные вехи в области обработки естественного языка и способности к рассуждению. Эта статья предоставляет детальное сравнение DeepSeek V3 и DeepSeek R1, исследуя их характеристики, производительность и практическое применение.
Основное описание моделей
Для начала сравнения сначала разберёмся с фундаментальными характеристиками каждой модели.
DeepSeek V3
- Дата выпуска: 27 декабря 2024 года
- Масштаб модели:
- Ключевые особенности:
- Размер модели: 671B параметров (37B активных на токен)
- Токенизатор: Многоязычный токенизатор на основе SentencePiece
- Поддерживаемые языки: Акцент на китайский, английский и японский
- Мультимодальность: Только текст
- Контекстное окно: 128K токенов
- Форматы хранения: FP8/BF16 инференс
- Архитектура: Смесь экспертов (MoE) + Многоголовое скрытое внимание (Multi-Head Latent Attention)
- Метод обучения: Предварительное обучение → Контролируемая точная настройка (SFT) → Обучение с подкреплением (RL)
- Данные для обучения: 14,8 трлн токенов для предварительного обучения
DeepSeek R1
- Дата выпуска: 21 января 2025 года
- Масштаб модели:
- Ключевые особенности:
- Размер модели: 671B параметров (37B активных на токен)
- Токенизатор: Улучшенный токенизатор с тегами саморефлексии
- Поддерживаемые языки: Многоязычный с культурной адаптацией
- Мультимодальность: Только текст
- Контекстное окно: 128K токенов
- Форматы хранения: Поддержка квантования Q8/Q5
- Архитектура: Смесь экспертов (MoE) + Pipeline обучения, усиленный RL
