

- Quais São as Principais Melhorias do DeepSeek V3.1 em Relação ao R1?
- DeepSeek V3.1 VS DeepSeek R1: Notas de Lançamento
- DeepSeek V3.1 VS DeepSeek R1: Arquitetura
- DeepSeek V3.1 VS DeepSeek R1: Benchmark
- DeepSeek V3.1 VS DeepSeek R1: Velocidade
- DeepSeek V3.1 VS DeepSeek R1: Requisitos do Sistema
- DeepSeek V3.1 VS DeepSeek R1: Aplicações
- Como Acessar DeepSeek V3.1 e R1 por uma API Barata e Estável?
Quando a DeepSeek apresentou o V3.1 em agosto de 2025, muitos esperavam uma nova geração: “Por que não R2?” A resposta está na sua mudança estratégica: deixar de ser um motor de raciocínio puro para se tornar um LLM flexível e pronto para agentes. Enquanto o DeepSeek R1 era um modelo de raciocínio de ponta alimentado por aprendizado por reforço, o V3.1 representa uma evolução diferente: uma que combina interação rápida, raciocínio profundo e uso de ferramentas.
Este artigo explora as principais diferenças entre DeepSeek V3.1 e R1, não apenas do ponto de vista de benchmarks ou arquitetura, mas sob a perspectiva de por que a DeepSeek está migrando para inferência híbrida, casos de uso reais com agentes e eficiência.
Quais São as Principais Melhorias do DeepSeek V3.1 em Relação ao R1?
| Dimensão | DeepSeek V3.1 | R1 |
|---|---|---|
| Suporte a Modos | Modo de Pensamento Híbrido. Suporta alternância via template de chat: • thinking ativa raciocínio em cadeia de pensamento• response muda para modo de resposta direta |
Modo exclusivo de raciocínio. Principalmente raciocínio em cadeia de pensamento com modo fixo |
| Capacidade de Ferramentas/Agente | Habilidades de Agente Mais Fortes. • Pós-treinamento melhora o uso de ferramentas • Suporte a chamadas de ferramentas estruturadas • Templates especializados para código/busca |
Inicialmente sem suporte. A atualização R1-0528 adicionou posteriormente saída JSON e chamada de função |
| Eficiência de Inferência | Respostas mais rápidas. • Modo DeepThink ≈ qualidade das respostas do R1 • Modo sem pensamento é mais rápido, adequado para aplicações sensíveis a latência |
