

LlamaIndex とは
LlamaIndex は、プライベートデータと公開データを LLM と接続するプロセスを簡素化するオーケストレーションフレームワークです。データの取り込み、構造化、検索に必要なツールを提供し、開発者がこれらのコンポーネントをゼロから構築することなく、堅牢な LLM 搭載アプリケーションを構築できるようにします。このフレームワークは、LLM がデータを消費するための準備や、必要な情報を必要なときに検索するという複雑なプロセスを効率化します。
LlamaIndex の主な機能
- 包括的なデータソース互換性: ファイル、データベース、アプリケーションなど、さまざまなデータソースをサポートする優れた統合機能により、さまざまな業界やユースケースでの汎用性と柔軟性を実現します。
- 豊富なコネクターエコシステム: ビルトインのデータ取り込みコネクターにより、開発者はカスタム統合の複雑さを排除し、データと大規模言語モデル(LLM)を迅速かつシームレスに橋渡しでき、開発効率を大幅に向上させます。
- インテリジェントデータ検索システム: 高度なクエリインターフェースにより、開発者やユーザーはクエリに最も関連性の高い情報を正確に取得でき、ユーザーエクスペリエンスを最適化し、情報の正確性を向上させます。
- カスタマイズ可能なインデックス戦略: 多様なインデックスオプションにより、特定のデータタイプやクエリ要件に合わせてシステムを最適化でき、検索速度と精度を高め、さまざまなアプリケーションシナリオに最適なパフォーマンスを提供します。
LlamaIndex の実世界でのユースケース
- 対話型ドキュメントアシスタント: 製品ドキュメントと即座に対話できる高度な自然言語チャットボットを開発し、直感的な知識アクセスによって顧客エンゲージメントを大幅に向上させ、サポート問い合わせを削減します。
- 適応型ナレッジエージェント: 継続的に拡大する知識リポジトリに基づいて複雑な意思決定ツリーをナビゲートできるインテリジェントエージェントを作成し、ビジネスインテリジェンスと顧客ニーズに合わせて進化するパーソナライズされた応答を提供します。