- Метод обучения: Построен на базе V3 с RL-конвейером (SFT → RL → SFT → RL)
- Данные для обучения: База V3 + данные оптимизации RL
Сравнение моделей
Сходства:
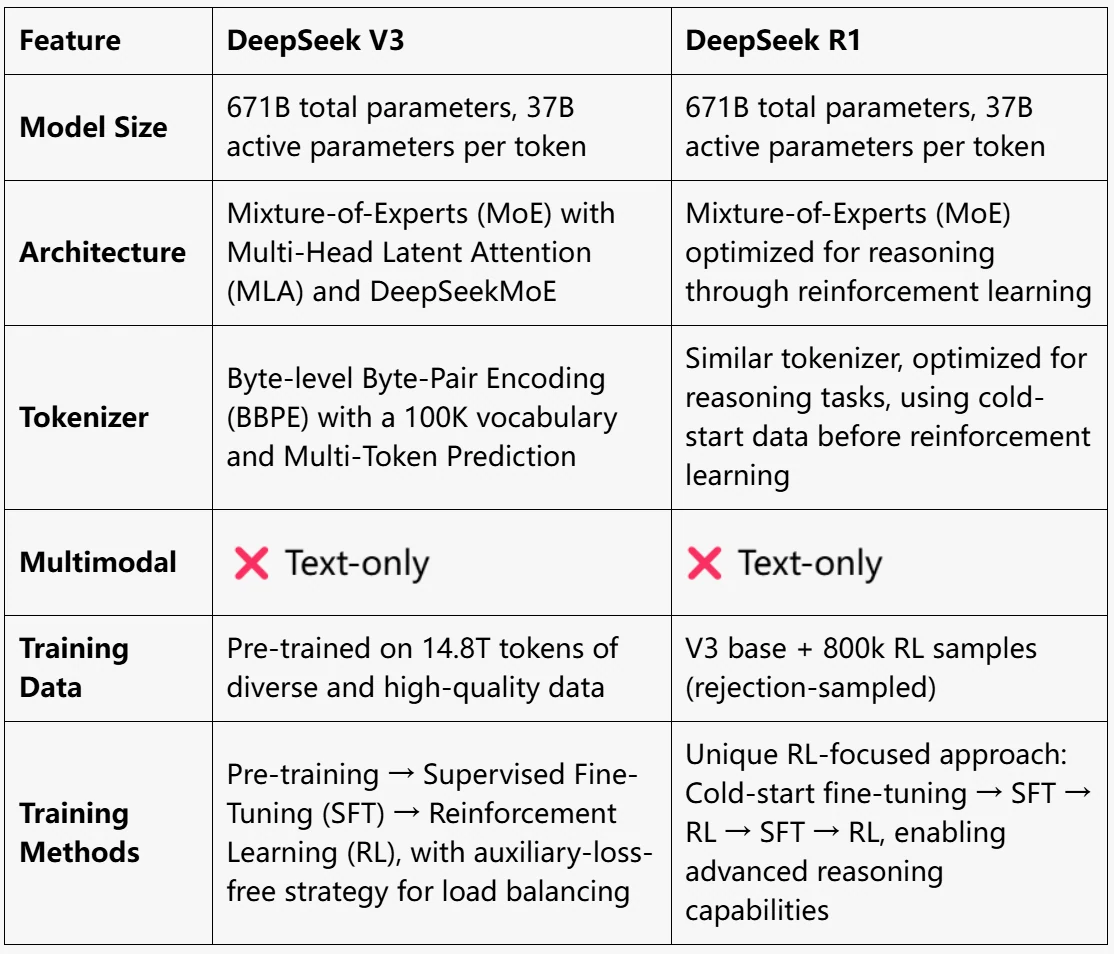
- Обе имеют одинаковый размер модели (671B параметров, 37B активных параметров на токен).
- Обе используют архитектуру «Смесь экспертов» (MoE).
- Обе являются многоязычными моделями, превосходно работающими с английским и китайским языками.
Ключевые различия:
