

A Novita AI está lançando sua campanha “Mês da Construção”, oferecendo aos desenvolvedores um incentivo exclusivo de até 20% de desconto em todos os principais produtos!
Implantar modelos multimodais em larga escala continua sendo um desafio para os desenvolvedores devido aos altos custos de infraestrutura, fluxos de trabalho de implantação complexos e trade-offs pouco claros entre desempenho, precisão e consumo de recursos. Esses desafios são particularmente pronunciados para modelos avançados de linguagem e visão, como o GLM-4.6V, que exigem VRAM substancial, suporte a contexto longo e integração estreita entre percepção visual e execução de ferramentas.
Este artigo aborda esses pontos de dor explicando sistematicamente as inovações arquitetônicas do GLM-4.6V, seu mecanismo nativo de chamada de funções multimodais, estratégias práticas de VRAM e quantização, e caminhos de implantação com bom custo-benefício na GPU em nuvem da Novita AI. Ao combinar insights em nível de modelo com orientação concreta de implantação e faturamento, o artigo ajuda os desenvolvedores a tomar decisões informadas ao construir, implantar e escalar aplicativos baseados no GLM-4.6V.
Alta Eficiência e Alto Desempenho do GLM 4.6V
O GLM-4.6V permite que tensores visuais sejam passados diretamente para as camadas de raciocínio que disparam chamadas de funções. Isso significa que o modelo efetivamente “clica” na imagem em seu espaço latente. Essa capacidade é possibilitada pela extensão do Protocolo de Contexto de Modelo (MCP), que padroniza como contextos visuais são transferidos para ferramentas externas.
Mecanismo de Chamada de Funções Multimodais Nativa
| Pipeline Tradicional (Visão-para-Texto-para-Ferramenta) | Pipeline GLM-4.6V (Visão-para-Ferramenta) |
|---|---|
| Passo 1: Codificar Imagem -> Vetor | Passo 1: Codificar Imagem -> Vetor Multimodal |
| Passo 2: Vetor -> Descrição de Texto (“Uma caixa vermelha”) | Passo 2: Vetor -> Roteador Direto |
| Passo 3: Texto -> Lógica -> Chamada de Ferramenta | Passo 3: Roteador -> Ação Executável |
| Latência: Alta (Sobrecarga de Geração de Texto) | Latência: Reduzida em 37% |
| Precisão: Baixa (Aproximação Semântica) | Precisão: Alta (Precisão em Nível de Coordenada) |
| Taxa de Sucesso: Moderada | Taxa de Sucesso: Aumentada em 18% |
Loops de Feedback Visual e Auto correção
Inspirado na pesquisa UI2Code^N da Zhipu AI, o GLM-4.6V implementa um loop de Aprendizado por Reforço (RL) especificamente para tarefas visuais. Esse processo imita o fluxo de trabalho humano de “Fazer, Verificar, Corrigir”:
- Ação: O modelo gera código (por exemplo, HTML para um site) com base em um prompt visual.
- Observação: O modelo invoca uma ferramenta de renderização para visualizar seu próprio código.
- Auditoria: O modelo compara a saída renderizada com a imagem alvo original usando seu codificador visual.
- Correção: O modelo detecta discrepâncias (por exemplo, “O preenchimento do botão está muito pequeno”) e itera sobre o código.
Essa capacidade de “Auditoria Visual” é o que permite que o GLM-4.6V alcance replicação de frontend com precisão de pixel, diferenciando-o de modelos que essencialmente “adivinham” o CSS com base em descrições de texto.
Dinâmicas da Janela de Contexto
A janela de contexto de 128.000 tokens é um recurso crítico para fluxos de trabalho empresariais. Na prática, essa capacidade se traduz em:
- Análise de Documentos: Processamento de um relatório financeiro de 150 páginas (incluindo gráficos e tabelas complexos) em uma única passagem.
- Compreensão de Vídeo: Análise de um arquivo de vídeo de 1 hora (por exemplo, uma palestra ou feed de vigilância) para extrair eventos ou resumos específicos.
- Compreensão de Base de Código: Ingestão de toda a documentação e arquivos principais de um repositório para realizar refatoração arquitetônica.
Ao contrário de modelos apenas de texto, onde “contexto longo” se refere simplesmente à contagem de palavras, em um VLM, essa janela deve acomodar a pesada pegada de tokens dos embeddings visuais. O GLM-4.6V utiliza uma técnica de “Alinhamento de Compressão Visual-Linguagem” (inspirada no Glyph) para comprimir tokens visuais, garantindo que imagens de alta resolução não esgotem a janela de contexto prematuramente.
