

Le révolutionnaire Qwen3-235B-A22B-Thinking-2507 d’Alibaba est désormais disponible sur Novita AI.
Ce modèle de raisonnement surpasse OpenAI O4-mini, Claude4 Opus et d’autres leaders du secteur sur les benchmarks de raisonnement, pour une fraction du coût. Avec 92,3 % sur AIME25 et un support natif du contexte 256K, il établit de nouveaux standards pour la résolution de problèmes complexes. Le modèle dispose de 235B paramètres (22B activés) avec des capacités de raisonnement améliorées pour les mathématiques, le codage et les tâches analytiques.
Tarifs actuels sur Novita AI : Contexte 131072, 0,3 $/M tokens d’entrée, 3 $/M tokens de sortie.
Essayez la démo 235B-A22B-Thinking-2507
Qu’est-ce que Qwen3-235B-A22B-Thinking-2507 ?
Qwen3-235B-A22B-Thinking-2507 est une version améliorée du modèle phare d’Alibaba à 235B paramètres, spécialisée dans le raisonnement. Après trois mois d’optimisation continue, ce modèle offre des améliorations significatives en profondeur de raisonnement, résolution de problèmes mathématiques et tâches analytiques complexes.
Le modèle s’appuie sur l’architecture Qwen3-235B-A22B avec des améliorations spécifiques pour les capacités de raisonnement. Il obtient des résultats de pointe parmi les modèles de raisonnement open-source sur les benchmarks académiques.
Améliorations révolutionnaires
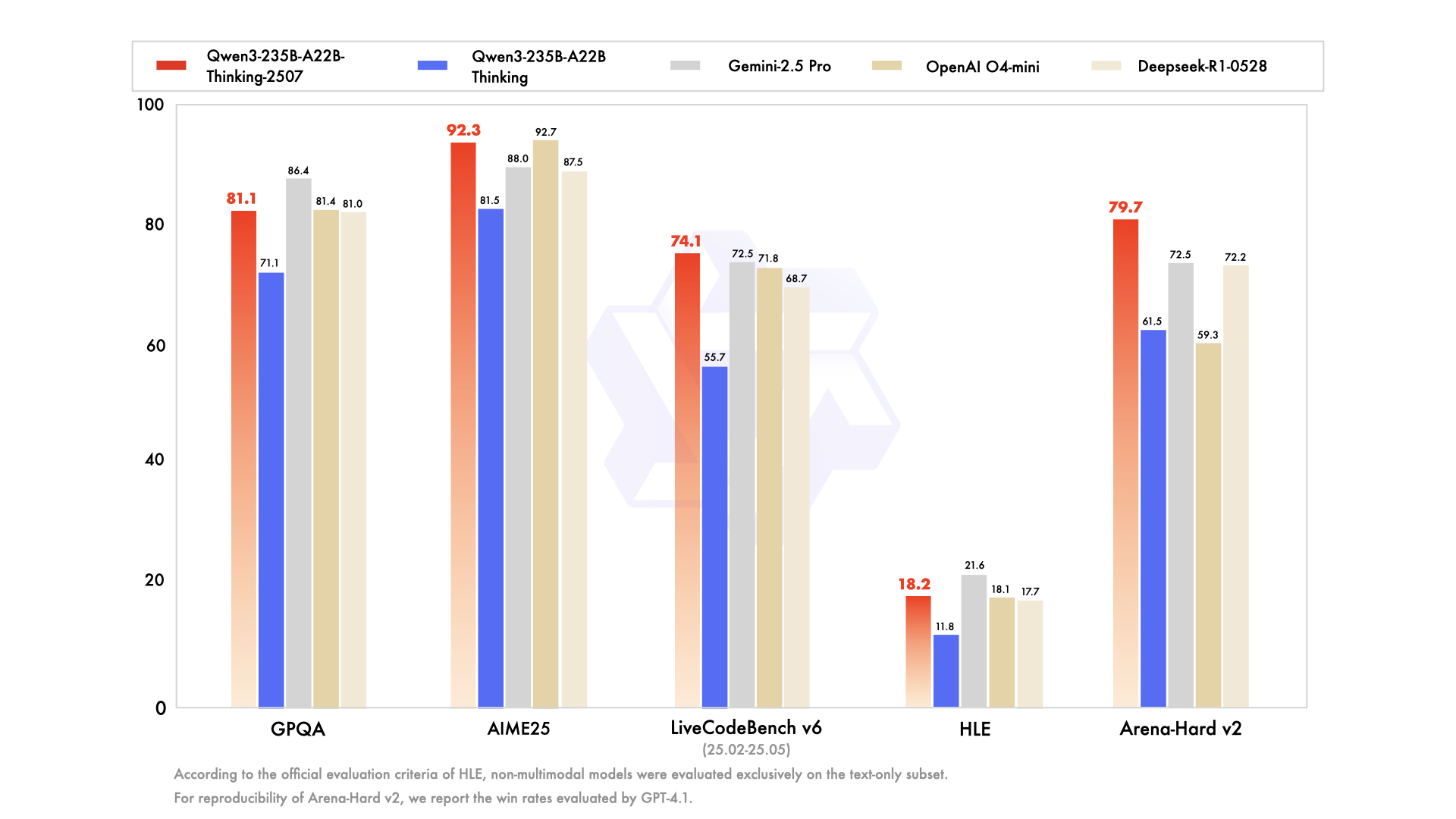
Améliorations spectaculaires du raisonnement
