

GLM 4.7은 추론, 지식 분석, 장문 콘텐츠 생성을 위해 설계된 고급 358B 매개변수 AI 모델입니다. 203K 토큰의 거대한 컨텍스트 윈도우, 특화된 “생각하기(thinking)” 모드, 정형 출력 지원을 통해 소형 모델이 어려워하는 복잡한 작업을 처리합니다. 값비싼 GPU 설정의 번거로움은 잊으세요. API 액세스를 통해 즉시 전체 성능을 활용하고 사용한 만큼만 비용을 지불하면 됩니다. 실시간 채팅, 다단계 추론, 대규모 문서 처리가 필요하든 GLM 4.7이 가능하게 합니다.
GLM 4.7 모델 개요
| 사양 | 값 |
|---|---|
| 전체 매개변수 | 3583억 (순방향 패스당 320억 활성) |
| 아키텍처 | GLM 4 MoE Transformer (160 라우팅 + 1 공유 전문가, 토큰당 8 활성) |
| 컨텍스트 윈도우 | 202,752 토큰 |
| 최대 출력 토큰 | 128K–131K (제공업체별 상이) |
| 정밀도 | bfloat16 (FP8 변형 사용 가능) |
| 라이선스 | MIT |
| 특수 기능 | 인터리브(Interleaved)/보존(Preserved)/턴 수준(Turn-level) 생각하기 모드, 함수 호출, 정형 출력 |
GLM 4.7의 벤치마크 성능
| 벤치마크 | GLM 4.7 | Claude Sonnet 4.5 | GPT-5-High | DeepSeek V3.2 |
|---|---|---|---|---|
| MMLU-Pro | 84.3 | 88.2 | 87.5 | 85.0 |
| GPQA-Diamond | 85.7 | 83.4 | 85.7 | 82.4 |
| AIME 2025 | 95.7 | 87.0 | 94.6 | 93.1 |
| LiveCodeBench-v6 | 84.9 | 64.0 | 87.0 | 83.3 |
| SWE-bench Verified | 73.8 | 77.2 | 74.9 | 73.1 |
| Terminal Bench 2.0 | 41.0 | 42.8 | 35.2 | 46.4 |
| τ²-Bench (도구 사용) | 87.4 | 87.2 | 82.4 | 85.3 |
GLM 4.7은 일반 지식, 추론, 수학 벤치마크에서 강력하고 일관된 성능을 보여주며, 특히 AIME 2025 및 LiveCodeBench-v6와 같은 작업에서 높은 점수를 기록합니다. 반면 도구 사용 및 소프트웨어 엔지니어링 벤치마크(Terminal Bench 2.0, SWE-bench)에서는 상대적으로 낮은 결과를 보입니다. 이는 GLM 4.7이 복잡한 질문 응답이나 데이터 분석과 같은 추론 집약적이고 지식 기반 애플리케이션에 가장 적합하지만, 직접적인 코드 실행이나 소프트웨어 도구 상호작용이 필요한 작업에는 덜 최적일 수 있음을 시사합니다.
GLM 4.7에 API 액세스가 중요한 이유는?
358B MoE 모델을 자체 호스팅하려면 상당한 GPU 메모리가 필요합니다. 토큰당 활성화되는 매개변수 수와 관계없이 전체 가중치 세트가 추론 시 VRAM에 적재되어야 합니다. 아래 표는 각 양자화 수준별 하드웨어 요구 사항을 보여줍니다.
| 양자화 | 필요 VRAM | 최소 H100 80GB |
|---|---|---|
| BF16 (전체 정밀도) | 717 GB | 9× H100 |
| FP8 / Q8_0 | 381 GB | 5× H100 |
| Q4_K_M | 216 GB | 3× H100 |
| Q3_K_M | 171 GB | 3× H100 |
| Q2_K | 131 GB | 2× H100 |
GLM 4.7을 자체 호스팅하려면 매우 고가의 GPU가 필요합니다. 최소 배포에 2×H100, 프로덕션 수준 FP8 사용 시 5×H100이 필요하여 인프라 비용이 높습니다. API를 사용하면 이러한 고정 비용을 피하고 실제 사용량에 대해서만 비용을 지불하므로 중간 규모 워크로드에 훨씬 비용 효율적입니다.
GLM 4.7 API 제공업체를 선택하는 방법은?