- Методы обучения: V3 использует традиционный конвейер: предварительное обучение, контролируемая точная настройка (SFT) и обучение с подкреплением (RL). В отличие от этого, R1 фокусируется на подходе с акцентом на RL, включая точную настройку с «холодного старта» и механизмы вознаграждения для улучшения способностей к рассуждению.
Сравнение скорости
Если вы хотите протестировать самостоятельно, вы можете начать бесплатную пробную версию на сайте Novita AI.
Попробовать демо DeepSeek V3 сейчас!
Сравнение скорости
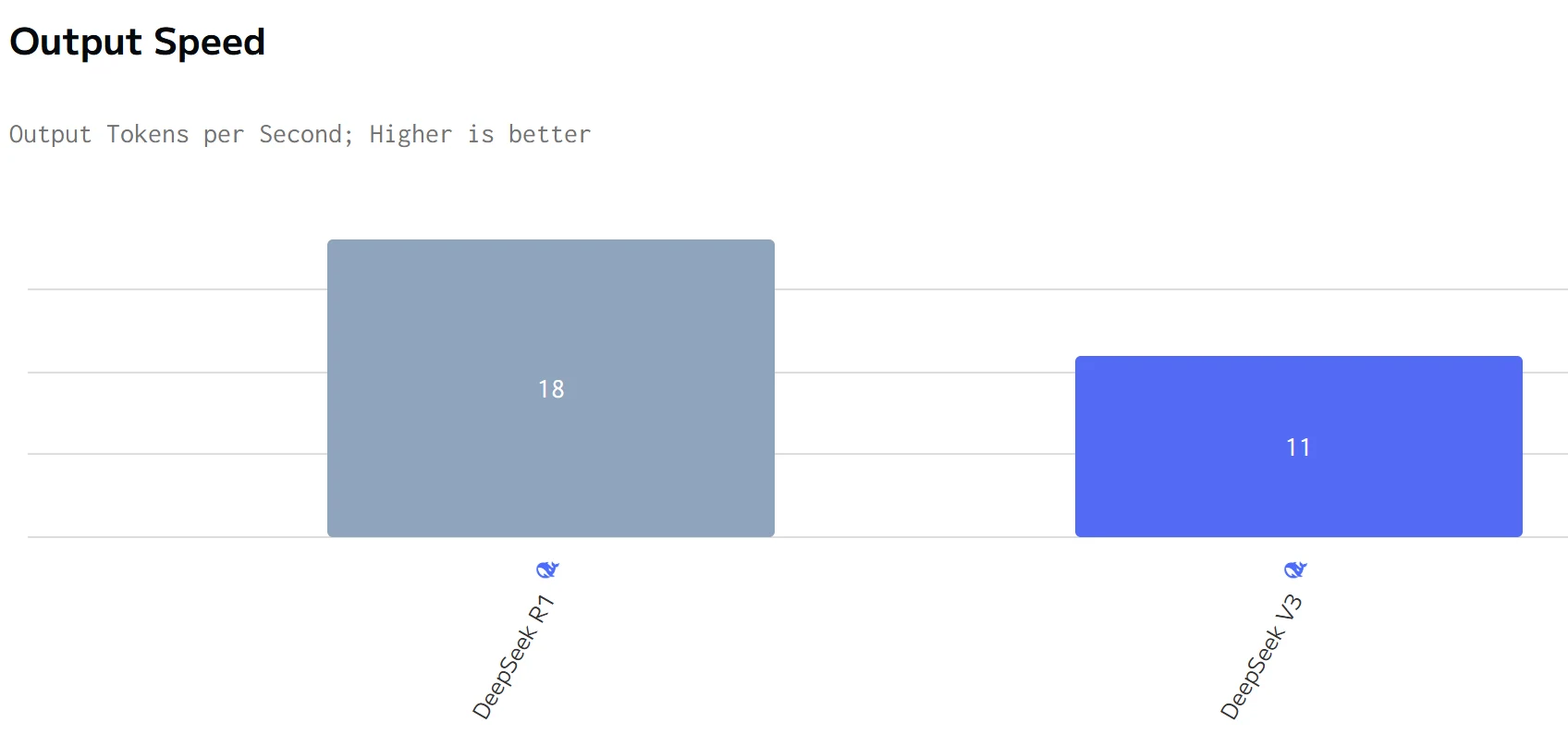
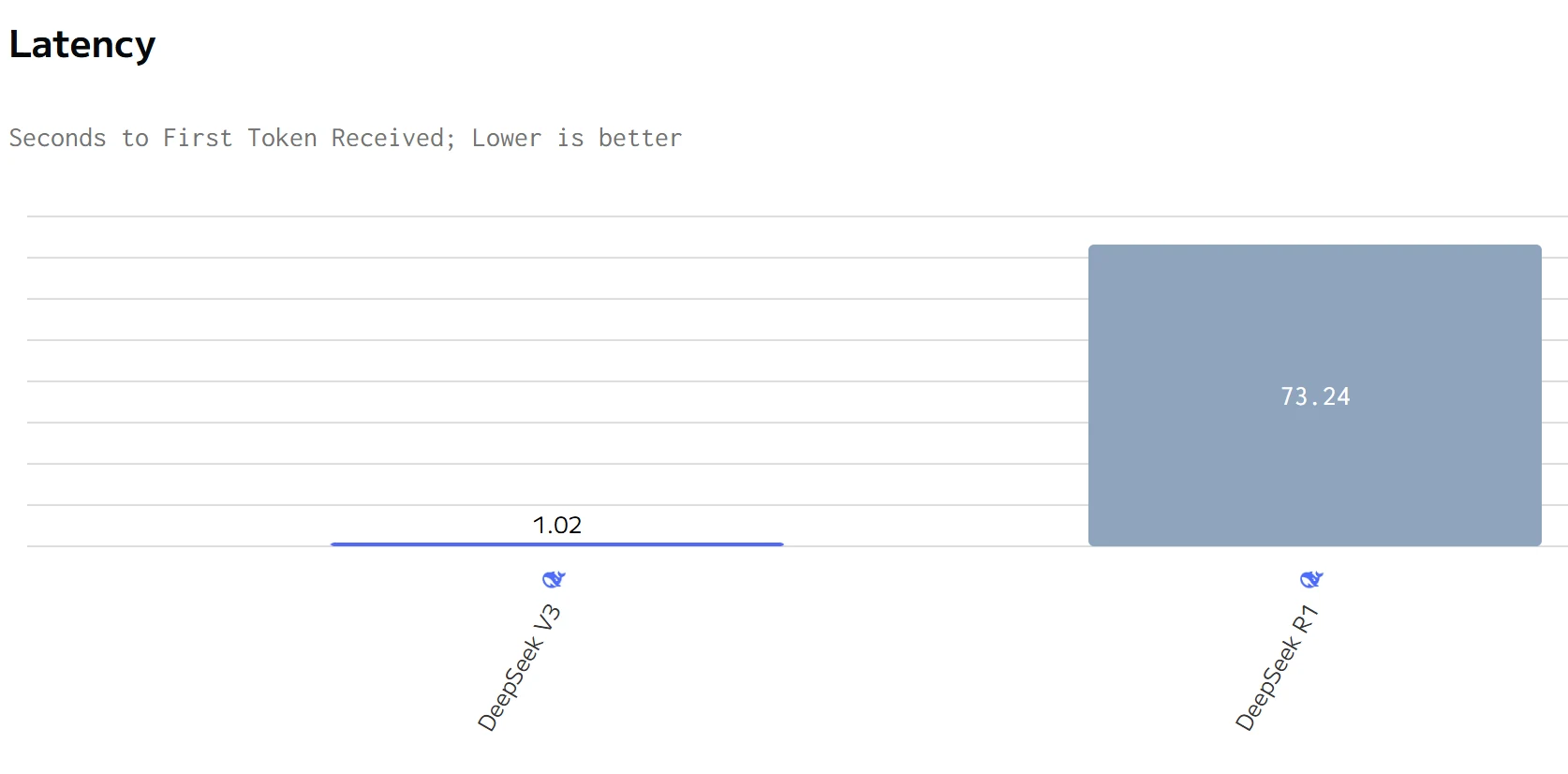
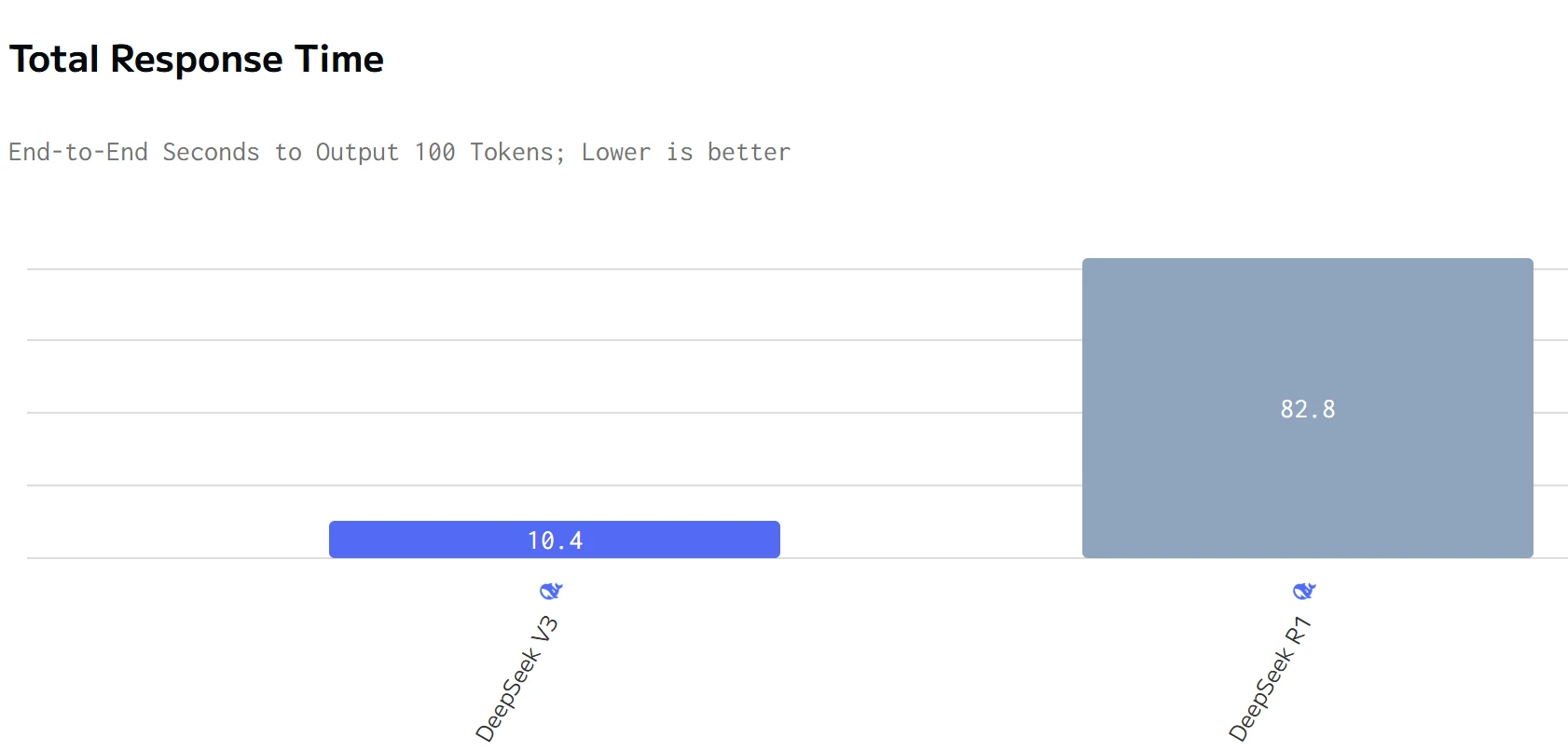
источник: artificialanalysis
Сравнение стоимости
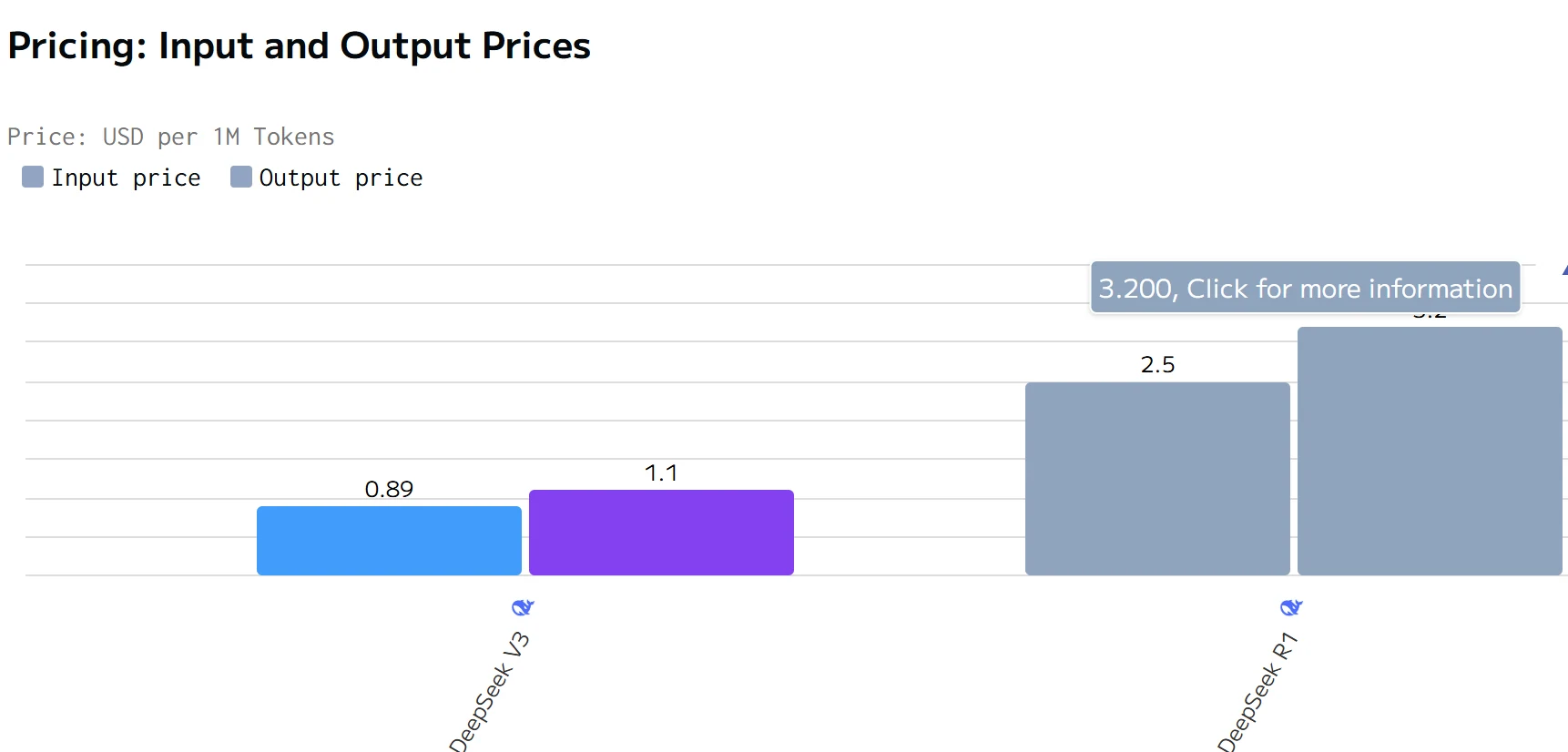
источник: artificialanalysis
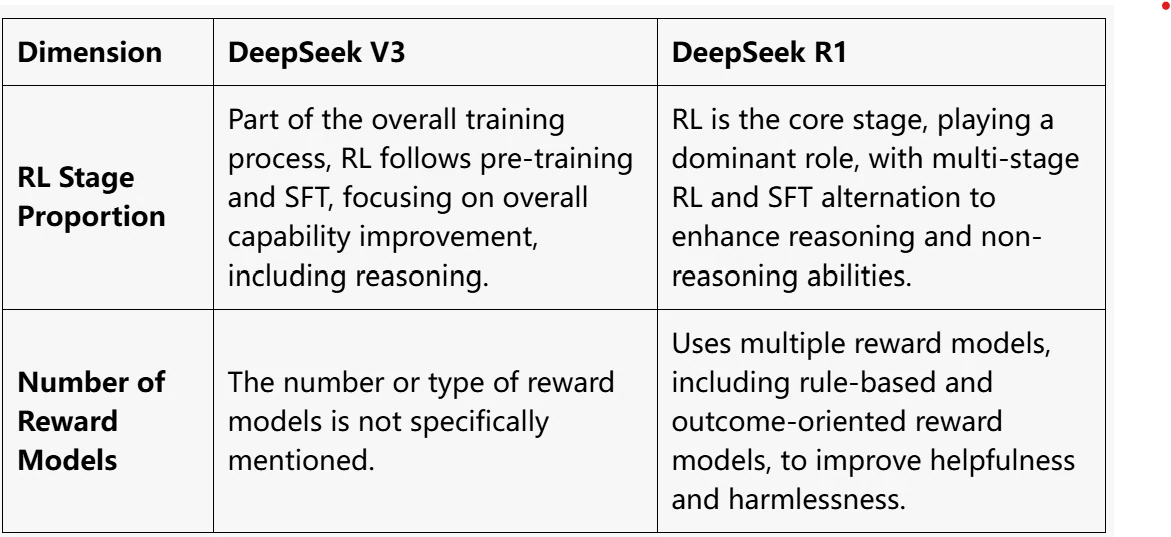
DeepSeek R1 превосходит DeepSeek V3 по скорости генерации, но имеет большее общее время ответа. Цены на ввод и вывод DeepSeek R1 значительно выше, чем у DeepSeek V3.
