

Что такое LlamaIndex
LlamaIndex — это оркестрационный фреймворк, который упрощает подключение частных и публичных данных к LLM. Он предоставляет необходимые инструменты для приёма, структурирования и поиска данных, помогая разработчикам создавать надёжные приложения на базе LLM без необходимости создавать эти компоненты с нуля. Фреймворк оптимизирует часто сложный процесс подготовки данных для использования LLM и извлечения релевантной информации по мере необходимости.
Ключевые возможности LlamaIndex
- Совместимость с разнообразными источниками данных: Исключительные интеграционные возможности поддерживают различные источники данных — от файлов и баз данных до приложений, обеспечивая универсальность и гибкость для разных отраслей и сценариев использования.
- Богатая экосистема коннекторов: Готовые коннекторы для приёма данных позволяют разработчикам быстро и бесшовно подключать свои данные к большим языковым моделям (LLM), устраняя сложность пользовательских интеграционных решений и значительно повышая эффективность разработки.
- Интеллектуальная система поиска данных: Продвинутый интерфейс запросов гарантирует, что разработчики и пользователи точно получают наиболее релевантную информацию по своим запросам, оптимизируя пользовательский опыт и повышая точность информации.
- Настраиваемые стратегии индексации: Разнообразные варианты индексации позволяют оптимизировать систему для конкретных типов данных и требований к запросам, повышая скорость и точность поиска, обеспечивая оптимальную производительность для различных сценариев приложений.
Реальные сценарии использования LlamaIndex
- Диалоговые ассистенты документации: Разработка сложных чат-ботов на естественном языке, которые обеспечивают мгновенное взаимодействие с документацией продуктов, значительно повышая вовлечённость клиентов и сокращая количество запросов в поддержку за счёт интуитивного доступа к знаниям.
- Адаптивные агенты знаний: Создание интеллектуальных агентов, способных ориентироваться в сложных деревьях решений на основе постоянно расширяющихся хранилищ знаний, предоставляя персонализированные ответы, которые развиваются вместе с бизнес-аналитикой и потребностями клиентов.
- Расширенные решения семантического поиска: Внедрение мощных систем обработки естественного языка, позволяющих интуитивно взаимодействовать с огромными хранилищами структурированных данных, революционизируя поиск информации в различных корпоративных приложениях.
- Стратегическое обогащение данных: Использование передовых методов для бесшовного объединения публичных наборов данных с собственными корпусами знаний, создавая уникально ценные информационные экосистемы, которые стимулируют вовлечённость в приложения и обеспечивают превосходный пользовательский опыт.
Как работает LlamaIndex
Комплексная платформа оркестрации данных LlamaIndex работает через три основных этапа обработки: приём данных, интеллектуальная индексация и продвинутый поиск.
- Приём данных
LlamaIndex упрощает интеграцию данных для приложений LLM, предоставляя универсальные коннекторы для API, баз данных, PDF и различных форматов документов. Этот комплексный набор инструментов позволяет легко включать как структурированные, так и неструктурированные данные, давая разработчикам возможность создавать более эффективные AI-решения с минимальными накладными расходами на интеграцию.
- Индексация данных
После приёма данных LlamaIndex использует различные методы индексации для организации данных с целью эффективного поиска, включая:
- Списочный индекс: Упорядочивает данные последовательно, идеально подходит для наборов данных, которые развиваются со временем.
- Древовидный индекс: Реализует структуру бинарного дерева, идеально подходит для иерархической организации данных.
- Индекс векторного хранилища: Кодирует данные как векторные эмбеддинги для эффективного поиска на основе сходства.
- Ключевой индекс: Связывает теги метаданных с узлами данных, поддерживая запросы на основе ключевых слов.
Во время индексации данные преобразуются в многомерные векторные эмбеддинги. Это преобразование позволяет получить нюансированное представление данных, улучшая детализацию и точность результатов поиска.
- Запросы
LlamaIndex использует обработку естественного языка (NLP) и инженерию промптов для обеспечения бесшовных запросов. Пользователи могут взаимодействовать с данными через запросы на естественном языке, которые интерпретируются и обрабатываются для извлечения релевантной информации из проиндексированных данных. Эта функциональность поддерживает разнообразные приложения, включая чат-ботов, агентов знаний, семантический поиск и дополнение данных.
Как использовать LlamaIndex
LlamaIndex (GPT Index) — это фреймворк данных для вашего LLM-приложения. Создание с помощью LlamaIndex обычно включает работу с ядром LlamaIndex и выбранным набором интеграций (или плагинов). Есть два способа начать разработку с LlamaIndex в Python:
- Начальный:
pip install llama-index. Начальный пакет Python, включающий ядро LlamaIndex, а также подборку интеграций. - Настраиваемый:
pip install llama-index-core. Установите ядро LlamaIndex и добавьте необходимые пакеты интеграций LlamaIndex с LlamaHub, которые требуются для вашего приложения. Существует более 300 пакетов интеграций LlamaIndex, которые бесшовно работают с ядром, позволяя вам создавать приложения с вашими предпочтительными поставщиками LLM, эмбеддингов и векторных хранилищ.
