

- Llama 4 Maverick vs DeepSeek V3 0324 : Présentation
- Llama 4 Maverick vs DeepSeek V3 0324 : Benchmarks
- Llama 4 Maverick vs DeepSeek V3 0324 : Comparaison de vitesse
- Llama 4 Maverick vs DeepSeek V3 0324 : Configuration matérielle requise
- Llama 4 Maverick vs DeepSeek V3 0324 : Applications
- Llama 4 Maverick vs DeepSeek V3 0324 : Exemples de tâches
- Comment accéder à Llama 4 Maverick et DeepSeek V3 0324 via l’API Novita ?
Points clés
Llama 4 Maverick est robuste, modulaire et particulièrement performant pour les tâches nécessitant une logique claire et un long contexte.
DeepSeek V3 0324 est très efficace pour le code et les questions-réponses générales, excellent en compacité et en économie de ressources.
Novita AI propose non seulement des services API stables, mais aussi des tarifs extrêmement compétitifs. Par exemple, llama-4-maverick coûte seulement 0,17 $ pour 1 million de tokens en entrée et 0,85 $ pour 1 million de tokens en sortie, tandis que deepseek-v3-0324 coûte 0,33 $ pour 1M tokens en entrée et 1,3 $ pour 1M tokens en sortie.
Llama 4 Maverick vs DeepSeek V3 0324 : Présentation
Llama 4 Maverick

DeepSeek V3 0324
Llama 4 Maverick vs DeepSeek V3 0324 : Benchmarks
| Catégorie | Llama 4 Maverick | DeepSeek V3 | DeepSeek V3 0324 | Qwen-Max | GPT-4.5 | Claude-Sonnet-3.7 |
|---|---|---|---|---|---|---|
| MMLU-Pro | 80,5 % | 75,9 % | 81,2 % | 76,1 % | 86,1 % | 80,7 % |
| GPQA Diamond | 69,8 % | 59,1 % | 68,4 % | 60,1 % | 71,4 % | 68,0 % |
| LiveCodeBench | 43,4 % | 39,2 % | 49,2 % | 38,7 % | 44,4 % | 42,2 % |
- Llama 4 Maverick a un léger avantage dans les questions-réponses de haute qualité.
- DeepSeek V3 0324 est supérieur en connaissances générales et surtout en tâches de codage.
- La différence en connaissances générales (MMLU-Pro) est minime, les deux sont donc quasiment équivalents dans ce domaine.
Llama 4 Maverick vs DeepSeek V3 0324 : Comparaison de vitesse
Si vous souhaitez tester par vous-même, vous pouvez commencer un essai gratuit sur le site de Novita AI.

Essayez dès maintenant la démo de Llama 4 Maverick et DeepSeek V3 0324 !
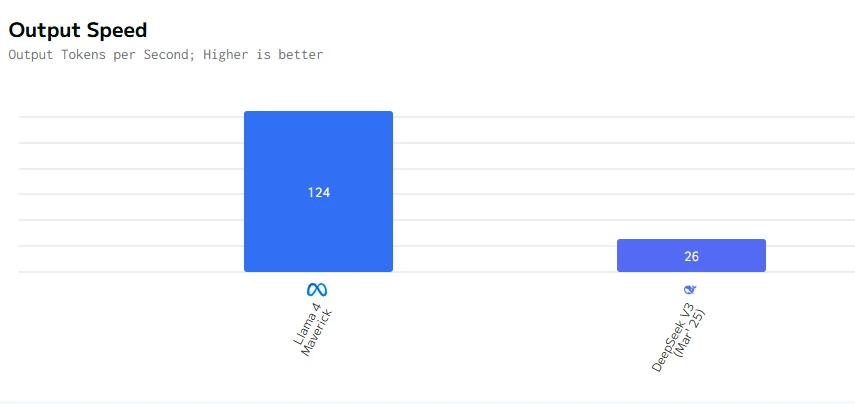
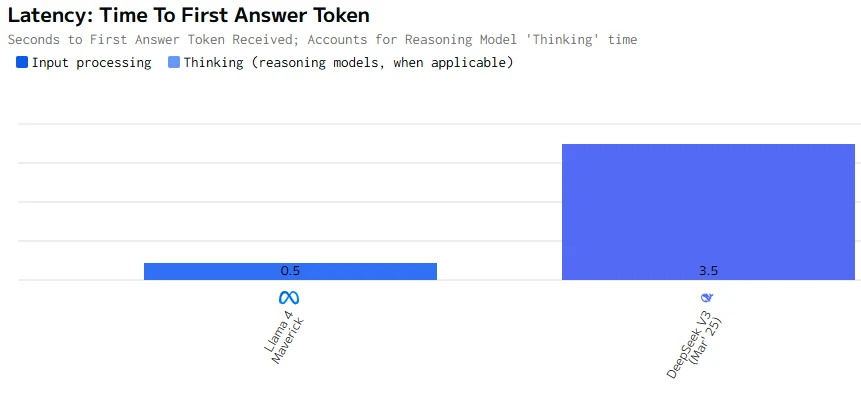
Llama 4 Maverick est beaucoup plus rapide, à la fois en vitesse de sortie et en latence du premier token, comparé à DeepSeek V3 0324. Pour les scénarios interactifs ou sensibles à la vitesse, Llama 4 Maverick est le grand gagnant.