Mais lento, mas estável. • Principalmente modo de raciocínio, melhor para tarefas que exigem precisão |
DeepSeek V3.1 VS DeepSeek R1: Notas de Lançamento
DeepSeek R1 (Janeiro de 2025)
- Primeiro modelo de raciocínio baseado em RL
- Paridade de Desempenho: Equipara ao o1 da OpenAI (equivalente ao GPT-4o) em benchmarks de matemática/código/raciocínio
- SOTA com Modelo Denso: Seis modelos destilados menores (1,5B–70B) alcançando resultados de ponta
- Abordagem Inovadora: Pioneirismo na metodologia “RL em larga escala no pós-treinamento”
DeepSeek R1–0528 (Maio de 2025)
- Atualização intermediária com melhorias de qualidade e usabilidade
- Melhorias em Benchmarks: Métricas de desempenho aprimoradas
- Atualizações no Frontend: Experiência de interação do usuário melhorada
- Redução de Alucinações: Maior consistência factual
- Novos Recursos na API: Suporte a saída JSON e chamada de função
DeepSeek V3.1 (Agosto de 2025)
- Primeiro passo rumo à era dos agentes
- Inferência Híbrida: Um modelo suportando modos duais (Think & Non-Think)
- Pensamento Mais Rápido: V3.1-Think alcança resultados mais rápido que o R1–0528
- Habilidades de Agente Aprimoradas: Melhorias pós-treinamento para uso de ferramentas e tarefas de múltiplas etapas
- Suporte a Contexto: Mantém contexto de 128K tokens em todos os modos
DeepSeek V3.1 VS DeepSeek R1: Arquitetura

DeepSeek V3.1 VS DeepSeek R1: Benchmark
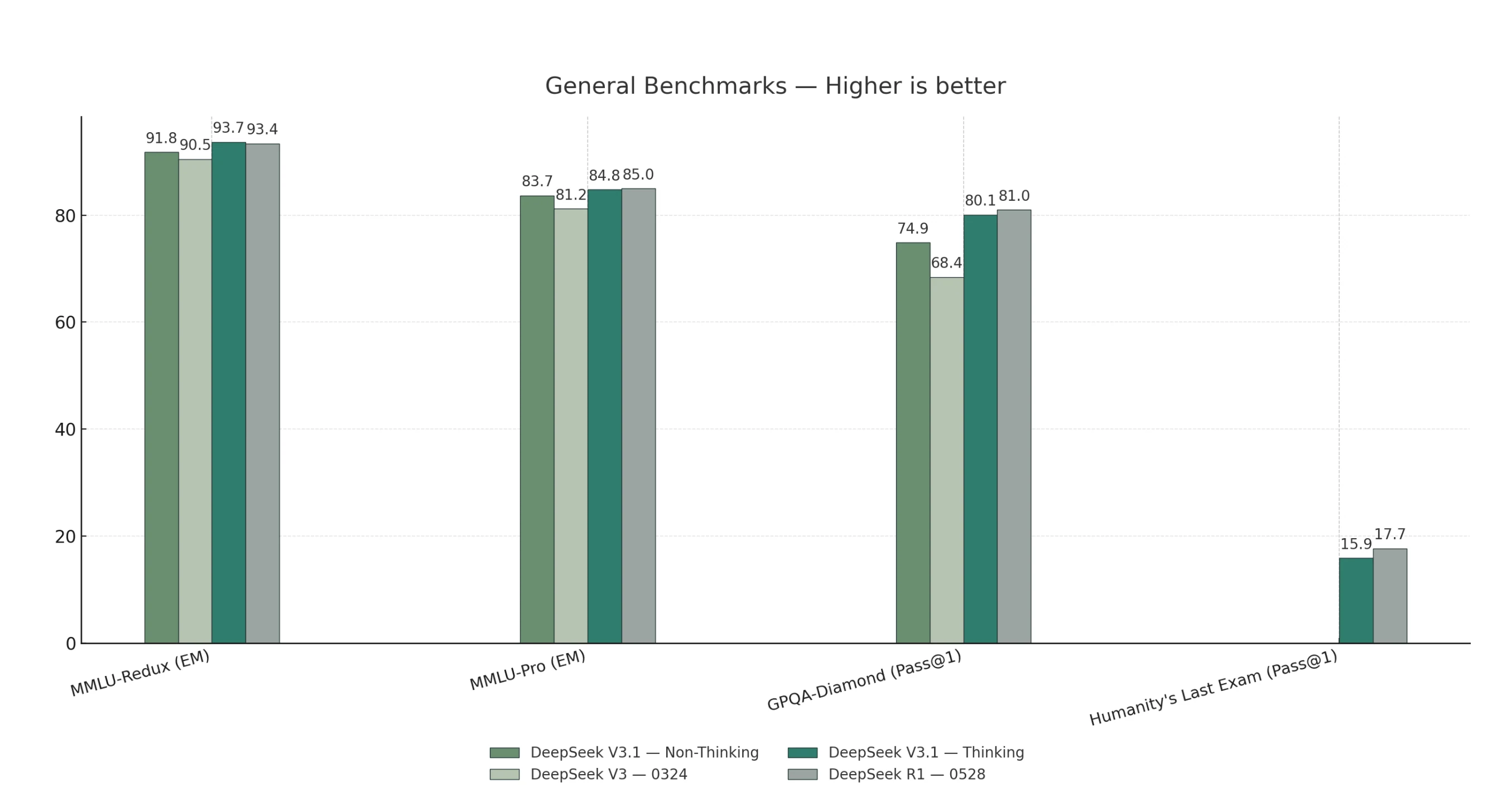
Benchmark Geral
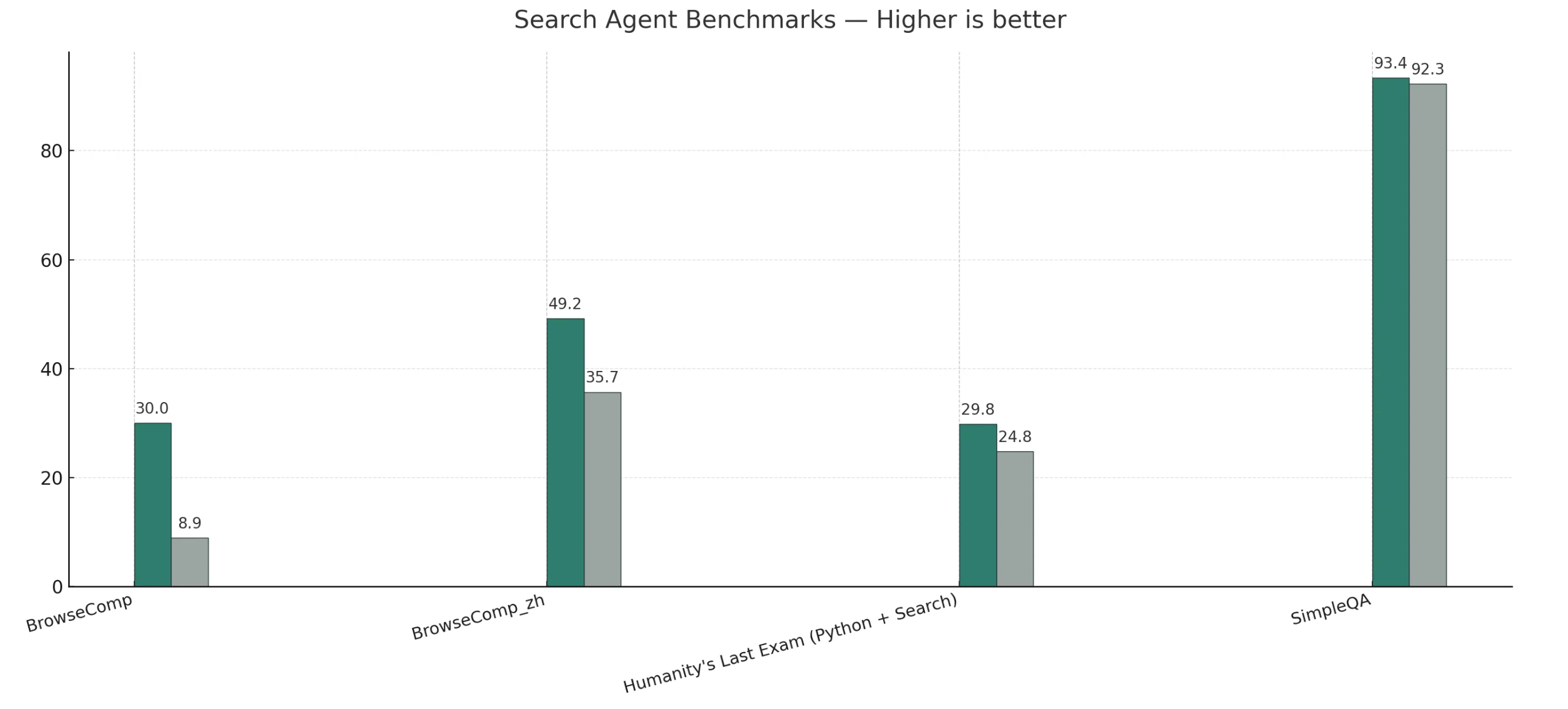
Benchmark de Agente de Busca
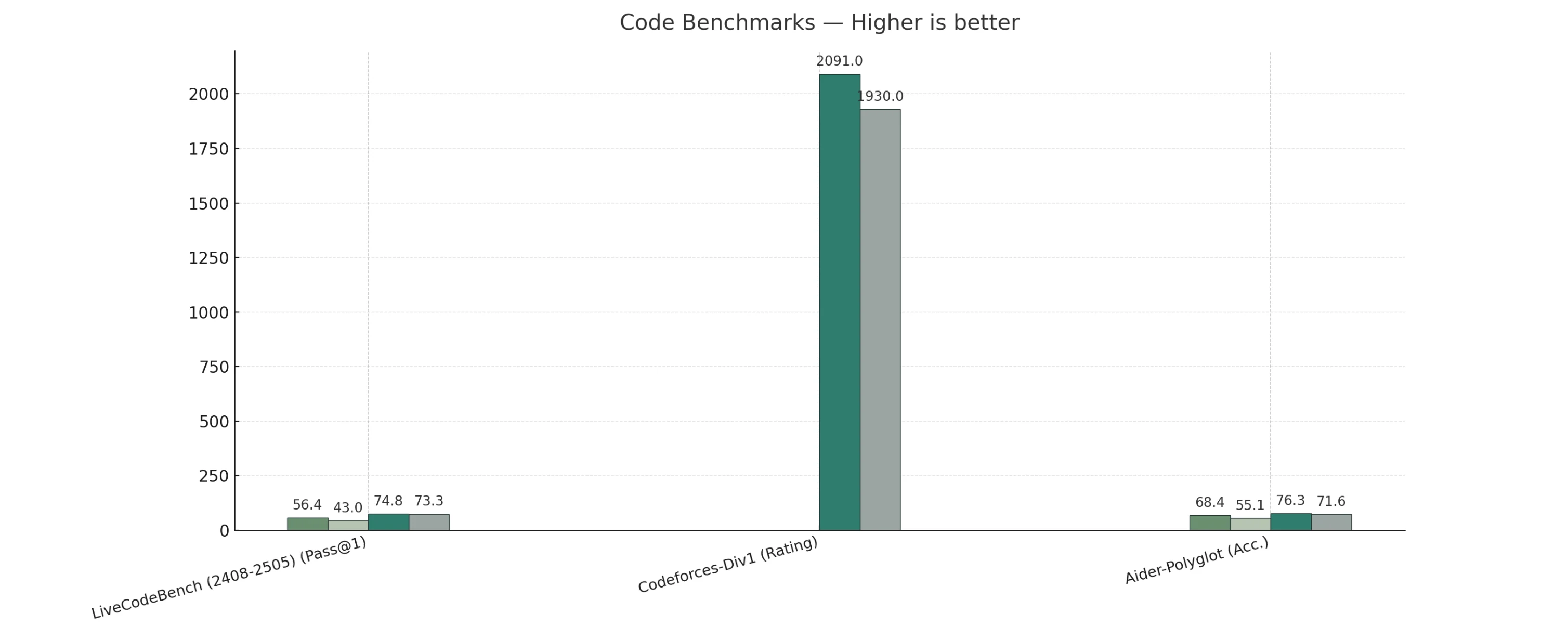
Benchmark de Código
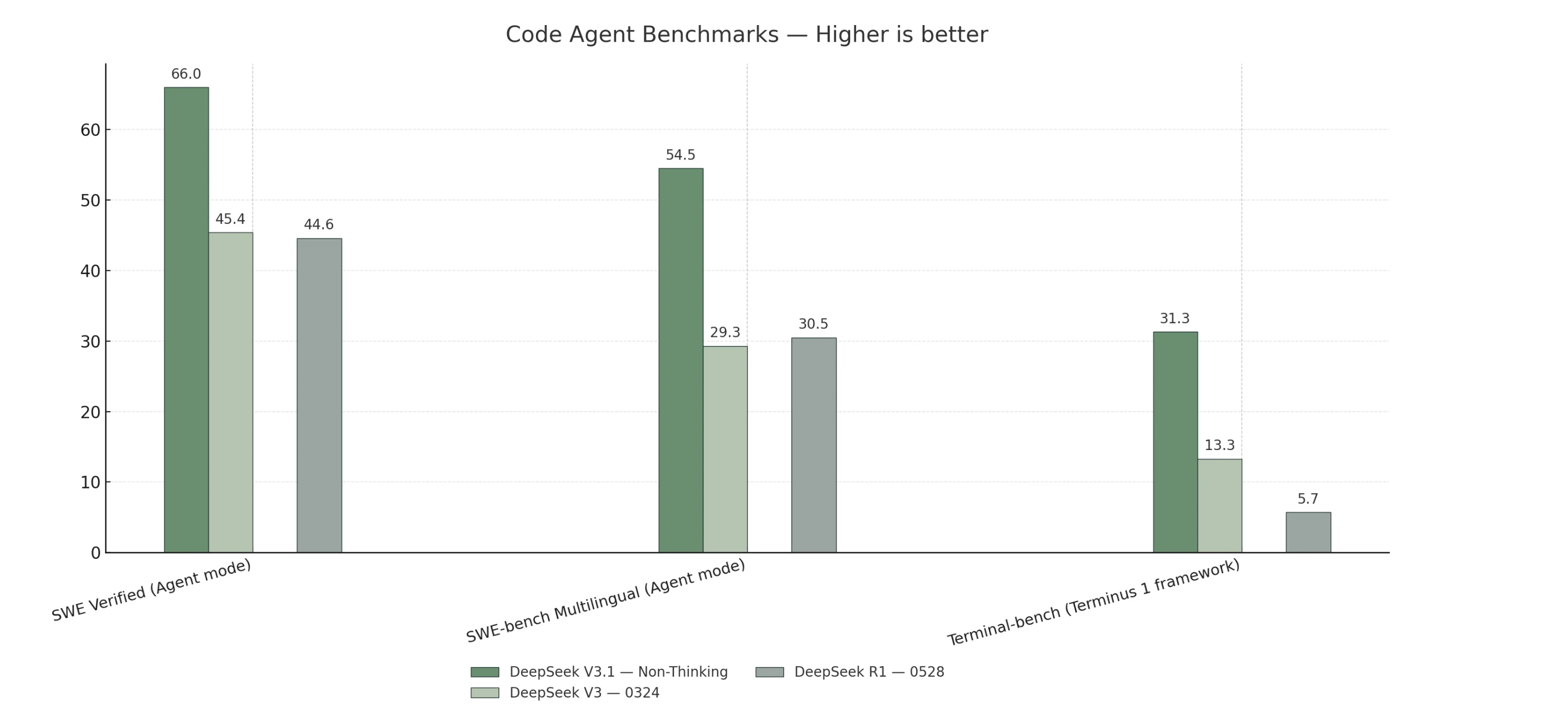
Benchmark de Agente de Código
Benchmark de Matemática
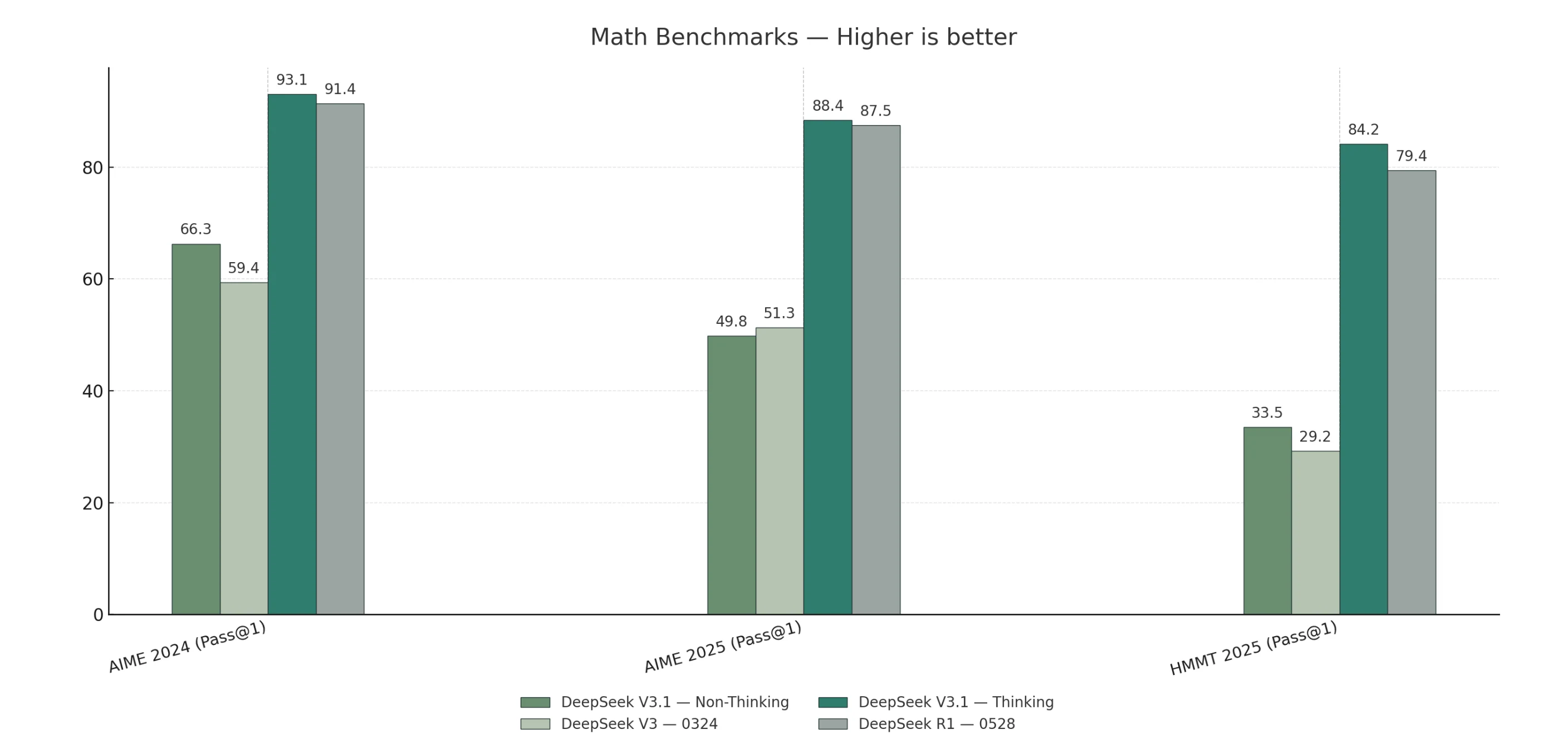
V3.1-Thinking supera ou iguala o R1-0528 em tarefas gerais, de codificação, matemática e busca.
