

Что, если бы вы могли запустить модель с 8B параметрами, которая превосходит модели в 30 раз большего размера?
DeepSeek-R1-0528-Qwen3-8B обеспечивает прорывную производительность в рассуждениях, сравниваясь с моделями на 235B параметров в сложных математических задачах, при этом эффективно работая на одном RTX 4090.
Это руководство покажет вам, как развернуть эту революционную модель на Novita AI за считанные минуты.
Что такое DeepSeek-R1-0528-Qwen3-8B
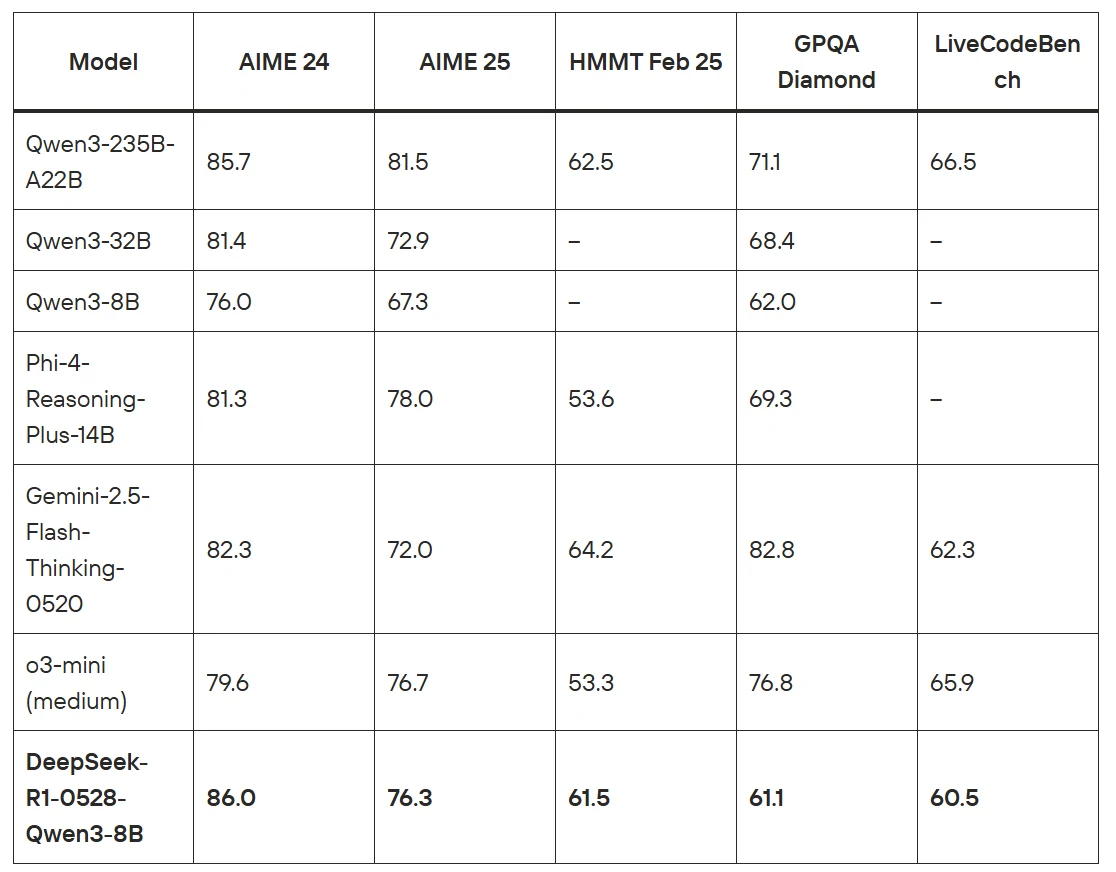
DeepSeek-R1-0528-Qwen3-8B — это сложная модель рассуждений, созданная путём дистилляции способностей цепочки мыслей из DeepSeek-R1-0528 в базовую модель Qwen3 8B. Такой инновационный подход привёл к созданию передовой модели с открытым исходным кодом, которая достигает выдающихся результатов на математических и логических бенчмарках, включая AIME 2024, где она превосходит Qwen3 8B на +10,0% и сравнивается с производительностью гораздо более крупной модели Qwen3-235B-thinking.
