

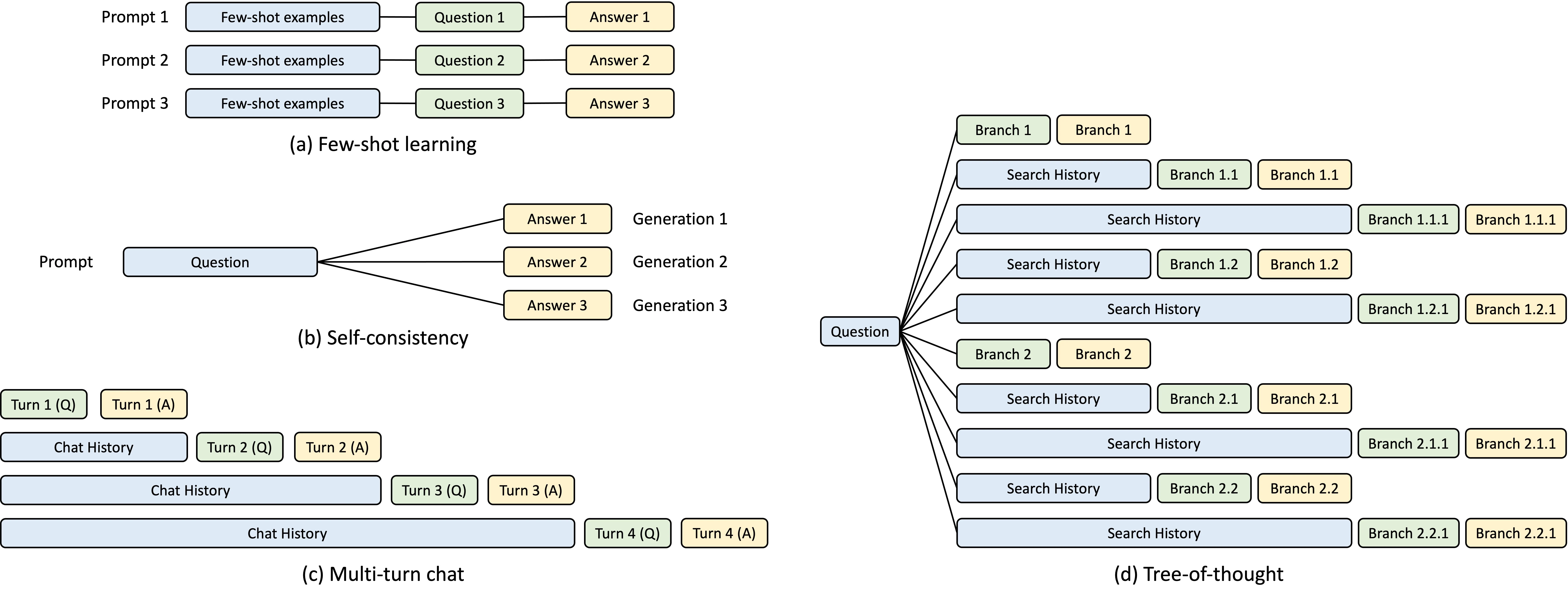
Key Highlights
Efficient Execution: SGLang combines a co-designed frontend language with an optimized backend runtime, featuring innovations like RadixAttention for KV cache reuse and compressed finite state machines for faster structured decoding.
Performance Boost: Benchmarks show SGLang consistently achieves the highest throughput (1.0) and lowest latency (~0.2) across tasks.
Memory Efficiency: Techniques like paged attention and KV cache quantization reduce memory usage, improving resource utilization for long sequences and complex workflows.
Developer-Friendly: Embedded in Python, SGLang offers primitives for generation, parallelism, and multi-modal data handling, simplifying advanced LLM programming.
Flexible Integration: Ideal for tasks like advanced prompting, control flow, and structured I/O, SGLang streamlines LLM workflows while maximizing efficiency.