API 제공업체 선택은 5가지 메트릭에 달려 있습니다: 최대 출력 토큰, 입력/출력 가격, 지연 시간(첫 번째 토큰까지의 시간), 처리량(초당 토큰 수), 컨텍스트 윈도우 지원. 아래 표는 각 메트릭의 정의와 다양한 사용 사례에 미치는 영향을 설명합니다.
| 메트릭 | 정의 | 중요성 |
|---|---|---|
| 최대 출력 토큰 | 모델이 단일 응답에서 생성할 수 있는 최대 토큰 수 | 장문 콘텐츠 생성(문서, 보고서, 코드 리팩토링)을 제한합니다. |
| 입력 비용 | 1M 입력 토큰(프롬프트 + 컨텍스트) 당 가격 | 긴 컨텍스트 사용 사례(리포지토리 분석, 다중 파일 코드 리뷰)에서 비용을 지배합니다. |
| 출력 비용 | 1M 출력 토큰(생성된 응답) 당 가격 | 높은 출력 시나리오(코드 생성, 콘텐츠 제작)에서 비용을 결정합니다. |
| 캐시 읽기 | 재사용된 캐시 프롬프트 접두사에 대한 할인된 요금 | 반복되는 시스템 프롬프트 및 긴 컨텍스트 재사용 비용을 절감합니다. |
| 지연 시간 (TTFT) | 첫 번째 토큰까지의 시간(초) | 실시간 채팅 및 대화형 UI에 중요합니다. <0.7초는 즉각적으로 느껴지고, >2초는 사용자 이탈을 유발합니다. |
| 처리량 | 스트리밍 중 초당 생성되는 토큰 수 | 긴 출력의 체감 속도에 영향을 미칩니다. |
핵심 요약: 긴 컨텍스트 워크플로(리포지토리 분석, 문서 처리)는 입력 비용과 컨텍스트 윈도우 지원에 최적화합니다. 높은 출력 시나리오(코드 생성, 콘텐츠 제작)는 출력 비용과 처리량을 우선시합니다. 실시간 애플리케이션(채팅, 코딩 어시스턴트)은 무엇보다 1초 미만의 TTFT가 필요합니다. 동일한 긴 시스템 프롬프트를 많은 요청에 걸쳐 재사용할 때 캐시 읽기 가격이 중요해집니다.
GLM 4.7 API 제공업체 비교
각 GLM 4.7 제공업체는 뚜렷한 강점을 가지고 있습니다.
- Novita AI는 낮은 캐시 비용과 빠른 지연 시간을 제공하여 대화형 애플리케이션에 이상적입니다.
- SiliconFlow는 가장 긴 컨텍스트 윈도우와 높은 토큰 용량을 지원하여 장문 문서 처리나 대규모 코드베이스에 적합합니다.
- **Z.ai (공식)**은 공식 채널을 통해 안정적이고 신뢰할 수 있는 성능을 제공합니다.
- Atlas Cloud는 가장 낮은 출력 비용과 균형 잡힌 컨텍스트 제한을 제공하여 콘텐츠나 코드 생성과 같은 높은 출력 시나리오에 비용 효율적입니다.
Novita AI: 빠르고, 비용 효율적이며, 높은 처리량
옵션 A: Playground 사용하기
GLM 4.7을 알아보는 가장 쉬운 방법은 Novita AI Playground에서 직접 사용해보는 것입니다. Novita AI Playground에서 GLM 4.7을 즉시 사용할 수 있습니다. 설정도, 코드도 필요 없습니다. 가입하고 Playground를 열어 실시간으로 프롬프트를 테스트하세요. 신규 계정은 등록 후 무료 크레딧을 받으므로 바로 모델을 사용해볼 수 있습니다.
