

Et si vous pouviez exécuter un modèle de 8 milliards de paramètres qui surpasse des modèles 30 fois plus grands ?
DeepSeek-R1-0528-Qwen3-8B offre des capacités de raisonnement révolutionnaires, égalant des modèles de 235 milliards de paramètres sur des tâches mathématiques complexes tout en tournant efficacement sur une seule RTX 4090.
Ce guide vous montre comment déployer ce modèle révolutionnaire sur Novita AI en quelques minutes.
Qu’est-ce que DeepSeek-R1-0528-Qwen3-8B
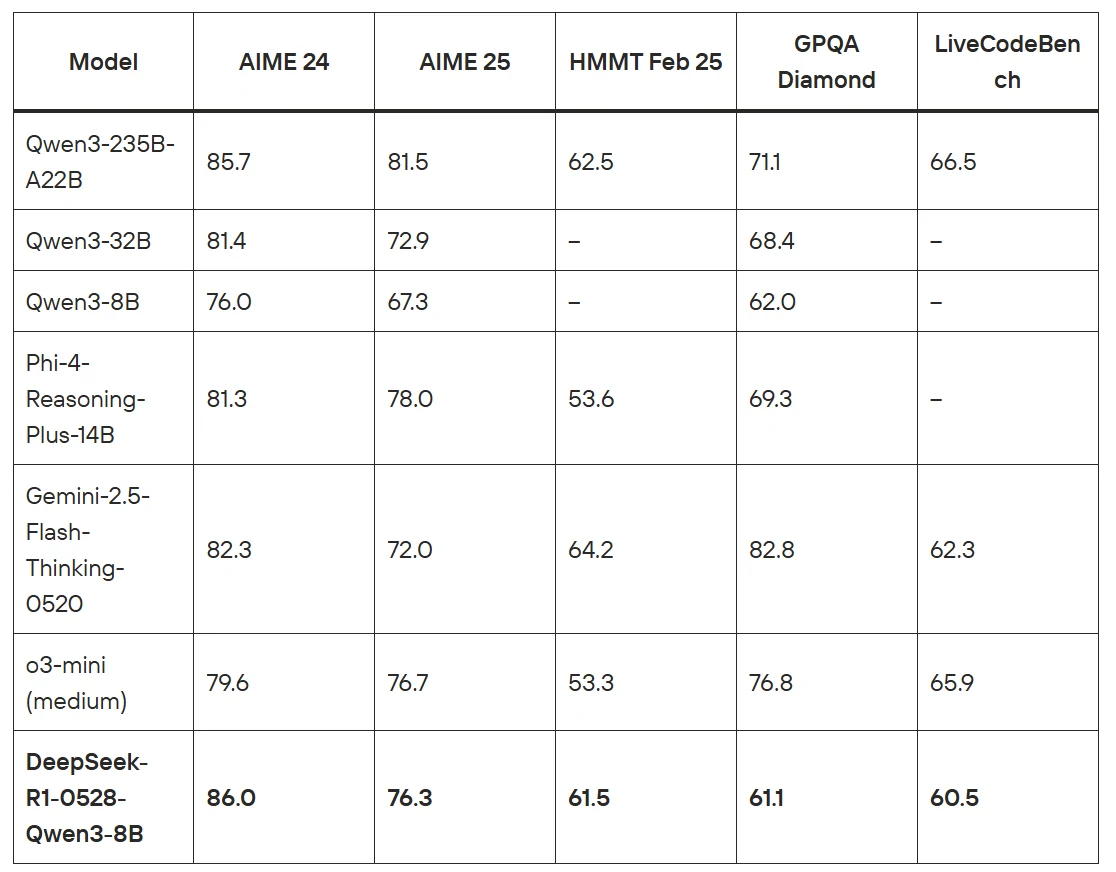
DeepSeek-R1-0528-Qwen3-8B est un modèle de raisonnement sophistiqué créé en distillant les capacités de chaîne de pensée de DeepSeek-R1-0528 dans le modèle de base Qwen3 8B. Cette approche innovante a produit un modèle open-source de pointe qui atteint des performances remarquables sur les benchmarks mathématiques et de raisonnement, notamment AIME 2024 où il dépasse Qwen3 8B de +10,0 % et égale les performances du modèle bien plus grand Qwen3-235B-thinking.
Le modèle démontre des capacités exceptionnelles sur diverses métriques d’évaluation, obtenant 86,0 sur AIME 24, 76,3 sur AIME 25 et 61,5 sur HMMT Feb 25. Ce qui rend ce modèle particulièrement précieux est sa capacité à offrir des performances de raisonnement comparables à des modèles beaucoup plus grands tout en conservant l’efficacité et la déployabilité d’un modèle de 8 milliards de paramètres.