High-Speed Deployment: For optimal performance, deploy SGLang in a high-speed environment using Novita AI GPU Instances, featuring GPUs like NVIDIA A100 SXM and RTX 4090.
Large language models are increasingly utilized for complex tasks that involve multiple generation calls, advanced prompting, control flow, and structured inputs/outputs. However, existing systems for programming and executing such applications often lack efficiency. sGLang seeks to overcome these limitations by providing a streamlined solution, featuring a frontend language for simplified programming and a runtime optimized for accelerated execution.
Challenges in Serving LLMs
- High Memory Footprint: State-of-the-art inference engines can lead to significant inefficiencies in memory usage, particularly with the Key-Value (KV) cache21 . The KV cache, which stores reusable intermediate tensors, is often not effectively reused across multiple LLM calls with shared prefixes, leading to wasted memory21 .
- Limited Throughput: Existing systems often process one token at a time during constrained decoding for structured outputs, even when multiple tokens could be decoded together, leading to suboptimal speeds21 …
- Computational Cost: Redundant computation arises from the lack of KV cache reuse across different LLM calls with common prefixes21 …
Understanding SGLang and Its Importance
What is SGLang?
SGLang Architecture: The frontend offers primitives for generation (e.g., extend, gen, select) and parallelism control (e.g., fork, join), enabling users to create advanced prompting workflows seamlessly within native Python syntax. The runtime enhances execution efficiency with innovative optimizations, including RadixAttention for KV cache reuse and compressed finite state machines for faster structured output decoding. These two components can function either collaboratively or independently, depending on the use case.
Core Technologies Behind SGLang
