

주요 하이라이트
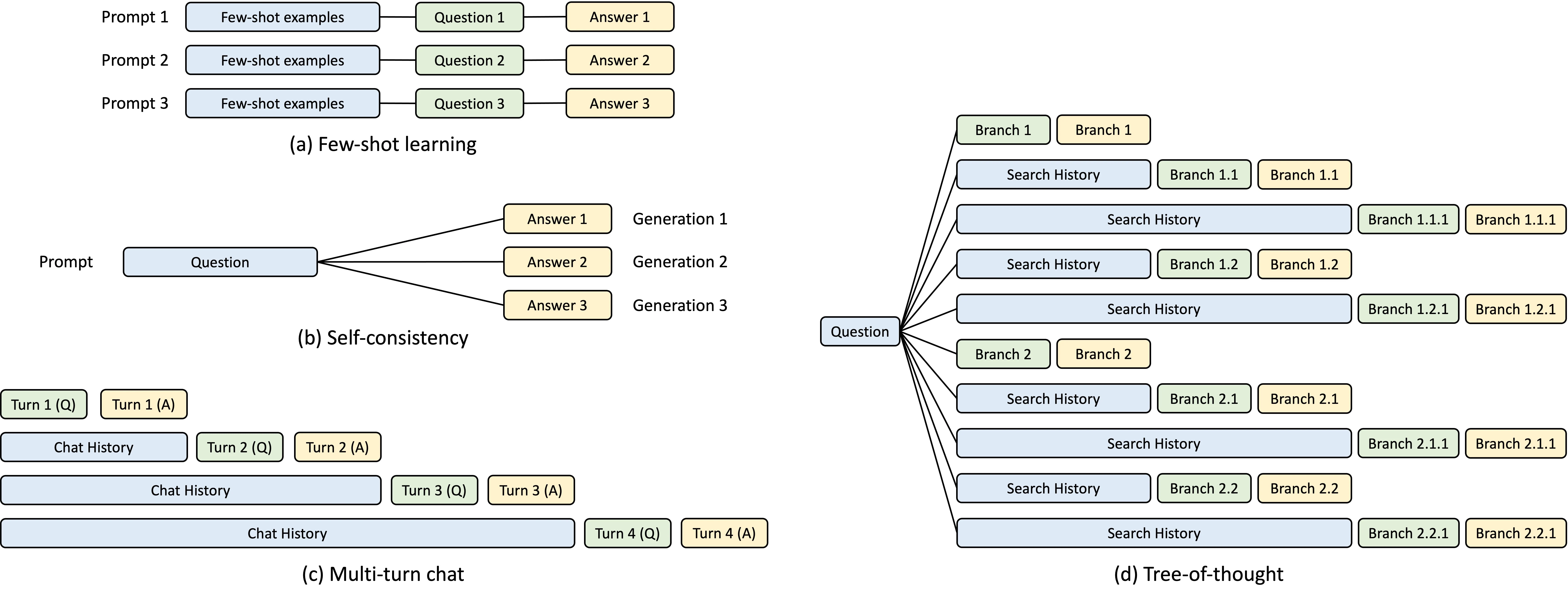
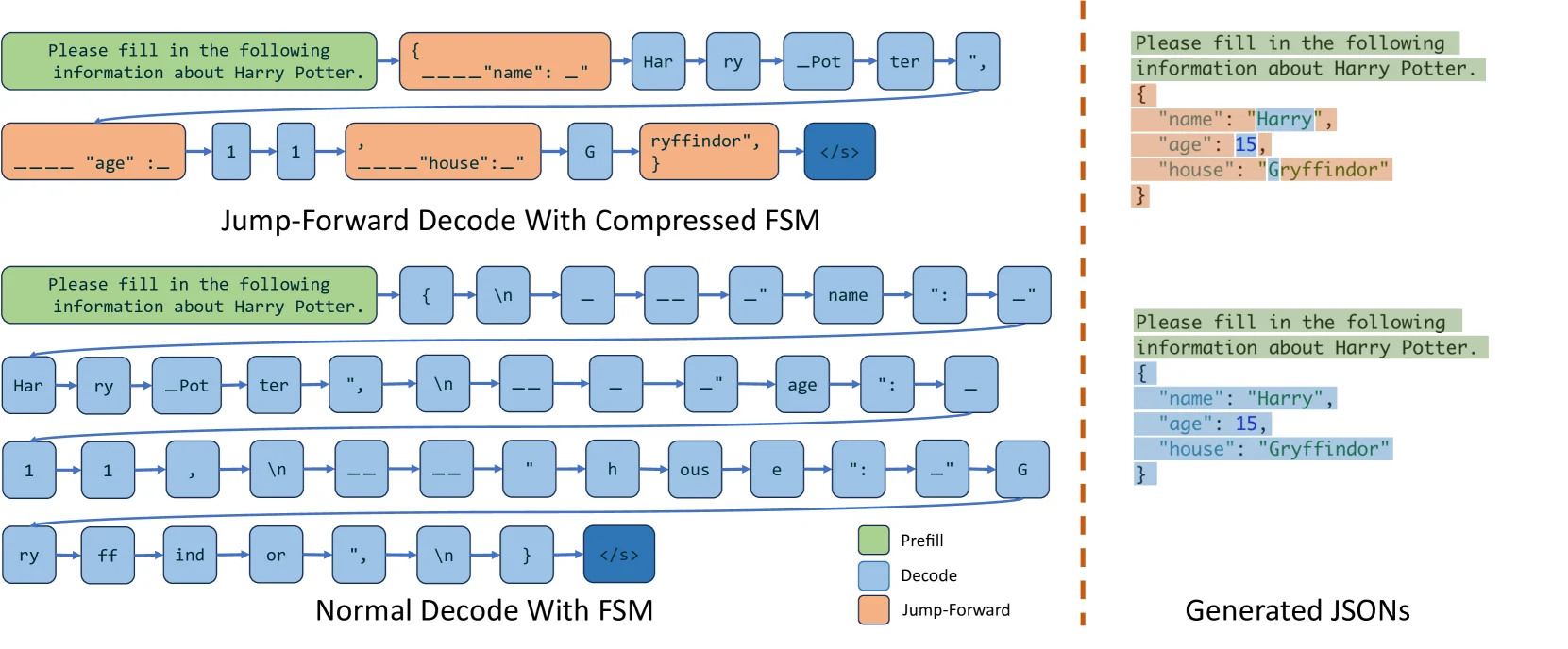
효율적인 실행 ** : SGLang은 공동 설계된 프론트엔드 언어와 최적화된 백엔드 런타임을 결합하며, KV 캐시 재사용을 위한 RadixAttention 과 더 빠른 구조적 디코딩을 위한 ** 압축 유한 상태 기계 같은 혁신을 특징으로 합니다.
성능 향상 ** : 벤치마크에서 SGLang은 작업 전반에 걸쳐 ** 가장 높은 처리량(1.0) 과 ** 가장 낮은 지연 시간(~0.2)** 을 지속적으로 달성합니다.
메모리 효율성 ** : ** 페이지 어텐션 및 KV 캐시 양자화와 같은 기술이 메모리 사용량을 줄여 긴 시퀀스와 복잡한 워크플로우에서 리소스 활용도를 향상시킵니다.
개발자 친화적 : Python에 내장된 SGLang은 생성, 병렬 처리, 다중 모달 데이터 처리를 위한 프리미티브를 제공하여 고급 LLM 프로그래밍을 단순화합니다.
유연한 통합 : 고급 프롬프팅, 제어 흐름, 구조화된 입출력과 같은 작업에 이상적이며, SGLang은 LLM 워크플로우를 간소화하고 효율성을 극대화합니다.