Модель демонстрирует исключительные возможности по различным метрикам оценки, набирая 86,0 на AIME 24, 76,3 на AIME 25 и 61,5 на HMMT Feb 25. Что делает эту модель особенно ценной — это её способность обеспечивать производительность рассуждений, сопоставимую с гораздо более крупными моделями, сохраняя при этом эффективность и возможность развёртывания модели с 8B параметрами.
Зачем запускать DeepSeek-R1-0528-Qwen3-8B на GPU-инстансах Novita AI?
1. Значительное ценовое преимущество и гибкие модели ценообразования
Novita AI предлагает конкурентоспособные цены на рынке GPU-вычислений, что делает передовые AI-модели, такие как DeepSeek-R1-0528-Qwen3-8B, доступными для исследователей, бизнеса и разработчиков любого масштаба.
Выбирайте между ценообразованием по запросу и по подписке в зависимости от ваших сценариев использования. Для DeepSeek-R1-0528-Qwen3-8B на RTX 4090:
- По запросу: $0,35/час — подходит для тестирования и переменных нагрузок
- 1–5 месяцев: $226,80/месяц (скидка 10%) — среднесрочные проекты
- 6–11 месяцев: $206,64/месяц (скидка 18%) — расширенные циклы разработки
- 12 месяцев: $189,00/месяц (скидка 25%) — большая экономия при долгосрочных обязательствах
Годовая подписка может сэкономить вам сотни долларов, гарантируя при этом доступность ресурсов. Узнайте больше о моделях ценообразования.
2. Несколько вариантов GPU для оптимизации производительности
Novita AI предоставляет широкий выбор GPU, соответствующих вашим вычислительным потребностям и бюджету:
- RTX 3090 24GB: экономически эффективен для разработки и тестирования
- RTX 4090 24GB: Рекомендуется для DeepSeek-R1-0528-Qwen3-8B — сбалансированная производительность и стоимость
- RTX 5090 32GB
- RTX 6000 Ada 48GB: увеличенная видеопамять для больших контекстных длин
- L40S 48GB: профессиональная производительность с расширенным объёмом памяти
- A100 SXM 80GB: высокопроизводительные вычисления с существенной пропускной способностью памяти
- H100 SXM 80GB: производительность корпоративного уровня для production-развёртываний
3. Готовые шаблоны и гибкость настройки
Предварительно настроенные шаблоны для популярных моделей, таких как DeepSeek-R1-0528-Qwen3-8B, устраняют сложность ручной настройки, включая оптимизированные конфигурации контейнеров, переменные окружения и проверенные параметры развёртывания. Опытные пользователи могут создавать полностью собственные шаблоны со специализированными конфигурациями и персональными скриптами развёртывания, что обеспечивает как лёгкость использования для новичков, так и полную кастомизацию для опытных разработчиков.
4. Глобальная сеть развёртывания
Развёртывайте GPU-инстансы ближе к вашим пользователям через глобальную сеть Novita AI, охватывающую 15 регионов на территории Америки (США, Канада, Бразилия), Азиатско-Тихоокеанского региона (Япония, Сингапур, Индия, ОАЭ, Гонконг) и Европы (Германия, Великобритания). Эта глобальная инфраструктура обеспечивает снижение задержек и надёжную производительность вашего развёртывания DeepSeek-R1-0528-Qwen3-8B, гарантируя стабильный доступ независимо от местоположения пользователя.