Ecossistema de Desenvolvedores do GLM 4.6V
O GLM-4.6V é um dos primeiros modelos a suportar nativamente uma versão estendida do Protocolo de Contexto de Modelo (MCP). Esse protocolo atua como um “aperto de mão” padronizado entre o modelo de IA e o Ambiente de Desenvolvimento Integrado (IDE).
| Capacidade | Descrição |
|---|---|
| Integração com Um Clique | Conecte o GLM-4.6V ao VS Code ou Cursor com menos de 10 linhas de configuração. |
| Consciência de Contexto | O modelo recebe automaticamente a árvore de arquivos, abas abertas e estado do terminal como contexto. |
| Arrastar e Soltar Visual | Os desenvolvedores podem arrastar uma captura de tela para o IDE, e o modelo gera automaticamente o componente de código frontend correspondente. |
| Serviço Local | O servidor MCP pode apontar para uma instância local do vLLM, mantendo o código proprietário totalmente offline. |
Requisitos de VRAM e Quantização do GLM 4.6V
Embora a contagem de parâmetros ativos seja baixa (12B), o requisito de armazenamento para os pesos permanece alto (106B). Para executar o modelo completo na precisão nativa (FP16) com uma janela de contexto completa, é necessário um cluster de nível empresarial. No entanto, a quantização agressiva (INT4) combinada com o offloading de MoE (armazenando especialistas na RAM do sistema e trocando-os para a VRAM da GPU sob demanda) permite que o modelo seja executado em estações de trabalho prossumidor, embora com velocidade de inferência reduzida.
| Variante do Modelo | Precisão | Comprimento do Contexto | Estimativa de VRAM | Configuração de Hardware Recomendada |
|---|---|---|---|---|
| GLM-4.6V (106B) | FP16 / BF16 | 128K (Completo) | 640 GB - 720 GB | 8x H100 (80GB) ou 8x A100 (80GB) |
| GLM-4.6V (106B) | FP16 / BF16 | Curto (Inferência) | 96 GB - 120 GB | 2x A6000 (48GB) ou 4x RTX 3090/4090 |
| GLM-4.6V (106B) | FP8 (Quantizado) | 128K | 320 GB | 4x H100 (80GB) |
| GLM-4.6V (106B) | INT4 (Quantizado) | Curto | 64 GB | 1x A100 (80GB) ou 3x RTX 3090/4090 |
| GLM-4.6V-Flash (9B) | FP16 | 128K | 24 GB | 1x RTX 3090/4090 (24GB) |
| GLM-4.6V-Flash (9B) | INT4 | Curto | 6-8 GB | RTX 3060 / GPU de Laptop |
Implantação com vLLM e Docker
Para desenvolvedores que optam por auto-hospedar, o vLLM é o motor de inferência recomendado devido ao seu suporte a Paralelismo de Tensores (TP) e processamento de lotes contínuo.
Configuração de Implantação (Docker)
Para implantar o modelo 106B em uma configuração de 4 GPUs usando vLLM, use o padrão de configuração a seguir. Observe os argumentos específicos para a arquitetura GLM-4.5/4.6 (--tool-call-parser, --enable-expert-parallel).
Argumentos Principais:
--tensor-parallel-size 4: Distribui o modelo por 4 GPUs. Essencial para caber os pesos de 106B na memória.--tool-call-parser glm45: Ativa a lógica de parsing específica para o formato de chamada de funções nativo do GLM.--enable-expert-parallel: Otimiza a distribuição de especialistas MoE entre os dispositivos para equilibrar a carga de computação.--max-model-len: Controla o tamanho da janela de contexto. Definir isso como65536ou128000(se o hardware permitir) define o buffer de memória para o cache KV.
Uma Maneira Melhor e Mais Barata de Acessar o GLM 4.6V em GPU em Nuvem
A Novita AI oferece quatro modelos de faturamento de GPU para acomodar diferentes padrões de carga de trabalho e requisitos de custo.