**고속 배포 ** : 최적의 성능을 위해 Novita AI GPU 인스턴스 를 사용하여 고속 환경에 SGLang을 배포하세요. 이 인스턴스는 NVIDIA A100 SXM 및 RTX 4090과 같은 GPU를 제공합니다.
대규모 언어 모델은 여러 생성 호출, 고급 프롬프팅, 제어 흐름, 구조화된 입출력을 포함하는 복잡한 작업에 점점 더 많이 사용되고 있습니다. 그러나 이러한 애플리케이션을 프로그래밍하고 실행하기 위한 기존 시스템은 종종 효율성이 부족합니다. SGLang은 간소화된 솔루션을 제공하여 이러한 한계를 극복하고자 하며, 간편한 프로그래밍을 위한 프론트엔드 언어와 가속화된 실행을 위해 최적화된 런타임을 갖추고 있습니다.
LLM 서비스의 과제
- 높은 메모리 사용량 : 최첨단 추론 엔진은 특히 KV 캐시에서 메모리 사용의 심각한 비효율을 초래할 수 있습니다. 재사용 가능한 중간 텐서를 저장하는 KV 캐시는 공유 프리픽스가 있는 여러 LLM 호출에서 효과적으로 재사용되지 않는 경우가 많아 메모리 낭비로 이어집니다.
- 제한된 처리량 : 기존 시스템은 구조화된 출력에 대한 제약 디코딩에서 여러 토큰을 함께 디코딩할 수 있는 경우에도 한 번에 하나의 토큰만 처리하여 최적 이하의 속도를 보입니다.
- 계산 비용 : 공통 프리픽스가 있는 여러 LLM 호출 간에 KV 캐시 재사용이 부족하여 중복 계산이 발생합니다.