Как интегрировать Novita AI API с LlamaIndex
Предварительные требования
- Базовые знания Python и LlamaIndex.
- Доступ к платформе Novita AI и API-ключ.
- Установленный Python 3.7 или выше.
Шаги по использованию LlamaIndex с Novita AI
Шаг 1: Посетите Библиотеку моделей на Novita AI и выберите интересующую модель
Шаг 2: Перейдите на страницу демо-версии выбранной модели и нажмите кнопку Code справа
Шаг 3: Скопируйте название модели и запишите его
Шаг 4: Войдите в платформу Novita
Шаг 5: После входа перейдите на страницу настроек платформы
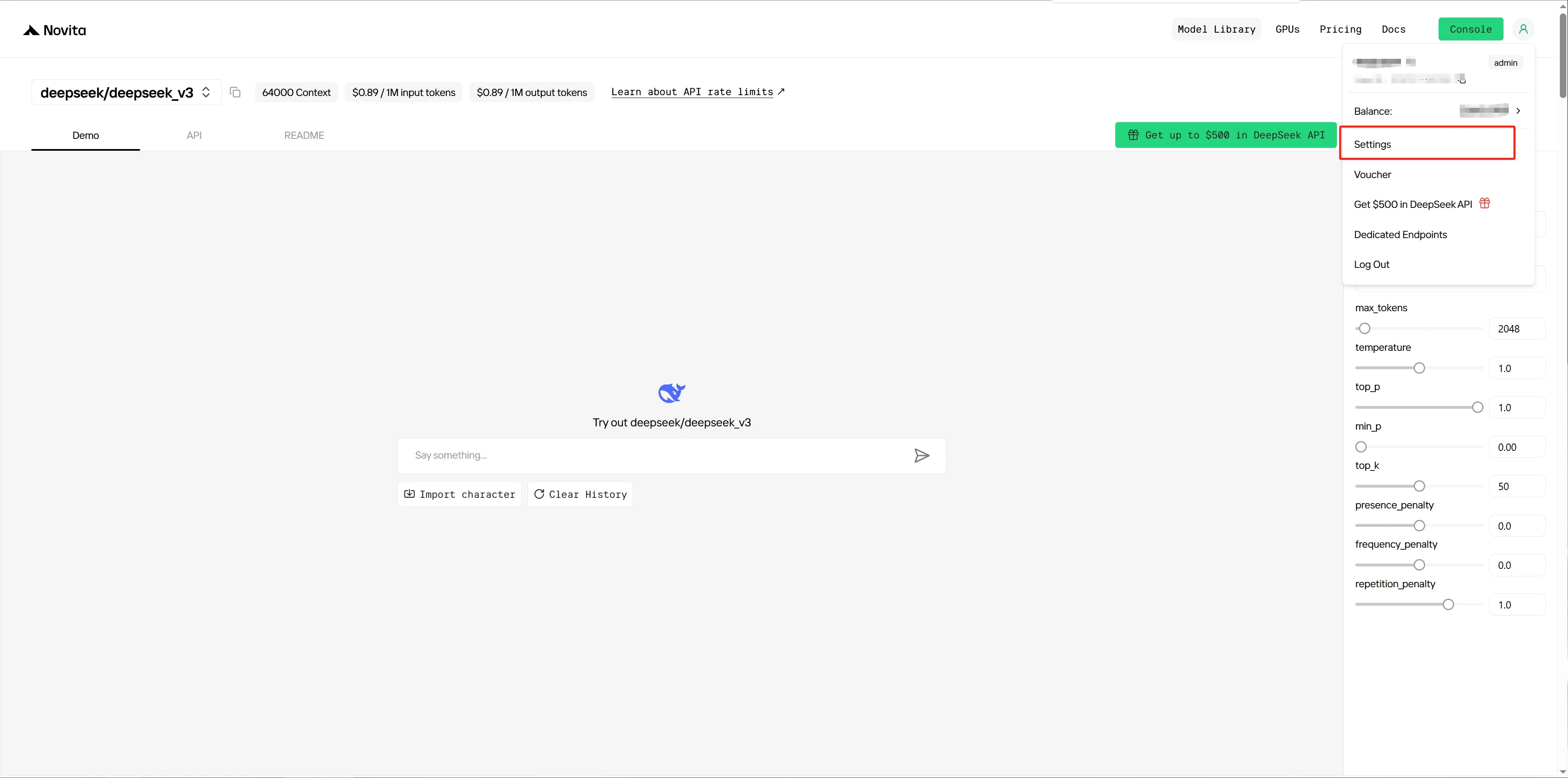
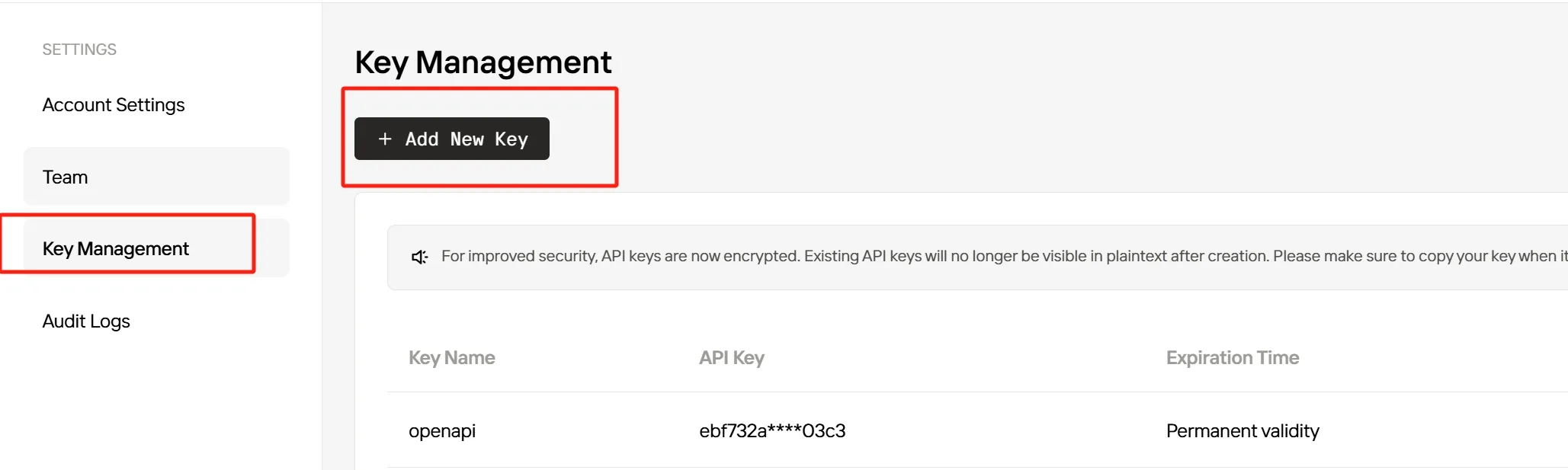
Шаг 6: Создайте новый API-ключ и скопируйте его для аутентификации сервиса
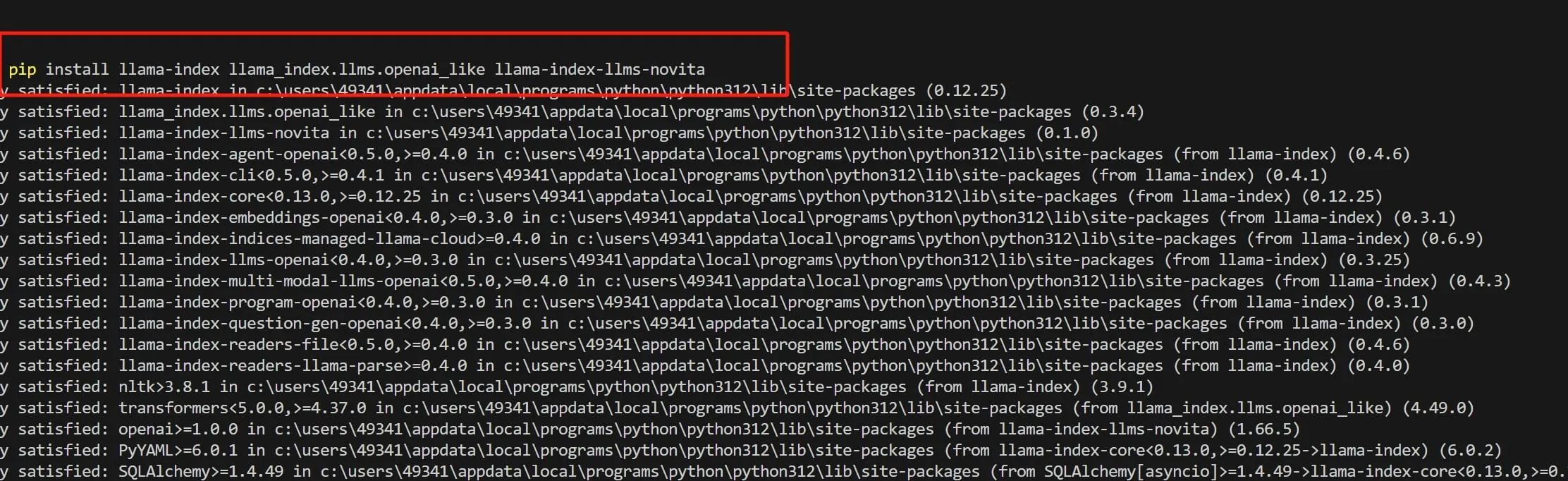
Шаг 7: Установите llama_index и связанные библиотеки Python, выполнив:
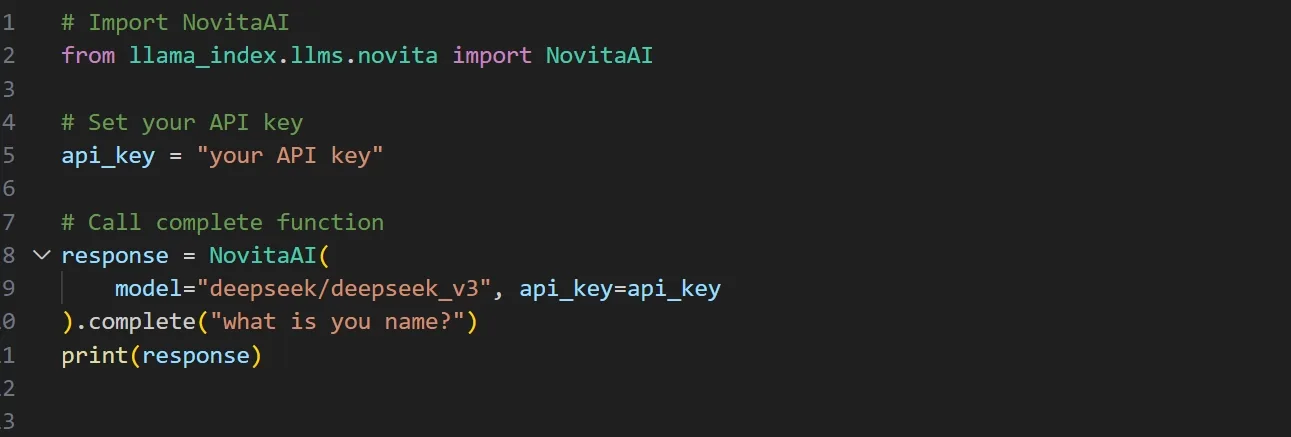
Шаг 8: Напишите код Python и задайте имя модели и API-ключ как параметры в классе NovitaAI
Шаг 9: Запустите код, чтобы получить результат