Modelo de Preço Método de Faturamento Disponibilidade de Recursos Nível de Custo Risco de Interrupção Casos de Uso Típicos Sob Demanda (Pague pelo uso) Cobrado pelo tempo de execução real (por segundo ou por hora) Alta, instâncias podem ser iniciadas ou paradas a qualquer momento Médio Nenhum Desenvolvimento e testes, depuração de modelos, cargas de trabalho variáveis ou imprevisíveis Instâncias Spot Cobrado pelo tempo de execução com taxas com desconto Média, dependente da capacidade ociosa disponível Baixo (geralmente até ~50% mais barato que Sob Demanda) Sim, instâncias podem ser preemptadas Tarefas em lote, inferência offline, treinamento tolerante a falhas, cargas de trabalho sensíveis a custo Assinatura / Planos Reservados Faturamento fixo mensal ou anual Alta, recursos dedicados e previsíveis Médio-Baixo (com desconto vs. Sob Demanda) Nenhum Cargas de trabalho estáveis de longo prazo, sistemas de produção, treinamento ou inferência contínuos Faturamento de GPU Serverless Cobrado pelo consumo real de computação por execução Escala automaticamente com a demanda Baixo-Médio (pague apenas pelo que usar) Nenhum (totalmente gerenciado pela plataforma) Inferência orientada a eventos, tráfego com picos, serviço de modelos via API, sobrecarga operacional mínima
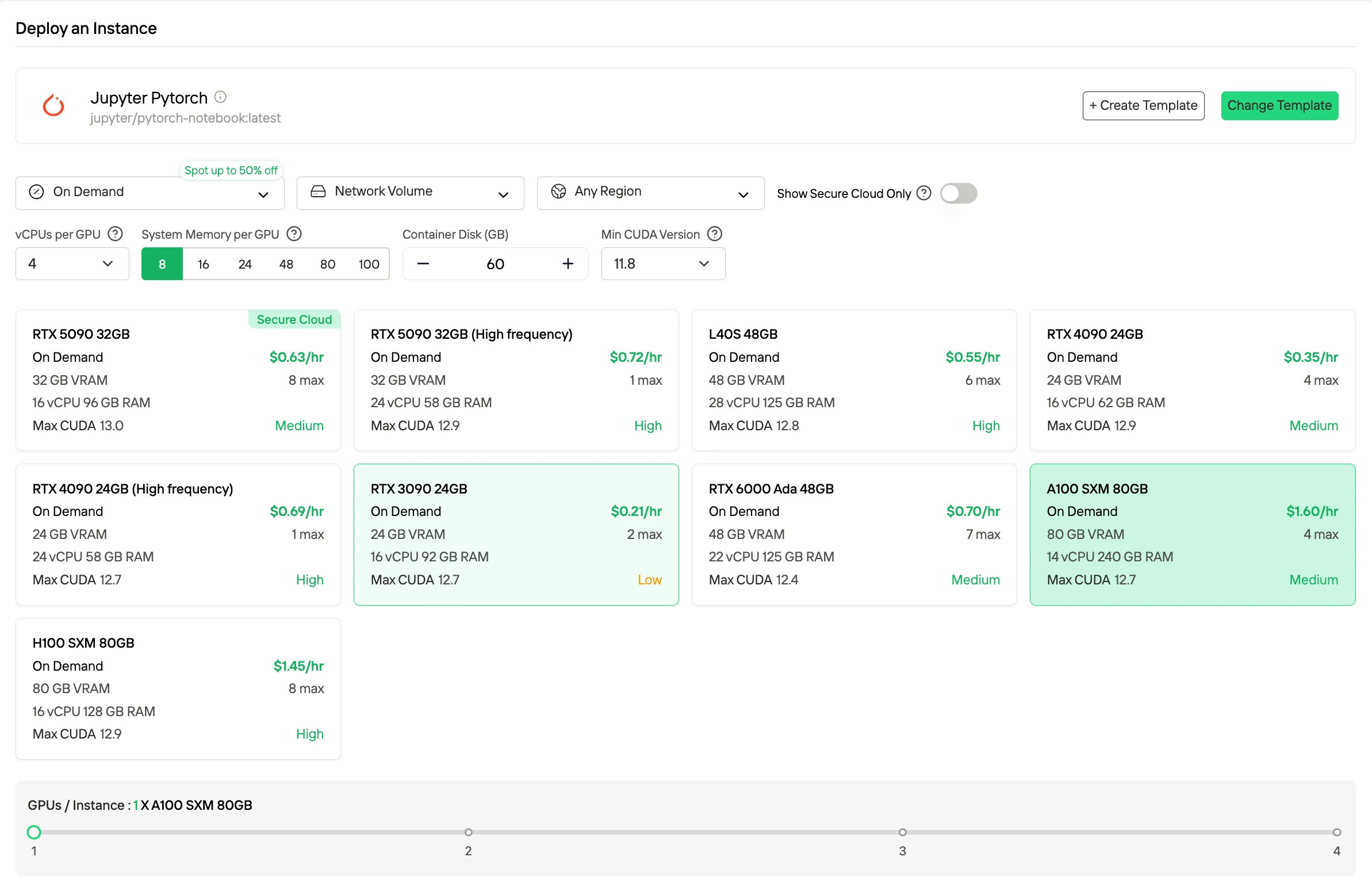
- Sob Demanda (Pague pelo uso)
O Sob Demanda é o modelo de consumo padrão, no qual a computação de GPU é cobrada estritamente pelo tempo de execução, geralmente por segundo ou por hora, sem compromissos ou reservas de longo prazo. Ele oferece máxima flexibilidade e é adequado para cargas de trabalho variáveis, uso intermitente e experimentação em estágio inicial, pois os custos são incorridos apenas enquanto a instância está ativa. Armazenamento e recursos auxiliares, incluindo discos e rede, são cobrados com base no uso.
Experimente GPUs Rápidas e Baratas Agora!