V3.1-Non-Thinking lidera nos benchmarks de agente de código, enquanto o R1-0528 mostra apenas uma ligeira vantagem em raciocínio de humanidades de formato longo.
DeepSeek V3.1 VS DeepSeek R1: Velocidade
| Métrica | DeepSeek V3.1 (Sem pensamento) | DeepSeek R1–0528 | DeepSeek V3.1 (Raciocínio) |
|---|---|---|---|
| Velocidade de Saída (tokens/s, maior é melhor) | 20 | 20 | 20 |
| Latência – Tempo até o Primeiro Token de Resposta (s) | 2,9 | 102,3 | 103,9 |
| Tempo de Resposta Fim a Fim (500 tokens) (s, menor é melhor) | 28,1 (25,2 entrada + 2,9 saída) | 127,1 (99,4 entrada + 24,9 saída + 2,8 pensamento est.) | 129,2 (101 entrada + 25,2 saída + 3,0 pensamento est.) |
Teste o DeepSeek V3.1 Agora no Playground Grátis!
O valor do modo de Pensamento Híbrido do V3.1 está na flexibilidade:
- Modo sem pensamento: Menor latência (apenas 2,9s até o primeiro token, 28,1s para uma resposta completa de 500 tokens). Ideal para aplicações sensíveis a latência, como chat ou APIs interativas.