Больше примеров см. в документации: llama_index/llama-index-integrations/llms/llama-index-llms-novita at main · run-llama/llama_index.
Полезные ссылки и ресурсы LlamaIndex
- LlamaIndex.TS (Typescript/Javascript)
- Документация
- Discord
Заключение
В заключение, интеграция LlamaIndex с Novita AI открывает мощные возможности для создания продвинутых генеративных AI-приложений. Объединяя инструменты обработки данных LlamaIndex с экспертизой Novita AI, разработчики могут создавать масштабируемые, эффективные и ориентированные на пользователя решения, максимально раскрывая потенциал технологий на основе AI.
Часто задаваемые вопросы
Какие существуют типы индексов в LlamaIndex?
LlamaIndex предлагает четыре основных типа индексов: List Index (списочный), Vector Store Index (векторное хранилище), Tree Index (древовидный) и Keyword Table Index (таблица ключевых слов). Каждый служит своей цели, и понимание их функциональности является ключом к оптимизации запросов к данным.
Что такое древовидный индекс в LlamaIndex?
Древовидный индекс строит иерархическое дерево из набора узлов (которые становятся листовыми узлами в этом дереве). Запрос к древовидному индексу включает обход от корневых узлов вниз к листовым. По умолчанию (при child_branch_factor=1) запрос выбирает один дочерний узел для данного родительского узла.
Можно ли использовать LangChain и LlamaIndex вместе?
Оба фреймворка предоставляют мощные возможности, и выбор между ними должен основываться на конкретных потребностях и целях проекта. В некоторых проектах объединение сильных сторон LlamaIndex и LangChain может дать наилучшие результаты.
Ограниченное по времени предложение
Novita AI сейчас предлагает Реферальную программу, которая может быть полезна пользователям Helicone: если кто-то заинтересован, пользователи могут поделиться своей пригласительной ссылкой/кодом, и как они, так и их рефералы получат $20 кредита для использования с API DeepSeek R1 и V3.
О Novita AI
Novita AI — это облачная платформа AI, которая предоставляет разработчикам простой способ развертывания AI-моделей с помощью нашего простого API, а также предлагает доступное и надежное GPU-облако для создания и масштабирования.