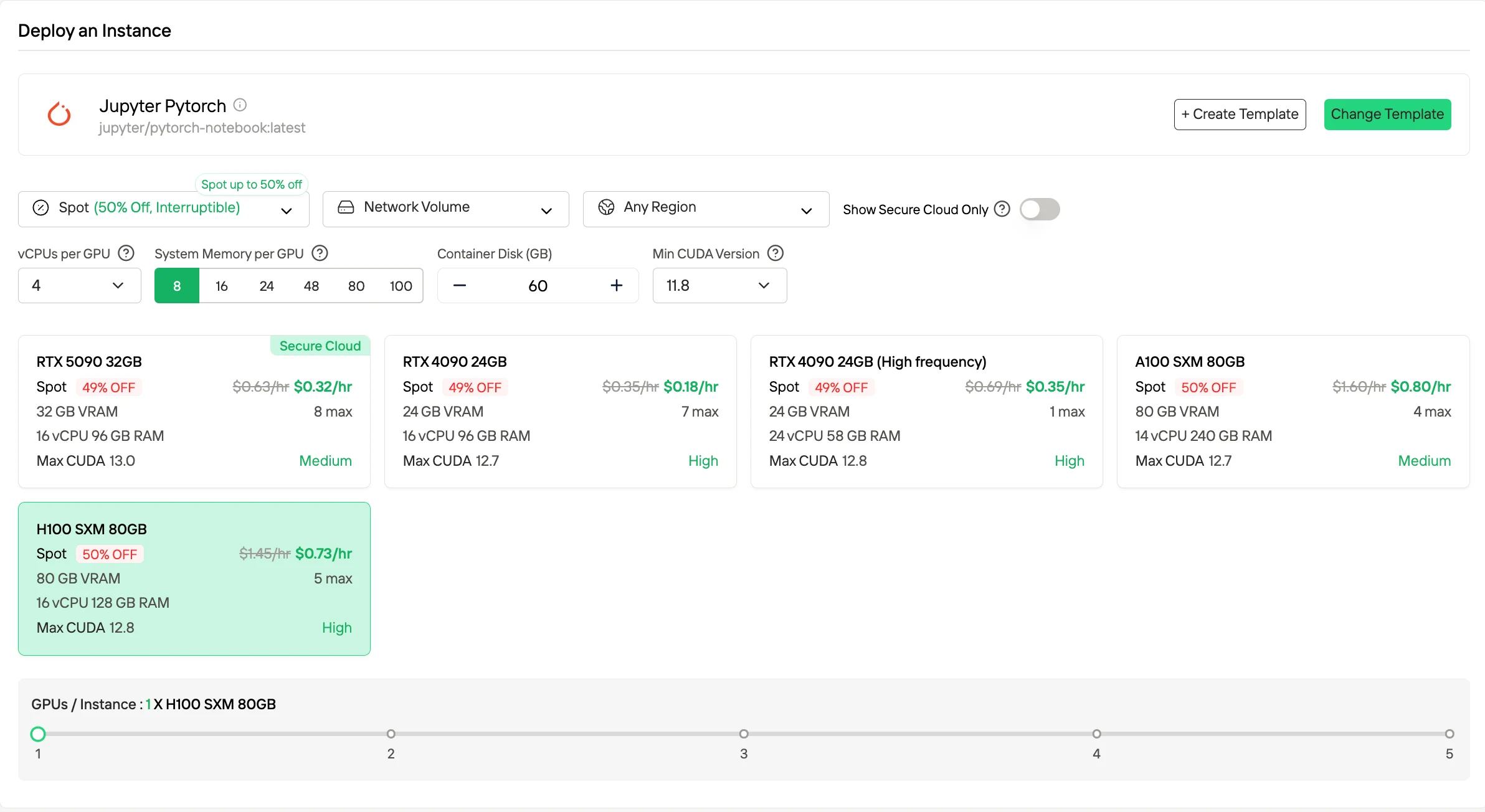
- Instâncias Spot
As Instâncias Spot oferecem preços horários substancialmente reduzidos, geralmente até aproximadamente 50% menores que as taxas Sob Demanda, ao utilizar capacidade ociosa de GPU. Essas instâncias podem ser preemptadas pela plataforma. A Novita mitiga esse risco fornecendo uma janela de proteção de uma hora e notificações de término antecipado. Esse modo de preço é apropriado para cargas de trabalho tolerantes a falhas ou em lote, onde interrupções ocasionais podem ser acomodadas.
Experimente GPUs Rápidas e Baratas Agora!