Progrès fulgurants en logique, mathématiques, sciences et codage. Le modèle excelle dans les benchmarks académiques qui exigent habituellement une expertise humaine.
Capacités générales renforcées
Meilleur suivi des instructions, utilisation d’outils et génération de texte. Alignement amélioré avec les préférences humaines tout en maintenant des processus de réflexion structurés.
Maîtrise du contexte étendu
La compréhension du long contexte (256K) maintient une parfaite cohérence à travers des documents entiers, des articles de recherche et des chaînes de raisonnement étendues.
Remarque : Il est fortement recommandé d’utiliser les capacités de réflexion étendues pour les tâches de raisonnement très complexes nécessitant un traitement analytique approfondi.
Principales fonctionnalités et capacités
Spécifications techniques
- Type : Modèles de langage causaux
- Phase d’entraînement : Pré-entraînement et post-entraînement
- Paramètres totaux : 235B avec 22B activés
- Nombre de paramètres (hors embeddings) : 234B
- Architecture : 94 couches
- Têtes d’attention (GQA) : 64 pour Q et 4 pour KV
- Experts : 128 au total avec 8 activés
- Longueur de contexte : 262 144 tokens nativement
- Mode : Mode raisonnement uniquement (insertion automatique de la balise
<think>)
Résultats des benchmarks
Qwen3-235B-A22B-Thinking-2507 ne se contente pas de rivaliser avec les leaders du secteur : il les domine. Ce modèle de raisonnement surpasse systématiquement les modèles premium sur l’ensemble des benchmarks d’évaluation.