- Modo de raciocínio: Desempenho comparável ao R1–0528, mantendo forte precisão na cadeia de pensamento. Ideal para tarefas complexas de raciocínio.
- Otimização geral: A melhoria não está na velocidade bruta de saída, mas na capacidade de evitar longos “atrasos de pensamento”. Isso permite que o V3.1 equilibre tanto interação rápida quanto raciocínio profundo dependendo da tarefa.
DeepSeek V3.1 VS DeepSeek R1: Requisitos do Sistema
| Modelo | #Total de Parâmetros | #Parâmetros Ativados | Comprimento do Contexto |
|---|---|---|---|
| DeepSeek-V3.1-Base | 671B | 37B | 128K |
| DeepSeek-V3.1 | 671B | 37B | 128K |
| DeepSeek-R1-0528 | 671B | 37B | 128K |
| DeepSeek-R1 | 671B | 37B | 128K |
O modelo MoE completo de 671B requer cerca de 1–1,5 TB de RAM de GPU para ser executado em precisão total.
E para aproveitar as otimizações FP8 do V3.1, recomenda-se GPUs com suporte a FP8 (NVIDIA H100, H200, série Blackwell).
Você pode usar a cobrança spot da Novita AI para obter H200 SXM por apenas $1,63/hora, ou H100 SXM por apenas $0,90/hora.