KV Cache Management: A core innovation in sGLang is RadixAttention, which enables automatic and systematic KV cache reuse during runtime. By organizing the KV cache in a radix tree, it supports efficient prefix search, reuse, insertion, and eviction. This approach minimizes redundant computation and memory usage by allowing requests with shared prompt prefixes to reuse the KV cache. Additionally, a cache-aware scheduling policy prioritizes requests with longer matched prefixes, significantly improving the cache hit rate.
From ARXIV
Attention Algorithm and PagedAttention: sGLang incorporates advanced optimizations such as paged attention, which reduces memory usage by managing the KV cache in non-contiguous memory pages. While RadixAttention focuses on maximizing KV cache reuse across multiple calls, paged attention optimizes memory efficiency within individual calls, especially for handling longer sequences.
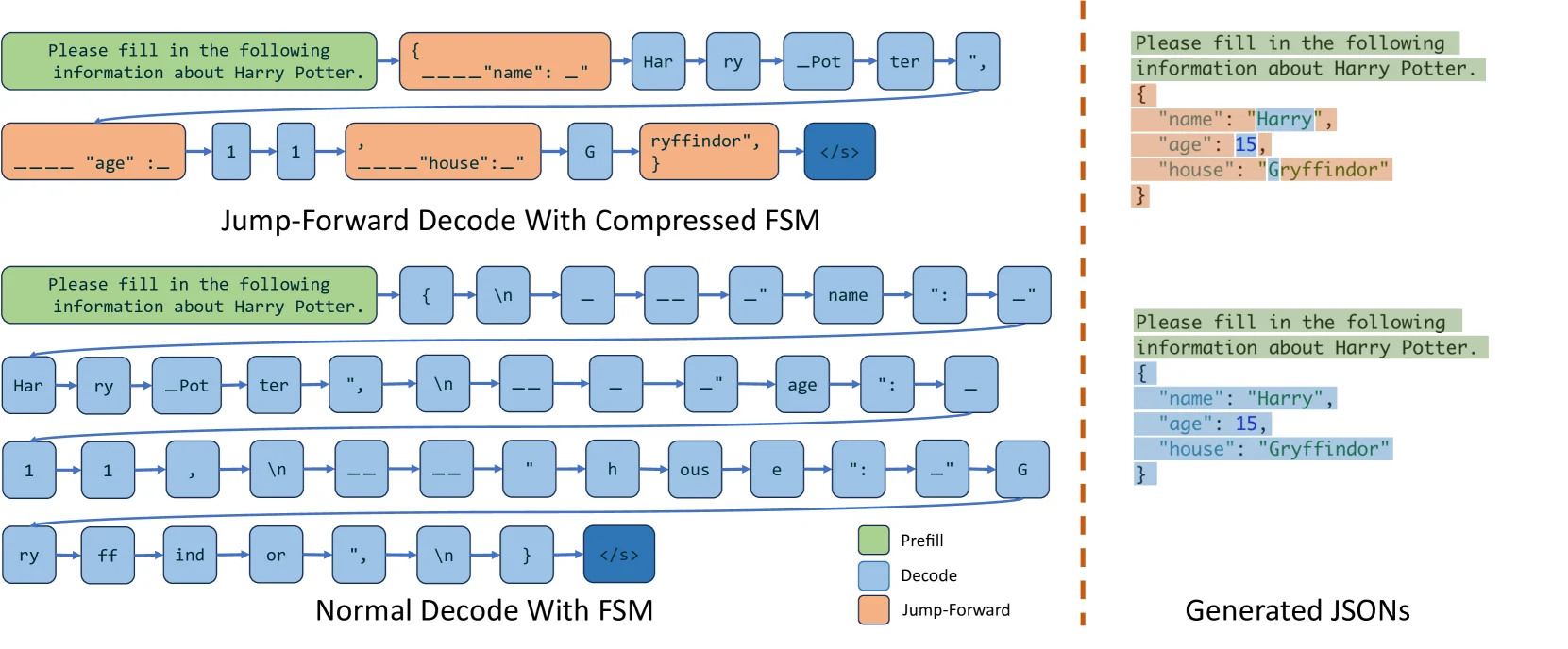
From ARXIV
A High-Speed Way to Enhance Your SGLang Running Efficiency
Novita AI GPU Instance is a cloud-based solution that excels in delivering high-performance computing power. It features cutting-edge GPUs such as the NVIDIA A100 SXM and RTX 4090, making it an ideal choice for demanding tasks.
This service is particularly advantageous for PyTorch users, offering the immense computational power of GPUs without requiring any upfront investment in local hardware. It’s a seamless way to enhance your workflow and achieve better performance with sGLang or other GPU-intensive applications.
How to start your journey in Novita AI GPU Instance
Step1:Register an account
Create your Novita AI account through our website. After registration, go to the “[GPUs](https://novita.ai/gpus/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=NVIDIA RTX 4090 vs. RTX 6000 Ada: Choosing the Right GPU for Your Needs)” tab to view available resources and begin your journey.

Try Novita AI’s High-Performance GPUs
Step2:Exploring Templates and GPU Servers
Choose from templates like PyTorch, TensorFlow, or CUDA that match your project needs. Then select your preferred GPU configuration—options include the powerful RTX 4090 or RTX 6000 Ada, each with different VRAM, RAM, and storage specifications.