Как развернуть DeepSeek-R1-0528-Qwen3-8B на Novita AI
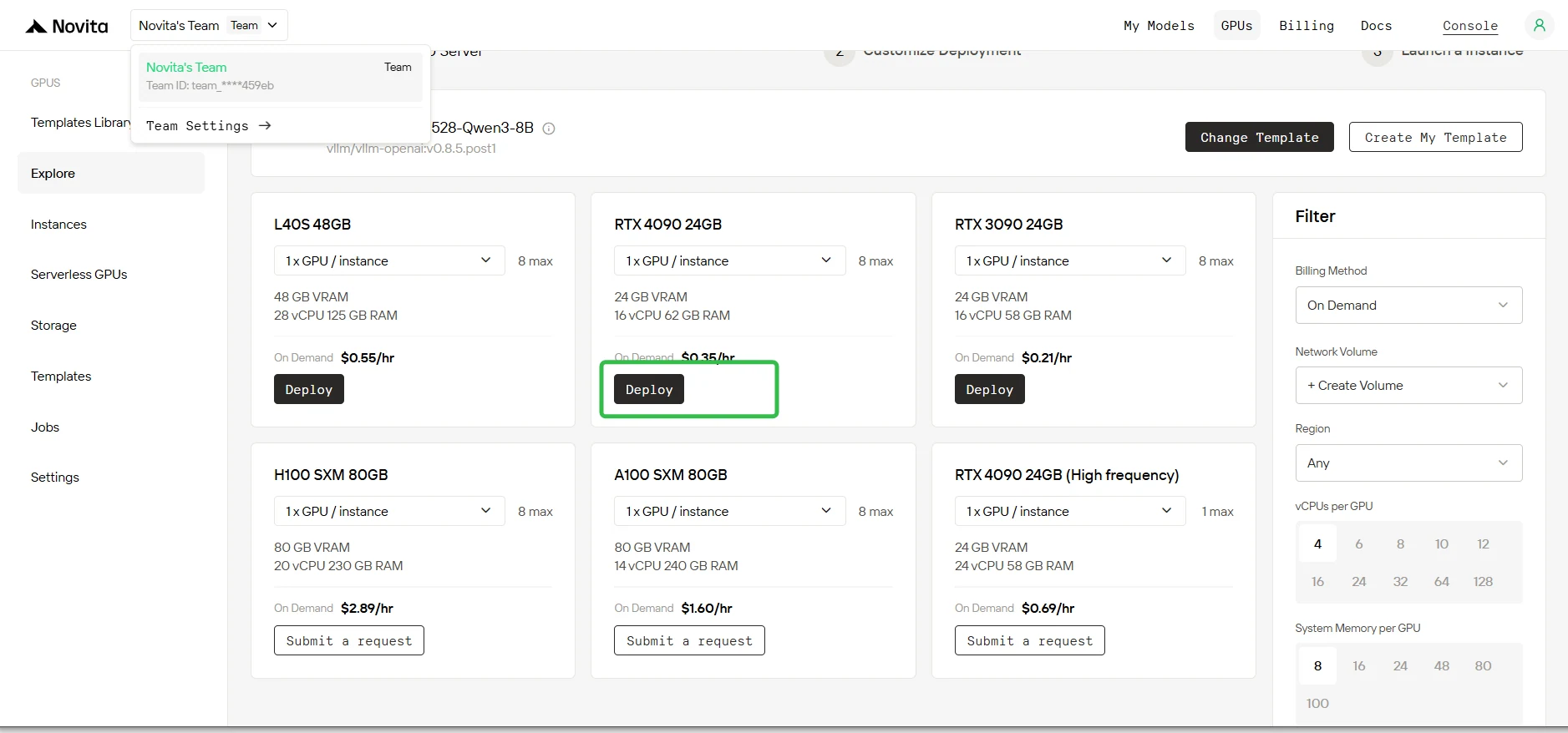
Шаг 1: Выбор шаблона
Выберите шаблон DeepSeek-R1-0528-Qwen3-8B из библиотеки моделей. Выберите один RTX 4090 в качестве типа GPU и нажмите Deploy.