SGLang 이해와 그 중요성
SGLang이란?
**SGLang 아키텍처 ** : 프론트엔드는 생성(예: extend , gen , select ) 및 병렬 처리 제어(예: fork , join )를 위한 프리미티브를 제공하여 사용자가 기본 Python 구문 내에서 원활하게 고급 프롬프팅 워크플로우를 만들 수 있도록 합니다. 런타임은 RadixAttention 을 통한 KV 캐시 재사용 및 더 빠른 구조화된 출력 디코딩을 위한 압축 유한 상태 기계와 같은 혁신적인 최적화를 통해 실행 효율성을 향상시킵니다. 이 두 구성 요소는 사용 사례에 따라 협력하거나 독립적으로 기능할 수 있습니다.
SGLang의 핵심 기술
**KV 캐시 관리 ** : SGLang의 핵심 혁신은 RadixAttention 으로, 런타임 중 KV 캐시의 자동적이고 체계적인 재사용을 가능하게 합니다. KV 캐시를 radix 트리로 구성함으로써 효율적인 프리픽스 검색, 재사용, 삽입 및 제거를 지원합니다. 이 접근 방식은 공유 프롬프트 프리픽스가 있는 요청이 KV 캐시를 재사용할 수 있도록 하여 중복 계산과 메모리 사용을 최소화합니다. 또한 캐시 인식 스케줄링 정책은 더 긴 일치 프리픽스가 있는 요청을 우선 처리하여 캐시 적중률을 크게 향상시킵니다.
출처: ARXIV
어텐션 알고리즘 및 PagedAttention : SGLang은 ** 페이지 어텐션** 과 같은 고급 최적화를 통합하여 비연속 메모리 페이지에서 KV 캐시를 관리함으로써 메모리 사용량을 줄입니다. RadixAttention이 여러 호출 간 KV 캐시 재사용을 극대화하는 데 초점을 맞추는 반면, 페이지 어텐션은 특히 긴 시퀀스를 처리할 때 개별 호출 내 메모리 효율성을 최적화합니다.
출처: ARXIV
SGLang 실행 효율성을 높이는 고속 방법
Novita AI GPU 인스턴스는 **클라우드 기반 솔루션 ** 으로, 고성능 컴퓨팅 파워를 제공하는 데 탁월합니다. NVIDIA A100 SXM 및 RTX 4090 과 같은 최첨단 GPU를 갖추고 있어 까다로운 작업에 이상적인 선택입니다.
이 서비스는 **PyTorch 사용자 ** 에게 특히 유용하며, 로컬 하드웨어에 대한 사전 투자 없이 GPU의 막대한 컴퓨팅 성능을 제공합니다. SGLang 또는 다른 GPU 집약적 애플리케이션에서 워크플로우를 개선하고 더 나은 성능을 달성할 수 있는 간편한 방법입니다.
Novita AI GPU 인스턴스 시작 방법
1단계: 계정 등록
Novita AI 웹사이트를 통해 계정을 만드세요. 등록 후 " [GPUs](https://novita.ai/gpus/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=NVIDIA RTX 4090 vs. RTX 6000 Ada: Choosing the Right GPU for Your Needs) " 탭으로 이동하여 사용 가능한 리소스를 확인하고 여정을 시작하세요.

2단계: 템플릿 및 GPU 서버 탐색
프로젝트 요구에 맞는 PyTorch, TensorFlow 또는 CUDA와 같은 템플릿을 선택하세요. 그런 다음 원하는 GPU 구성을 선택하십시오. 옵션에는 강력한 RTX 4090 또는 RTX 6000 Ada가 포함되며, 각각 다른 VRAM, RAM 및 스토리지 사양을 제공합니다.