- 拡張セマンティック検索ソリューション: 大量の構造化データリポジトリとの直感的な対話を可能にする強力な自然言語処理システムを実装し、複数のエンタープライズアプリケーションにおける情報検索に革命をもたらします。
- 戦略的データエンリッチメント: 公開データセットと独自の知識コーパスをシームレスにブレンドする高度な技術を活用し、アプリケーション固有のエンゲージメントを促進し、優れたユーザーエクスペリエンスを提供する独自の価値ある情報エコシステムを構築します。
LlamaIndex の仕組み
LlamaIndex の包括的なデータオーケストレーションプラットフォームは、データ取り込み、インテリジェントインデックス作成、高度なクエリという 3 つの基本的な処理段階で動作します。
- データ取り込み
LlamaIndex は、API、データベース、PDF、およびさまざまなドキュメント形式に対応する汎用コネクターを提供し、LLM アプリケーション向けのデータ統合を効率化します。この包括的なツールキットにより、構造化データと非構造化データの両方をシームレスに組み込むことができ、最小限の統合オーバーヘッドでより効果的な AI ソリューションを構築できます。
- データインデックス作成
データが取り込まれると、LlamaIndex はさまざまなインデックス手法を使用してデータを整理し、効率的な検索を実現します。主な手法は次のとおりです。
- リストインデックス: データを順次配置します。時間の経過とともに進化するデータセットに最適です。
- ツリーインデックス: バイナリツリー構造を実装し、階層的なデータ編成に最適です。
- ベクトルストアインデックス: データをベクトル埋め込みとしてエンコードし、類似性ベースの検索を効率的に実行します。
- キーワードインデックス: メタデータタグをデータノードにリンクし、キーワード駆動型のクエリをサポートします。