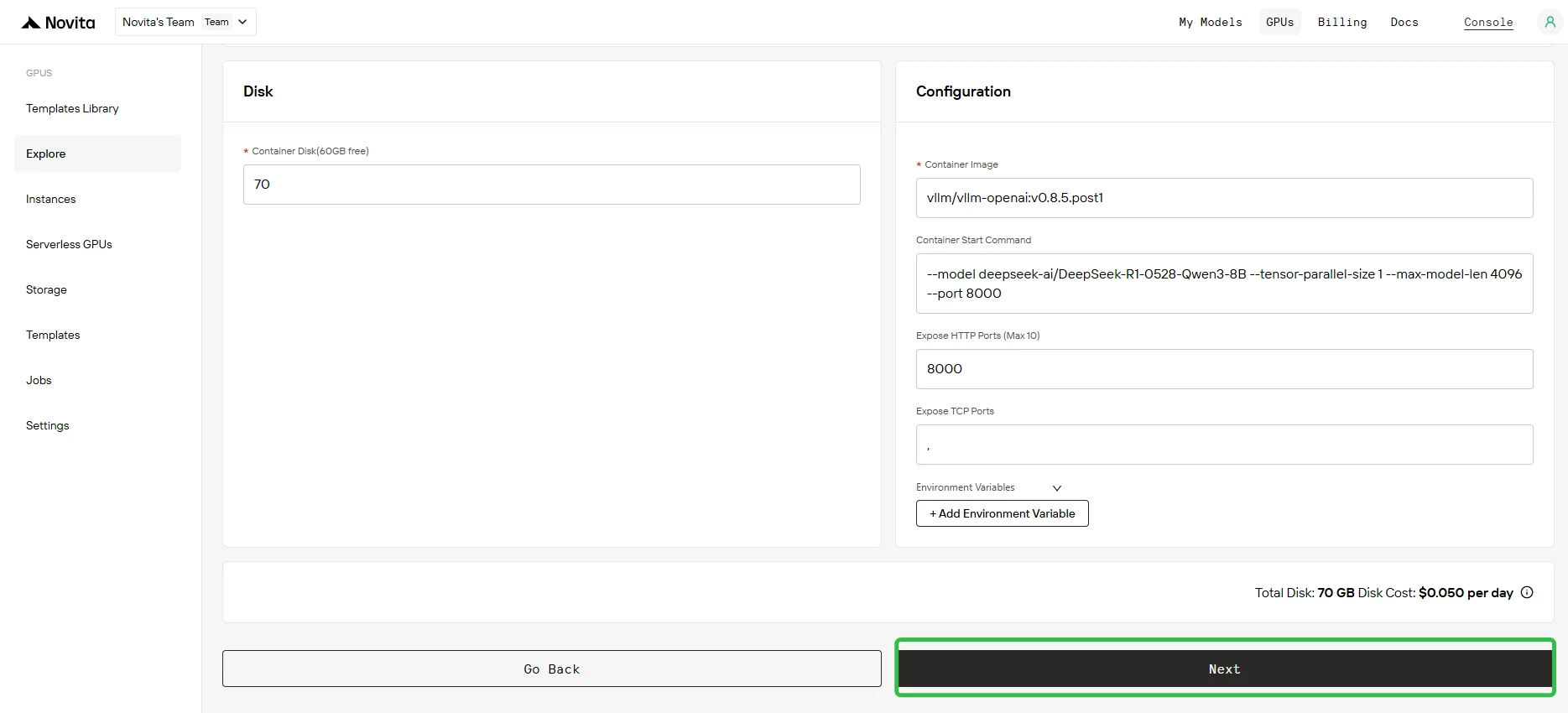
Шаг 2: Подтверждение параметров
Проверьте параметры развёртывания, отображаемые на экране конфигурации. Убедитесь, что все настройки верны, и нажмите Next для продолжения.
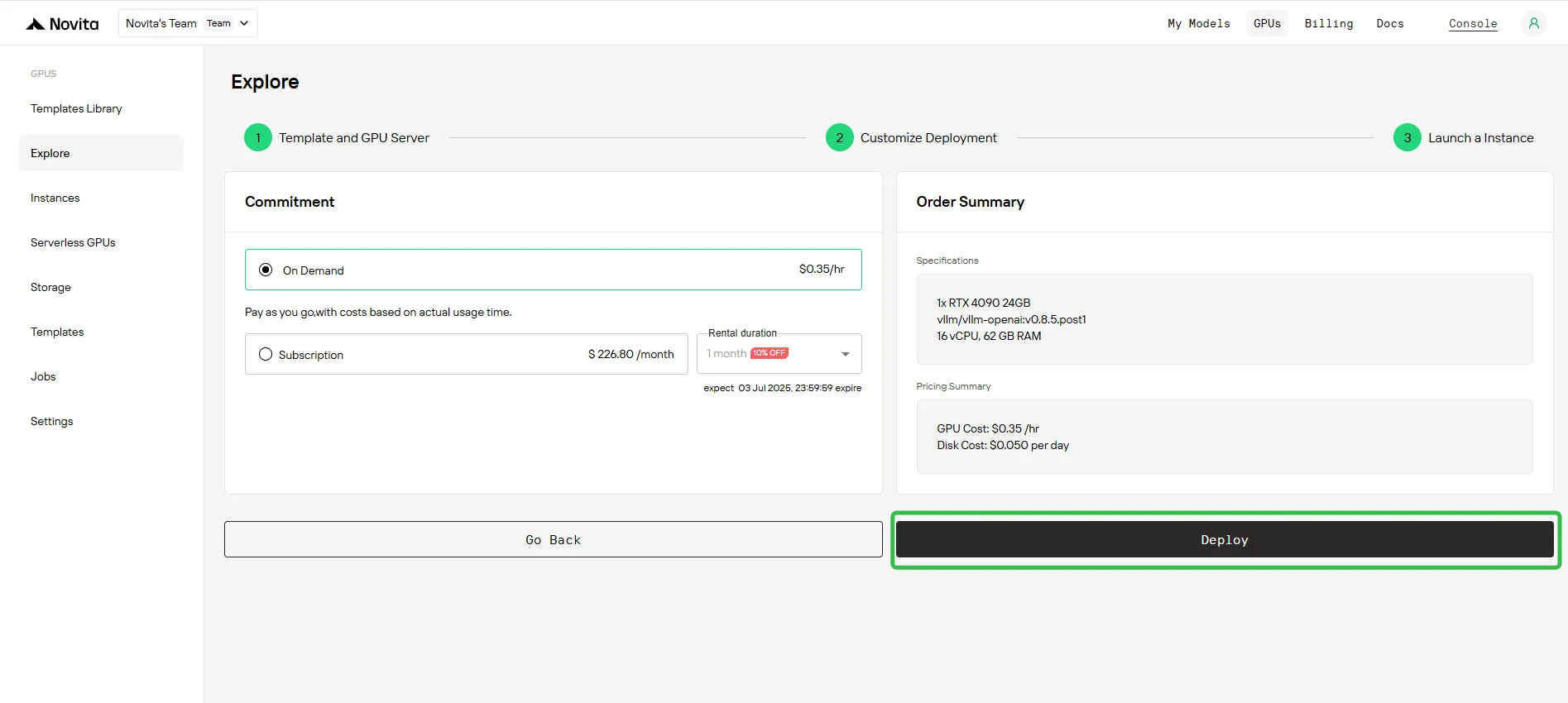
Шаг 3: Развёртывание инстанса
Нажмите Deploy, чтобы начать процесс создания инстанса. Система начнёт подготовку вашего GPU-инстанса.
Шаг 4: Мониторинг прогресса развёртывания
Перейдите в раздел Instance Management, чтобы открыть консоль управления. Эта панель позволяет отслеживать статус развёртывания в реальном времени.
Шаг 5: Просмотр статуса загрузки образа
Нажмите на ваш конкретный инстанс, чтобы отслеживать прогресс загрузки образа контейнера. Этот процесс может занять несколько минут в зависимости от состояния сети.
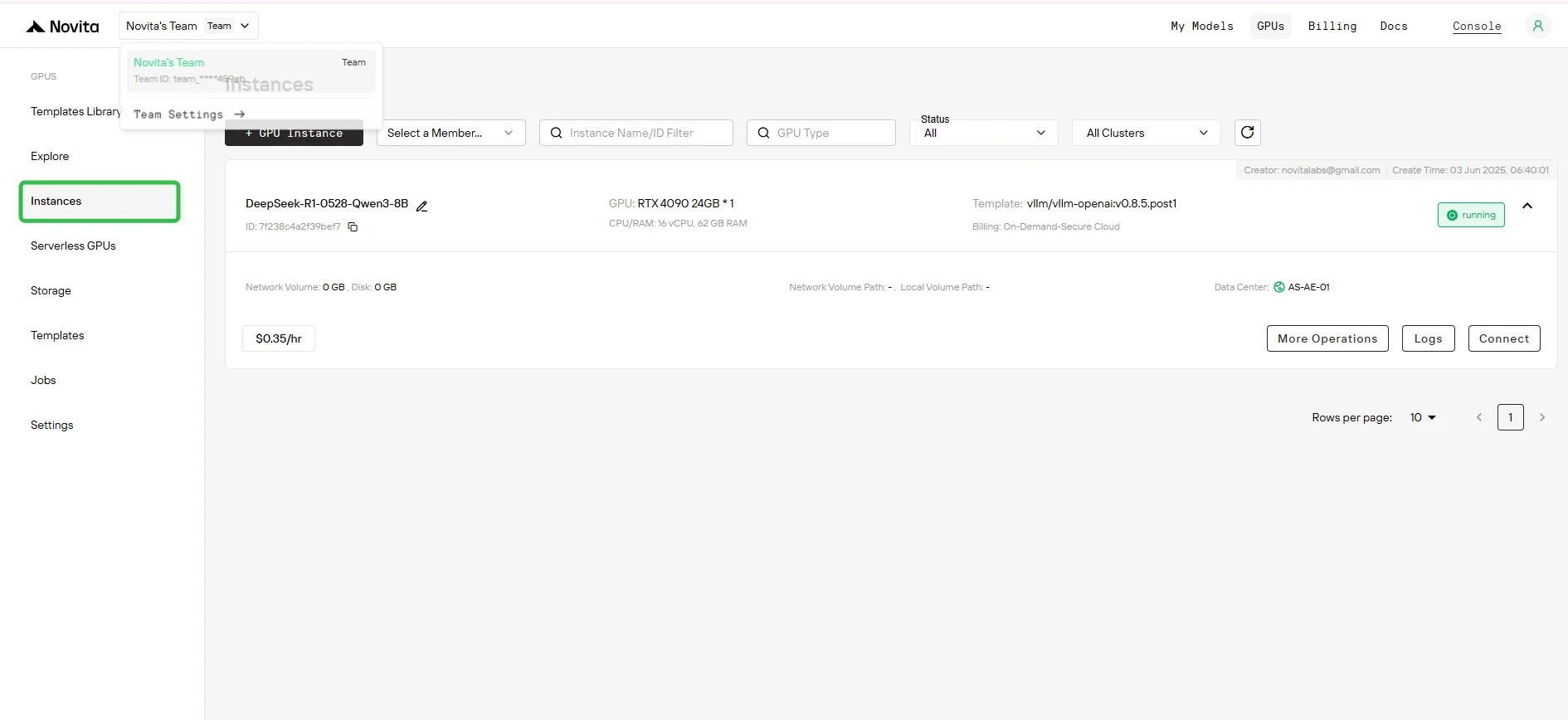
Шаг 6: Отслеживание загрузки модели
После запуска инстанса начнётся загрузка модели. Нажмите “Logs” –> “Instance Logs”, чтобы следить за прогрессом загрузки модели.