Résultats complets des performances
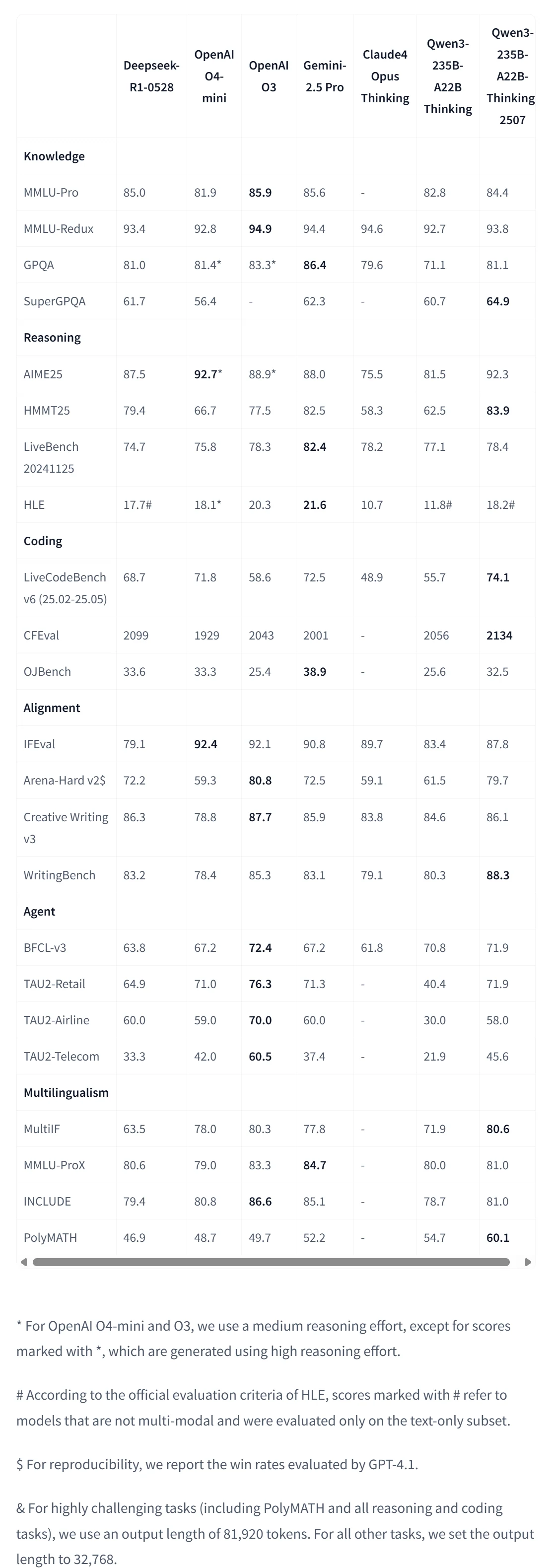
Source : Page Hugging Face officielle de Qwen
Faits marquants des performances
Excellence en mathématiques
Obtient 92,3 % sur AIME25, égalant OpenAI O4-mini (92,7 %) et surpassant tous les autres modèles. Score de 83,9 % sur HMMT25, dépassant Gemini-2.5 Pro (82,5 %) et nettement meilleur que Claude4 Opus Thinking (58,3 %).
Compréhension supérieure des connaissances
Atteint 81,1 % sur GPQA, au niveau de Deepseek-R1 et OpenAI O4-mini. Obtient un score de 64,9 % sur SuperGPQA, surpassant tous les concurrents, y compris Gemini-2.5 Pro (62,3 %).
Leader en codage
Domine avec 74,1 % sur LiveCodeBench v6, surpassant tous les modèles, y compris Gemini-2.5 Pro (72,5 %) et OpenAI O4-mini (71,8 %). Obtient le score CFEval le plus élevé (2134) parmi tous les modèles évalués.
Maîtrise du raisonnement
Score de 78,4 % sur LiveBench, compétitif avec les meilleurs modèles. Atteint 18,2 % sur HLE (sous-ensemble texte uniquement), se rapprochant d’OpenAI O4-mini (18,1 %) et dépassant la version précédente de Qwen3 (11,8 %).
Alignement des préférences utilisateur
Obtient 79,7 % sur Arena-Hard v2, juste derrière OpenAI O3 (80,8 %) et surpassant Deepseek-R1 (72,2 %). Score le plus élevé sur WritingBench avec 88,3 %, dépassant tous les concurrents.
Excellence multilingue
Leader avec 80,6 % sur MultiIF, surpassant la plupart des modèles à l’exception d’OpenAI O3 (80,3 %). Réalise une percée avec 60,1 % sur PolyMATH, nettement supérieur à tous les concurrents, y compris Gemini-2.5 Pro (52,2 %).
Comment accéder à Qwen3-235B-A22B-Thinking-2507 sur Novita AI
Commencer avec Qwen3-235B-A22B-Thinking-2507 sur Novita AI est simple pour les développeurs et les chercheurs.
Utilisez le Playground (sans codage requis)
Accès instantané : Inscrivez-vous et commencez à expérimenter avec Qwen3-235B-A22B-Thinking-2507 en quelques secondes.