Llama 4 Maverick vs DeepSeek V3 0324 : Configuration matérielle requise
| Modèle | Mémoire estimée nécessaire | Configuration GPU | Mémoire GPU totale |
|---|---|---|---|
| DeepSeek V3 0324 | ~1532 Go | 24 × H100 (80 Go) | 1920 Go |
| Llama 4 Maverick | ~18,8 To | 240 × H100 (80 Go) | 19200 Go |
Le DeepSeek V3 0324 standard nécessite beaucoup moins de ressources GPU que Llama 4 Maverick avec une fenêtre de contexte de 10 millions de tokens. Les modèles à très long contexte (comme Llama 4 Maverick à 10M tokens) exigent une mémoire GPU énorme – plus de 10 fois plus – principalement à cause du cache KV.
Llama 4 Maverick vs DeepSeek V3 0324 : Applications
Llama 4 Maverick
Recherche et analyse de documents juridiques, de conformité et scientifiques
- Peut traiter des documents extrêmement longs (jusqu’à 10 millions de tokens) en un seul contexte, en préservant toutes les informations et relations.
Réponses à partir de bases de connaissances
- Intègre et référence des informations provenant de bases de connaissances massives, prenant en charge les requêtes complexes et multi-documents.
Traitement de rapports financiers
- Analyse efficacement de longs rapports financiers ou d’analystes, en extrayant des informations pertinentes sans troncature.
DeepSeek V3 0324
Assistants de programmation intelligents
- Excellent pour la génération de code, la complétion de code et la compréhension de code, idéal pour les outils de développement et l’intégration dans les IDE.
Révision de code automatisée
- Performant pour analyser la logique et le style du code, détecter les bugs et fournir des suggestions, simplifiant ainsi les processus de révision.
Questions-réponses généralistes
- Solide dans les scénarios à contexte standard, adapté aux chatbots de support client, aux assistants de connaissances d’entreprise, etc.
Llama 4 Maverick vs DeepSeek V3 0324 : Exemples de tâches
Invite :
Un mot de passe est considéré comme fort si toutes les conditions suivantes sont remplies :
- Il comporte au moins 6 caractères et au plus 20 caractères.
- Il contient au moins une lettre minuscule, au moins une lettre majuscule et au moins un chiffre.
- Il ne contient pas trois caractères identiques consécutifs (par exemple "Baaabb0" est faible, mais "Baaba0" est fort).
Étant donné une chaîne password, renvoyez le nombre minimal d’étapes nécessaires pour rendre le mot de passe fort. Si le mot de passe est déjà fort, renvoyez 0.
En une étape, vous pouvez :
- Insérer un caractère dans le mot de passe,
- Supprimer un caractère du mot de passe, ou
- Remplacer un caractère du mot de passe par un autre caractère.
Exemple 1 :
Entrée : password = "a"
Sortie : 5
Exemple 2 :
Entrée : password = "aA1"
Sortie : 3
Exemple 3 :
Entrée : password = "1337C0d3"
Sortie : 0
Contraintes :
1 <= password.length <= 50
password est composé de lettres, chiffres, point '.' ou point d'exclamation '!'.