Шаг 7: Проверка успешного развёртывания
Найдите сообщение "Application startup complete." в логах инстанса. Это указывает на то, что процесс развёртывания успешно завершён.
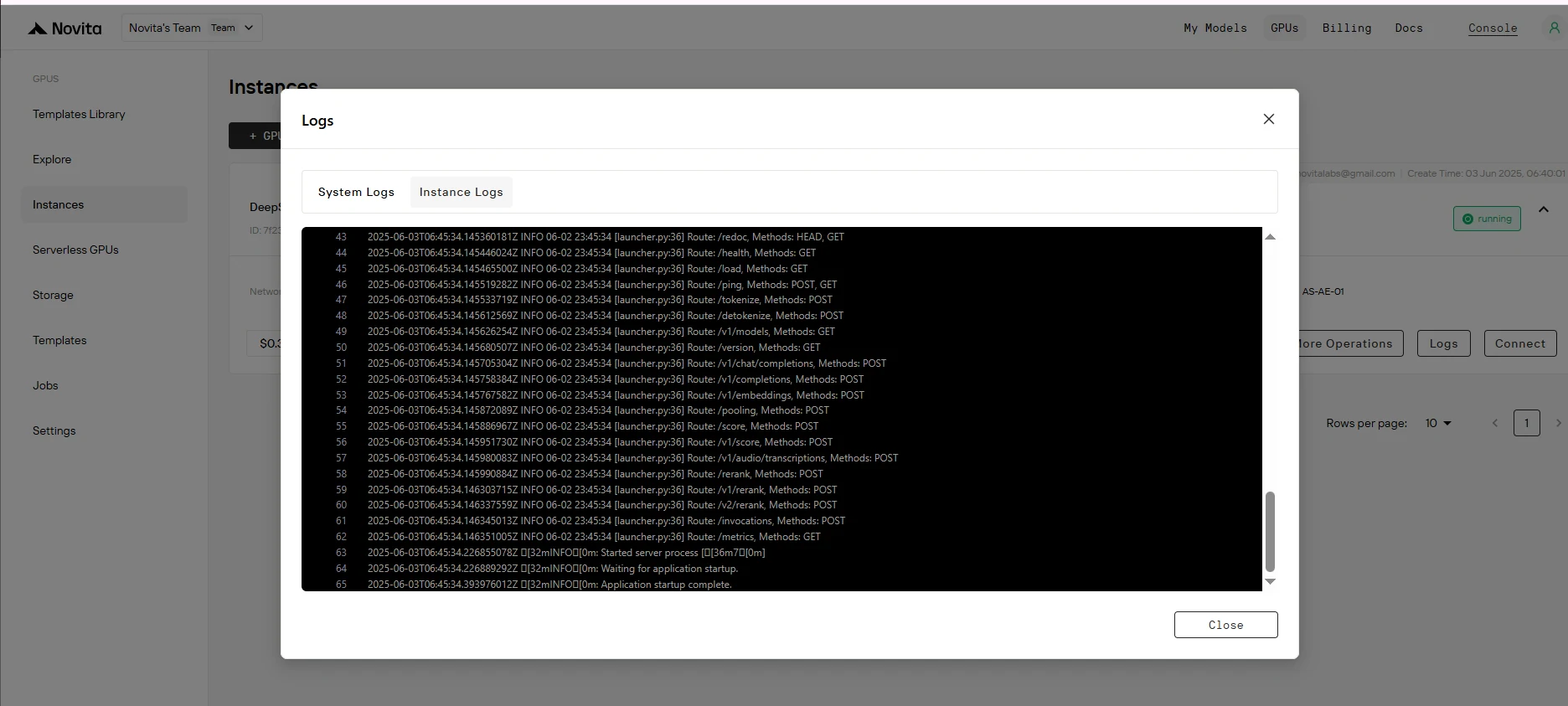
Шаг 8: Получение URL-адреса для доступа
Нажмите “Connect”, затем –> “Connect to HTTP Service [Port 8000]”. Поскольку это API-сервис, вам нужно скопировать адрес.

Шаг 9: Доступ к вашей развёрнутой модели
Чтобы отправлять запросы к вашей модели, замените “http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai" на ваш реальный открытый адрес. Скопируйте следующий код, чтобы получить доступ к вашей приватной модели!
# Вызов сервера с помощью curl:
curl -X POST "http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
]
}'
{"id":"chatcmpl-56d12c91edbb46fcb93ccbbc0ecddd2c","object":"chat.completion","created":1748588145,"model":"deepseek-ai/DeepSeek-R1-0528-Qwen3-8B","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":" thinking\