Interface interactive : Testez des invites de raisonnement complexes et visualisez les résultats structurés en temps réel.
Comparaison de modèles : Comparez Qwen3-235B-A22B-Thinking-2507 avec d’autres modèles leaders pour votre cas d’utilisation spécifique.
Intégration via l’API (pour les développeurs)
Connectez Qwen3-235B-A22B-Thinking-2507 à vos applications grâce à l’API REST unifiée de Novita AI.
Option 1 : Intégration API directe (exemple Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_CnjsV-lI2tqhCbXYRCfnfGoFieN4Ubn2A-5n07_AE0vOcfoffz0egjxrlijiCdtsOlBLaPuCbLNhDmP3naR3Dg==",
)
model = "qwen/qwen3-235b-a22b-thinking-2507"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Fonctionnalités clés :
- API compatible OpenAI pour une intégration transparente
- Contrôle flexible des paramètres pour un réglage fin
- Support du streaming pour des réponses en temps réel
Option 2 : Workflows multi-agents avec OpenAI Agents SDK
Construisez des systèmes multi-agents sophistiqués en utilisant Qwen3-235B-A22B-Instruct-2507 :
- Intégration plug-and-play : Utilisez les modèles de Novita AI dans n’importe quel workflow OpenAI Agents
- Capacités d’agent avancées : Prise en charge des transferts, du routage et de l’intégration d’outils
- Architecture évolutive : Concevez des agents capables de déléguer des tâches et d’exécuter des fonctions complexes
Connectez-vous à des plateformes tierces
Outils de développement : Intégrez-vous facilement aux IDE et environnements de développement populaires comme Cursor, Trae et Cline via des APIs compatibles OpenAI.
Frameworks d’orchestration : Connectez-vous à LangChain, Dify, Langflow et d’autres plateformes d’orchestration IA à l’aide de connecteurs officiels.
Intégration Hugging Face : Utilisez Qwen3-235B-A22B-Instruct-2507 dans Spaces, pipelines ou avec la bibliothèque Transformers via les endpoints Novita AI.
Bonnes pratiques pour des performances optimales
Suivez ces recommandations officielles de l’équipe Qwen pour des performances optimales.
Paramètres d’échantillonnage recommandés
- Temperature : 0,6
- TopP : 0,95
- TopK : 20
- MinP : 0
Ajustez presence_penalty entre 0 et 2 pour réduire les répétitions. Des valeurs plus élevées peuvent occasionnellement provoquer un mélange de langues.
Directives pour la longueur de sortie
- Requêtes standard : 32 768 tokens
- Problèmes complexes : 81 920 tokens pour les compétitions de mathématiques et de programmation
- Un espace suffisant garantit des processus de réflexion détaillés et des réponses complètes
Standardisez le format de sortie
- Problèmes mathématiques : Ajoutez « Please reason step by step, and put your final answer within \boxed{}. »
- Choix multiples : Incluez une structure JSON : « Please show your choice in the
answerfield with only the choice letter, e.g., “answer”: “C”. »
Conversations à plusieurs tours
Les sorties historiques doivent exclure le contenu de réflexion. Seules les réponses finales doivent figurer dans l’historique de la conversation. Le modèle de chat Jinja2 gère cela automatiquement.
Conclusion
Qwen3-235B-A22B-Thinking-2507 prouve qu’une IA open-source peut égaler les modèles de raisonnement commerciaux. Avec 92,3 % sur AIME25 et 74,1 % sur LiveCodeBench, il rivalise avec OpenAI O4-mini et Claude4 Opus pour une fraction du coût. La fenêtre de contexte de 256K et l’architecture de raisonnement améliorée excellent dans les tâches complexes. À 0,15 $/M tokens d’entrée sur Novita AI, il démocratise l’accès à un raisonnement IA de pointe.
Essayez Qwen3-235B-A22B-Thinking-2507 sur Novita AI dès aujourd’hui.
Novita AI est une plateforme cloud IA qui permet aux développeurs de déployer facilement des modèles d’IA via notre API simple, tout en offrant un cloud GPU abordable et fiable pour construire et passer à l’échelle.