Сравнение бенчмарков
Теперь, когда мы установили основные характеристики каждой модели, давайте углубимся в их производительность на различных бенчмарках. Это сравнение поможет проиллюстрировать их сильные стороны в разных областях.
| Бенчмарк | DeepSeek-R1 (%) | DeepSeek-V3 (%) |
|---|---|---|
| Codeforces | 96,3 | 63,6 |
| GPQA Diamond | 71,5 | 62,1 |
| MATH-500 | 97,3 | 90,0 |
| MMLU | 90,8 | 87,4 |
Эти результаты предполагают, что DeepSeek-R1 лучше оптимизирован для задач, требующих интенсивных рассуждений и специфичных для предметной области (например, Codeforces и MATH-500), в то время как DeepSeek-V3 демонстрирует высокую, хотя и немного более низкую производительность на этих бенчмарках.
Если вы хотите увидеть больше сравнений, ознакомьтесь с этими статьями:
- Deepseek v3 vs Llama 3.3 70b: Языковые задачи против кода и математики
- Llama 3.2 3B vs DeepSeek V3: Сравнение эффективности и производительности.
Применение и варианты использования
DeepSeek V3
- Предназначена для широкого круга задач, включая понимание естественного языка, написание кода и базовое решение проблем.
- Применима в таких отраслях, как образование, создание контента и бизнес-автоматизация.
- Превосходно работает в таких областях, как генерация текста, автодополнение кода и математические рассуждения.
- Универсальная модель общего назначения, подходящая для различных приложений.
DeepSeek R1
- Специализирована для задач, требующих продвинутого рассуждения, логического вывода и решения математических задач.
- Идеально подходит для решения сложных отраслевых задач в таких сферах, как здравоохранение, финансы и юридические услуги.
- Особенно эффективна для задач, требующих расширенного цепочечного мышления (Chain-of-Thought, CoT), таких как диагностика сложных проблем, анализ многошаговых сценариев и синтез выводов из больших наборов данных.
Доступность и развёртывание через Novita AI
Novita AI — это облачная платформа ИИ, которая предоставляет разработчикам простой способ развёртывания моделей ИИ с помощью нашего простого API, а также доступный и надёжный GPU-облако для сборки и масштабирования.
Шаг 1: Войдите и откройте библиотеку моделей
Войдите в свою учётную запись и нажмите кнопку Model Library.

Шаг 2: Выберите модель
Просмотрите доступные варианты и выберите модель, подходящую для ваших нужд.

Шаг 3: Начните бесплатную пробную версию
Начните бесплатную пробную версию, чтобы изучить возможности выбранной модели.

Шаг 4: Получите ваш API-ключ
Для аутентификации в API мы предоставим вам новый API-ключ. Перейдя на страницу «Settings», вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.

После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с Novita AI LLM. Это пример использования chat completions API для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_v3"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
После регистрации Novita AI предоставляет кредит в размере $0,5 для начала работы!
Если бесплатные кредиты закончатся, вы можете оплатить и продолжить использование.
DeepSeek V3 и DeepSeek R1 — это мощные LLM с различными сильными сторонами. DeepSeek V3 — универсальная модель общего назначения, известная своей эффективностью и высокой производительностью в различных задачах. DeepSeek R1, с другой стороны, является специализированной моделью, оптимизированной для продвинутых рассуждений. Выбор между ними зависит от конкретных требований приложения. Обе модели представляют собой значительные достижения в этой области, бросая вызов существующим моделям своей производительностью, эффективностью и открытым доступом.
Часто задаваемые вопросы
В чём основное различие между DeepSeek V3 и R1?
DeepSeek V3 — это модель общего назначения, в то время как R1 специально разработана для задач продвинутого рассуждения.
Требуют ли эти модели специального оборудования?
Да, обе модели большие и требуют высокопроизводительного оборудования, особенно GPU с большим объёмом VRAM.
Как обучаются модели?
DeepSeek V3 предварительно обучена на 14,8 триллионах токенов. DeepSeek R1 основана на DeepSeek V3, используя точную настройку и обучение с подкреплением для способностей к рассуждению.
Novita AI — это универсальная облачная платформа, которая расширяет ваши возможности в области ИИ. Интегрированные API, бессерверные решения, GPU-инстансы — экономичные инструменты, которые вам нужны. Устраните инфраструктурные барьеры, начните бесплатно и воплотите ваше видение ИИ в реальность.