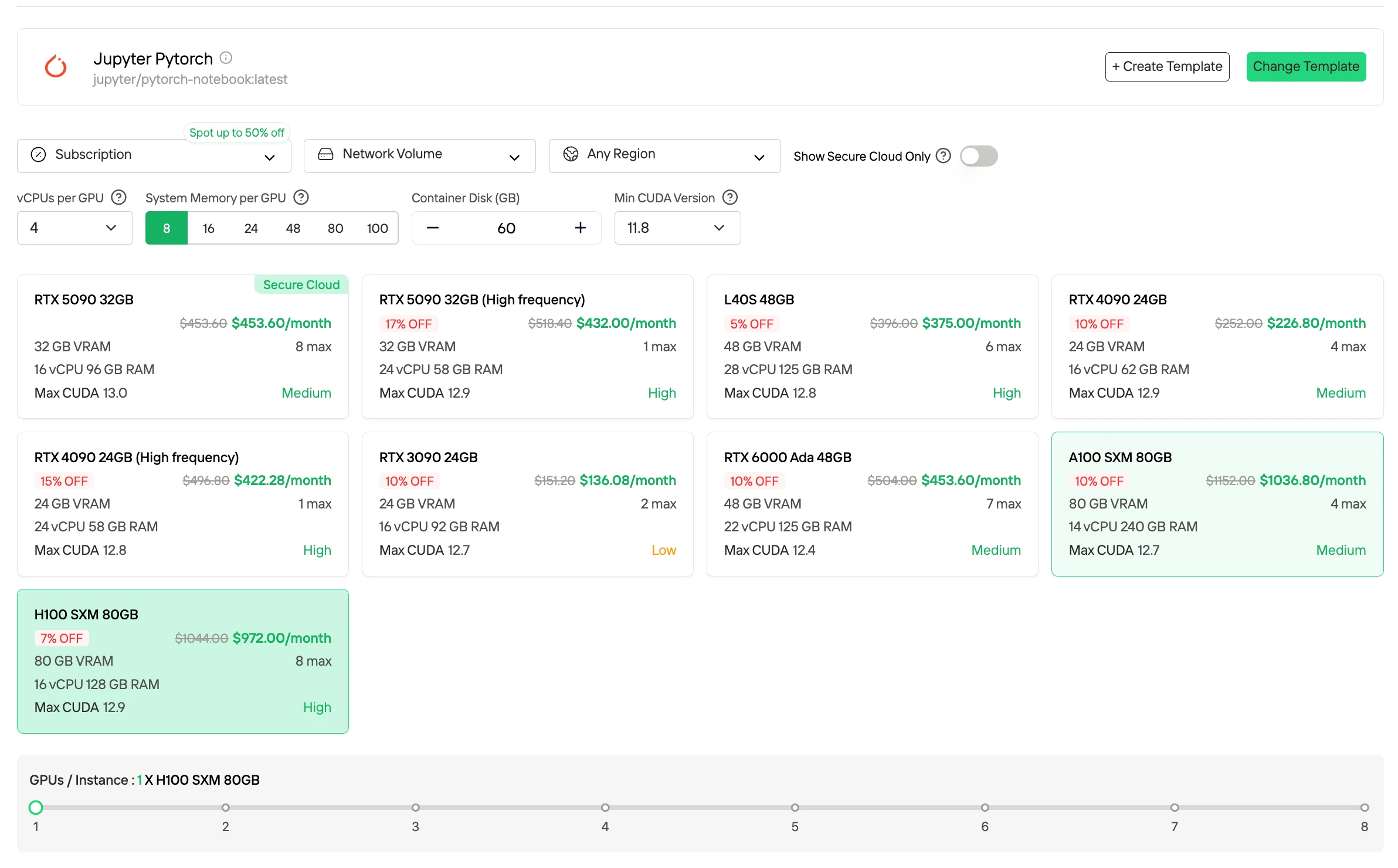
- Assinatura / Planos Reservados
Assinaturas e planos reservados estão disponíveis em termos mensais ou anuais e fornecem recursos de GPU dedicados com disponibilidade previsível. Comparado com o preço Sob Demanda, esses planos geralmente oferecem custos unitários efetivos menores em troca de compromisso de longo prazo. Eles são mais adequados para cargas de trabalho estáveis e contínuas e ambientes de produção que exigem capacidade de computação consistente.
Experimente GPUs Rápidas e Baratas Agora!