インデックス作成中、データは高次元のベクトル埋め込みに変換されます。この変換によりデータの表現が微妙に変わり、検索結果の粒度と精度が向上します。
- クエリ
LlamaIndex は自然言語処理(NLP)とプロンプトエンジニアリングを活用して、シームレスなクエリを実現します。ユーザーは自然言語クエリを通じてデータと対話でき、クエリは解釈・処理されてインデックス化されたデータから関連情報を取得します。この機能は、チャットボット、ナレッジエージェント、セマンティック検索、データ拡張など、多様なアプリケーションをサポートします。
LlamaIndex の使用方法
LlamaIndex(GPT Index)は、LLM アプリケーション向けのデータフレームワークです。LlamaIndex で構築するには、通常、LlamaIndex コアと、選択したインテグレーション(またはプラグイン)のセットを操作します。Python で LlamaIndex を使い始める方法は 2 つあります。
- スターター版:
pip install llama-index。LlamaIndex コアと、いくつかのインテグレーションを選択したスターターパッケージ。 - カスタマイズ版:
pip install llama-index-core。LlamaIndex コアをインストールし、アプリケーションに必要な LlamaIndex インテグレーションパッケージを LlamaHub から追加します。コアとシームレスに連携する 300 以上の LlamaIndex インテグレーションパッケージがあり、好みの LLM、埋め込み、ベクトルストアプロバイダーを使用して構築できます。
Novita AI API と LlamaIndex の統合方法
前提条件
- Python と LlamaIndex に関する基本的な知識。
- Novita AI プラットフォームへのアクセスと API キー。
- Python 3.7 以上がインストールされていること。
LlamaIndex と Novita AI を活用する手順