Pourquoi exécuter DeepSeek-R1-0528-Qwen3-8B sur les instances GPU Novita AI ?
1. Avantage de prix significatif et modèles de tarification flexibles
Novita AI propose des prix compétitifs sur le marché pour le calcul GPU, rendant les modèles d’IA avancés comme DeepSeek-R1-0528-Qwen3-8B accessibles aux chercheurs, entreprises et développeurs à toute échelle.
Choisissez entre la tarification à la demande et par abonnement selon vos modes d’utilisation. Pour DeepSeek-R1-0528-Qwen3-8B sur RTX 4090 :
- À la demande : 0,35 $/heure – Adapté aux tests et aux charges variables
- 1 à 5 mois : 226,80 $/mois (10 % de réduction) – Projets à moyen terme
- 6 à 11 mois : 206,64 $/mois (18 % de réduction) – Cycles de développement prolongés
- 12 mois : 189,00 $/mois (25 % de réduction) – Économies plus importantes pour les engagements à long terme
L’abonnement annuel peut vous faire économiser des centaines de dollars tout en garantissant la disponibilité des ressources. En savoir plus sur les modèles de tarification.
2. Choix multiples de GPU pour l’optimisation des performances
Novita AI propose des options GPU complètes pour répondre à vos besoins de calcul et à votre budget :