Llama 4 Maverick
DeepSeek V3 0324
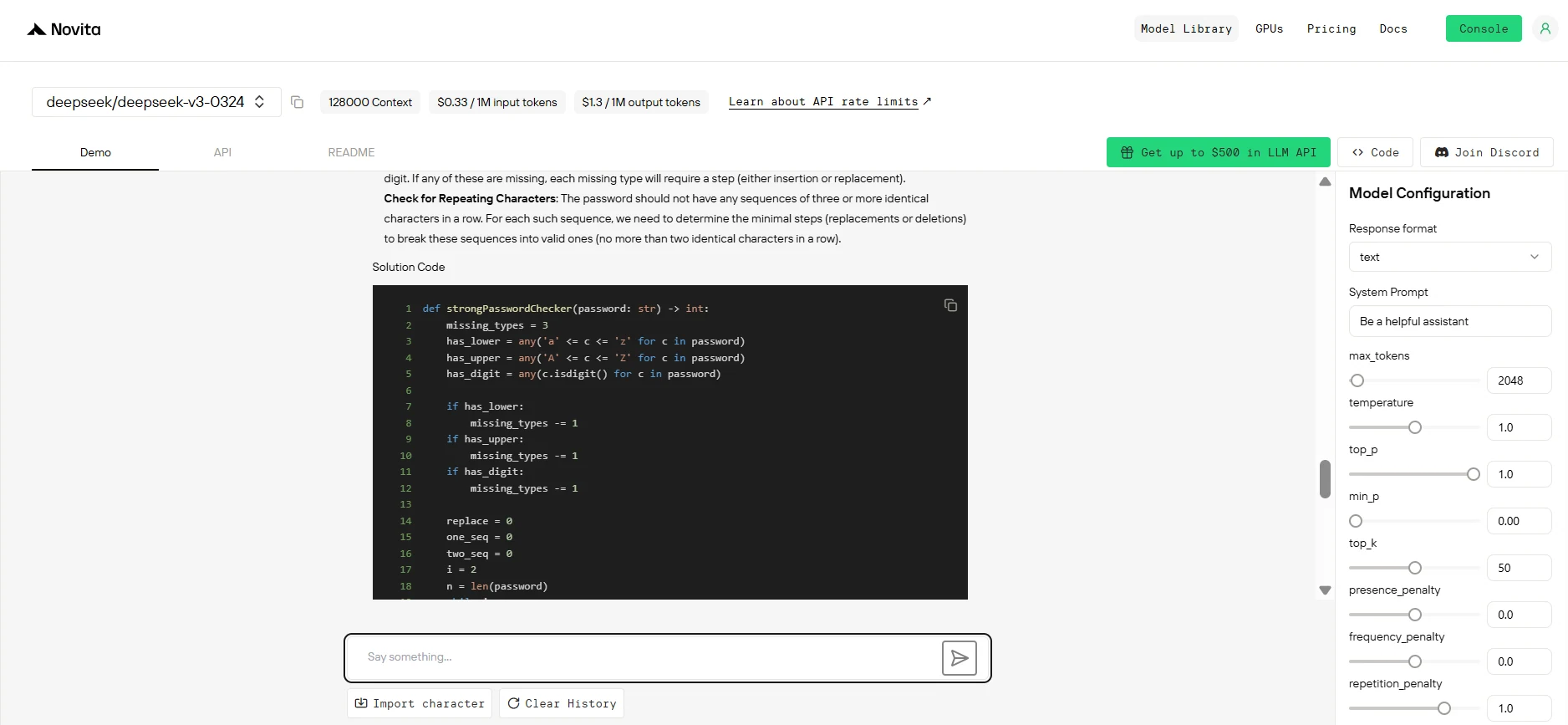
Comparaison des tâches Llama 4 Maverick vs DeepSeek V3 0324
llama 4 maverick :
- Plus robuste et modulaire, avec une logique claire et une gestion explicite des cas limites.
- Gère les mots de passe longs et les séquences répétées avec une meilleure transparence et optimisation.
- Recommandé pour les scénarios nécessitant clarté, maintenabilité et robustesse.
deepseek v3 0324 :
- Plus compact et efficace pour les cas simples.
- Traite les scénarios complexes de manière efficace mais avec moins de clarté.
- Adapté aux scénarios où la compacité et la performance sont prioritaires sur la lisibilité.
Comment accéder à Llama 4 Maverick et DeepSeek V3 0324 via l’API Novita ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez dès maintenant la démo de Llama 4 Maverick et DeepSeek V3 0324 !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier avec l’API, nous vous fournirons une nouvelle clé API. Rendez-vous dans la page Paramètres et copiez la clé API comme indiqué dans l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE_CLÉ_API_Novita_AI>",
)
model = "meta-llama/llama-4-maverick-17b-128e-instruct-fp8"
stream = True # ou False
max_tokens = 2048
system_content = """Soyez un assistant utile"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Le choix entre Llama 4 Maverick et DeepSeek V3 0324 dépend de vos besoins. Pour les contextes ultra-longs et la clarté, Llama 4 Maverick se démarque. Pour le codage efficace et les déploiements économiques, DeepSeek V3 0324 est le grand gagnant. Les deux modèles offrent des performances de premier ordre dans leurs domaines respectifs.
Questions fréquemment posées
Quelles sont les principales différences entre Llama 4 Maverick et DeepSeek V3 0324 ?
Llama 4 Maverick est meilleur pour les tâches à long contexte, à haute transparence et sensibles à la vitesse. DeepSeek V3 0324 excelle dans les tâches liées au code et les scénarios économes en ressources.
Comment les besoins matériels se comparent-ils entre Llama 4 Maverick et DeepSeek V3 0324 ?
DeepSeek V3 0324 nécessite beaucoup moins de mémoire GPU que Llama 4 Maverick, qui est gourmand en ressources pour les contextes longs.
Quel modèle choisir pour l’analyse de documents juridiques ou de recherche ?
Llama 4 Maverick est préféré en raison de sa capacité à traiter des contextes d’entrée extrêmement longs.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.**