ステップ 1: Novita AI の Model Library にアクセスし、関心のあるモデルを選択します。
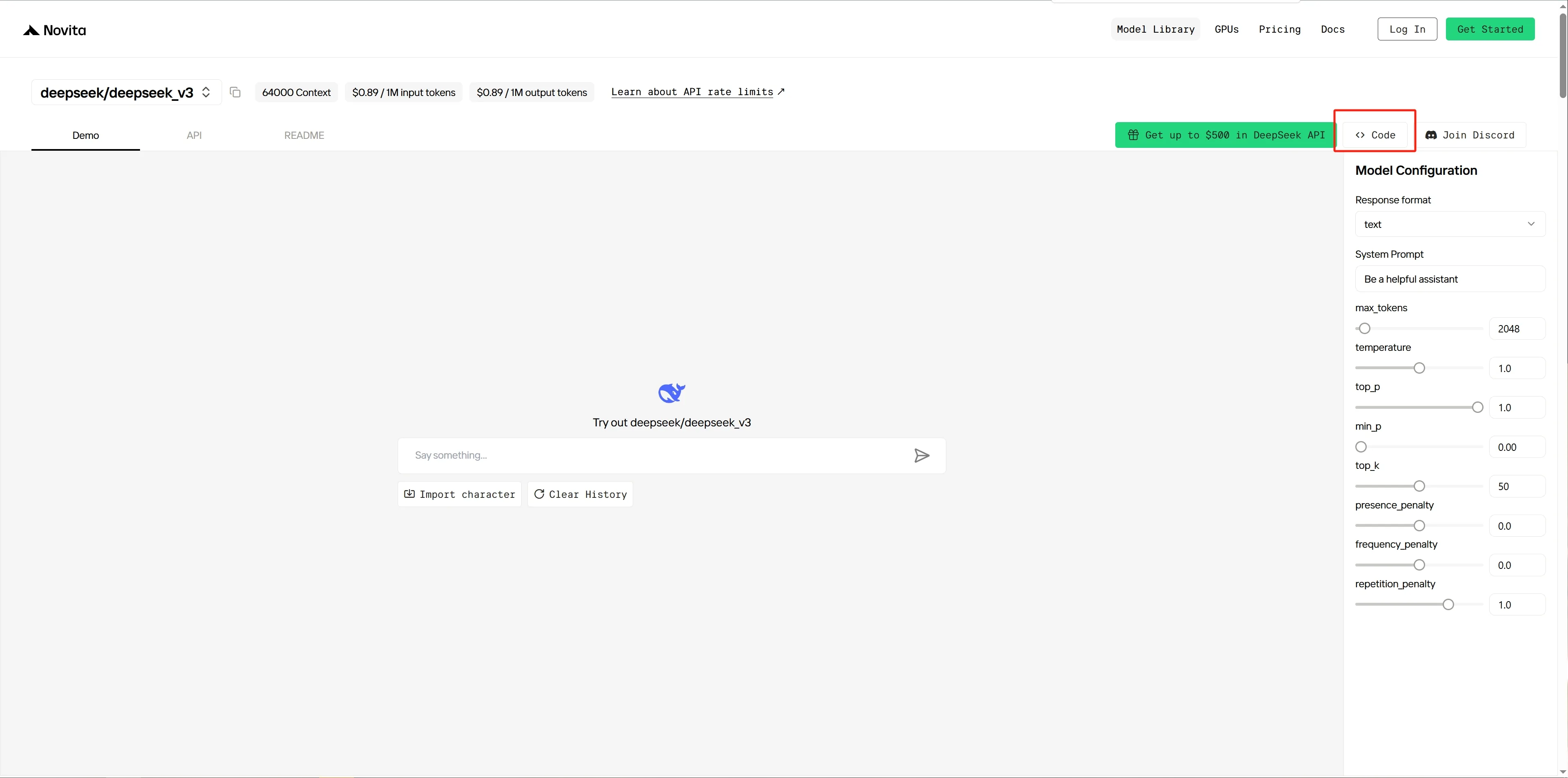
ステップ 2: 選択したモデルのデモページに移動し、右側の Code ボタンをクリックします。
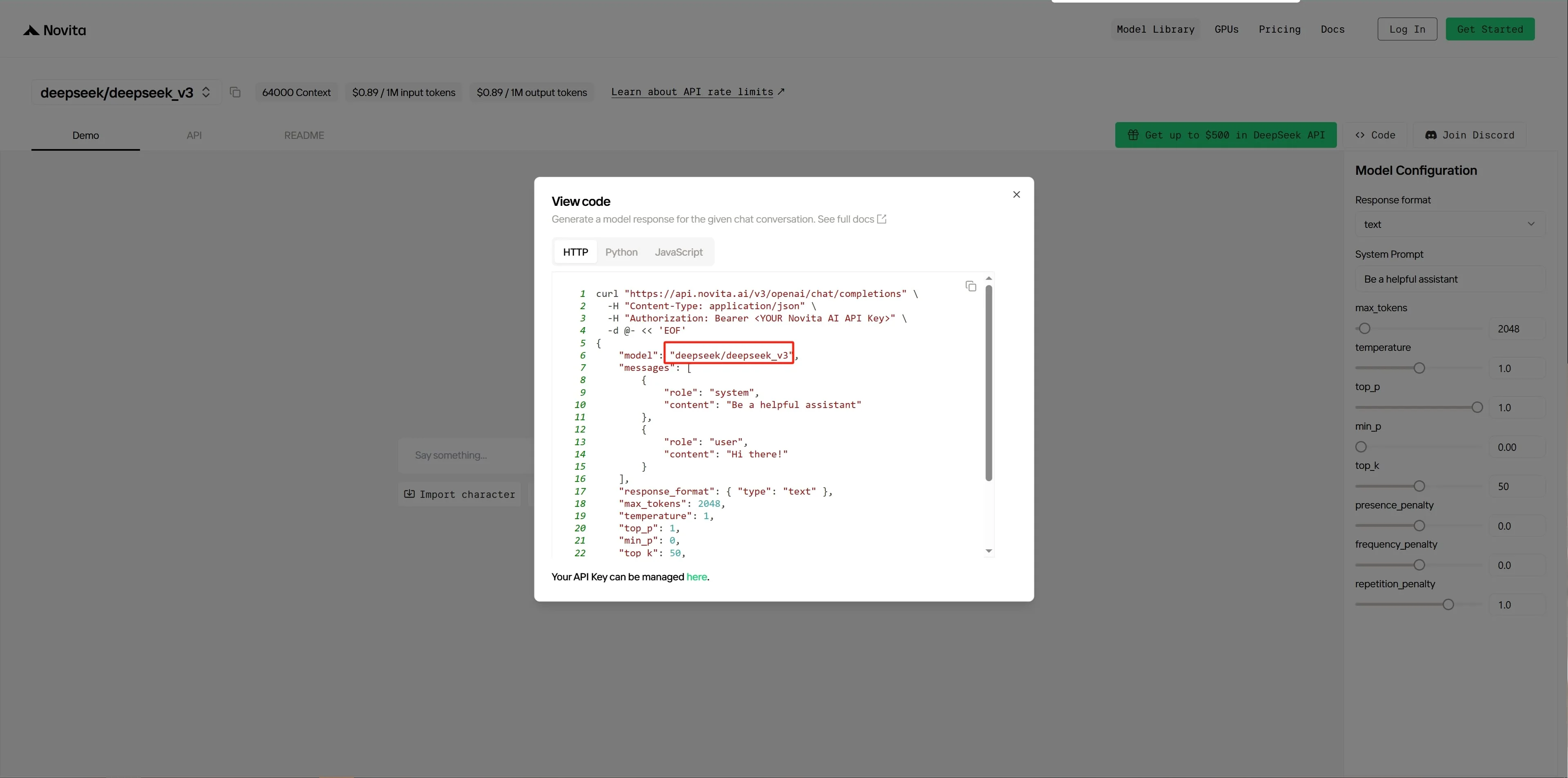
ステップ 3: モデル名をコピーしてメモします。
ステップ 4: Novita プラットフォームにログインします。
ステップ 5: ログイン後、プラットフォームの設定ページに移動します。
ステップ 6: 新しい API キーを作成し、サービス認証用にコピーします。
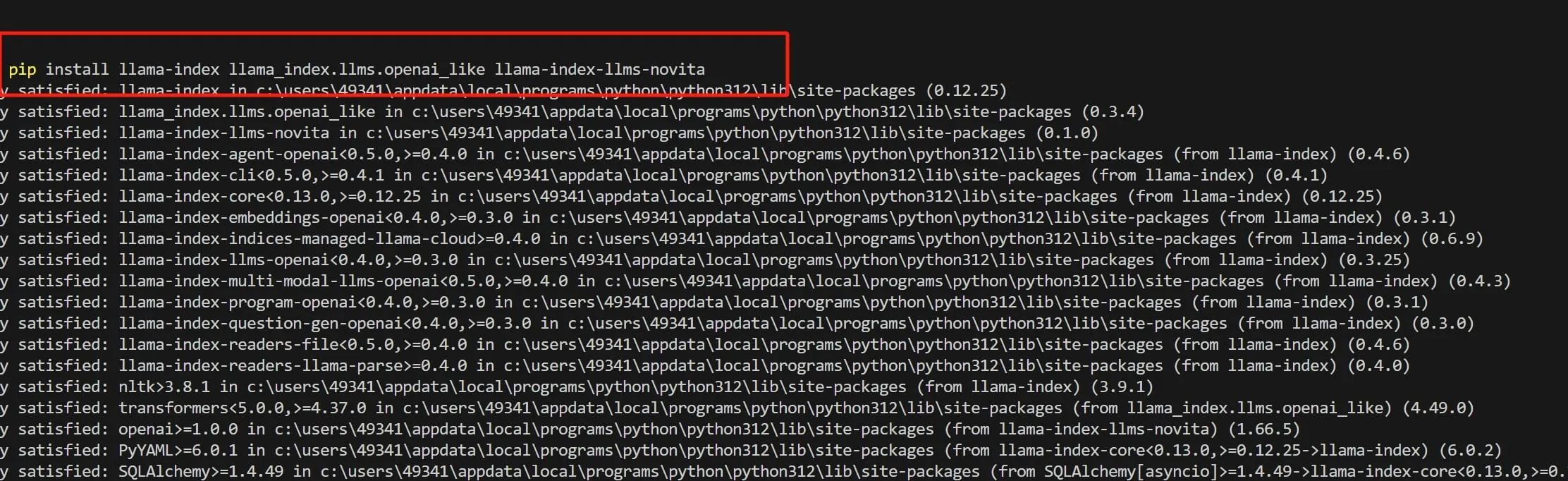
ステップ 7: llama_index と関連する Python ライブラリをインストールするには、以下を実行します。
ステップ 8: Python コードを記述し、NovitaAI クラスのパラメーターとしてモデル名と API キーを設定します。
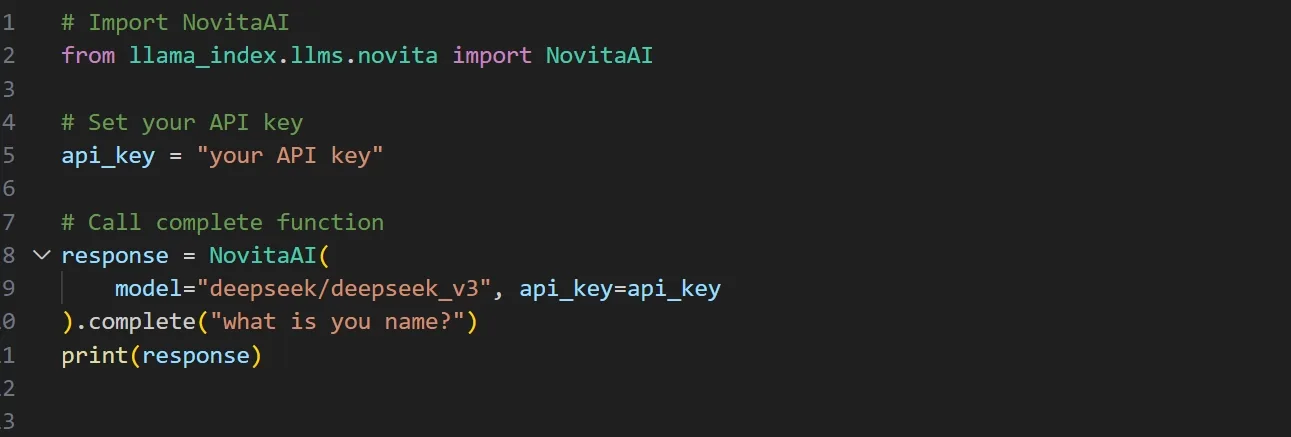
ステップ 9: コードを実行して出力を取得します。

その他の例については、ドキュメントを参照してください:llama_index/llama-index-integrations/llms/llama-index-llms-novita at main · run-llama/llama_index
LlamaIndex の便利なリンクとリソース
- LlamaIndex.TS (Typescript/Javascript)
- ドキュメント
- Discord
結論
まとめると、LlamaIndex と Novita AI の統合により、高度な生成 AI アプリケーションを構築するための強力な機能が解放されます。LlamaIndex のデータ処理ツールと Novita AI の専門知識を組み合わせることで、開発者はスケーラブルで効率的、かつユーザー中心のソリューションを作成し、AI 駆動型テクノロジーの可能性を最大限に活用できます。