- RTX 3090 24 Go : Rentable pour le développement et les tests
- RTX 4090 24 Go : Recommandé pour DeepSeek-R1-0528-Qwen3-8B – performances et coût équilibrés
- RTX 5090 32 Go
- RTX 6000 Ada 48 Go : VRAM améliorée pour des contextes plus longs
- L40S 48 Go : Performances professionnelles avec une capacité mémoire étendue
- A100 SXM 80 Go : Calcul haute performance avec une bande passante mémoire substantielle
- H100 SXM 80 Go : Performances de niveau entreprise pour les déploiements en production
3. Modèles prêts à l’emploi et flexibilité personnalisée
Les modèles préconfigurés pour des modèles populaires comme DeepSeek-R1-0528-Qwen3-8B éliminent la complexité de la configuration manuelle, incluant des configurations conteneur optimisées, des variables d’environnement et des paramètres de déploiement testés. Les utilisateurs avancés peuvent créer des modèles entièrement personnalisés avec des configurations spécialisées et des scripts de déploiement personnalisés, garantissant à la fois une facilité d’utilisation pour les débutants et une personnalisation complète pour les développeurs expérimentés.
4. Réseau de déploiement mondial
Déployez des instances GPU plus proches de vos utilisateurs grâce au réseau mondial de Novita AI avec 15 régions en Amériques (États-Unis, Canada, Brésil), en Asie-Pacifique (Japon, Singapour, Inde, Émirats arabes unis, Hong Kong) et en Europe (Allemagne, Royaume-Uni). Cette infrastructure globale garantit une latence réduite et des performances fiables pour votre déploiement DeepSeek-R1-0528-Qwen3-8B, offrant un accès fiable quelle que soit la localisation de l’utilisateur.
Comment déployer DeepSeek-R1-0528-Qwen3-8B sur Novita AI
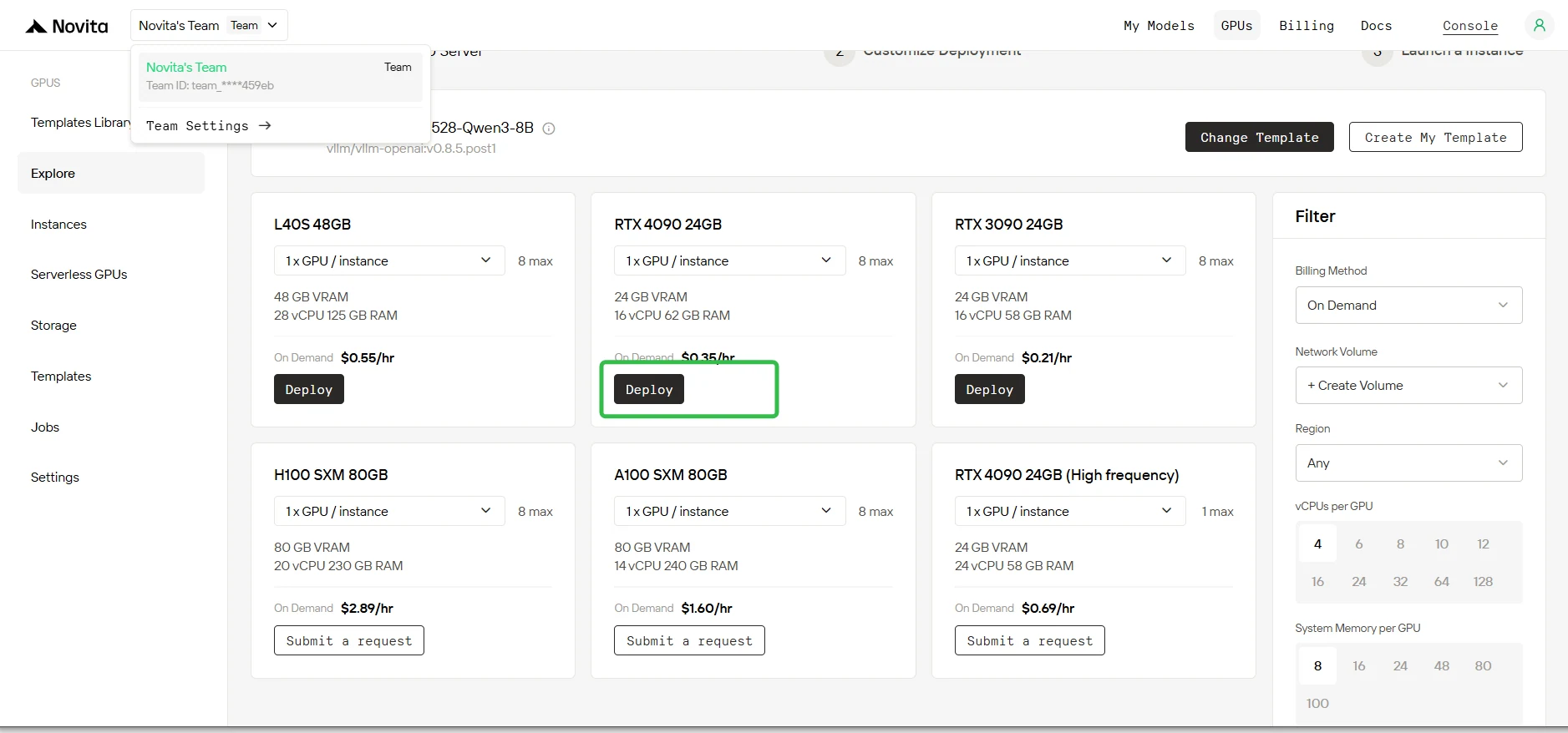
Étape 1 : Sélection du modèle
Sélectionnez le modèle DeepSeek-R1-0528-Qwen3-8B depuis la bibliothèque de modèles. Choisissez une RTX 4090 comme type de GPU et cliquez sur Déployer.
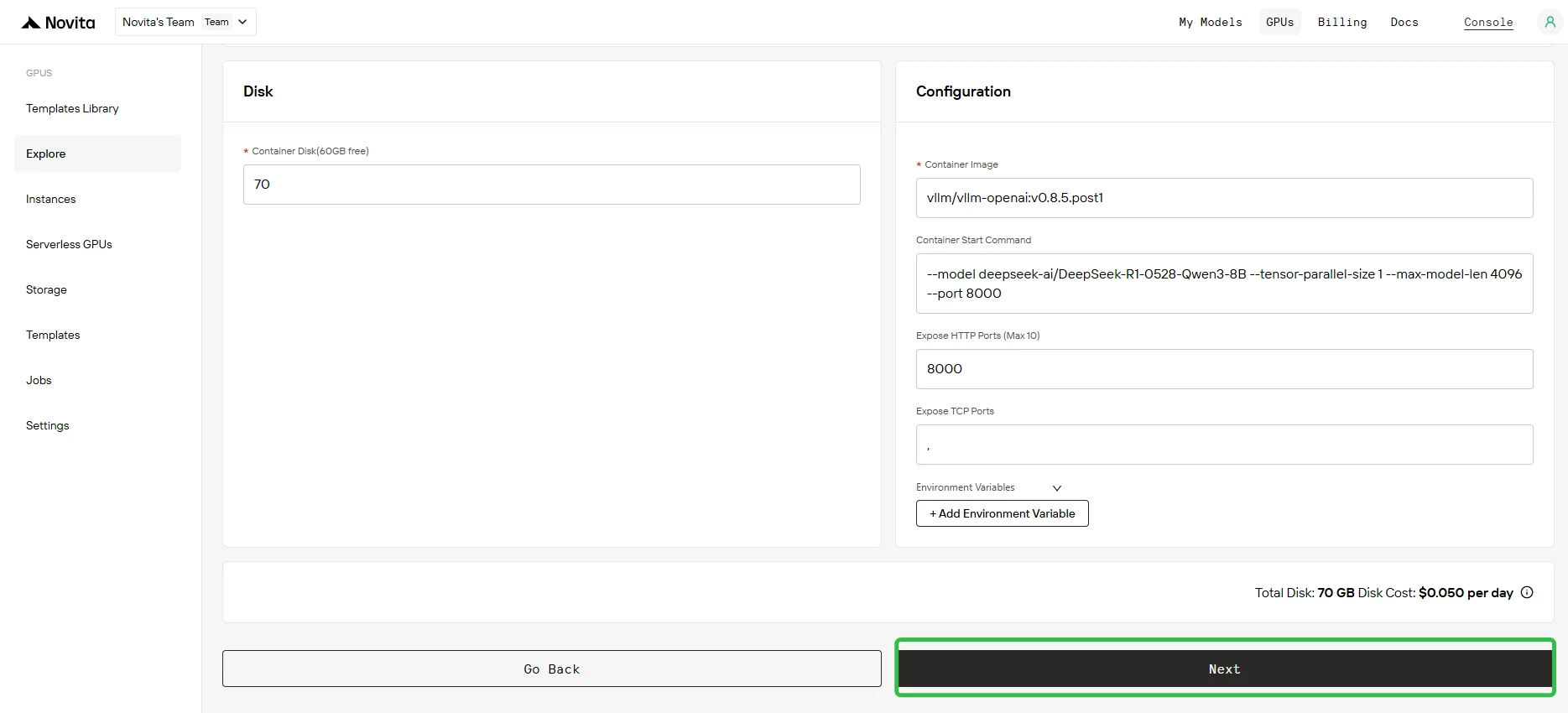
Étape 2 : Confirmation des paramètres
Passez en revue les paramètres de déploiement affichés sur l’écran de configuration. Vérifiez que tous les réglages sont corrects et cliquez sur Suivant pour continuer.
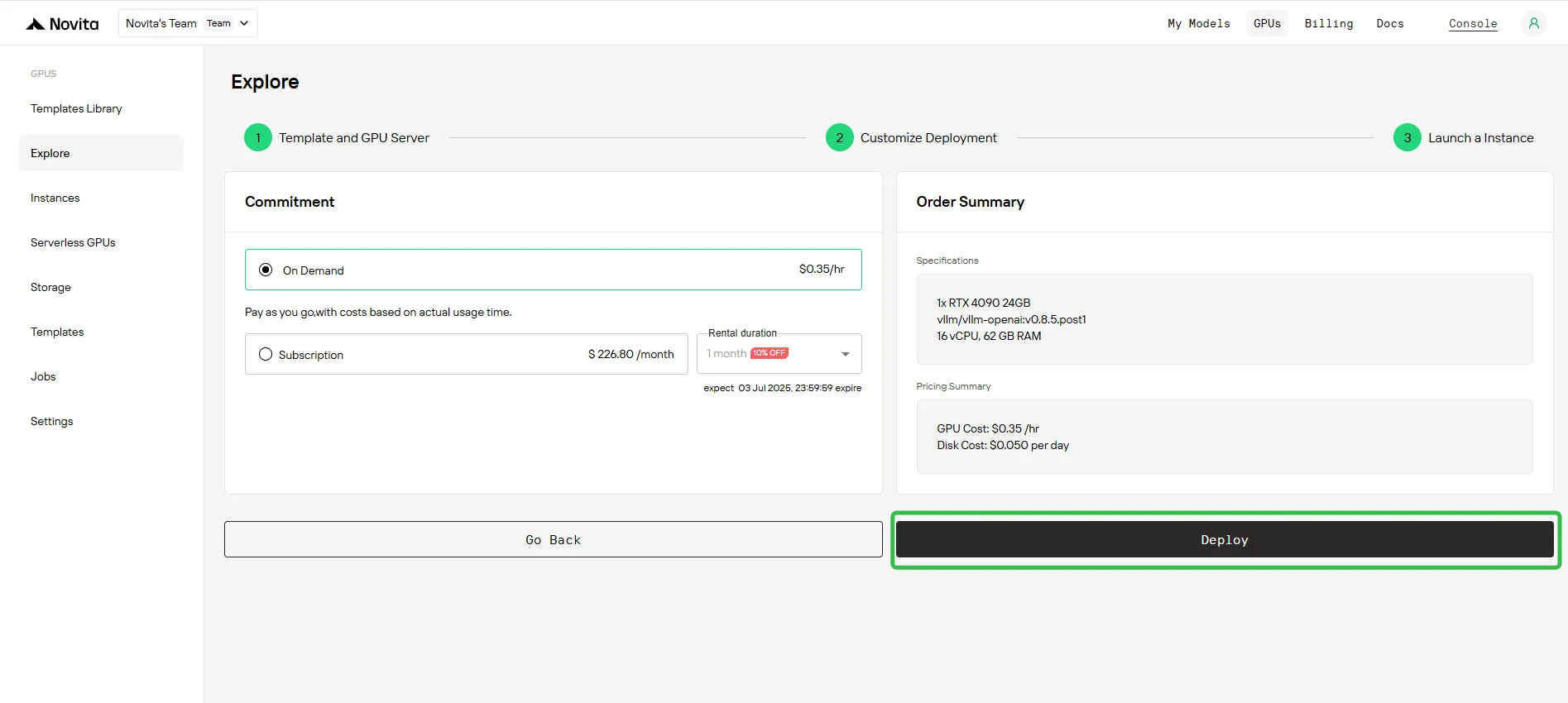
Étape 3 : Déploiement de l’instance
Cliquez sur Déployer pour lancer le processus de création de l’instance. Le système commence à provisionner votre instance GPU.