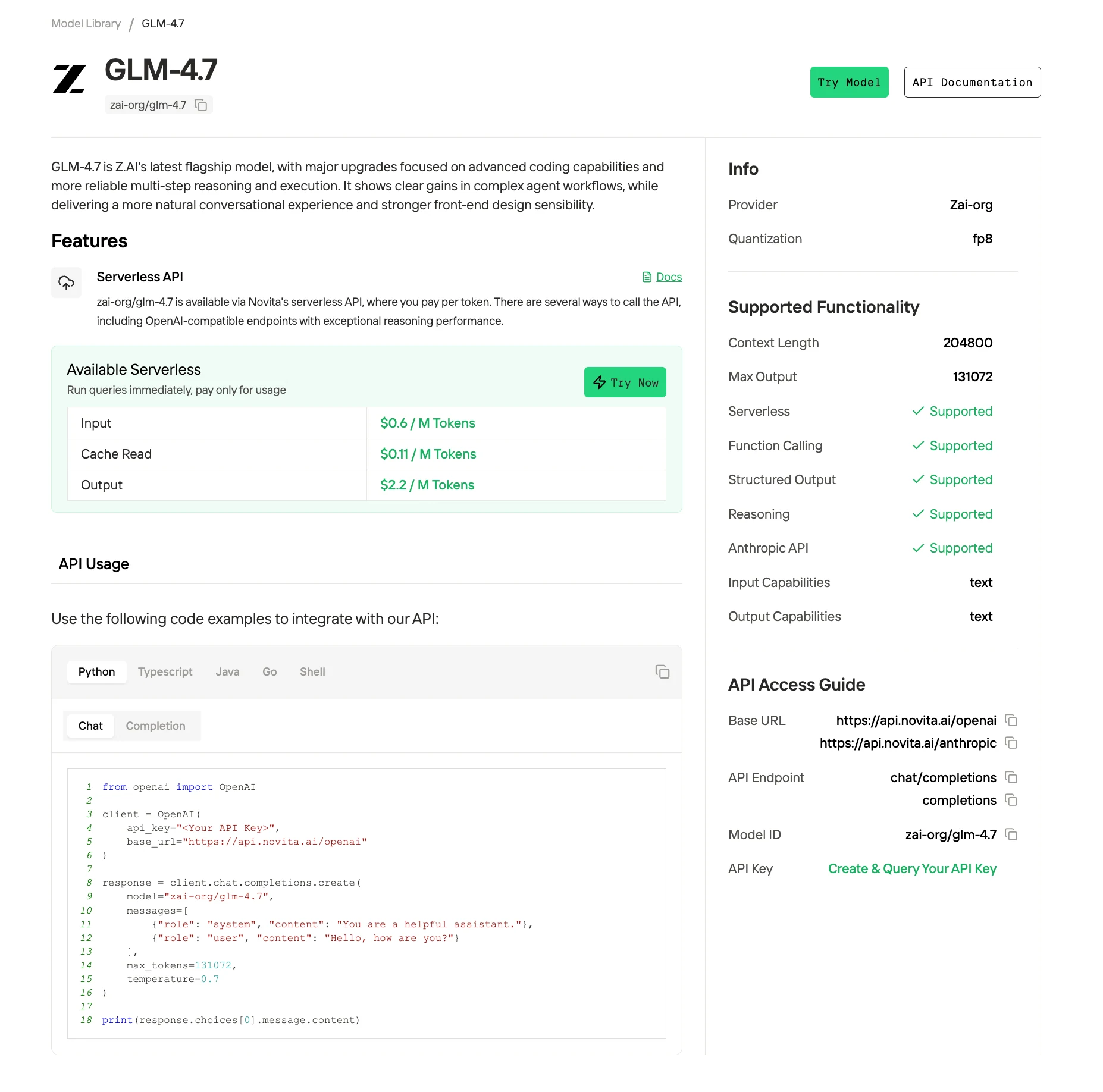
옵션 B: API로 통합하기
Novita AI의 통합 REST API를 사용하여 GLM 4.7을 애플리케이션에 연결하세요.
Novita AI에서 API 키 받기
1단계: 계정 생성 또는 로그인
[https://novita.ai](https://novita.ai)를 방문하여 가입하거나 기존 계정으로 로그인하세요.
2단계: 키 관리로 이동
로그인 후 "API Keys"를 찾으세요.
3단계: 새 키 생성
“Add New Key” 버튼을 클릭하세요.
4단계: 키 즉시 저장
키가 생성되면 즉시 복사하여 저장하세요. 일반적으로 한 번만 표시되며 이후에는 다시 확인할 수 없습니다. 비밀번호 관리자나 암호화된 노트와 같은 안전한 위치에 키를 보관하세요.
직접 API 통합
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
OpenAI Agents SDK를 사용한 멀티 에이전트 워크플로
복잡한 에이전트 시스템을 플러그 앤 플레이 방식으로 구축하세요. 핸드오프, 라우팅, 기본 함수 호출을 통한 도구 사용, 그리고 복잡한 다단계 작업을 위한 전체 긴 컨텍스트 윈도우를 지원합니다.
옵션 C: 타사 플랫폼 연동
이미 에이전트 프레임워크나 개발자 도구로 구축 중이라면 Novita AI는 최소한의 마찰로 연결되도록 설계되었습니다.
- 에이전트 프레임워크 및 앱 빌더: Novita의 단계별 통합 가이드를 따라 Continue, AnythingLLM, LangChain, Langflow 와 같은 인기 도구에 연결하세요.