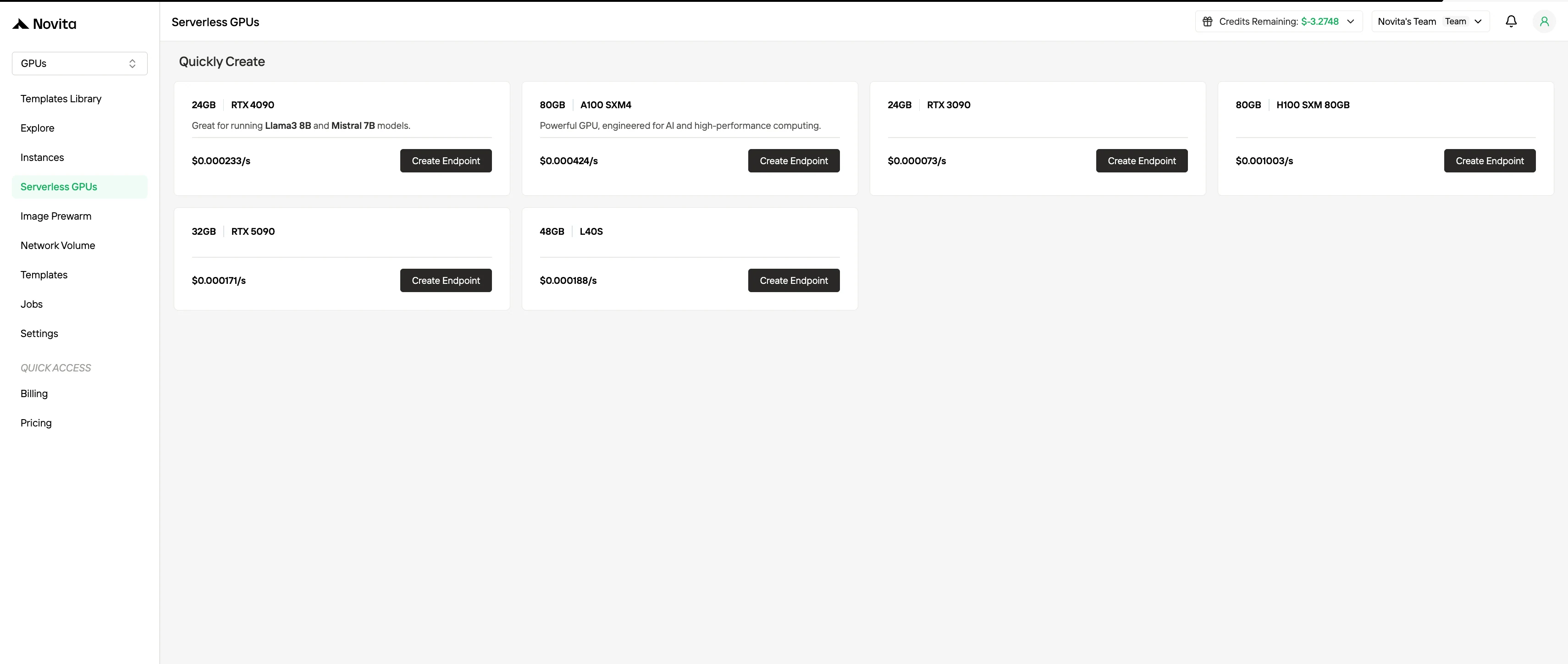
- Faturamento de GPU Serverless
O faturamento de GPU serverless abstrai o gerenciamento de instâncias, escalando automaticamente os recursos de GPU em resposta à demanda da carga de trabalho. Os usuários são cobrados apenas pelos recursos de computação realmente consumidos, em vez de instâncias provisionadas. Esse modelo é vantajoso para cargas de trabalho orientadas a eventos ou altamente elásticas, pois minimiza a sobrecarga operacional enquanto melhora a eficiência de custos.
Experimente GPUs Rápidas e Baratas Agora!
A Novita AI também oferece modelos, projetados para reduzir significativamente a sobrecarga operacional e cognitiva associada à implantação de cargas de trabalho de IA baseadas em GPU. Em vez de exigir que os desenvolvedores montem ambientes manualmente do zero, o sistema de modelos fornece imagens pré-configuradas, prontas para produção, que agrupam o sistema operacional, versões de CUDA e cuDNN, frameworks de aprendizado profundo, motores de inferência e, em alguns casos, até pilhas de serviço de modelo totalmente conectadas.
Como Implantar o GLM 4.6V na Novita AI
Passo 1: Registrar uma conta
Crie sua conta na Novita AI através do nosso site. Após o registro, navegue até a seção “Explorar” na barra lateral esquerda para ver nossas ofertas de GPU e começar sua jornada de desenvolvimento de IA.

Passo 2: Explorar Modelos e Servidores GPU
Escolha entre modelos como PyTorch, TensorFlow ou CUDA que correspondam às necessidades do seu projeto. Em seguida, selecione a configuração de GPU de sua preferência — as opções incluem a poderosa L40S, RTX 4090 ou A100 SXM4, cada uma com diferentes especificações de VRAM, RAM e armazenamento.