よくある質問
LlamaIndex にはどのような種類のインデックスがありますか?
LlamaIndex は主に 4 種類のインデックスを提供しています:リストインデックス、ベクトルストアインデックス、ツリーインデックス、キーワードテーブルインデックス。それぞれ固有の目的があり、それらの機能を理解することがデータクエリの最適化の鍵となります。
LlamaIndex のツリーインデックスとは何ですか?
ツリーインデックスは、ノード(このツリーではリーフノードになる)のセットから階層ツリーを構築します。ツリーインデックスでクエリを実行するには、ルートノードからリーフノードまでトラバースします。デフォルトでは( child_branch_factor=1 の場合)、クエリは親ノードに対して 1 つの子ノードを選択します。
LangChain と LlamaIndex を一緒に使用できますか?
両方のフレームワークは強力な機能を提供しており、どちらを選択するかは特定のプロジェクトのニーズと目標に基づくべきです。プロジェクトによっては、LlamaIndex と LangChain の両方の強みを組み合わせることで最良の結果が得られる場合があります。
期間限定オファー
Novita AI は現在、Helicone ユーザーにとってメリットのある 紹介プログラム を提供しています。関心のあるユーザーは、自分の紹介リンク/コードを共有でき、紹介者と紹介された方の両方が DeepSeek R1 & V3 API で使用できる $20 のクレジットを受け取ります。
Novita AI について
Novita AI は、シンプルな API を使用して AI モデルを簡単にデプロイできる方法を開発者に提供し、同時に手頃で信頼性の高い GPU クラウドを構築およびスケーリングするための AI クラウドプラットフォームです。