- Hugging Face Hub: Novita는 Hugging Face에 추론 제공업체(Inference Provider) 로 등록되어 있으므로 Hugging Face의 제공업체 워크플로와 생태계를 통해 지원되는 모델을 실행할 수 있습니다.
- OpenAI 호환 API: Novita의 LLM 엔드포인트는 OpenAI API 표준과 호환되므로 기존 OpenAI 스타일 앱을 쉽게 마이그레이션하고 많은 OpenAI 호환 도구(Cline, Cursor, Trae, Qwen Code)에 연결할 수 있습니다.
- Anthropic 호환 API (Claude Code 워크플로): Novita는 Anthropic SDK 호환 액세스도 제공하므로 Novita 지원 모델을 Claude Code 스타일 에이전트 코딩 워크플로에 통합할 수 있습니다.
- OpenCode (내장 제공업체): Novita AI는 이제 OpenCode에 지원 제공업체로 직접 통합되어 사용자가 별도 설정 없이 OpenCode에서 Novita를 선택할 수 있습니다.
SiliconFlow: 초장문 컨텍스트, 최대 처리량
SiliconFlow는 GLM 4.7을 포함한 많은 타사 LLM을 호스팅하는 클라우드 제공업체로, 긴 컨텍스트와 높은 처리량에 중점을 둡니다. 대규모 문서 처리, 긴 코드베이스, 또는 많은 병렬 요청을 효율적으로 처리해야 하는 워크로드에 적합합니다.
Z.AI (공식): 완전한 기능 세트와 공식 신뢰성
Z.AI (공식)은 GLM 제품군의 홈 플랫폼이며 공식 API를 통해 GLM 4.7을 제공합니다. 주요 업스트림 제공업체이므로 일반적으로 가장 완전한 기능 세트(고급 추론 및 코딩 기능, 새로운 모드나 ‘생각하기’ 기능에 대한 조기 액세스 포함)를 제공합니다. 모델 품질, 안정성, 최신 GLM 릴리스와의 일치를 중시하는 프로덕션 사용 사례를 대상으로 합니다.
Atlas Cloud: 낮은 출력 비용과 균형 잡힌 성능
Atlas Cloud는 GLM 4.7 제공을 비용 효율적이고 균형 잡힌 선택으로 포지셔닝한 다중 모델 추론 플랫폼입니다. 경쟁력 있는 지연 시간, 컨텍스트 길이, 처리량을 유지하면서 낮은 출력 토큰 가격을 강조하므로 대량 콘텐츠 또는 코드 생성 워크로드에 매력적입니다.
결론
제공업체별 장점을 활용하면 GLM 4.7 배포가 그 어느 때보다 쉬워졌습니다.
- Novita AI: 빠르고, 비용 효율적이며, 처리량이 높아 대화형 앱에 완벽합니다.
- SiliconFlow: 초장문 컨텍스트와 최대 처리량으로 대규모 문서나 코드베이스에 적합합니다.
- Z.ai (공식): 완전한 기능 세트와 공식 신뢰성으로 프로덕션 준비 배포에 적합합니다.
- Atlas Cloud: 낮은 출력 비용과 균형 잡힌 성능으로 대량 워크로드에 적합합니다.
올바른 API 선택을 통해 개발자는 GLM 4.7의 전체 잠재력을 활용하여 더 스마트한 애플리케이션을 구축하고, 워크플로를 가속화하며, 인프라 오버헤드 없이 대규모로 결과를 제공할 수 있습니다.
자주 묻는 질문
대화형 애플리케이션에 가장 적합한 GLM 4.7 API 제공업체는 무엇인가요?
실시간 채팅, 코딩 어시스턴트 또는 다단계 에이전트 워크플로의 경우 Novita AI 는 가장 낮은 지연 시간과 높은 처리량을 제공하여 비용을 관리하면서 상호작용을 즉각적으로 느끼게 합니다.
기존 앱에 GLM 4.7을 쉽게 통합할 수 있나요?
물론입니다. Novita AI 는 OpenAI API와 함께 LangChain, Langflow, 에이전트 SDK와 같은 인기 프레임워크를 위한 가이드를 제공하므로 코드를 다시 작성하지 않고도 GLM 4.7을 연결할 수 있습니다.
Novita AI 는 개발자와 스타트업이 높은 성능, 안정성, 비용 효율성으로 모델 및 에이전트 애플리케이션을 구축, 배포, 확장할 수 있도록 지원하는 AI 및 에이전트 클라우드 플랫폼입니다.
추천 자료