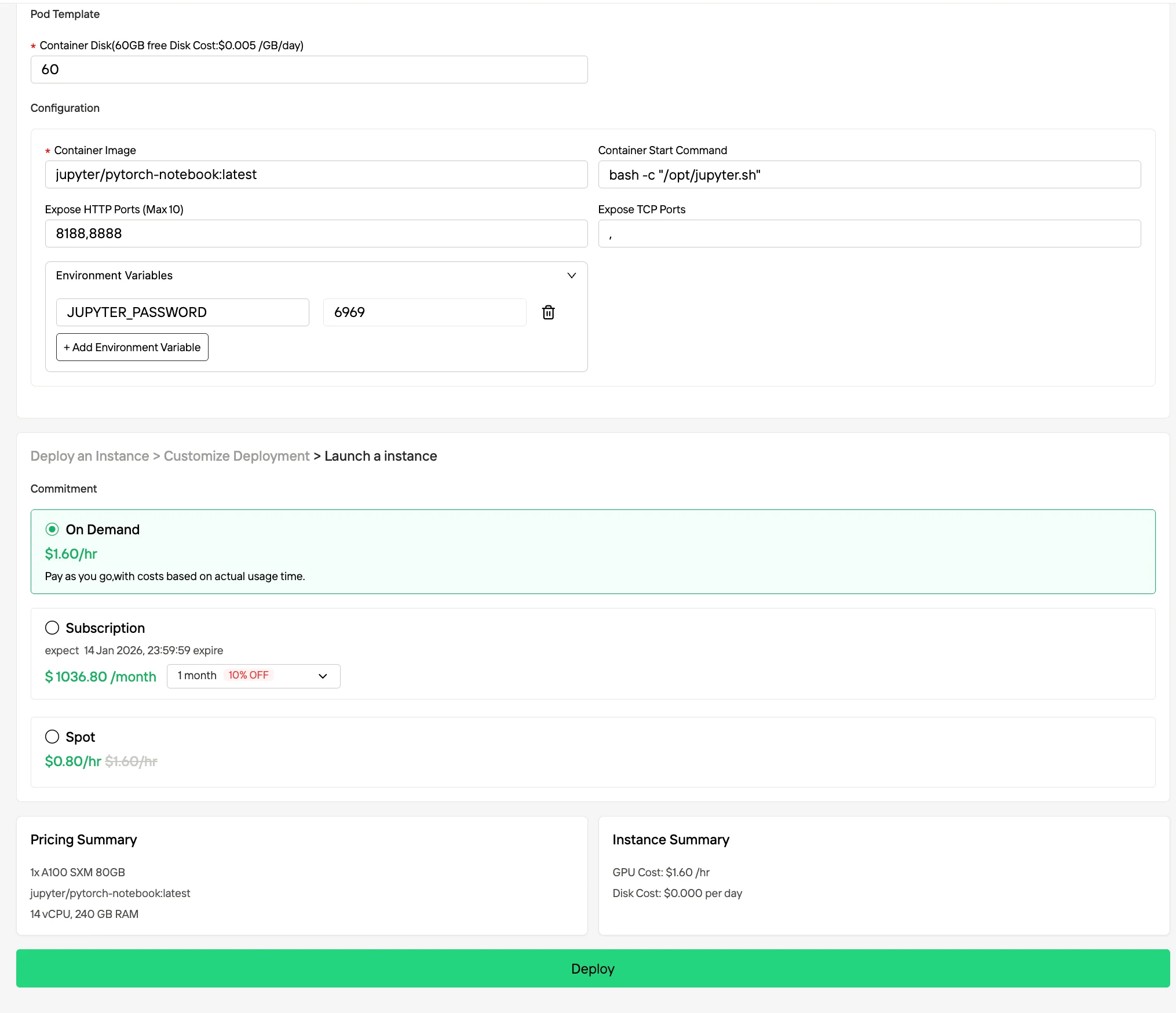
Passo 3: Personalizar sua Implantação e Iniciar uma Instância
Personalize seu ambiente selecionando o sistema operacional e as opções de configuração de sua preferência para garantir o desempenho ideal para suas cargas de trabalho de IA e necessidades de desenvolvimento específicas. Em seguida, seu ambiente de GPU de alto desempenho estará pronto em minutos, permitindo que você comece imediatamente seus projetos de aprendizado de máquina, renderização ou computação.
Passo 4: Monitorar o Progresso da Implantação
Navegue até o Gerenciamento de Instâncias para acessar o console de controle. Esse painel permite que você acompanhe o status da implantação em tempo real.
Experimente GPUs Rápidas e Baratas Agora!