Étape 4 : Suivre la progression du déploiement
Accédez à Gestion des instances pour ouvrir la console de contrôle. Ce tableau de bord vous permet de suivre l’état du déploiement en temps réel.
Étape 5 : Visualiser l’état du téléchargement d’image
Cliquez sur votre instance spécifique pour surveiller la progression du téléchargement de l’image conteneur. Ce processus peut prendre plusieurs minutes selon les conditions réseau.
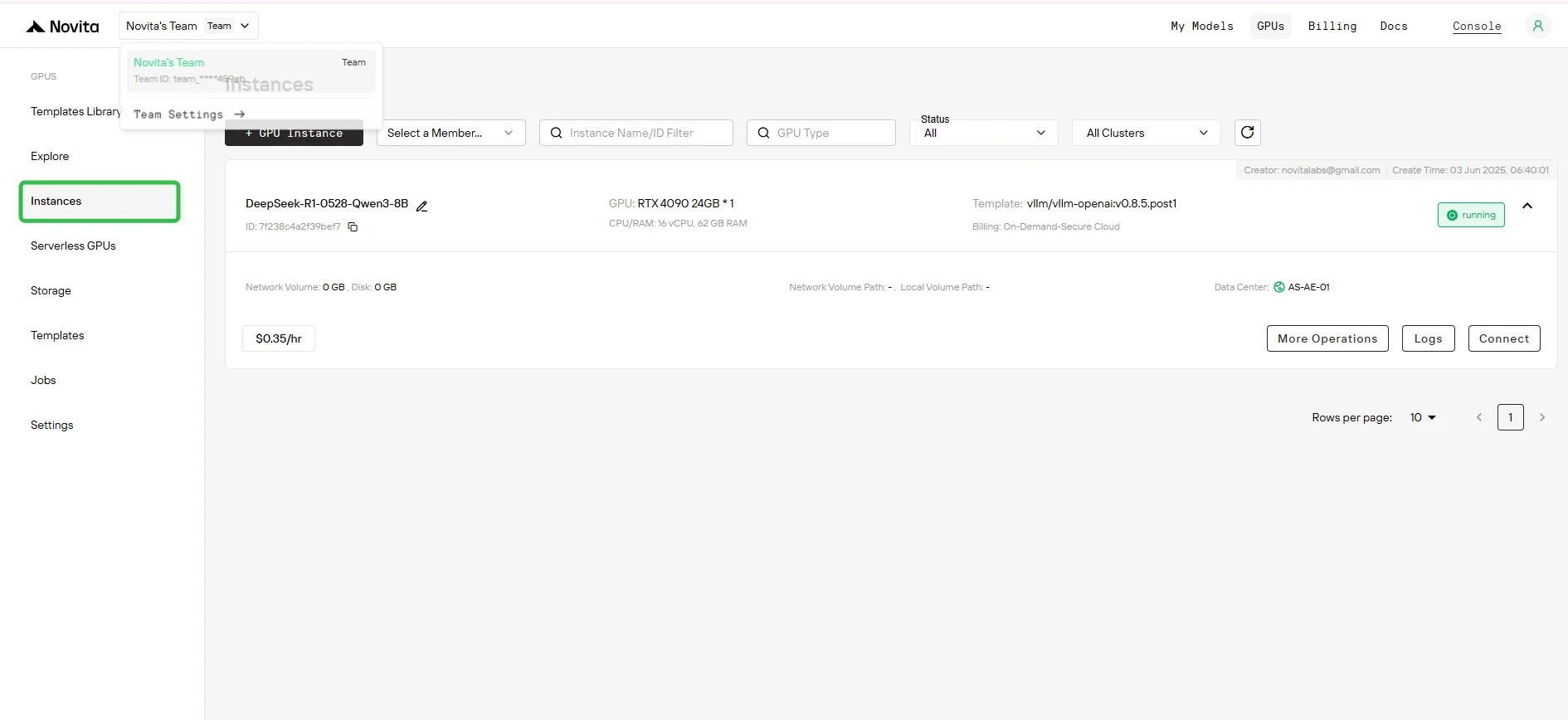
Étape 6 : Suivre le téléchargement du modèle
Après le démarrage de l’instance, celle-ci commence à télécharger le modèle. Cliquez sur “Logs” –> “Instance Logs” pour surveiller la progression du téléchargement du modèle.