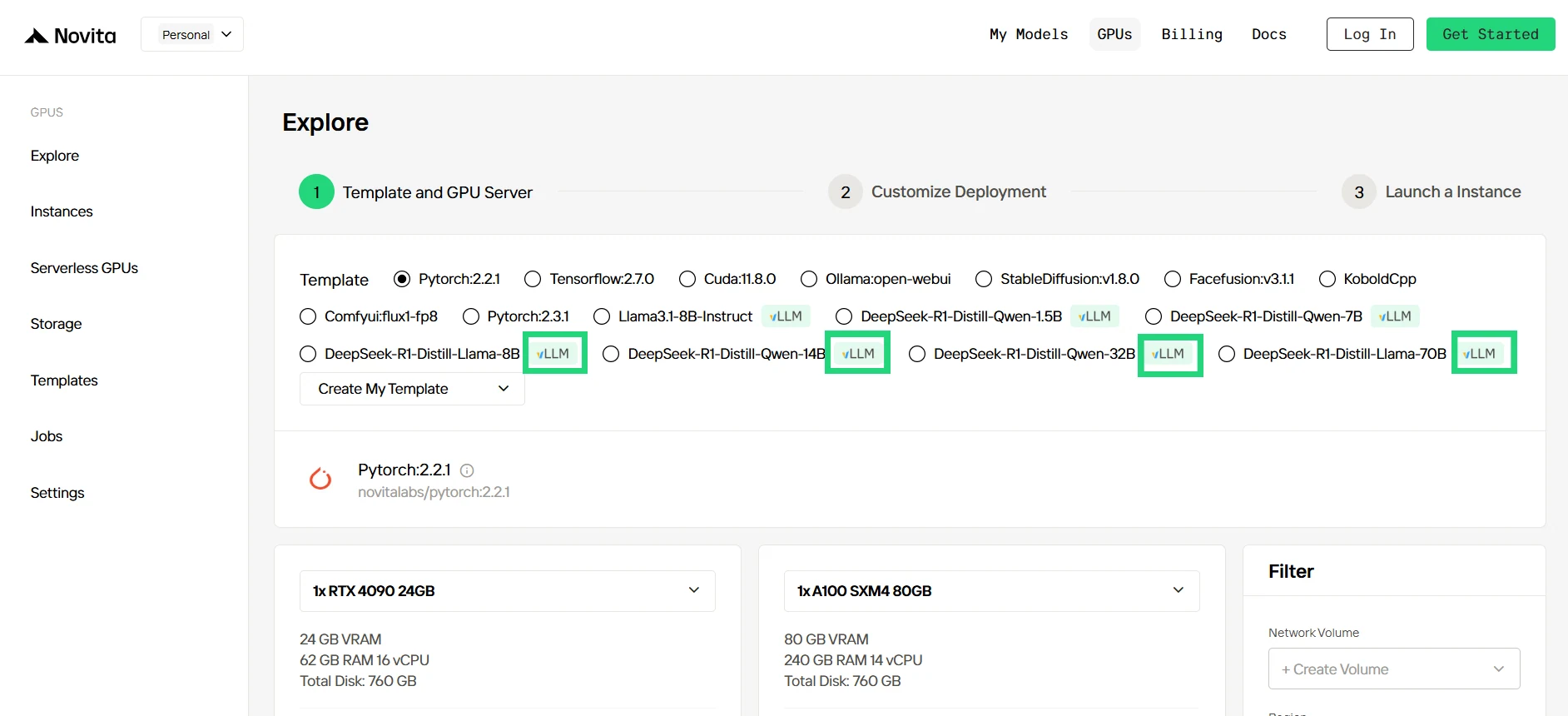
Step3:Tailor Your Deployment
Fine-tune your deployment by adjusting parameters such as operating system version and other configuration settings to optimize for your specific workload requirements.

Step4:Launch an instance
Click “Launch Instance” to deploy your configured environment. Within minutes, you’ll have access to high-performance GPU resources ready for your machine learning, rendering, or computational tasks.

Conclusion
SGLang marks a major breakthrough in the efficient execution of complex language model programs. By combining a co-designed frontend language with a highly optimized backend runtime, it leverages innovative techniques such as RadixAttention and compressed finite state machines to achieve significant improvements in both throughput and latency over existing inference systems. With its flexibility, broad model support, and developer-friendly integration, sGLang emerges as an invaluable tool for building and deploying advanced LLM applications, streamlining workflows and maximizing performance.
What is SGLang ?
SGLang (Structured Generation Language) is a programming language and runtime designed to efficiently execute programs that interact with Large Language Models (LLMs).
What is the first step to deploy SGLang?
The very first step of install and runSGLang is to deploy a high-speed environment. Here is an excellent way — — try Novita AI GPU Instance!
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommended reading