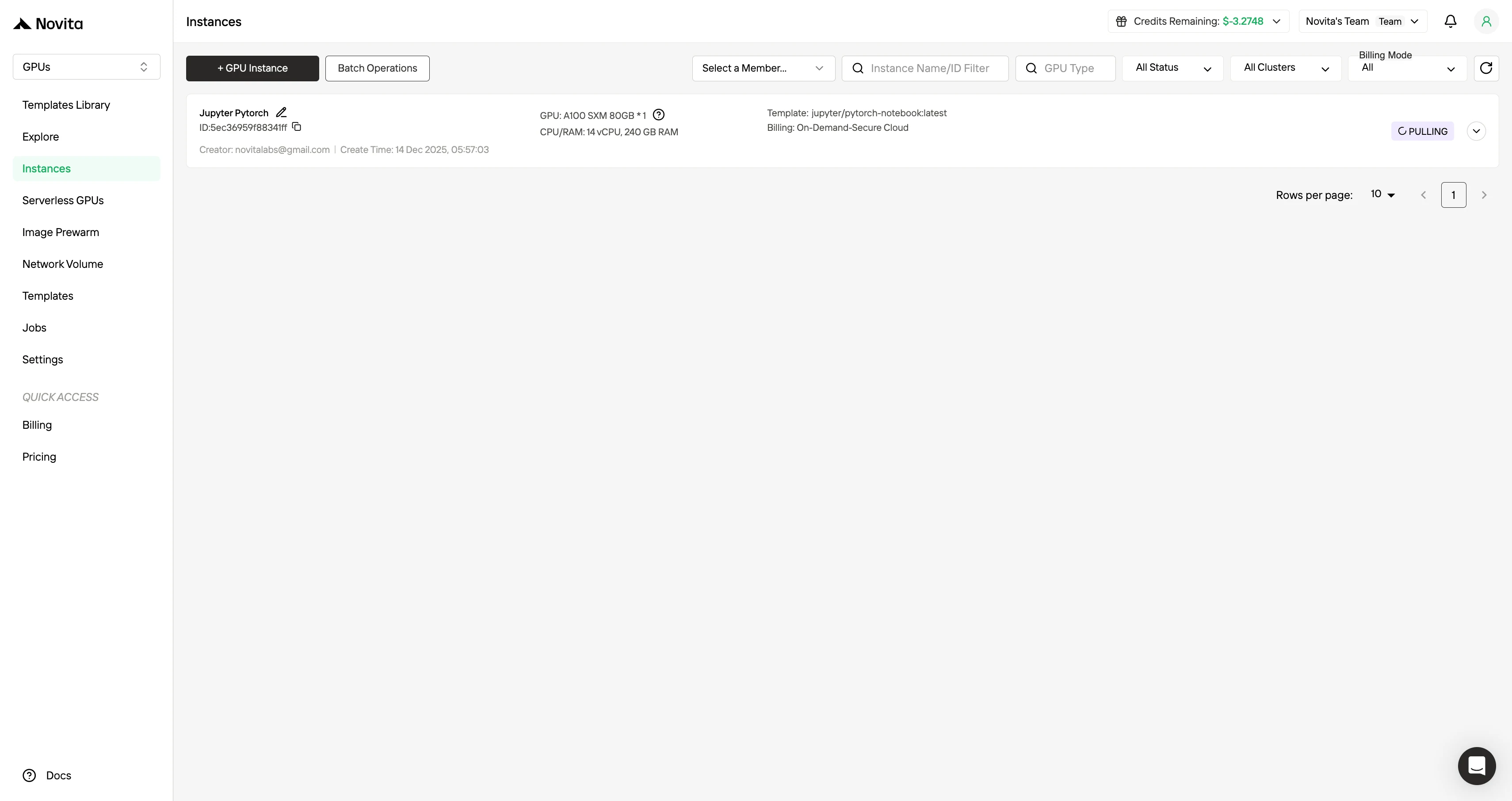
Passo 5: Visualizar o Status do Pull de Imagem
Clique na sua instância específica para monitorar o progresso do download da imagem do contêiner. Esse processo pode levar vários minutos, dependendo das condições de rede.
Passo 6: Verificar Implantação Bem-Sucedida
Depois que a instância for iniciada, ela começará a baixar o modelo. Clique em “Logs” → “Logs da Instância” para monitorar o progresso do download do modelo. Procure pela mensagem
"Application startup complete."nos logs da instância. Isso indica que o processo de implantação foi concluído com sucesso.Clique em “Conectar”, depois clique em → “Conectar ao Serviço HTTP [Porta 8000]”. Como este é um serviço de API, você precisará copiar o endereço.
Para fazer solicitações ao seu modelo, substitua “http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai” pelo seu endereço exposto real. Copie o código abaixo para acessar seu modelo privado!
O GLM-4.6V representa um avanço significativo no raciocínio multimodal, permitindo execução nativa de visão para ferramenta, loops de feedback visual e compreensão de contexto longo em uma única arquitetura unificada. Embora sua implantação em precisão total exija hardware de nível empresarial, a quantização e o offloading de MoE tornam o GLM-4.6V acessível a uma gama mais ampla de desenvolvedores. A Novita AI reduz ainda mais as barreiras de adoção, oferecendo modelos de faturamento de GPU flexíveis, modelos pré-configurados e fluxos de trabalho de implantação simplificados. Juntos, o GLM-4.6V e a Novita AI fornecem uma base prática, escalável e com bom custo-benefício para construir aplicativos multimodais de próxima geração.
Perguntas Frequentes
O que diferencia o GLM-4.6V dos modelos de linguagem e visão tradicionais?
O GLM-4.6V suporta chamada de funções multimodais nativa, permitindo execução direta de visão para ferramenta sem geração de texto intermediária.
Por que o GLM-4.6V requer VRAM tão grande em precisão total?
Embora os parâmetros ativos do GLM-4.6V sejam limitados, seus 106B pesos armazenados e o cache KV de contexto longo aumentam significativamente os requisitos de VRAM.
Como o GLM-4.6V alcança precisão de frontend em nível de pixel?
O GLM-4.6V usa um loop de auditoria visual baseado em aprendizado por reforço que compara as saídas renderizadas com as imagens alvo.
A Novita AI é a plataforma em nuvem tudo-em-um que capacita suas ambições de IA. APIs integradas, serverless, Instância de GPU — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA realidade.