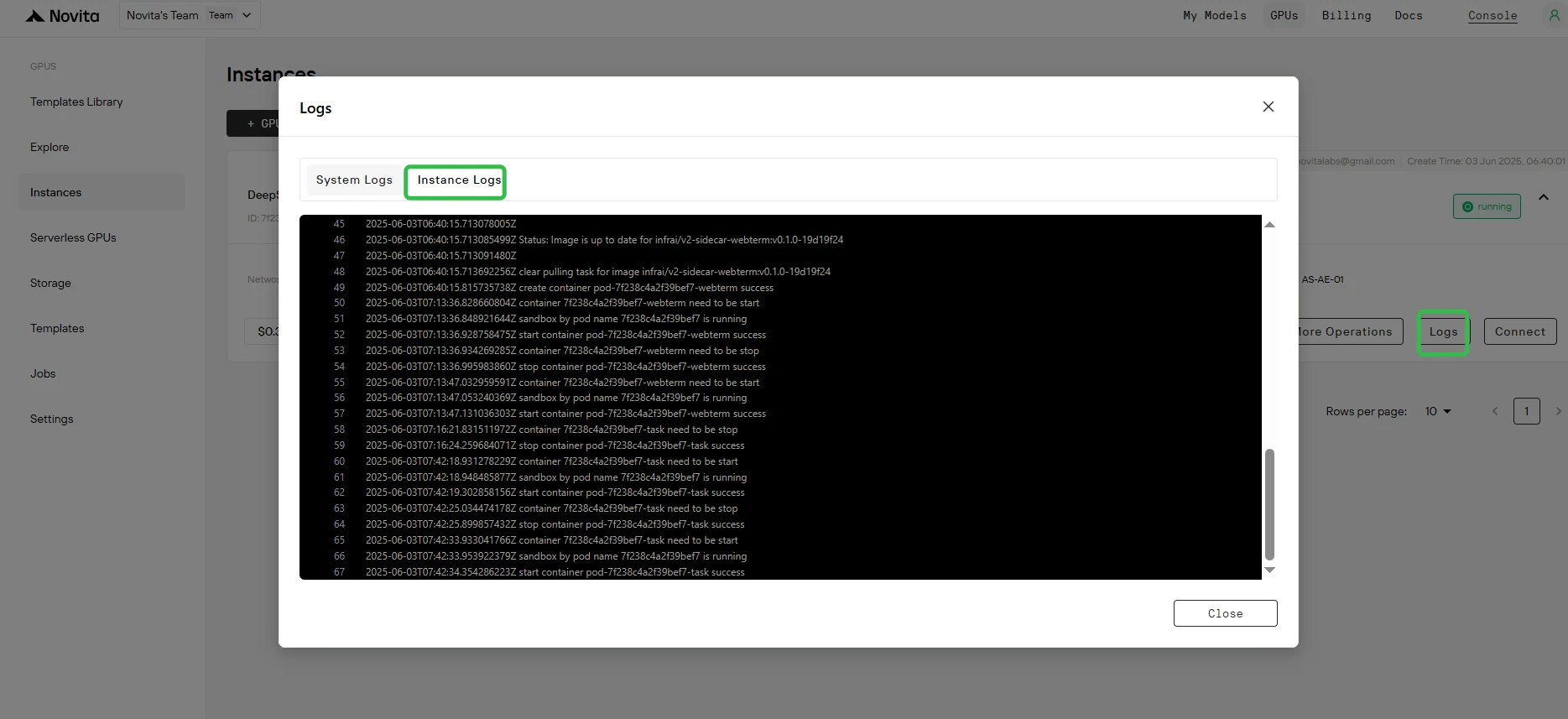
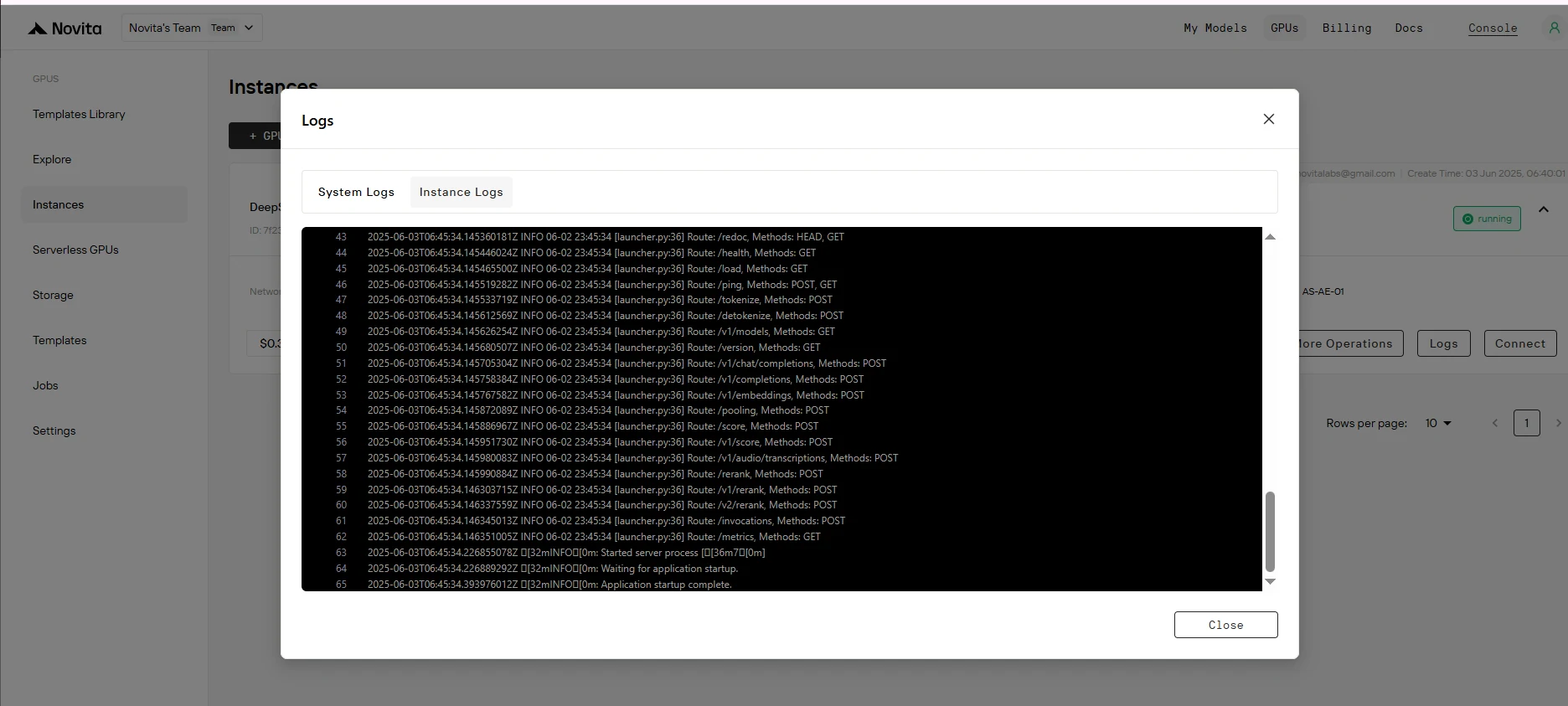
Étape 7 : Vérifier le déploiement réussi
Recherchez le message "Application startup complete." dans les logs de l’instance. Cela indique que le processus de déploiement s’est terminé avec succès.
Étape 8 : Obtenir l’URL d’accès
Cliquez sur “Connect”, puis cliquez sur “Connect to HTTP Service [Port 8000]“. Comme il s’agit d’un service API, vous devez copier l’adresse.