DeepSeek V3.1 VS DeepSeek R1: Aplicações
| Tipo de Tarefa | Modelo Recomendado | Modo Recomendado |
|---|---|---|
| Chamada de API para Ferramentas | DeepSeek V3.1 | Modo sem pensamento |
| Execução de Agente com Múltiplas Etapas | DeepSeek V3.1 | Modo sem pensamento |
| Raciocínio de Matemática / Lógica / Programação | DeepSeek V3.1 ou R1 | Modo de pensamento |
| Interação Rápida com o Usuário | DeepSeek V3.1 | Modo sem pensamento |
| Leitura e Resumo de Documentos Longos | DeepSeek V3.1 | Modo de pensamento (Contexto de 128K) |
Em resumo, R1 é um motor de raciocínio de ponta, melhor para tarefas que enfatizam lógica e cálculo, enquanto V3.1 é um modelo mais versátil e capaz de atuar como agente, atendendo tanto a chat geral quanto a aplicações sofisticadas baseadas em ferramentas.
Como Acessar DeepSeek V3.1 e R1 por uma API Barata e Estável?
A Novita AI integra uma ampla gama de modelos DeepSeek, incluindo V3.1, R1 0528, V3 Turbo, R1 Turbo e várias destilações leves como Qwen 14B/32B e LLaMA 70B — cobrindo desde raciocínio de contexto longo até inferência de baixo custo.
O que diferencia a Novita é seu DeepSeek R1 Turbo otimizado internamente, com até 3× mais throughput e um desconto limitado de 60%, tornando-o uma escolha ideal para desenvolvedores que buscam desempenho e preço acessível.
| Métrica | DeepSeek V3.1 Valor |
|---|---|
| Preço de Entrada | $0,55 |
| Preço de Saída | $1,66 |
| Latência | 3,00s |
| Throughput | 48,28 tps |
| Uptime | 🟩🟩🟩 |
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie Seu Teste Grátis
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar na API, forneceremos uma nova chave de API. Acesse a página “Settings” e copie a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
base_url = "https://api.novita.ai/openai"
api_key = "<Sua Chave de API>"
model = "deepseek/deepseek-v3.1"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # ou False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "Olá!",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
DeepSeek R1 continua sendo um benchmark de raciocínio — foi pioneiro no pós-treinamento baseado em RL e rivalizou com o GPT-4o em tarefas de matemática e lógica. Mas é lento, rígido e não foi construído para agentes.
DeepSeek V3.1, por outro lado, é projetado para a era de implantação no mundo real:
- 🔁 Alterna entre raciocínio e velocidade.
- 🛠️ Chame APIs, agentes e ferramentas nativamente.
- 🚀 Inferência mais rápida, pague menos e integre de forma mais inteligente.
Em vez de nomeá-lo R2, a DeepSeek escolheu sinalizar uma nova direção com o V3.1: não é apenas mais inteligente — é mais utilizável.
Para desenvolvedores, pesquisadores e empresas, o V3.1 é uma alternativa prática, flexível e pronta para produção, enquanto o R1 permanece como um benchmark acadêmico.
Perguntas Frequentes
O V3.1 é apenas uma versão mais rápida do R1?
Não exatamente. Embora o V3.1-Think iguale o R1 em qualidade de raciocínio, seu modo sem pensamento oferece latência ultrabaixa. Mais importante, o V3.1 suporta tarefas agentivas e uso estruturado de ferramentas, o que o R1 não suporta (nativamente).
Por que a DeepSeek pulou o nome “R2”?
Porque o V3.1 não é apenas um novo modelo de raciocínio — é um novo paradigma híbrido. O nome sinaliza que a DeepSeek está focada na prontidão para a era dos agentes, não apenas em lógica melhor.
Como posso testar o DeepSeek V3.1 facilmente?
Você pode usar a Novita AI para testar o DeepSeek V3.1 instantaneamente no playground gratuito. A Novita oferece:
✅ Suporte completo para DeepSeek V3.1, R1 e modelos Turbo
💸 H100 a partir de $0,90/hora, H200 a partir de $1,63/hora (preço spot)
Novita AI é a plataforma all-in-one na nuvem que impulsiona suas ambições de IA. APIs integradas, serverless, instância GPU — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA realidade.
Leituras Recomendadas
Qwen 3 em Pipelines RAG: Modelos LLM, Embedding e Reranking Tudo em Um
Trae ou Claude Code: Qual é Mais Adequado para Usar com Kimi K2?
Custo do DeepSeek R1 0528: Comparação entre API, GPU e On-Prem