Okay, the user is asking for the capital of France. Let me start by recalling the basic answer. Paris is definitely the correct response, so I'll start with that.\
\
But why is the user asking this? They might be a student preparing for a test, or maybe someone traveling who needs to know the main city for planning. Alternatively, they could be testing my knowledge. But since it's a straightforward question, I'll focus on providing accurate information.\
\
Wait, maybe they need more context. Should I mention some points of interest to add value? Like Eiffel Tower or Louvre. That could help if they're interested in tourism or education. \
\
I should check if there's any recent political changes or administrative updates but nothing seems off with Paris' status as a capital. Alright, keep it simple but informative. Let me structure the answer first, then decide on the optional details. \
\
Also, considering the user might not want a long answer. But including key landmarks might make it more engaging. They didn't ask for historical info, so maybe just stick to the status and one or two unique facts. \
\
Yes, \"city of love\" is a common nickname, so that adds a nice touch. Alright, final answer will confirm Paris, mention the nicknames, and list two landmarks to cover possible interests without being overwhelming.\
response\
The capital of France is **Paris**.","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":10,"total_tokens":294,"completion_tokens":284,"prompt_tokens_details":null},"prompt_logprobs":null}
Настройте адрес API в ваших приложениях, например Chatbox, и вы получите своего собственного личного помощника!
Novita AI — это облачная платформа искусственного интеллекта, которая предлагает разработчикам простой способ развёртывания AI-моделей с помощью нашего простого API, а также предоставляет доступное и надёжное GPU-облако для создания и масштабирования.