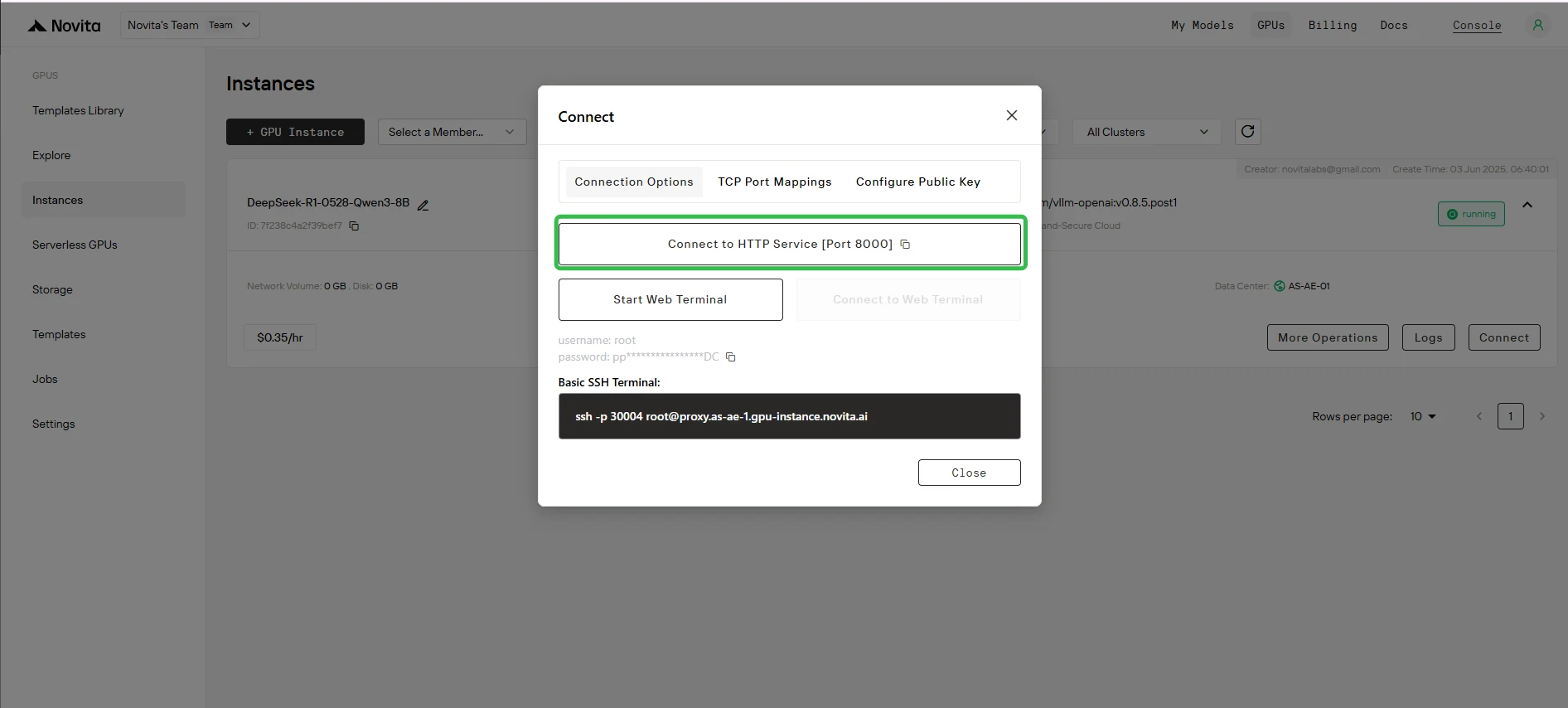

Étape 9 : Accéder à votre modèle déployé
Pour envoyer des requêtes à votre modèle, remplacez “http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai” par votre adresse exposée réelle. Copiez le code suivant pour accéder à votre modèle privé !
# Appeler le serveur avec curl :
curl -X POST "http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
]
}'
{"id":"chatcmpl-56d12c91edbb46fcb93ccbbc0ecddd2c","object":"chat.completion","created":1748588145,"model":"deepseek-ai/DeepSeek-R1-0528-Qwen3-8B","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":" thinking\
Okay, the user is asking for the capital of France. Let me start by recalling the basic answer. Paris is definitely the correct response, so I'll start with that.\
\
But why is the user asking this? They might be a student preparing for a test, or maybe someone traveling who needs to know the main city for planning. Alternatively, they could be testing my knowledge. But since it's a straightforward question, I'll focus on providing accurate information.\
\
Wait, maybe they need more context. Should I mention some points of interest to add value? Like Eiffel Tower or Louvre. That could help if they're interested in tourism or education. \
\
I should check if there's any recent political changes or administrative updates but nothing seems off with Paris' status as a capital. Alright, keep it simple but informative. Let me structure the answer first, then decide on the optional details. \
\
Also, considering the user might not want a long answer. But including key landmarks might make it more engaging. They didn't ask for historical info, so maybe just stick to the status and one or two unique facts. \
\
Yes, \"city of love\" is a common nickname, so that adds a nice touch. Alright, final answer will confirm Paris, mention the nicknames, and list two landmarks to cover possible interests without being overwhelming.\
response\
The capital of France is **Paris**.","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":10,"total_tokens":294,"completion_tokens":284,"prompt_tokens_details":null},"prompt_logprobs":null}
Configurez l’adresse API dans vos applications comme Chatbox, et vous aurez votre propre assistant personnel !
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour la construction et le passage à l’échelle.