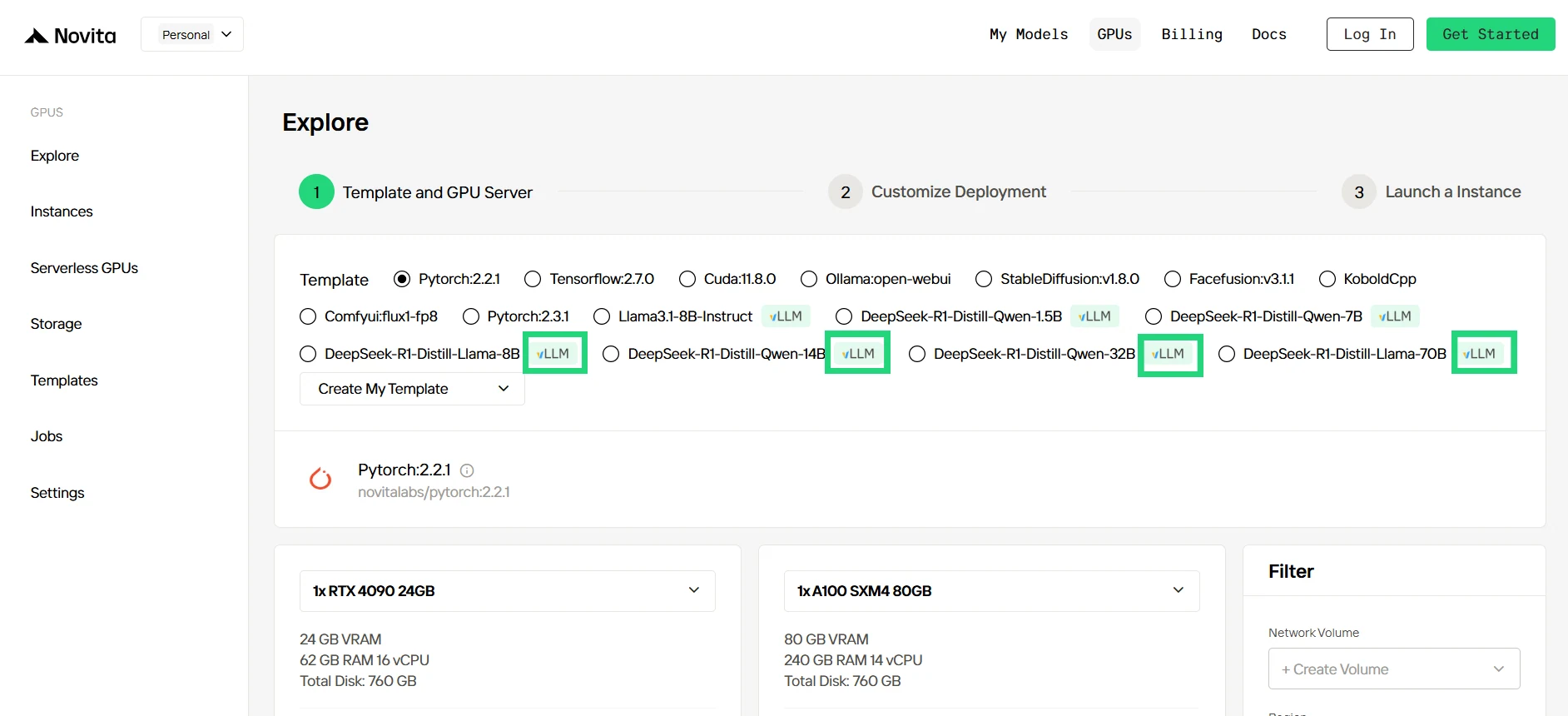
3단계: 배포 맞춤 설정
운영 체제 버전 및 기타 구성 설정과 같은 매개변수를 조정하여 특정 워크로드 요구 사항에 최적화된 배포를 미세 조정하세요.

4단계: 인스턴스 실행
"Launch Instance"를 클릭하여 구성된 환경을 배포하세요. 몇 분 안에 머신러닝, 렌더링 또는 계산 작업에 사용할 준비가 된 고성능 GPU 리소스에 액세스할 수 있습니다.

결론
SGLang 은 복잡한 언어 모델 프로그램의 효율적인 실행에 있어 주요한 돌파구를 의미합니다. 공동 설계된 ** 프론트엔드 언어 ** 와 고도로 최적화된 ** 백엔드 런타임 ** 을 결합함으로써 RadixAttention 및 ** 압축 유한 상태 기계 ** 와 같은 혁신적인 기술을 활용하여 기존 추론 시스템보다 ** 처리량 ** 과 ** 지연 시간 ** 모두에서 상당한 개선을 달성합니다. ** 유연성 ** , ** 광범위한 모델 지원 ** 및 ** 개발자 친화적인 통합** 을 통해 SGLang은 고급 LLM 애플리케이션을 구축하고 배포하는 데 매우 유용한 도구로 자리 잡으며, 워크플로우를 간소화하고 성능을 극대화합니다.
**SGLang이란 무엇인가요? **
SGLang(Structured Generation Language)은 대규모 언어 모델(LLM)과 상호작용하는 프로그램을 효율적으로 실행하도록 설계된 프로그래밍 언어 및 런타임입니다.
SGLang 배포의 첫 번째 단계는 무엇인가요?
SGLang을 설치하고 실행하는 첫 번째 단계는 고속 환경을 배포하는 것입니다. 훌륭한 방법이 있습니다 — Novita AI GPU 인스턴스 를 사용해보세요!
Novita AI 는 AI 비전을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 비용 효율적인 도구를 제공합니다. 인프라를 제거하고, 무료로 시작하여 AI 비전을 현실로 만드세요.
*추천 자료 *



